为什么SOTA网络在你的数据集上不行?来看看Imagnet结果的迁移能力研究
论文通过实验证明,ImageNet上的模型并不总能泛化到其他数据集中,甚至可能是相反的,而模型的深度和宽度也会影响迁移的效果。
如果需要参考,可选择类别数与当前任务相似的数据集上的模型性能。论文通过大量的实验来验证猜想,虽然没有研究出如通过数据集间的某些特性来直接判断模型迁移效果这样的成果,但读下来还是挺有意思的来源:晓飞的算法工程笔记 公众号
论文: Is it Enough to Optimize CNN Architectures on ImageNet?

Introduction
深度卷积网络是现代视觉任务的核心模块,近年来诞生了许多优秀的卷积网络结构,如何评价网络的优劣是研究中很重要的事情。但目前的网络性能还不能直接通过理论判别,需要进行相关的实验验证。目前许多模型都建立在ImageNet的基础上,虽然ImageNet数据集很大,但相对于开发世界而言,只是微不足道的一部分。因此,论文的立意就是,探索ImageNet下的优秀模型能否都迁移到其它数据集中。
为了回答这一问题,论文提出了APR(architecture and performance relationship)指标。由于模型的性能与数据集相关,数据集间的APR指标能够对比相同结构在不同数据集下的表现。为了让实验更准确,论文随机采样了500个网络,并在多个数据集间进行对比。
Experiment
Experimental datasets
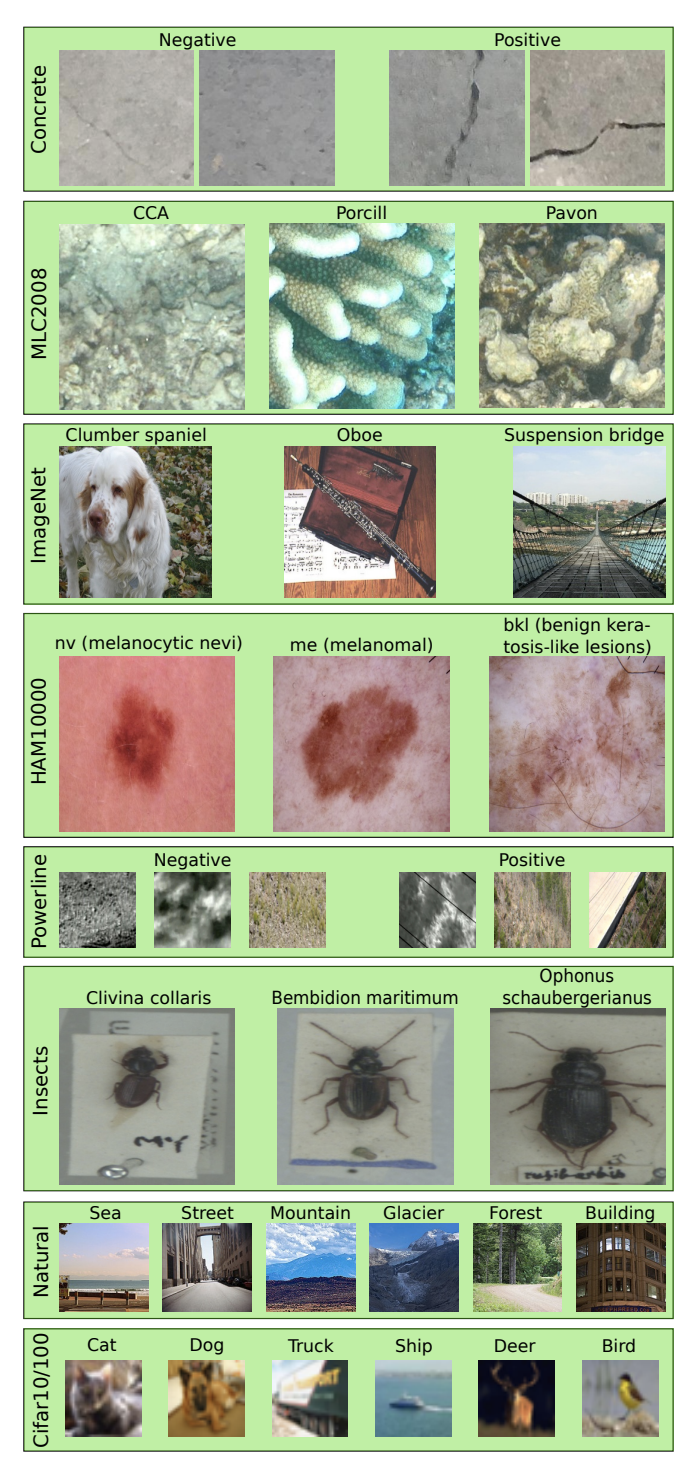
论文共在9个数据集上测试,数据集的样例如上图所示,这里简述下图片数和类别数:
- Conrete:4万张图片,2个类别,平衡。
- MLC2008:4万3000张图片,9个类别,不平衡。
- ImageNet:130万张图片,1000个类别,平衡。
- HAM10000:1万张图片,7个类别,不平衡。
- Powerline:8000张图片,2个类别,平衡。
- Insects:6300张图片,291类别,不平衡。
- Intel Image Classification(natural):2500张图片,6个类别,平衡。
- Cifar10:6万张图片,10个类别,平衡。
- Cifar100:6万张图片,100个类别,平衡。
Experimental setup
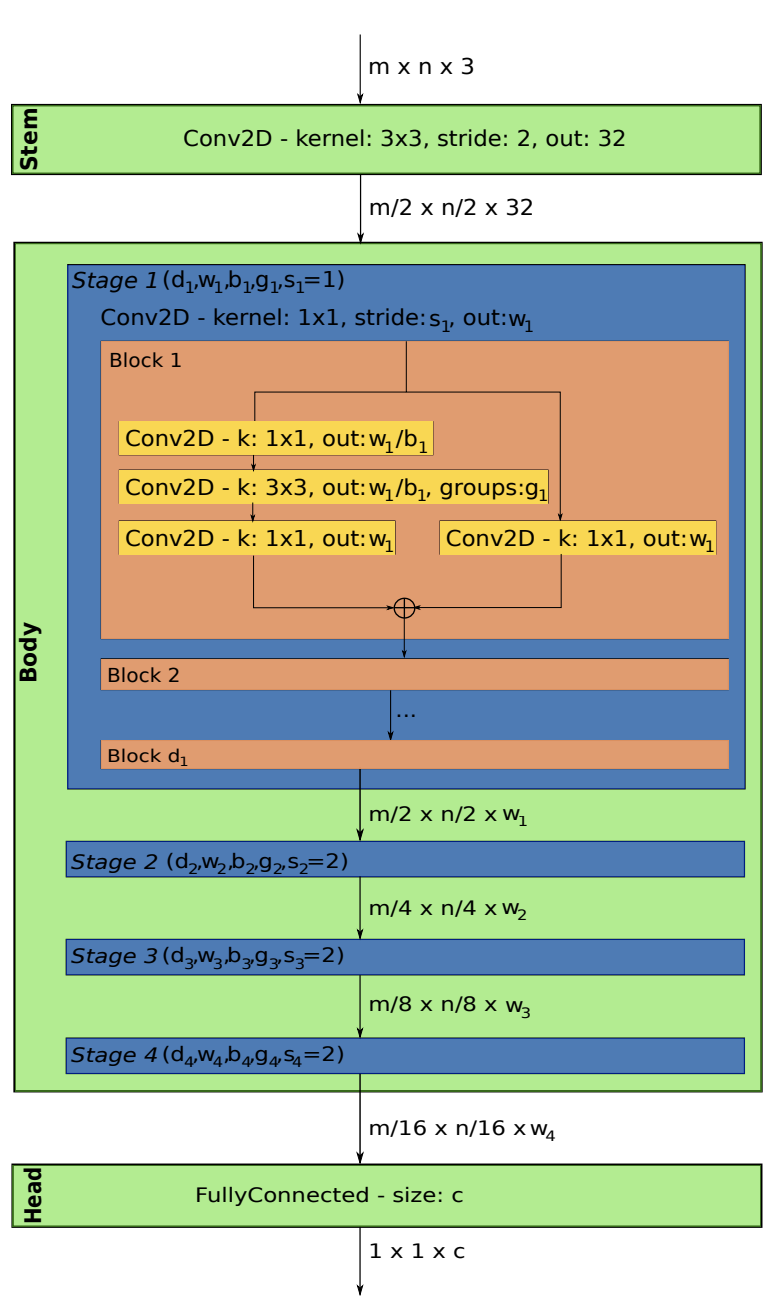
论文从AnyNetX网络空间采样实验结构,AnyNetX主要包含三部分:
- steam:固定结构,stride=2的\(3\times 3\)卷积,用于降低分辨率,提高输出维度。
- body:包含4个stage,每个stage \(i\)由步长为\(s_i\)的\(1\times 1\)卷积开头,后续是\(d_i\)个相同的标准residual bottleneck block,width为\(w_i\),bottleneck ratio为\(b_i\),group width为\(g_i\)(残差分支的并行子分支),这个参数对相同stage内的block是共享的。
- head:固定结构,全连接层,用于返回特定大小的输出。
AnyNetX的设计空间共包含16个可变参数,共4个stage,每个stage都有4个独自的参数。两个参数\(d_i\le 16\)和\(w_i\le 1024\)均需能被8整除,\(b_i\in 1,2,4\),\(g_i\in 1,2,\cdots,32\),剩下的\(stride_1\)固定为1,其余的均为2。反复执行模型随机采样,取500个计算量在360MF和400MF之间的模型。
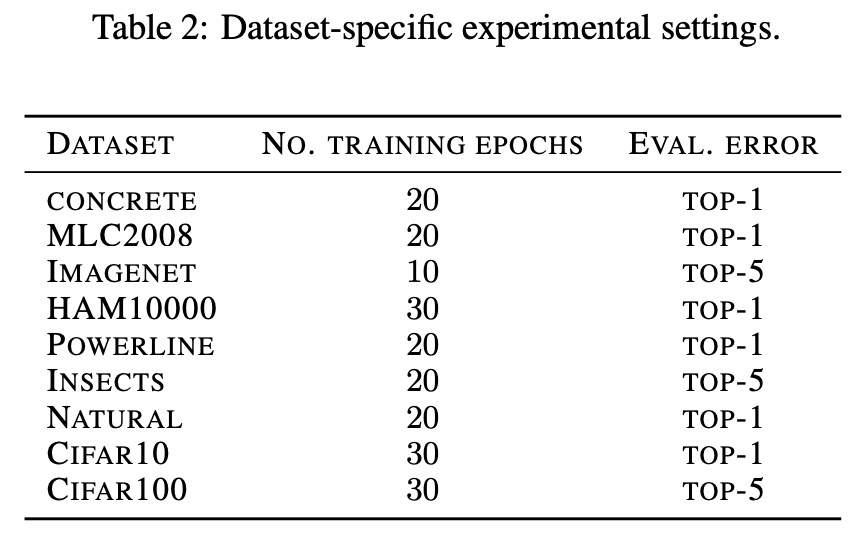
按表2的实验设置,将500个模型在不同的数据集上训练直到收敛得差不多了,获取其对应的性能指标。附录还有一些对比实验,使用了另外的配置,具体可见原文。
Experimental metrics
在进行实验之前,论文先对模型和数据集进行分析。定义eCDF(empirical cumulative error distribution)指标,用来标记错误率低于x的模型比例,n个模型的eCDF计算为:
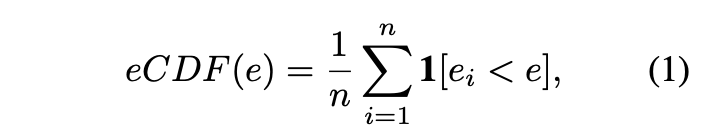
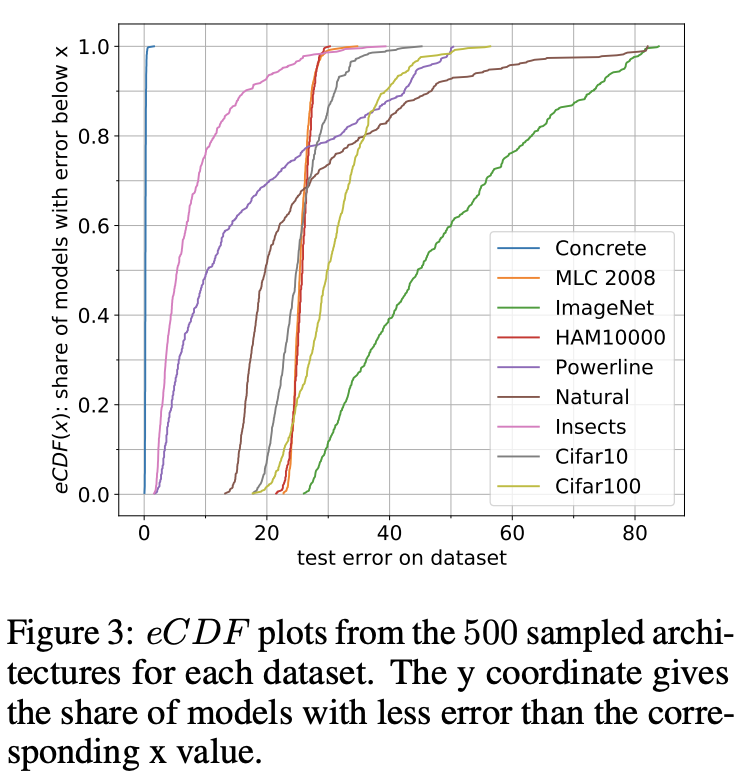
从图3可以看到不同数据集上的eCDF表现,ImageNet数据集的模型比例随模型性能增加稳定下降,模型之间的差异较大。Natural、Insects、Powerline和Cifar100数据集的高性能模型较多,只包含少量低性能模型,Concrete、HAM10000、MLC2008和Cifar10数据集的模型性能则比较集中。
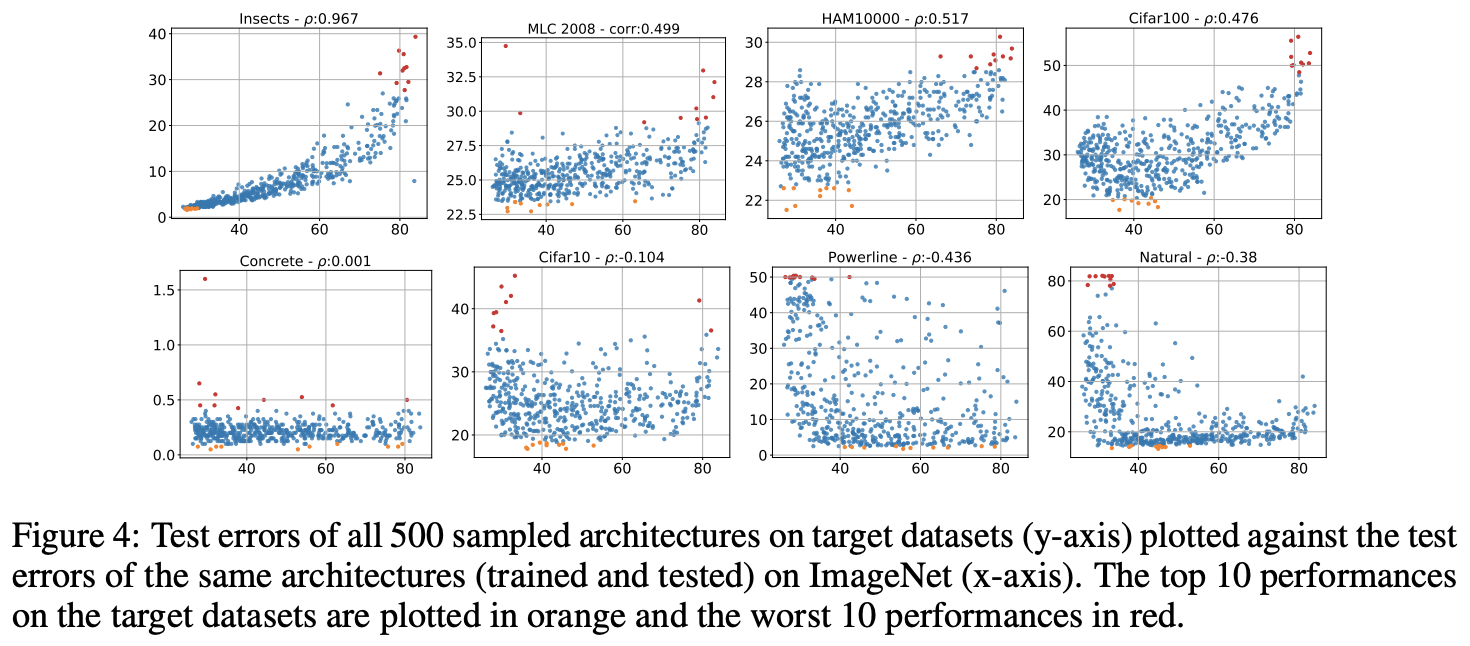
论文从两个方面来分析模型与性能的关系(APRs, architecture-performance relationship):
- 以ImageNet上的测试误差为x轴,目标数据集上的测试误差为y轴,标记所有的模型。
- 计算spearman相关系数\(\rho\in[-1, 1]\),用以反馈两个数据集上模型误差的相关性,0代表无关,-1和1代表关系可用单调函数表达。
分析的结果如图4所示:
- 第一行的数据集与ImageNet有较强或中等的相关性,表明大多数的分类任务跟ImageNet有相似的APR表现,可根据ImageNet来进行模型的选取。
- Concrete跟ImageNet无相关性,其准确率占满了\([0,0.5]\)的区间,在这种数据集上,模型的选择更应该注重性能而不是ImageNet上的表现。
- 部分数据集跟ImageNet有轻度或明显的负相关性,在ImageNet上表现优秀的模型在这些数据集上反而表现一般。
通过上面的三个分析,我们可以初步回答论文提出的问题,即ImageNet下的优秀模型不一定迁移到其它数据集中。
Identifying Drivers of Difference between Datasets
论文对不同数据集上的top15模型的结构进行分析,发现ImageNet数据集的top15模型的block width和depth参数十分相似,第一个stage的block width和depth都十分小,随后逐级增加。Insects数据集也有类似的现象,而MLC2008和HAM10000数据集也有相似的趋势,但噪声更多一些。Powerline和Natural数据集则完全相反,参数呈逐级减少的趋势,最后一个stage均是很小的block。Cifar10和Cifar100数据集则更有趣,在block width上是呈逐级增加的趋势,而block depth上则是呈逐级减少的趋势。为此,论文打算研究下这两个参数在不同数据集上与模型性能的关系。
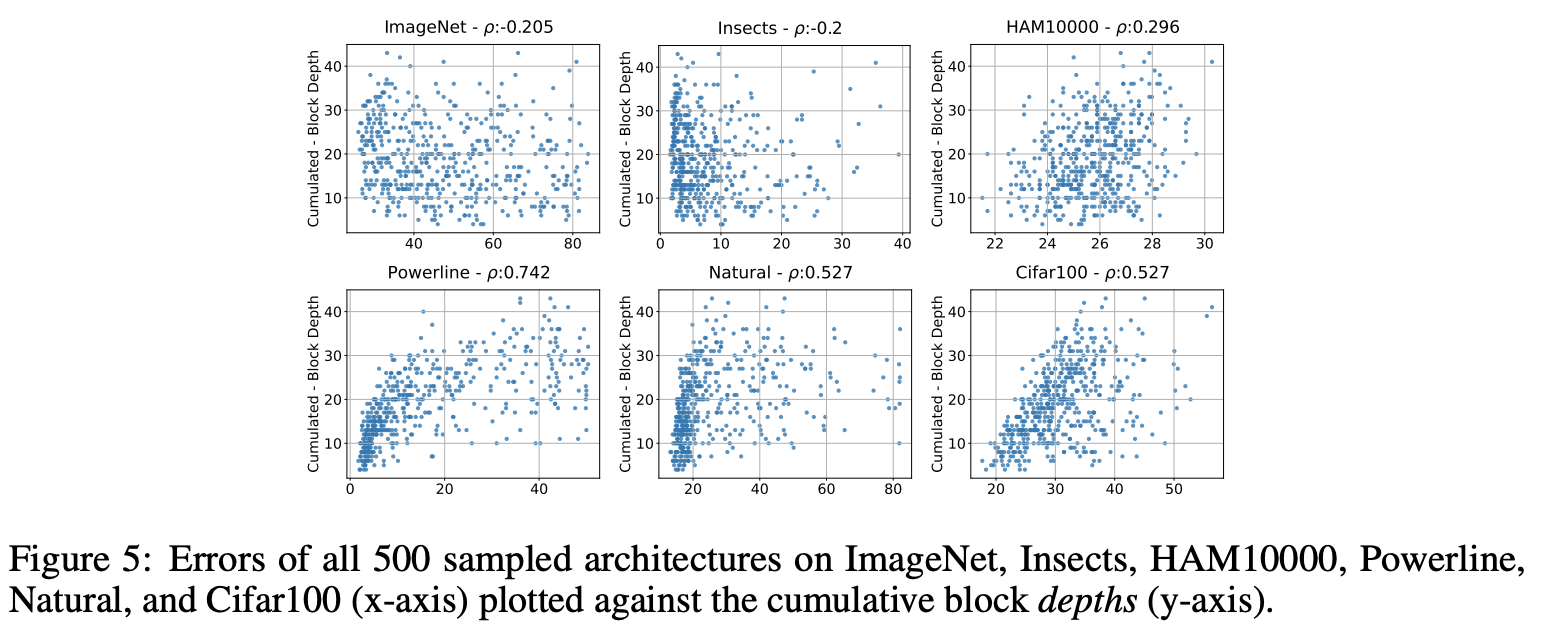
图5为所有stage累积的block depth与模型性能的关系。ImageNet的优秀模型的累积depth至少为10,此外没有其他的特殊关系。Insects数据集则完全无关。HAM10000有轻度向右倾斜现象,似乎有相关性,但肉眼看起来也没有强相关。Powerline、Natural和Cifar100数据集则有强烈的相关性,错误率随着累积depth增加而增加,优秀的模型累积depth均小于10。
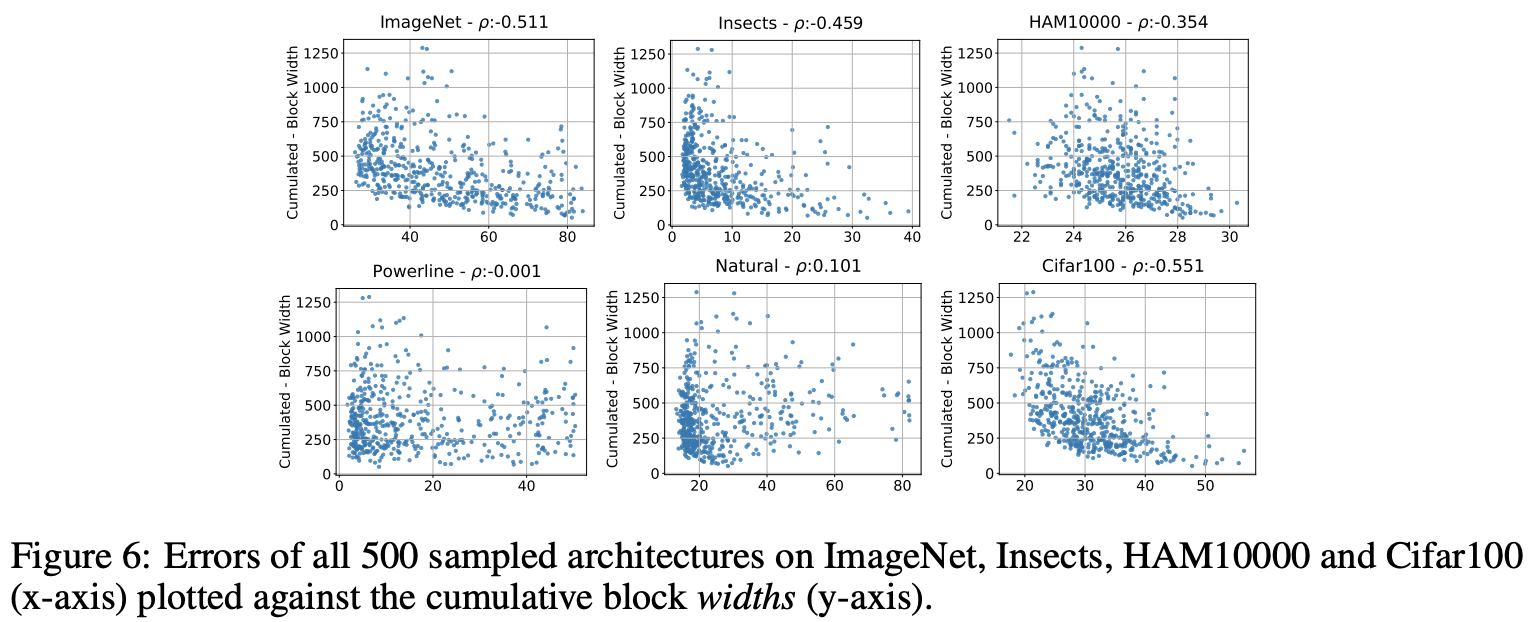
图6为所有stage累积的width depth与模型性能的关系。ImageNet的模型性能与累积width呈反相关,优秀模型的累积width至少为250。Insects和HAM10000数据集也有类似的反相关性,但程度弱一些。Powerline和Natural数据集与累积width没有明显的相关性,而Cifar100数据集则有强烈的反相关性。
除了上述的两个参数的对比,论文还对比了bottleneck ratios和group width参数,具体可以看附录。总结而言,在不同的数据集上,最优模型的网络深度和网络宽度有可能差异较大,这是模型迁移能力的重要影响因子。
Impact of the Number of Classes
ImageNet相对其他数据集有超大的类别数,Insect数据集是类别数第二的数据集,其ARP与ImageNet高度相似。从这看来,类别数似乎也可能是数据集的最优模型结构的影响因素之一。
为了探究这一问题,论文从ImageNet中构造了4个新数据集ImageNet-100、ImageNet-10、ImageNet-5和ImageNet-2,分别随机选取100,10,5,2个类别,统称为ImageNet-X。ImageNet-100的训练方法跟原数据集一样,而其他3个数据集考虑到数据集小了,则采用top-1 error以及训练40个周期。
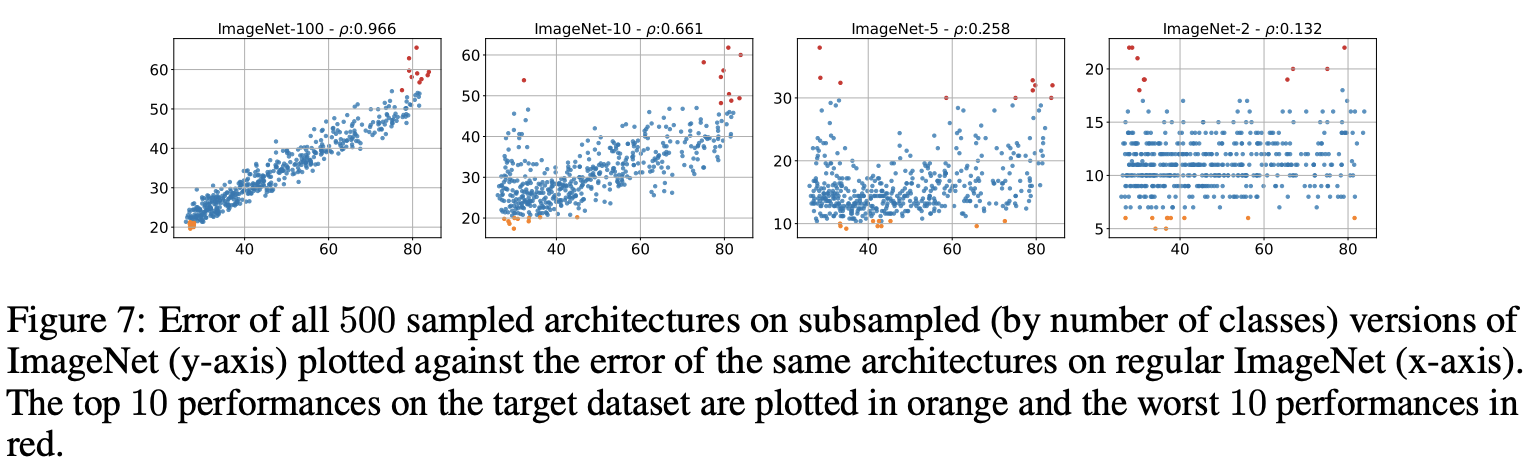
图7展示了子数据集与原数据集的ARP对比,从图中可以明显的看到,子数据集与原数据集的相关性随着类别数的减少而逐渐减少。这验证了论文猜测,数据集类别数也是影响模型结构与性能的相关性的重要因素。
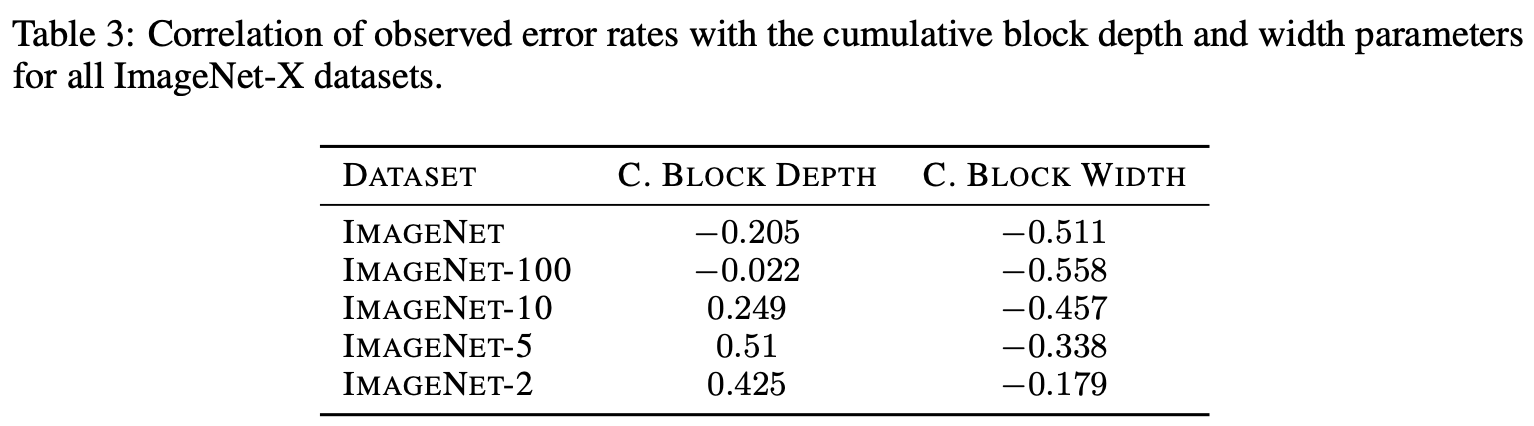
论文也测试了block的累积depth和累积width在ImageNet-X数据集上的表现,结构如表3所示。从表中可以看到,随着类别数增加,累积depth和累积width的相关因子都在逐级增加(不代表相关性增加)。所以,可以认为类别数也是影响block的累积depth和累积width与模型性能相关性的重要因素。
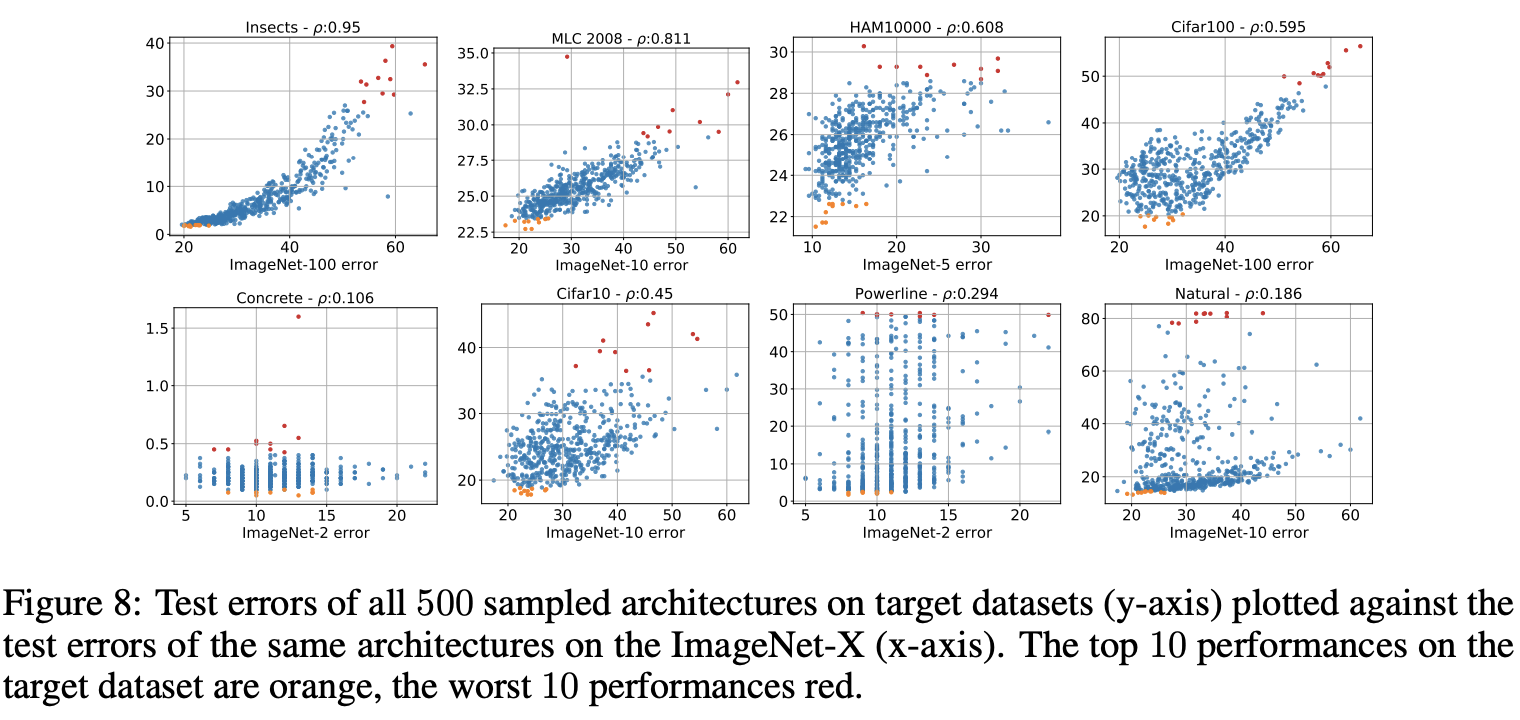
论文已经通过ImageNet-X数据集证明了类别数对APR有着重要影响,虽然不能说简单地改变数据集的类别数就能复制APR表现,但我们可以将类别数相近的数据集的APR表现作为参考,而不是总参考ImageNet数据集。为了进一步验证这个想法,论文将ImageNet-X与各数据集的相关性进行的统计,结果如图8所示。
从图8可以看出,MLC2008和Cifar10数据集与对应的ImageNet-X数据集高度相关性。而原本与ImageNet有负相关性的Powerline和Natural数据集,则变为与ImageNet-X数据集有轻度正相关性,重要的是最好的模型的表现更一致了。为此,论文得出的结论是,相对于ImageNet数据集而言,ImageNet-X数据集比代表了更大的APR多样性。
Conclusion
论文通过实验证明,ImageNet上的模型并不总能泛化到其他数据集中,甚至可能是相反的,而模型的深度和宽度也会影响迁移的效果。
如果需要参考,可选择类别数与当前任务相似的数据集上的模型性能。论文通过大量的实验来验证猜想,虽然没有研究出如通过数据集间的某些特性来直接判断模型迁移效果这样的成果,但读下来还是挺有意思的。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

为什么SOTA网络在你的数据集上不行?来看看Imagnet结果的迁移能力研究的更多相关文章
- NASNet学习笔记—— 核心一:延续NAS论文的核心机制使得能够自动产生网络结构; 核心二:采用resnet和Inception重复使用block结构思想; 核心三:利用迁移学习将生成的网络迁移到大数据集上提出一个new search space。
from:https://blog.csdn.net/xjz18298268521/article/details/79079008 NASNet总结 论文:<Learning Transfer ...
- Local Binary Convolutional Neural Networks ---卷积深度网络移植到嵌入式设备上?
前言:今天他给大家带来一篇发表在CVPR 2017上的文章. 原文:LBCNN 原文代码:https://github.com/juefeix/lbcnn.torch 本文主要内容:把局部二值与卷积神 ...
- pytorch实现MLP并在MNIST数据集上验证
写在前面 由于MLP的实现框架已经非常完善,网上搜到的代码大都大同小异,而且MLP的实现是deeplearning学习过程中较为基础的一个实验.因此完全可以找一份源码以参考,重点在于照着源码手敲一遍, ...
- PyTorch迁移学习-私人数据集上的蚂蚁蜜蜂分类
迁移学习的两个主要场景 微调CNN:使用预训练的网络来初始化自己的网络,而不是随机初始化,然后训练即可 将CNN看成固定的特征提取器:固定前面的层,重写最后的全连接层,只有这个新的层会被训练 下面修改 ...
- 网游中的网络编程3:在UDP上建立虚拟连接
目录 网游中的网络编程系列1:UDP vs. TCP 网游中的网络编程2:发送和接收数据包 网游中的网络编程3:在UDP上建立虚拟连接 TODO 二.在UDP上建立虚拟连接 介绍 UDP是无连接的,一 ...
- ios开发之网络数据的下载与上传
要实现网络数据的下载与上传,主要有三种方式 > NSURLConnection 针对少量数据,使用“GET”或“POST”方法从服务器获取数据,使用“POST”方法向服务器传输数据; > ...
- (2) 用DPM(Deformable Part Model,voc-release4.01)算法在INRIA数据集上训练自己的人体检測模型
步骤一,首先要使voc-release4.01目标检測部分的代码在windows系统下跑起来: 參考在window下执行DPM(deformable part models) -(检測demo部分) ...
- Microsoft Dynamics CRM 2011 当您在 大型数据集上执行 RetrieveMultiple 查询很慢的解决方法
症状 当您在 Microsoft Dynamics CRM 2011 年大型数据集上执行 RetrieveMultiple 查询时,您会比较慢. 原因 发生此问题是因为大型数据集缓存 Retrieve ...
- 在Titanic数据集上应用AdaBoost元算法
一.AdaBoost 元算法的基本原理 AdaBoost是adaptive boosting的缩写,就是自适应boosting.元算法是对于其他算法进行组合的一种方式. 而boosting是在从原始数 ...
- TersorflowTutorial_MNIST数据集上简单CNN实现
MNIST数据集上简单CNN实现 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文献 Tensorflow机器学习实战指南 源代码请点击下方链接欢迎加星 Tesorflow实现基于MNI ...
随机推荐
- CoreDNS笔记
因为项目的原因需要在客户端启动DNS服务,拦截本机DNS请求,考察了一下开源的DNS Server项目,适合在Windows下使用的只有CoreDNS. 说明 CoreDNS的项目地址 https:/ ...
- valueOf与toString
valueOf与toString valueOf和toString是Object.prototype上的方法,在Js几乎所有的对象都会继承自Object,同样由于包装对象的原因,几乎所有的数据类型都能 ...
- 【快速排序】采用D&C(divide and conquer)方法求解
介绍 快速排序使用分治法(Divide and conquer)策略来把一个串行(list)分为两个子串行(sub-lists).平均状况下,排序 n 个项目要 Ο(nlogn) 次比较,在最坏状况下 ...
- 学习go语言编程之安全编程
数据加密 对称加密 采用单密钥的加密算法,称为对称加密. 常见的单密钥加密算法有DES.AES.RC4等. 在对称加密中,私钥不能暴露,否则在算法公开的情况下,数据等同于明文. 非对称加密 采用双密钥 ...
- RHEL8重置root用户密码步骤
要先确定是否为RHEL 8系统. [root@zhangsan ~]# cat /etc/redhat-release Red Hat Enterprise Linux release 8.0 (Oo ...
- 从零开始写 Docker(二)---优化:使用匿名管道传递参数
本文为从零开始写 Docker 系列第二篇,主要在 mydocker run 命令基础上优化参数传递方式,改为使用 runC 同款的匿名管道传递参数. 如果你对云原生技术充满好奇,想要深入了解更多相关 ...
- 海康摄像SDK开发笔记(一):海康威视网络摄像头SDK介绍与模块功能
前言 视频监控.人脸识别等应用中经常使用到摄像头,当前占据主流视频监控摄像头就是海康和大华两家,都可通过自家的sdk或者是onvif方式使用和控制摄像头. 本文章讲解海康的sdk方式. 海康 ...
- python字典操作的大O效率
- 【ACM专项练习#03】打印图形、栈的合法性、链表操作、dp实例
运营商活动 题目描述 小明每天的话费是1元,运营商做活动,手机每充值K元就可以获赠1元,一开始小明充值M元,问最多可以用多少天? 注意赠送的话费也可以参与到奖励规则中 输入 输入包括多个测试实例.每个 ...
- 【LeetCode二叉树#09】路径总和I+II,以及求根节点到叶节点数字之和(回溯回溯,还是™的回溯)
路径总和 力扣题目链接(opens new window) 给定一个二叉树和一个目标和,判断该树中是否存在根节点到叶子节点的路径,这条路径上所有节点值相加等于目标和. 说明: 叶子节点是指没有子节点的 ...