Python爬虫(5-10)-编解码、ajax的get请求、ajax的post请求、URLError/HTTPError、微博的cookie登录、Handler处理器
五、编解码(Unicode编码)
(1)GET请求
所提方法都在
urllib.parse.路径下
- get请求的
quote()方法(适用于只提交一两个参数值)
url='http://www.baidu.com/baidu?ie=utf-8&wd='
# 对汉字进行unicode编码
name=urllib.parse.quote('白敬亭')
url+=name
- get请求的
urlencode()方法(适用于提交多个参数)
base_url='http://www.baidu.com/baidu?'
data={
'wd':'白敬亭',
'sex':'男',
'address':'中国'
}
new_data=urllib.parse.urlencode(data)
url=base_url+new_data
(2)POST请求
百度翻译
1.以百度翻译为例,输入需翻译的单词后,点击”检查”—”网络”,发现存在多个名为sug的文件
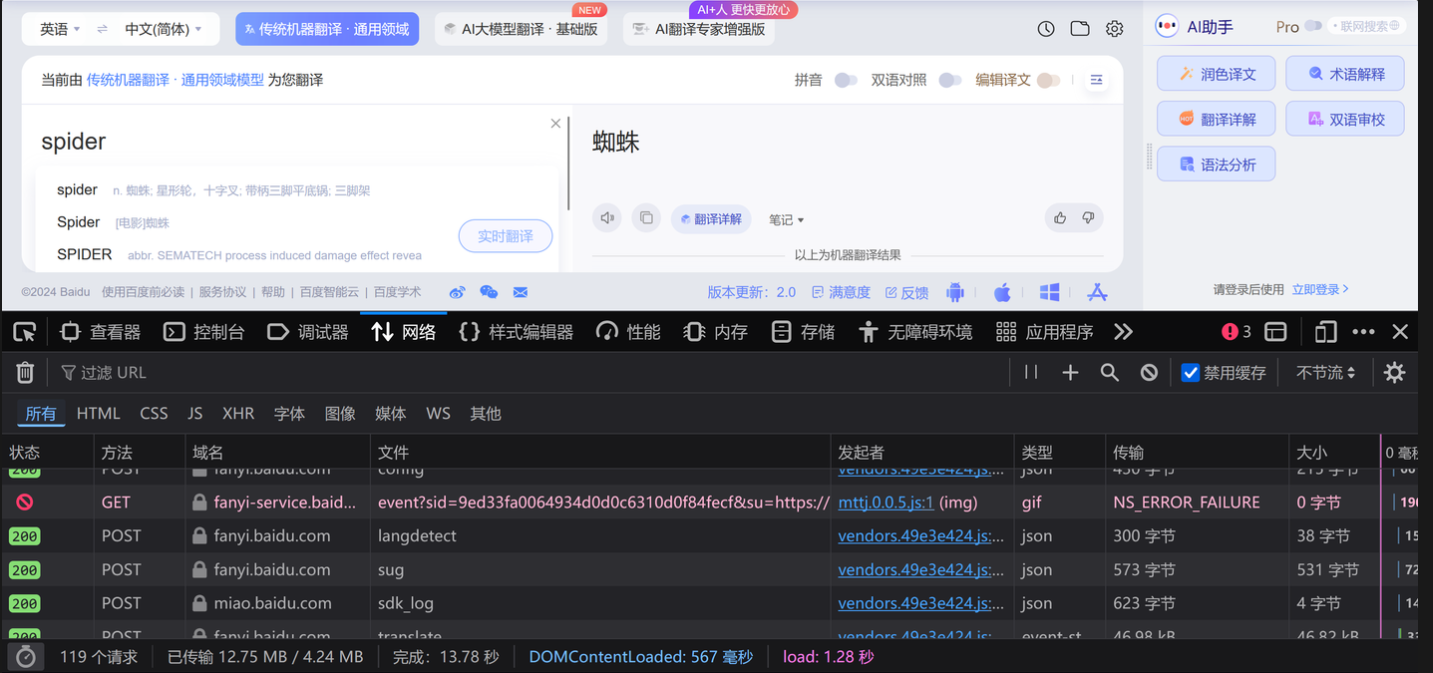
2.找到最后一个名为sug的文件,观察其请求和响应,发现就是我们要找的接口URL
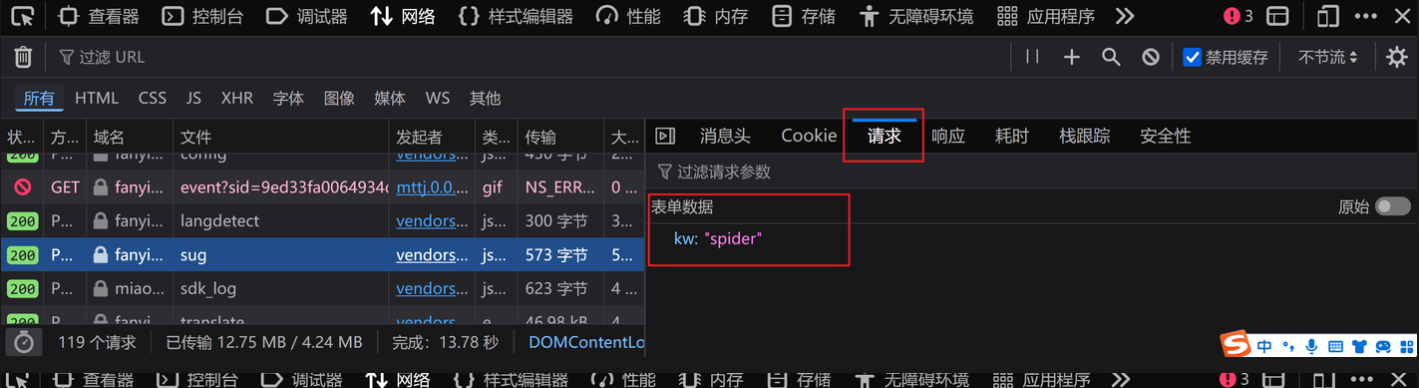
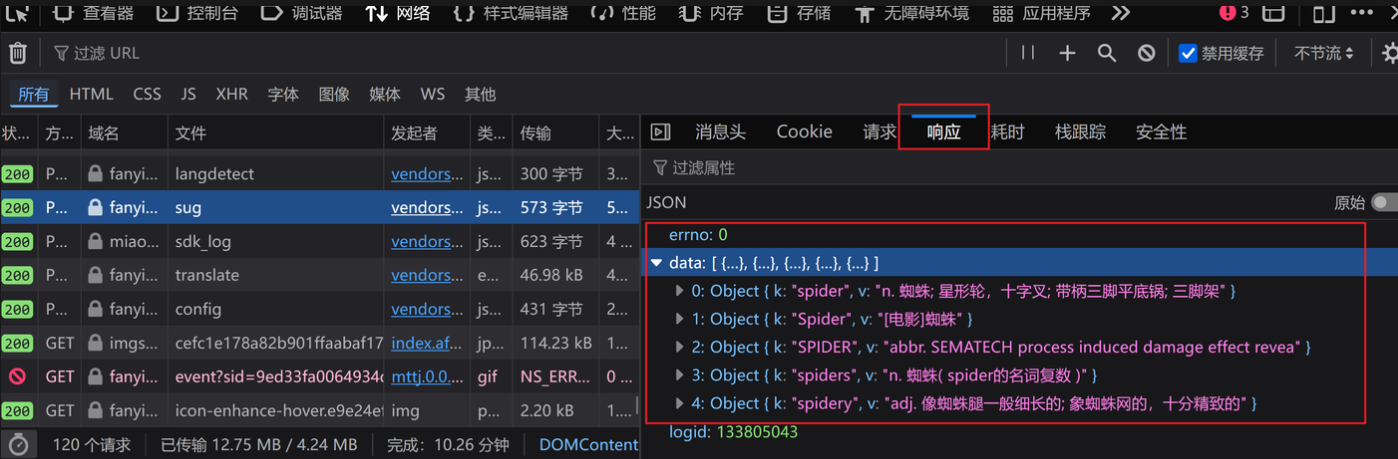
3.代码如下
# post请求百度翻译
url='https://fanyi.baidu.com/sug'
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:128.0) Gecko/20100101 Firefox/128.0'
}
data={
'kw':'spider'
}
# post请求的参数必须进行编码,转为字节型
# post的请求的参数是不会拼接在URL的后面的,而是需要放在清求对象定制的参数中
data=urllib.parse.urlencode(data).encode('utf-8')
request=urllib.request.Request(url=url,data=data,headers=headers)
response=urllib.request.urlopen(request)
content=response.read().decode('utf-8')
import json
# 将json字符串变为python对象
obj=json.loads(content)
print(obj)
4.总结
post请求方式的参数必须进行编码- 编码之后必须调用
encode()方法 - 参数要放在请求对象定制的方法中
六、ajax的get请求
(1)获取豆瓣电影的第一页的数据
1.打开“豆瓣电影”—“排行榜”—“喜剧”,找到接口(也就是找到某一个东西,该东西能展现当前页面的数据),由“响应”可以判断出所需的url
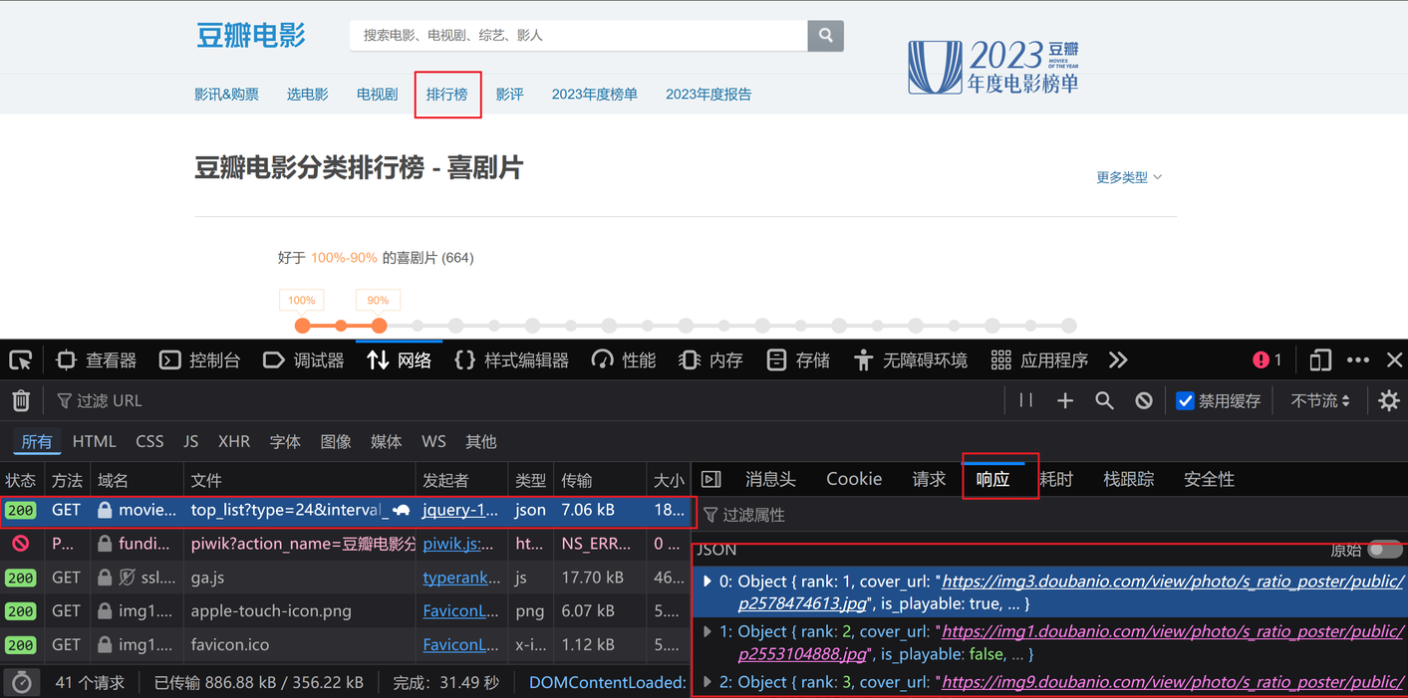
2.保存豆瓣电影的第一页的数据的代码如下:
import urllib.request
# ajax的get请求
# 获取豆瓣电影的第一页的数据并且保存起来
url='https://movie.douban.com/j/chart/top_list?type=24&interval_id=100:90&action=&start=0&limit=20'
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:128.0) Gecko/20100101 Firefox/128.0'
}
request=urllib.request.Request(url=url,headers=headers)
response=urllib.request.urlopen(request)
content=response.read().decode('utf-8')
# print(content)
# open方法默认情况下使用的是gbk的编码
# 使用UTF-8编码方式打开/创建名为douban.json文件
# 法一
fp=open('douban.json','w',encoding='utf-8')
fp.write(content)
# 法二
with open('douban1.json','w') as fp:
fp.write(content)
在法二中,with 语句用于管理文件对象的打开和关闭。as 关键字用于给文件对象取一个别名,这里是fp。fp.write(): 这是文件对象的一个方法,用于向文件中写入内容。
(2)获取豆瓣电影前十页的数据
1.观察可发现,URL中start的规律,start=(page-1)*20
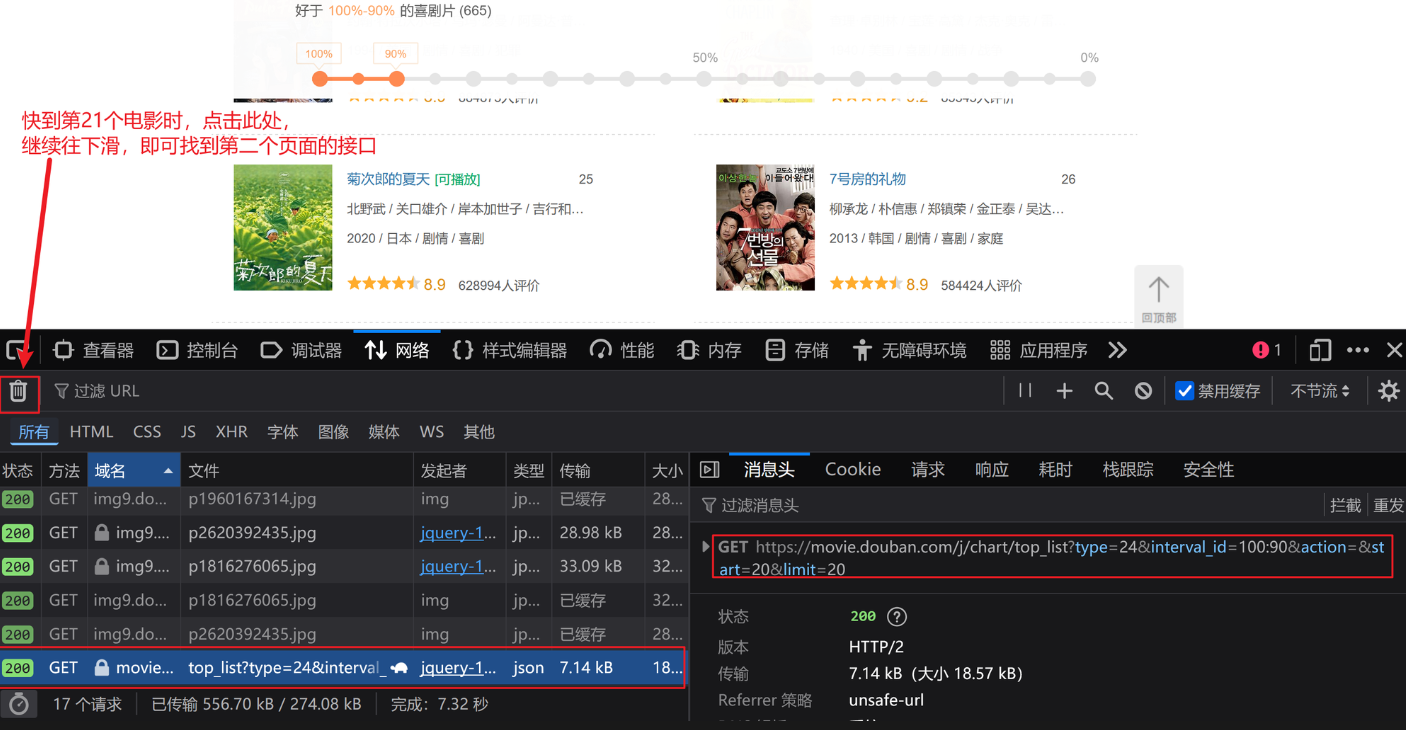
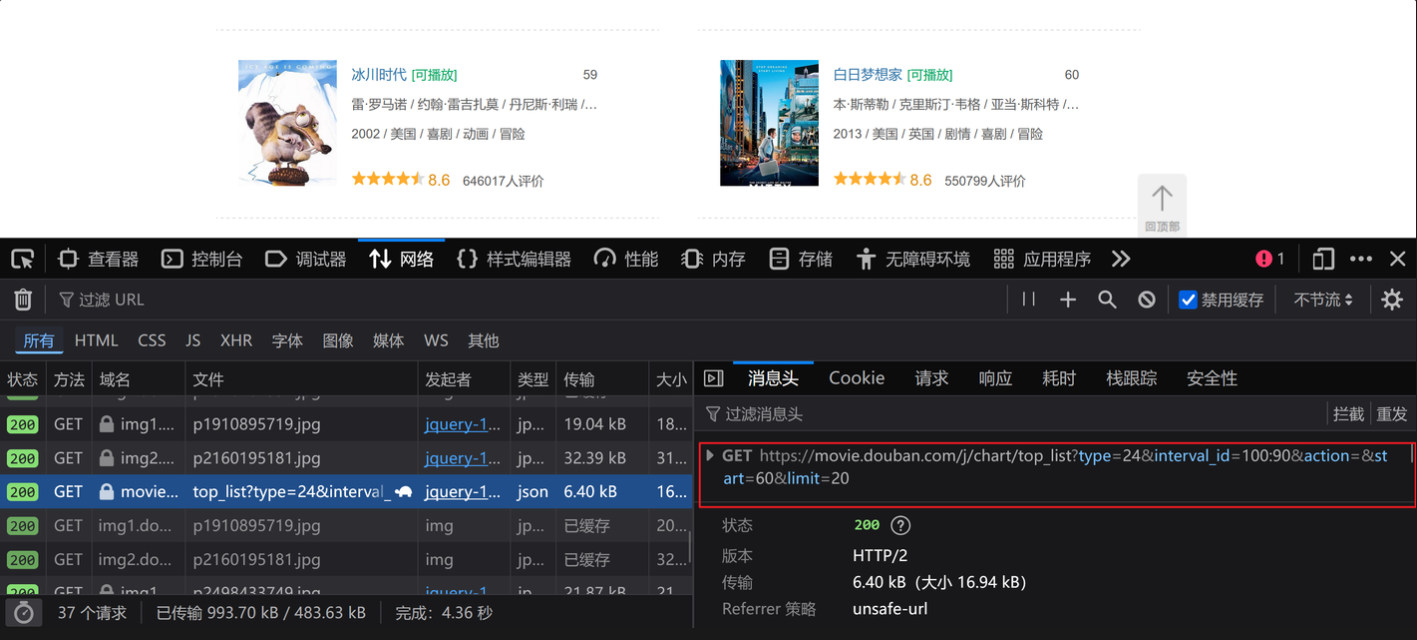
2.代码展示如下
# 获取豆瓣电影的前十页数据并且保存起来
def create_request(page):
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:128.0) Gecko/20100101 Firefox/128.0'
}
url='https://movie.douban.com/j/chart/top_list?'
data={
"type": 24,
"interval_id": "100:90",
"action": "",
# 观察可得start的规律
"start": (page-1)*20,
"limit": 20
}
new_data=urllib.parse.urlencode(data)
url+=new_data
request=urllib.request.Request(url=url,headers=headers)
return request
def get_content(request):
response=urllib.request.urlopen(request)
content=response.read().decode('utf-8')
return content
def load_content(page,content):
# 要将整形变量page转变为字符串
# 如果直接加单引号,page被当作一个字面量字符串,而不是变量page
with open('douban_'+str(page)+'.json','w') as fp:
fp.write(content)
# 程序的入口
if __name__=='__main__':
start_page=int(input('请输入开始的页码'))
end_page=int(input('请输入结束的页码'))
for page in range(start_page,end_page):
request=create_request(page)
content=get_content(request)
load_content(page,content)
七、ajax的post请求
1.观察发现”kfc官网“-”餐厅查询“网页的接口

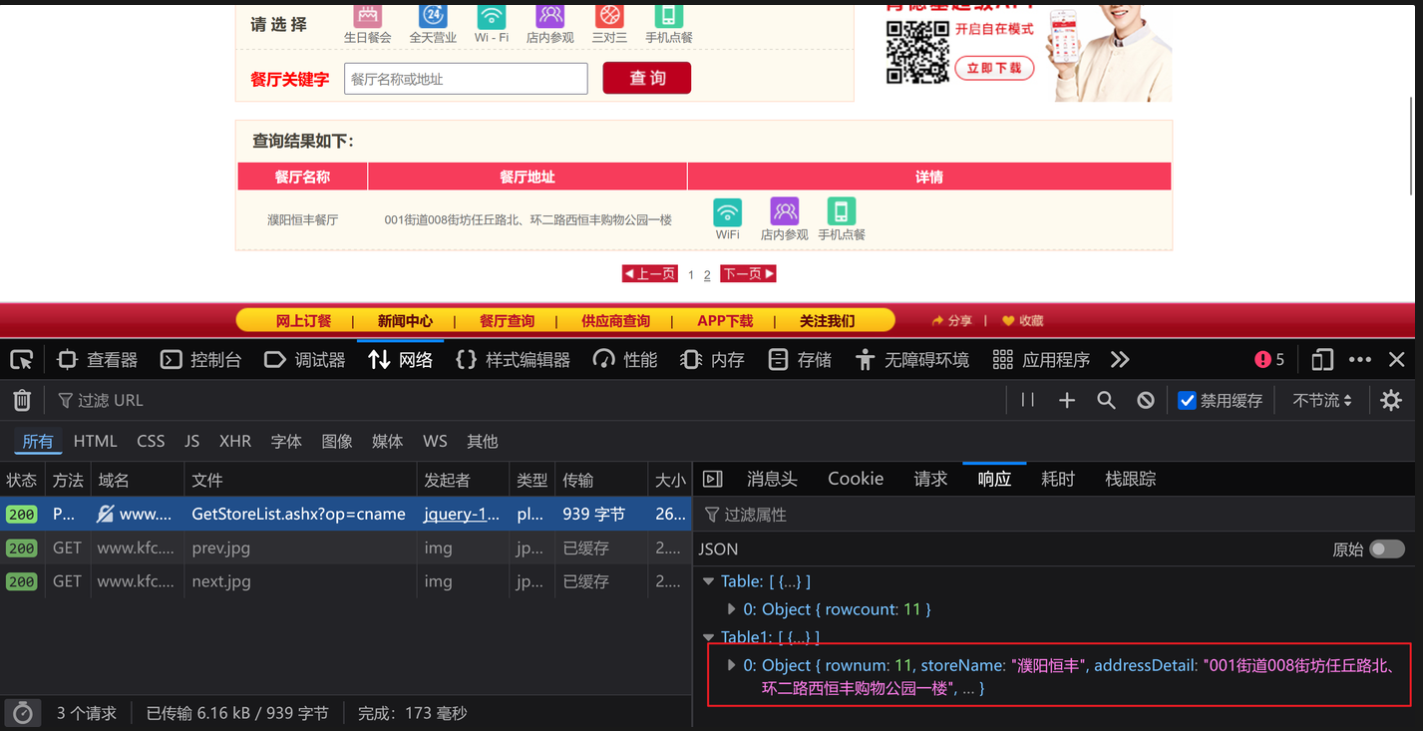
2.代码如下
# ajax的post请求--肯德基官网
def create_request(page):
url='http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
data={
'cname':'濮阳',
'pid':'',
'pageIndex':page,
'pageSize':10
}
new_data=urllib.parse.urlencode(data).encode('utf-8')
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:128.0) Gecko/20100101 Firefox/128.0'
}
# post方式不能直接拼接,要在请求对象定制的方法中加入该参数
request=urllib.request.Request(url=url,headers=headers,data=new_data)
return request
def get_content(request):
response=urllib.request.urlopen(request)
content=response.read().decode('utf-8')
return content
def load_content(page,content):
with open('kendeji'+str(page)+'.json','w',encoding='utf-8') as fp:
fp.write(content)
if __name__=='__main__':
start_page=int(input('请输入起始页码'))
end_page=int(input('请输入终止页码'))
for page in range(start_page,end_page):
request=create_request(page)
content=get_content(request)
print(f"页面 {page} 的内容: {content}")
# load_content(page,content)
八、URLError/HTTPError
简介:1.
HTTPError类是URLError类的子类
2.导入的包urllib.error.HTTPError或urllib.error.URLError
3.http错误:http错误是针对浏览器无法连接到服务器而增加出来的错误提示。引导并告诉浏览者该页是哪里出了问题。
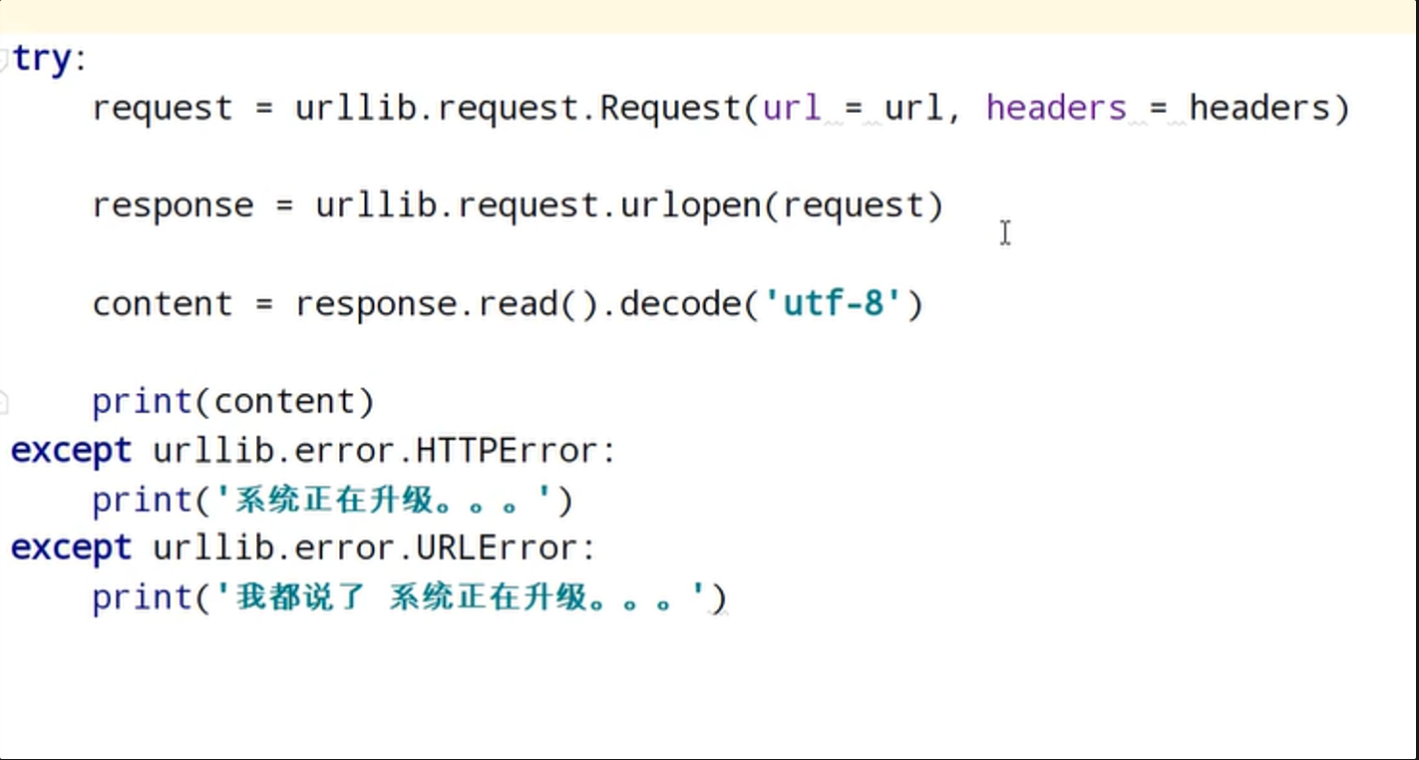
4.通过urllib发送请求的时候,有可能会发送失败,这个时候如果想让你的代码更加的健壮,可以通过try-except进行捕获异常,异常有两类:URLError/HTTPError
捕获异常的代码可参考下图:
九、微博的cookie登录
登录https://weibo.cn/5915756025/info
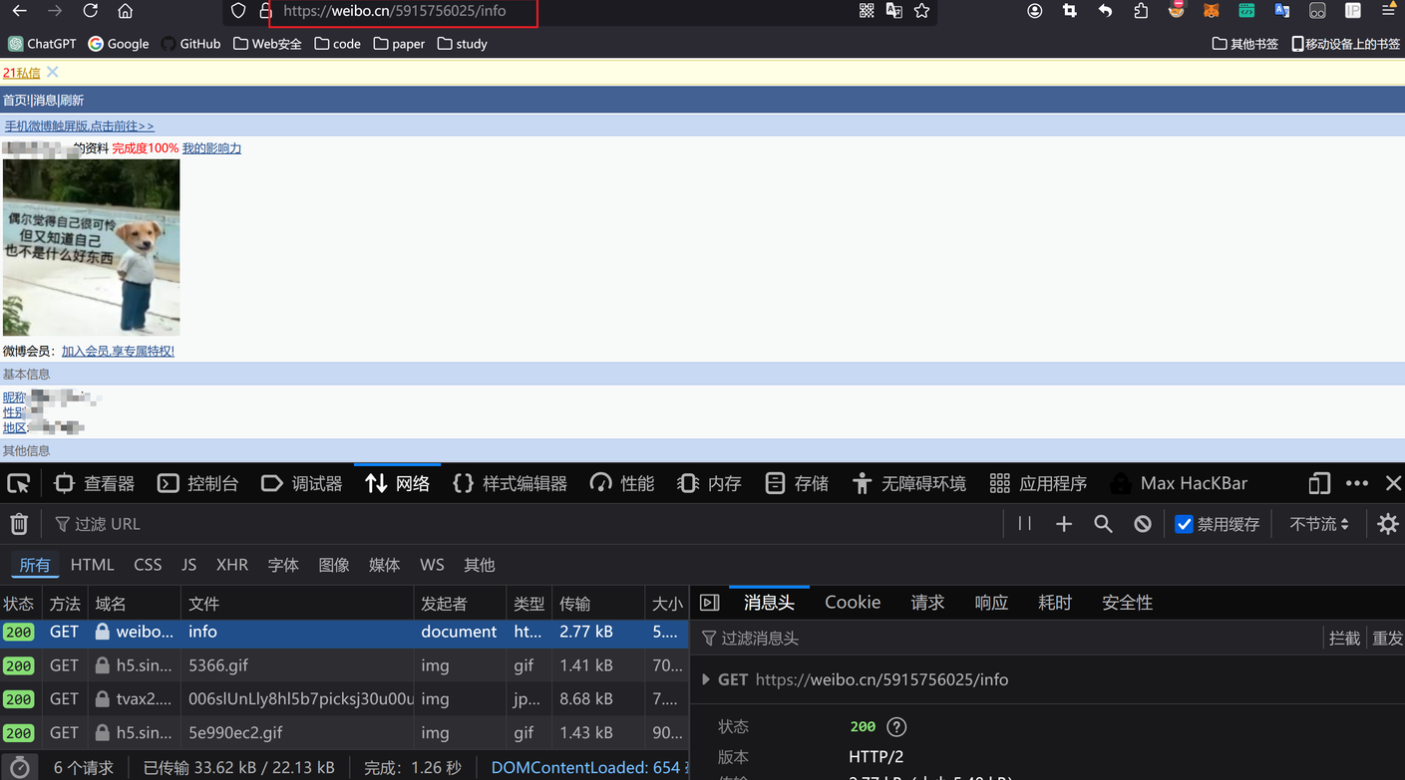
注意:URL中的那串数字根据自己的进行转换。当我们成功登录微博后,观察登陆成功的URL,得到上面所需要的那串数字
代码如下:
# 利用cookie获取微博登录页面
url='https://weibo.cn/5915756025/info'
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:128.0) Gecko/20100101 Firefox/128.0',
# 如果不带cookie,只能获得一直加载中的登录页面
'Cookie':'SCF=AuRE_quArNVh-RyQwgY_Mfyf1dQ9GXz5mpS5n6rPb4yrZ7pKGOaRqZ_TEjQo1ZKv0CUTDGSjai3FDr5cew5mnSM.; SUB=_2A25Lk7bsDeRhGeNH6lcW9SjMyTmIHXVo0LYkrDV6PUJbktAGLRj4kW1NSsw-pVvkP4MUFdoRPrVOGCv000hCGyH4; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9W5a32BT_aSyAG8TS1.P-hxi5NHD95Qf1K2fS0-cehzfWs4Dqcjai--Ri-8si-zNi--fi-2Xi-24i--fi-2Xi-24i--fi-ihiKn7i--fi-isiKn0PN.t; SSOLoginState=1721222844; ALF=1723814844; _T_WM=7dcb8e0c308d256e687e3e446561c97c'
}
request=urllib.request.Request(url=url,headers=headers)
response=urllib.request.urlopen(request)
content=response.read().decode('utf-8')
# print(content)
with open('weibo.html','w') as fp:
fp.write(content)
cookie中携带着你的登陆信息,如果有登陆之后的cookie,那么我们就可以携带着cookie进入到任何页面
学会爬取微博的个人信息页面后,我们也可以尝试爬取QQ空间的个人登录页面html代码,小提示:需要带上referer(判断当前路径是不是由上一个路径进来的)~
十、Handler处理器
Handler处理器:定制更高级的请求头。随着业务逻辑的复杂,请求对象的定制已经满足不了我们的需求(动态cookie和代理不能使用请求对象的定制)
基本使用方法如下:
Python爬虫(5-10)-编解码、ajax的get请求、ajax的post请求、URLError/HTTPError、微博的cookie登录、Handler处理器的更多相关文章
- python爬虫入门10分钟爬取一个网站
一.基础入门 1.1什么是爬虫 爬虫(spider,又网络爬虫),是指向网站/网络发起请求,获取资源后分析并提取有用数据的程序. 从技术层面来说就是 通过程序模拟浏览器请求站点的行为,把站点返回的HT ...
- 小白学 Python 爬虫(10):Session 和 Cookies
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 【听如子说】-python模块系列-AIS编解码Pyais
Pyais Module Introduce pyais一个简单实用的ais编解码模块 工作中需要和ais打交道,在摸鱼的过程中发现了一个牛逼的模块,对ais编解码感兴趣的可以拿项目学习一下,或者运用 ...
- python爬虫学习(10) —— 专利检索DEMO
这是一个稍微复杂的demo,它的功能如下: 输入专利号,下载对应的专利文档 输入关键词,下载所有相关的专利文档 0. 模块准备 首先是requests,这个就不说了,爬虫利器 其次是安装tessera ...
- python文件操作与编解码
1 # 文件操作 2 3 ''' 4 1.文件路径:要知道文件的路径 5 6 2.编码方式:要知道文件是什么编码的.utf-8 gbk...... 7 8 3.操作方式:要以什么样的方式进行打开这个文 ...
- python爬虫(10)--PyQuery的用法
简介 pyquery 可让你用 jQuery 的语法来对 xml 进行操作.这I和 jQuery 十分类似.如果利用 lxml,pyquery 对 xml 和 html 的处理将更快. 初始化 在这里 ...
- 【python爬虫】加密代理IP的使用与设置一套session请求头
1:代理ip请求,存于redis: # 请求ip代理连接,更新redis的代理ip def proxy_redis(): sr = redis.Redis(connection_pool=Pool) ...
- 小白学 Python 爬虫(19):Xpath 基操
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(32):异步请求库 AIOHTTP 基础入门
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(28):自动化测试框架 Selenium 从入门到放弃(下)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
随机推荐
- python377和python27的区别?
python27无法解释print(1,2,3,sep="*"),Windows命令行窗口运行会报语法错误:无效语法 SyntaxError:invalid syntax pyt ...
- WPF 滚动条ScrollViewer样式记录
WPF 应用程序中有两个支持滚动的预定义元素:ScrollBar 和 ScrollViewer. ScrollViewer 控件封装了水平和垂直 ScrollBar 元素以及一个内容容器(如 Pane ...
- 机器学习策略篇:详解可避免偏差(Avoidable bias)
可避免偏差 如果希望学习算法能在训练集上表现良好,但有时实际上并不想做得太好.得知道人类水平的表现是怎样的,可以确切告诉算法在训练集上的表现到底应该有多好,或者有多不好,让我说明是什么意思吧. 经常使 ...
- zabbix笔记_001
zabbix介绍 zabbix是一个基于WEB界面的提供分布式系统监视以及网络监视功能的企业级的开源解决方案. zabbix能监视各种网络参数,保证服务器系统的安全运营:并提供灵活的通知机制以让系统管 ...
- CSP-S2021 游记
那天是惊蛰 满天花瓣 就像现在 我看清了无池里的那个人 前言 终于是开了 游记 的坑(期盼已久!) 虽然参加过 CSP-J2019 ,CSP-S2020 以及 NOIP2020 ,但是都没有写过游记( ...
- itest(爱测试)开源接口测试&敏捷测试&极简项目管理 8.0.0 发布,测试重大升级
(一)itest 简介及更新说明 itest 开源敏捷测试管理,testOps 践行者,极简的任务管理,测试管理,缺陷管理,测试环境管理,接口测试,接口Mock 6合1,又有丰富的统计分析.可按测试包 ...
- js 留言板(带删除功能)
本文所用的知识点:创建节点和添加节点 创建节点:document.createElement('li') 添加节点 node(父亲节点).appendChild(child) child:子节 ...
- 系统镜像烧写及U-Boot编译
1 系统镜像烧写 1.1 工具介绍 烧写软件:使用NXP的MfgTool2工具烧写,工具路径:[正点原子]阿尔法Linux开发板(A盘)-基础资料\05.开发工具\04.正点原子MFG_TOOL出厂固 ...
- RT-Thread Studio使用教程
介绍 RT-Thread Studio是官方出品的一款专门针对RT-Thread嵌入式开发.部署.调试.测试的集成开发环境,它基于Eclipse开源项目开发,极大的提高了嵌入式开发者的开发效率,目前最 ...
- INFINI Gateway 如何防止大跨度查询
背景 业务每天生成一个日期后缀的索引,写入当日数据. 业务查询有时会查询好多天的数据,导致负载告警. 现在想对查询进行限制--只允许查询一天的数据(不限定是哪天),如果想查询多天的数据就走申请. 技术 ...