Python爬虫(5-10)-编解码、ajax的get请求、ajax的post请求、URLError/HTTPError、微博的cookie登录、Handler处理器
五、编解码(Unicode编码)
(1)GET请求
所提方法都在
urllib.parse.路径下
- get请求的
quote()方法(适用于只提交一两个参数值)
url='http://www.baidu.com/baidu?ie=utf-8&wd='
# 对汉字进行unicode编码
name=urllib.parse.quote('白敬亭')
url+=name
- get请求的
urlencode()方法(适用于提交多个参数)
base_url='http://www.baidu.com/baidu?'
data={
'wd':'白敬亭',
'sex':'男',
'address':'中国'
}
new_data=urllib.parse.urlencode(data)
url=base_url+new_data
(2)POST请求
百度翻译
1.以百度翻译为例,输入需翻译的单词后,点击”检查”—”网络”,发现存在多个名为sug的文件
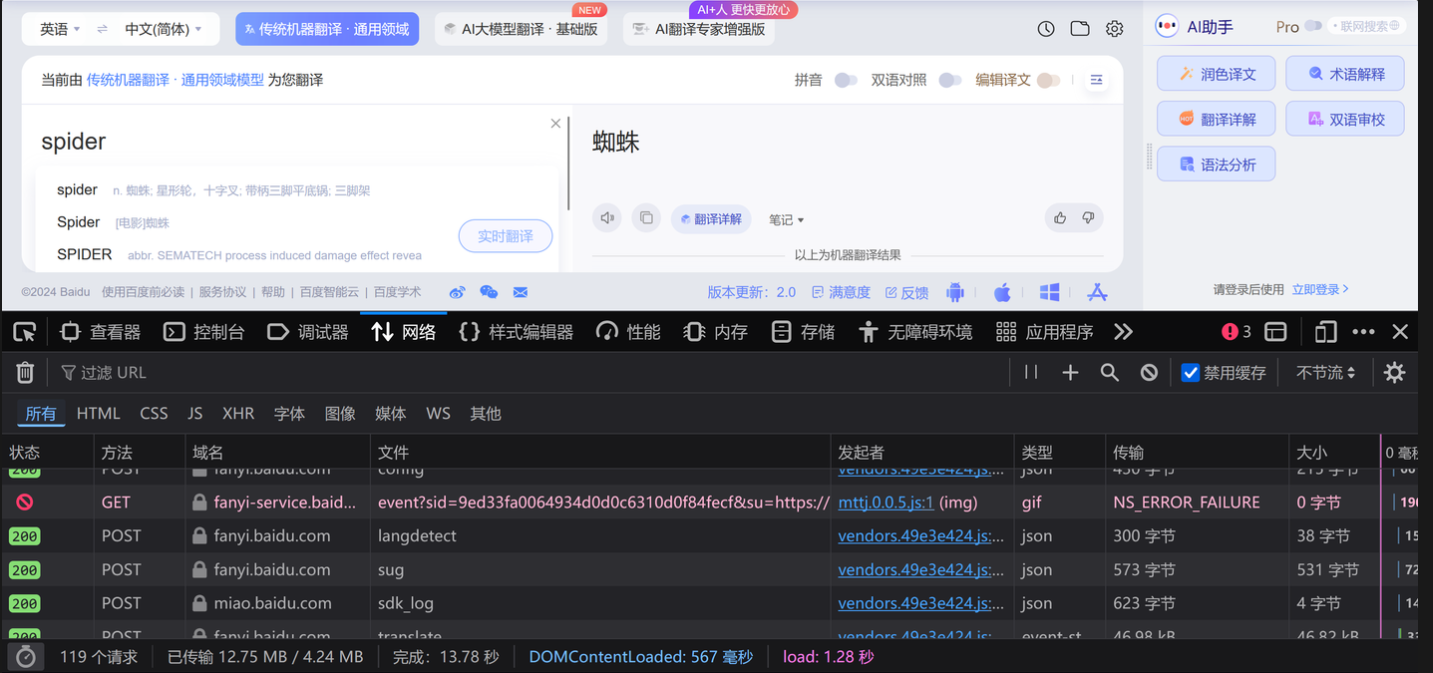
2.找到最后一个名为sug的文件,观察其请求和响应,发现就是我们要找的接口URL
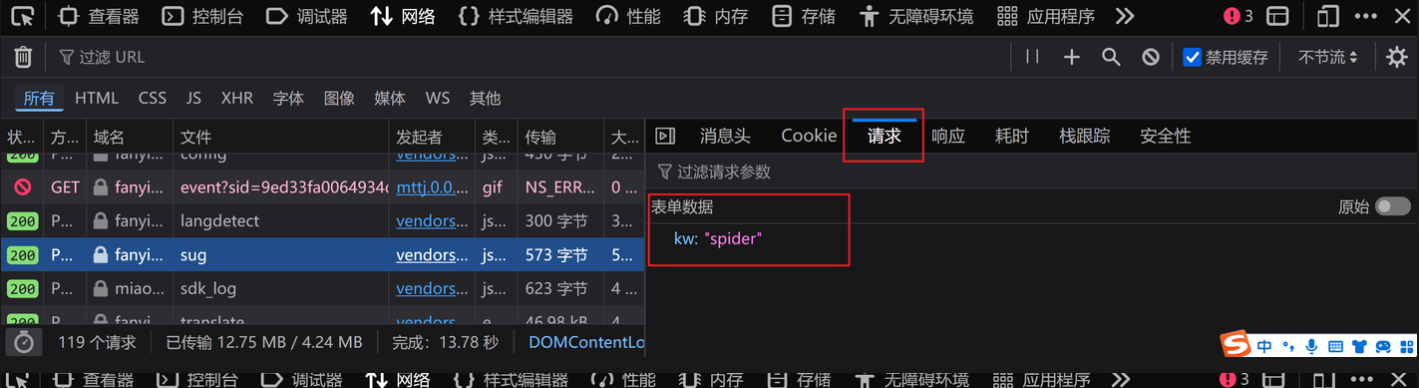
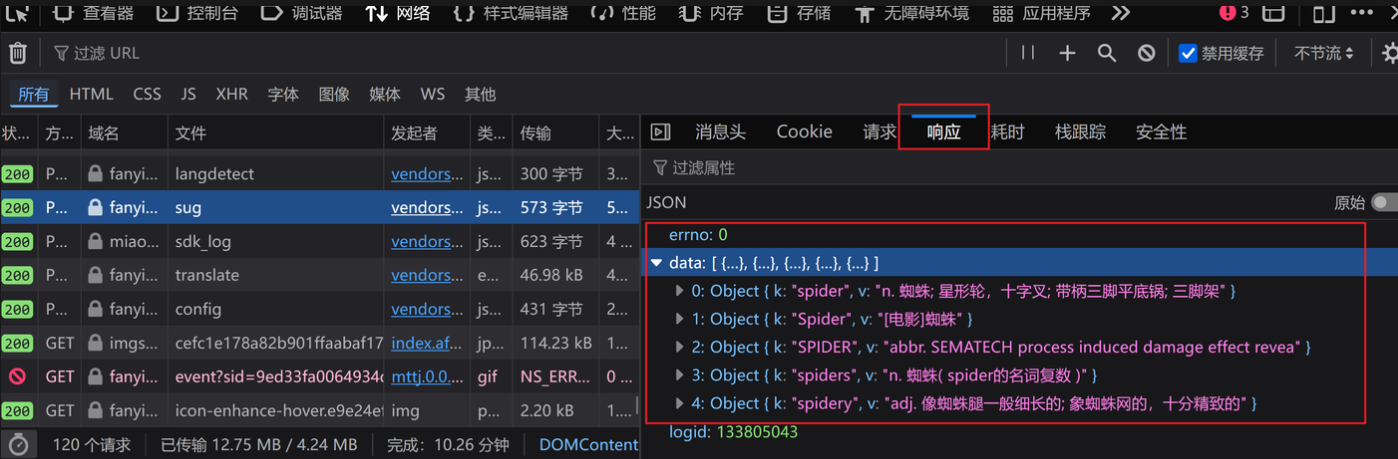
3.代码如下
# post请求百度翻译
url='https://fanyi.baidu.com/sug'
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:128.0) Gecko/20100101 Firefox/128.0'
}
data={
'kw':'spider'
}
# post请求的参数必须进行编码,转为字节型
# post的请求的参数是不会拼接在URL的后面的,而是需要放在清求对象定制的参数中
data=urllib.parse.urlencode(data).encode('utf-8')
request=urllib.request.Request(url=url,data=data,headers=headers)
response=urllib.request.urlopen(request)
content=response.read().decode('utf-8')
import json
# 将json字符串变为python对象
obj=json.loads(content)
print(obj)
4.总结
post请求方式的参数必须进行编码- 编码之后必须调用
encode()方法 - 参数要放在请求对象定制的方法中
六、ajax的get请求
(1)获取豆瓣电影的第一页的数据
1.打开“豆瓣电影”—“排行榜”—“喜剧”,找到接口(也就是找到某一个东西,该东西能展现当前页面的数据),由“响应”可以判断出所需的url
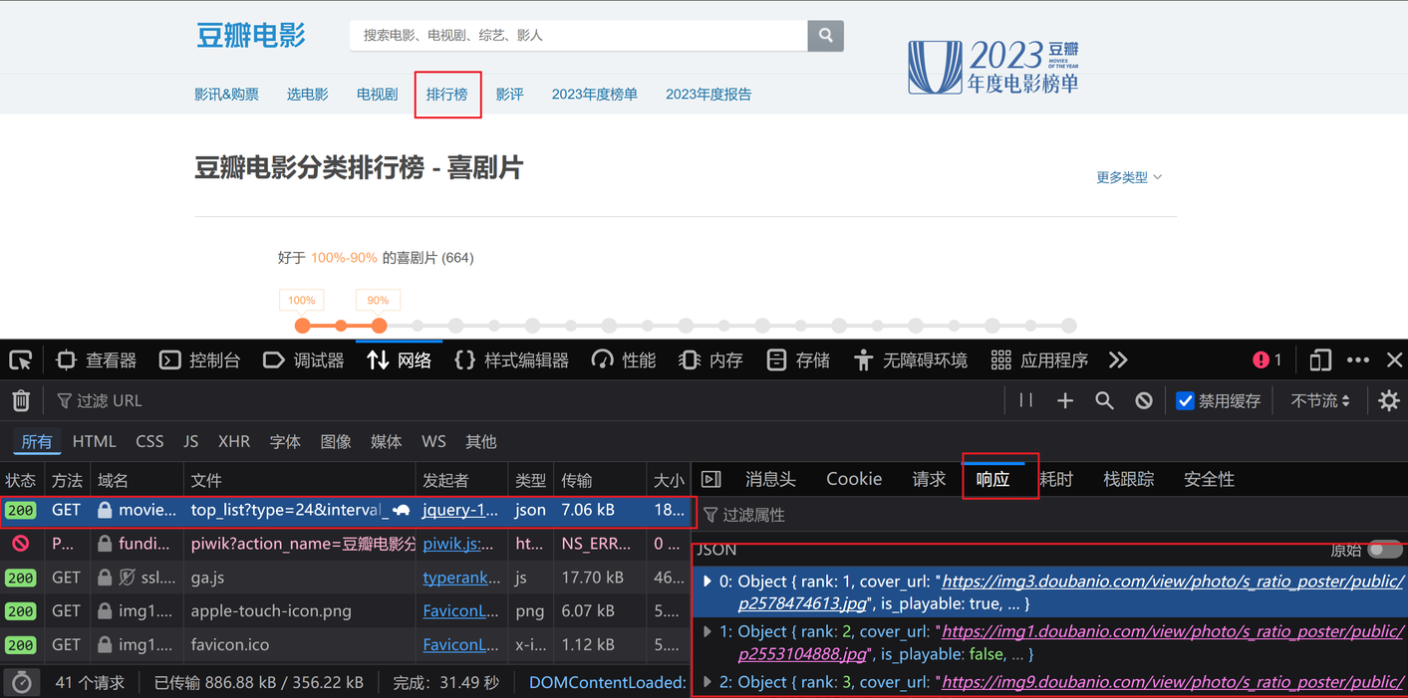
2.保存豆瓣电影的第一页的数据的代码如下:
import urllib.request
# ajax的get请求
# 获取豆瓣电影的第一页的数据并且保存起来
url='https://movie.douban.com/j/chart/top_list?type=24&interval_id=100:90&action=&start=0&limit=20'
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:128.0) Gecko/20100101 Firefox/128.0'
}
request=urllib.request.Request(url=url,headers=headers)
response=urllib.request.urlopen(request)
content=response.read().decode('utf-8')
# print(content)
# open方法默认情况下使用的是gbk的编码
# 使用UTF-8编码方式打开/创建名为douban.json文件
# 法一
fp=open('douban.json','w',encoding='utf-8')
fp.write(content)
# 法二
with open('douban1.json','w') as fp:
fp.write(content)
在法二中,with 语句用于管理文件对象的打开和关闭。as 关键字用于给文件对象取一个别名,这里是fp。fp.write(): 这是文件对象的一个方法,用于向文件中写入内容。
(2)获取豆瓣电影前十页的数据
1.观察可发现,URL中start的规律,start=(page-1)*20
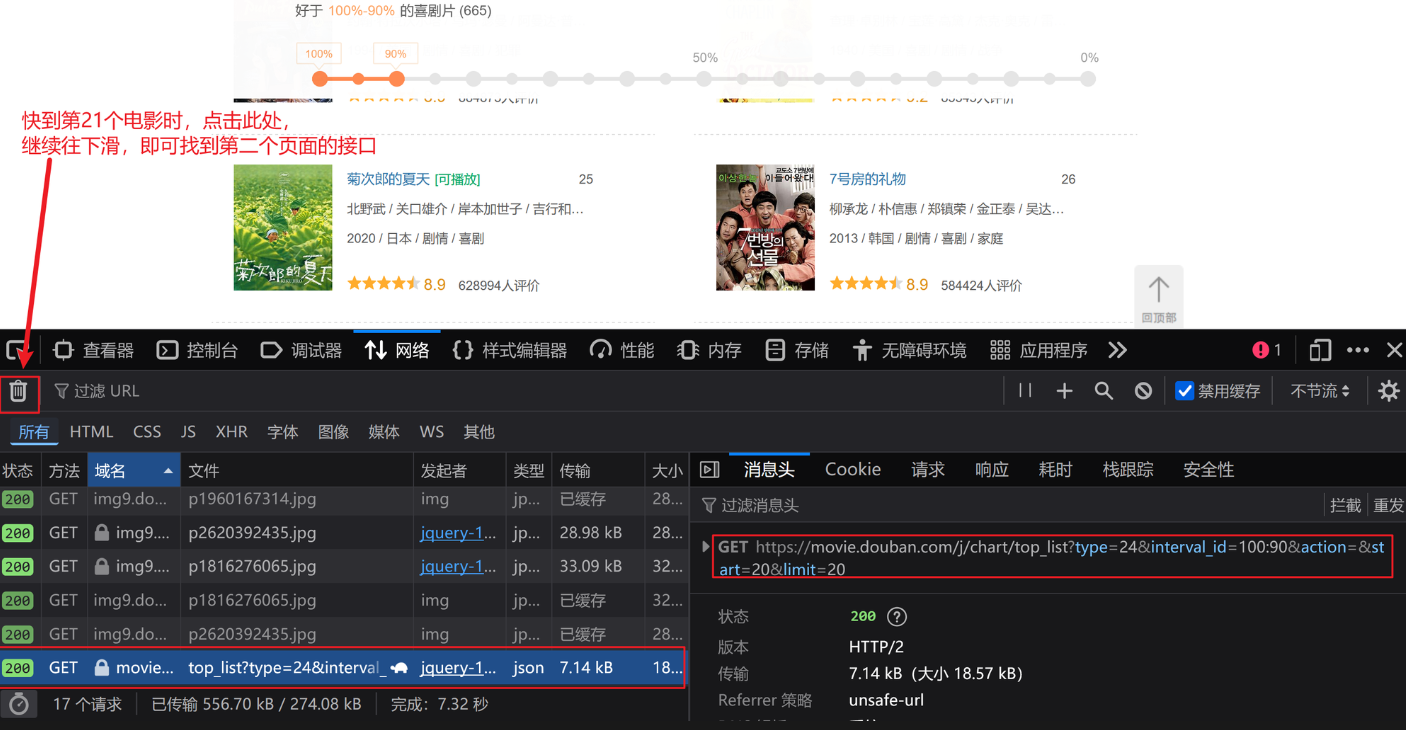
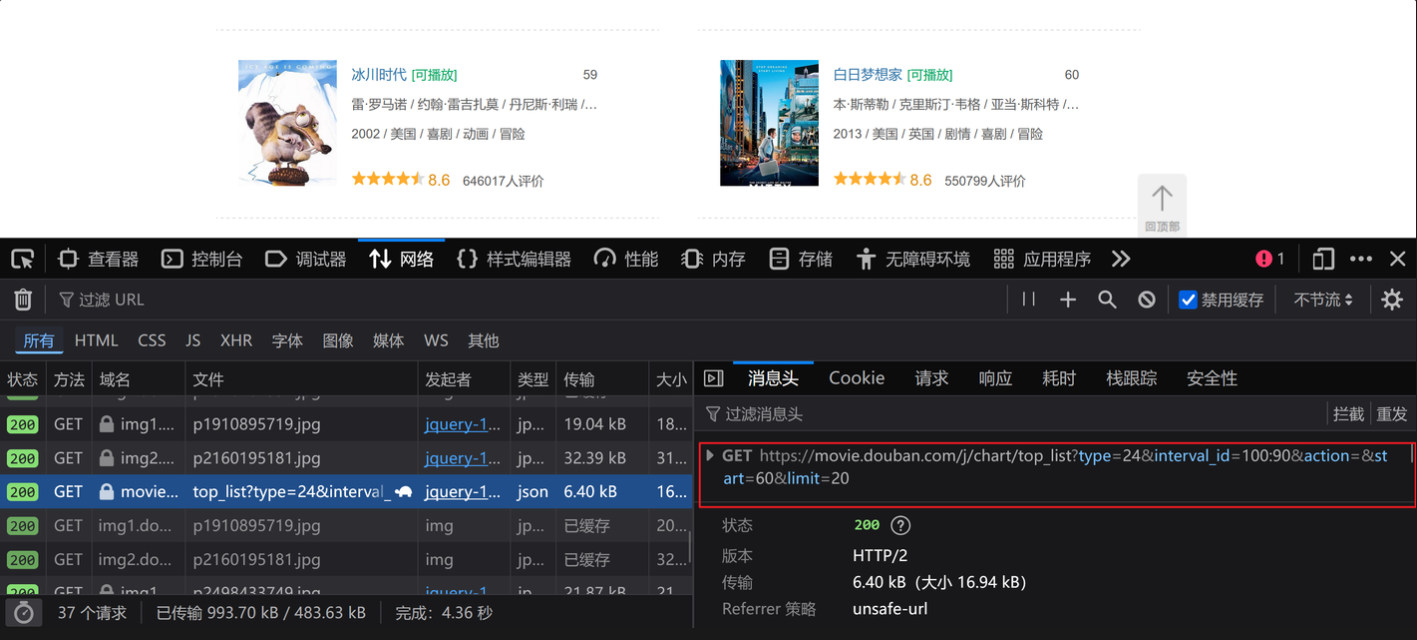
2.代码展示如下
# 获取豆瓣电影的前十页数据并且保存起来
def create_request(page):
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:128.0) Gecko/20100101 Firefox/128.0'
}
url='https://movie.douban.com/j/chart/top_list?'
data={
"type": 24,
"interval_id": "100:90",
"action": "",
# 观察可得start的规律
"start": (page-1)*20,
"limit": 20
}
new_data=urllib.parse.urlencode(data)
url+=new_data
request=urllib.request.Request(url=url,headers=headers)
return request
def get_content(request):
response=urllib.request.urlopen(request)
content=response.read().decode('utf-8')
return content
def load_content(page,content):
# 要将整形变量page转变为字符串
# 如果直接加单引号,page被当作一个字面量字符串,而不是变量page
with open('douban_'+str(page)+'.json','w') as fp:
fp.write(content)
# 程序的入口
if __name__=='__main__':
start_page=int(input('请输入开始的页码'))
end_page=int(input('请输入结束的页码'))
for page in range(start_page,end_page):
request=create_request(page)
content=get_content(request)
load_content(page,content)
七、ajax的post请求
1.观察发现”kfc官网“-”餐厅查询“网页的接口

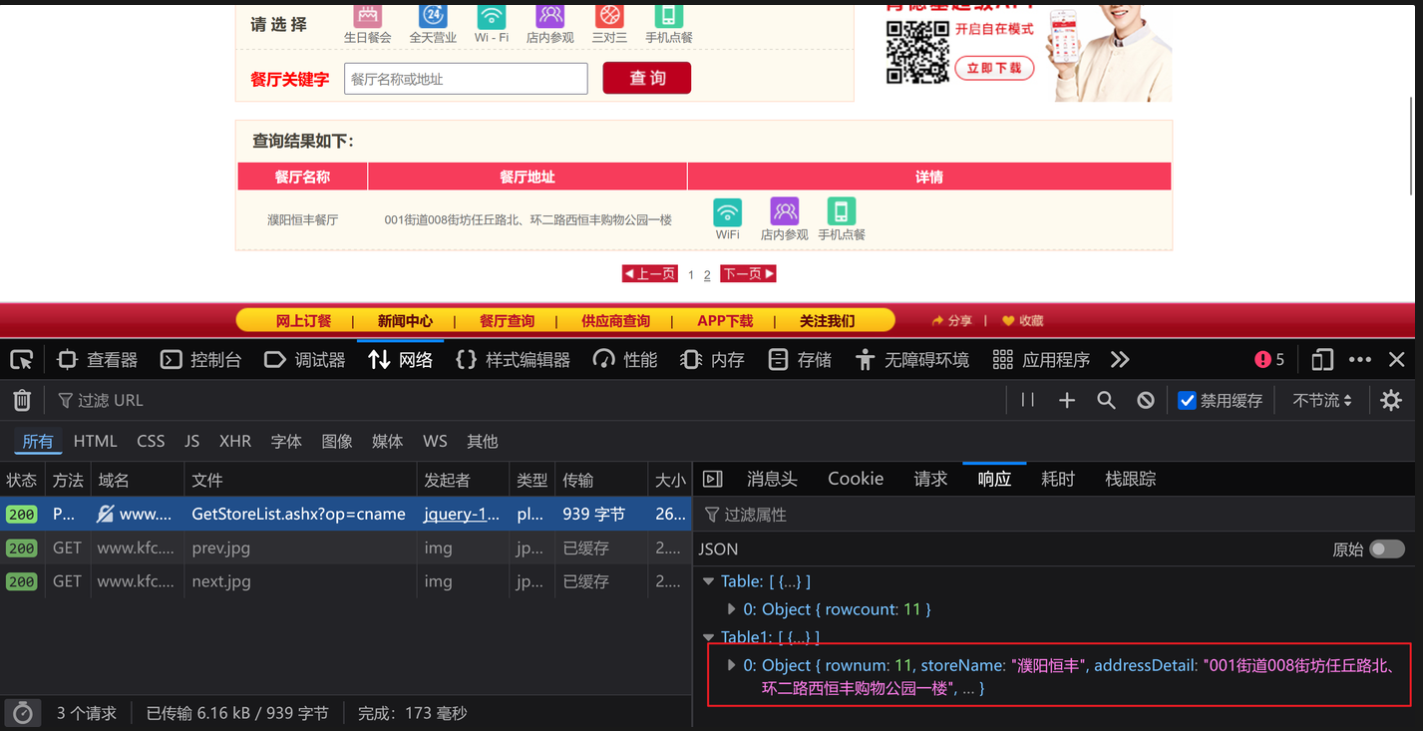
2.代码如下
# ajax的post请求--肯德基官网
def create_request(page):
url='http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
data={
'cname':'濮阳',
'pid':'',
'pageIndex':page,
'pageSize':10
}
new_data=urllib.parse.urlencode(data).encode('utf-8')
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:128.0) Gecko/20100101 Firefox/128.0'
}
# post方式不能直接拼接,要在请求对象定制的方法中加入该参数
request=urllib.request.Request(url=url,headers=headers,data=new_data)
return request
def get_content(request):
response=urllib.request.urlopen(request)
content=response.read().decode('utf-8')
return content
def load_content(page,content):
with open('kendeji'+str(page)+'.json','w',encoding='utf-8') as fp:
fp.write(content)
if __name__=='__main__':
start_page=int(input('请输入起始页码'))
end_page=int(input('请输入终止页码'))
for page in range(start_page,end_page):
request=create_request(page)
content=get_content(request)
print(f"页面 {page} 的内容: {content}")
# load_content(page,content)
八、URLError/HTTPError
简介:1.
HTTPError类是URLError类的子类
2.导入的包urllib.error.HTTPError或urllib.error.URLError
3.http错误:http错误是针对浏览器无法连接到服务器而增加出来的错误提示。引导并告诉浏览者该页是哪里出了问题。
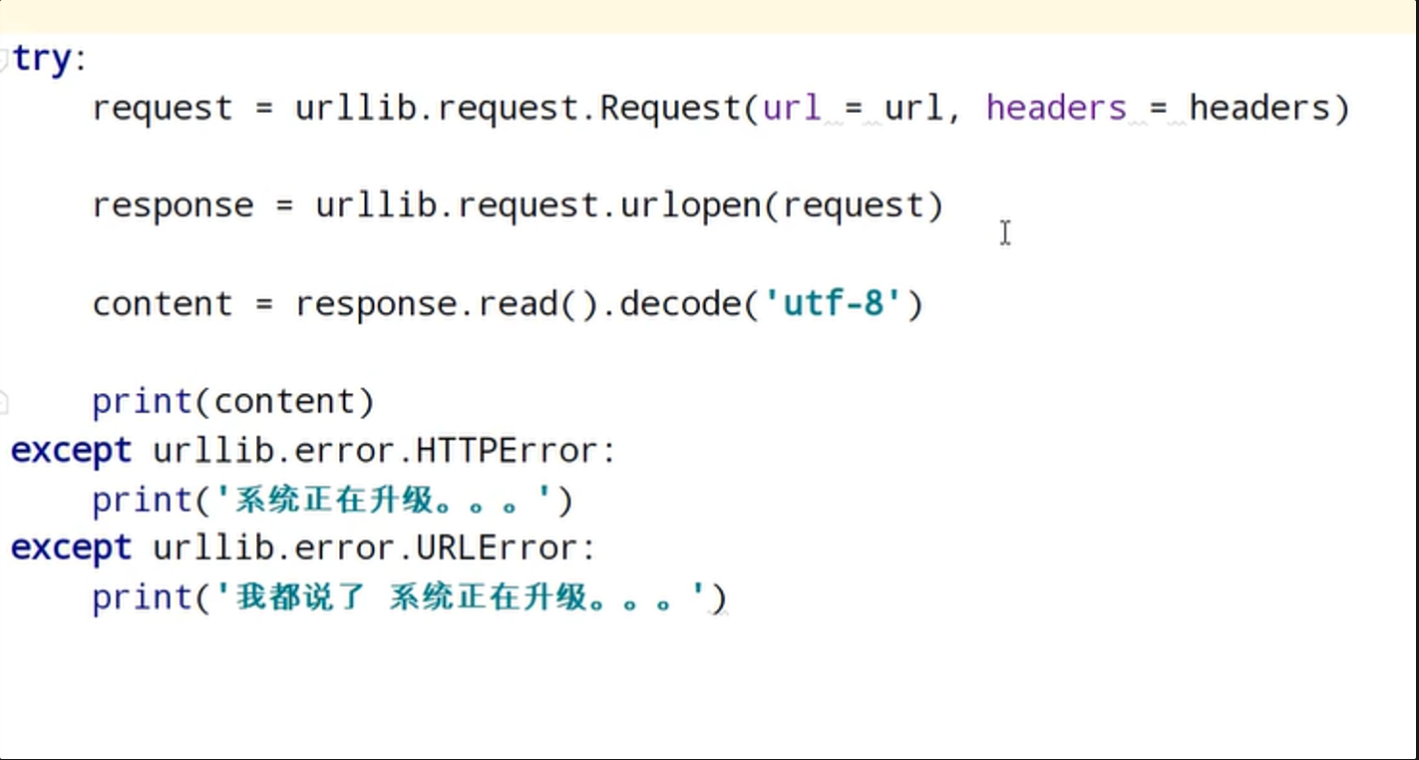
4.通过urllib发送请求的时候,有可能会发送失败,这个时候如果想让你的代码更加的健壮,可以通过try-except进行捕获异常,异常有两类:URLError/HTTPError
捕获异常的代码可参考下图:
九、微博的cookie登录
登录https://weibo.cn/5915756025/info
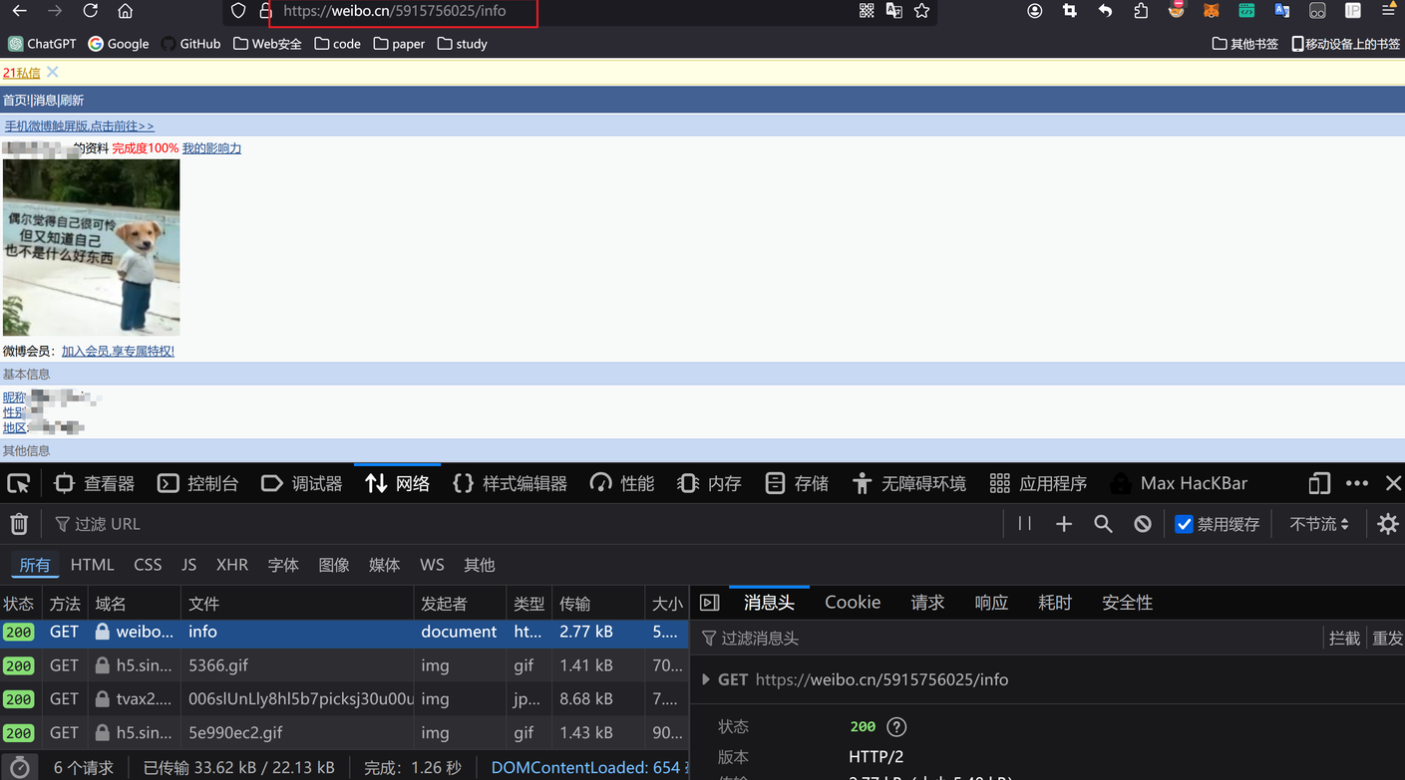
注意:URL中的那串数字根据自己的进行转换。当我们成功登录微博后,观察登陆成功的URL,得到上面所需要的那串数字
代码如下:
# 利用cookie获取微博登录页面
url='https://weibo.cn/5915756025/info'
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:128.0) Gecko/20100101 Firefox/128.0',
# 如果不带cookie,只能获得一直加载中的登录页面
'Cookie':'SCF=AuRE_quArNVh-RyQwgY_Mfyf1dQ9GXz5mpS5n6rPb4yrZ7pKGOaRqZ_TEjQo1ZKv0CUTDGSjai3FDr5cew5mnSM.; SUB=_2A25Lk7bsDeRhGeNH6lcW9SjMyTmIHXVo0LYkrDV6PUJbktAGLRj4kW1NSsw-pVvkP4MUFdoRPrVOGCv000hCGyH4; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9W5a32BT_aSyAG8TS1.P-hxi5NHD95Qf1K2fS0-cehzfWs4Dqcjai--Ri-8si-zNi--fi-2Xi-24i--fi-2Xi-24i--fi-ihiKn7i--fi-isiKn0PN.t; SSOLoginState=1721222844; ALF=1723814844; _T_WM=7dcb8e0c308d256e687e3e446561c97c'
}
request=urllib.request.Request(url=url,headers=headers)
response=urllib.request.urlopen(request)
content=response.read().decode('utf-8')
# print(content)
with open('weibo.html','w') as fp:
fp.write(content)
cookie中携带着你的登陆信息,如果有登陆之后的cookie,那么我们就可以携带着cookie进入到任何页面
学会爬取微博的个人信息页面后,我们也可以尝试爬取QQ空间的个人登录页面html代码,小提示:需要带上referer(判断当前路径是不是由上一个路径进来的)~
十、Handler处理器
Handler处理器:定制更高级的请求头。随着业务逻辑的复杂,请求对象的定制已经满足不了我们的需求(动态cookie和代理不能使用请求对象的定制)
基本使用方法如下:
Python爬虫(5-10)-编解码、ajax的get请求、ajax的post请求、URLError/HTTPError、微博的cookie登录、Handler处理器的更多相关文章
- python爬虫入门10分钟爬取一个网站
一.基础入门 1.1什么是爬虫 爬虫(spider,又网络爬虫),是指向网站/网络发起请求,获取资源后分析并提取有用数据的程序. 从技术层面来说就是 通过程序模拟浏览器请求站点的行为,把站点返回的HT ...
- 小白学 Python 爬虫(10):Session 和 Cookies
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 【听如子说】-python模块系列-AIS编解码Pyais
Pyais Module Introduce pyais一个简单实用的ais编解码模块 工作中需要和ais打交道,在摸鱼的过程中发现了一个牛逼的模块,对ais编解码感兴趣的可以拿项目学习一下,或者运用 ...
- python爬虫学习(10) —— 专利检索DEMO
这是一个稍微复杂的demo,它的功能如下: 输入专利号,下载对应的专利文档 输入关键词,下载所有相关的专利文档 0. 模块准备 首先是requests,这个就不说了,爬虫利器 其次是安装tessera ...
- python文件操作与编解码
1 # 文件操作 2 3 ''' 4 1.文件路径:要知道文件的路径 5 6 2.编码方式:要知道文件是什么编码的.utf-8 gbk...... 7 8 3.操作方式:要以什么样的方式进行打开这个文 ...
- python爬虫(10)--PyQuery的用法
简介 pyquery 可让你用 jQuery 的语法来对 xml 进行操作.这I和 jQuery 十分类似.如果利用 lxml,pyquery 对 xml 和 html 的处理将更快. 初始化 在这里 ...
- 【python爬虫】加密代理IP的使用与设置一套session请求头
1:代理ip请求,存于redis: # 请求ip代理连接,更新redis的代理ip def proxy_redis(): sr = redis.Redis(connection_pool=Pool) ...
- 小白学 Python 爬虫(19):Xpath 基操
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(32):异步请求库 AIOHTTP 基础入门
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(28):自动化测试框架 Selenium 从入门到放弃(下)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
随机推荐
- Git三大区域
1.工作区 2.暂存区 3.版本库
- CF437E The Child and Polygon
The Child and Polygon 题解 这世界这么大,遇到了这个奇奇怪怪的题. 这道题其实可以很自然的联想到卡特兰数. 在卡特兰数的计数中,有这么一个意义:\(C_n\) 表示把有 \(n+ ...
- Python BeautifulSoup定位取值
-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-* ...
- 使用 Java 客户端通过 HTTPS 连接到 Easysearch
Easysearch 一直致力于提高易用性,这也是我们的核心宗旨,然而之前一直没有官方的 Java 客户端,也对用户使用造成了一些困扰,现在,我们正式发布了第一个 Java 客户端 Easysearc ...
- 别想宰我,怎么查看云厂商是否超卖?详解 cpu steal time
据说有些云厂商会超卖,宿主有 96 个核心,结果卖出去 100 多个 vCPU,如果这些虚机负载都不高,大家相安无事,如果这些虚机同时运行一些高负载的任务,相互之间就会抢占 CPU,对应用程序有较大影 ...
- @RequestMapping 注解用在类上面有什么作用?
是一个用来处理请求地址映射的注解,可用于类或方法上.用于类上,表示类中的所有响应请求的方法都是以该地址作为父路径.
- MapStruct - 注解汇总
@Mapper @Mapper 将接口或抽象类标记为映射器,并自动生成映射实现类代码. public @interface Mapper { // 引入其他其他映射器 Class<?>[] ...
- 有点东西,template可以直接使用setup语法糖中的变量原来是因为这个
前言 我们每天写vue3代码的时候都会使用到setup语法糖,那你知道为什么setup语法糖中的顶层绑定可以在template中直接使用的呢?setup语法糖是如何编译成setup函数的呢?本文将围绕 ...
- ansible v2.9.9离线安装脚本
链接:https://pan.baidu.com/s/18uxyWWyJ39i1mJJ1hb8zww?pwd=QWSC 提取码:QWSC
- JAVA-poi导出excel到http响应流
导出结果为excel是相对常见的业务需求,大部分情况下只需要导出简单的格式即可,所以有许多可以采用的方案.有些方案还是很容易实现的. 一.可用的解决方案 目前可以有几类解决方案: 字处理企业提供的解决 ...