日处理数据量超10亿:友信金服基于Flink构建实时用户画像系统的实践
导读:当今生活节奏日益加快,企业面对不断增加的海量信息,其信息筛选和处理效率低下的困扰与日俱增。由于用户营销不够细化,企业 App 中许多不合时宜或不合偏好的消息推送很大程度上影响了用户体验,甚至引发了用户流失。在此背景下,友信金服公司推行全域的数据体系战略,通过打通和整合集团各个业务线数据,利用大数据、人工智能等技术构建统一的数据资产,如 ID-Mapping、用户标签等。友信金服用户画像项目正是以此为背景成立,旨在实现“数据驱动业务与运营”的集团战略。目前该系统支持日处理数据量超 10 亿,接入上百种合规数据源。
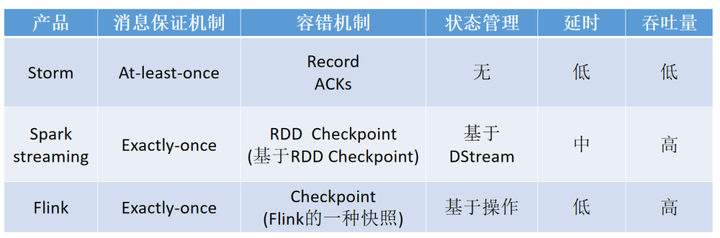
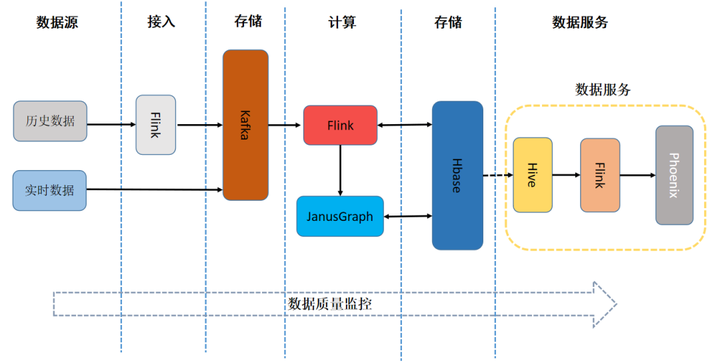
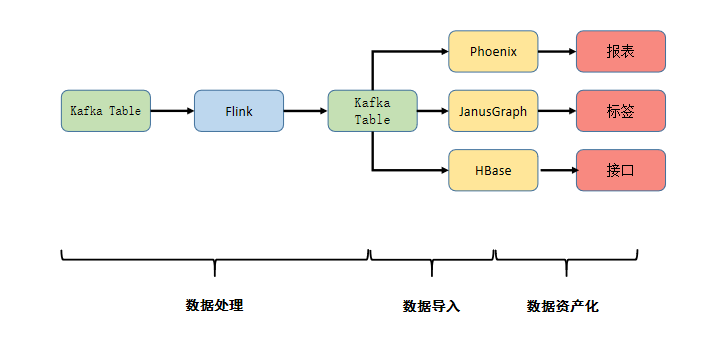
- 接入层:接入原始数据并对其进行处理,如 Kafka、Hive、文件等。
- 计算层:选用 Flink 作为实时计算框架,对实时数据进行清洗,关联等操作。
- 存储层:对清洗完成的数据进行数据存储,我们对此进行了实时用户画像的模型分层与构建,将不同应用场景的数据分别存储在如 Phoenix,HBase,HDFS,Kafka 等。
- 服务层:对外提供统一的数据查询服务,支持从底层明细数据到聚合层数据的多维计算服务。
- 应用层:以统一查询服务对各个业务线数据场景进行支撑。目前业务主要包含用户兴趣分、用户质量分、用户的事实信息等数据。
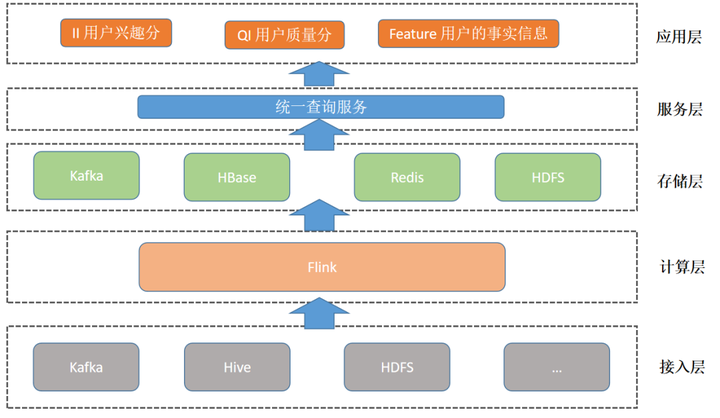
- 历史数据:从外部数据源接入的海量历史业务数据。接入后经过 ETL 处理,进入用户画像底层数据表。
- 实时数据:从外部数据源接入的实时业务数据,如用户行为埋点数据,风控数据等。
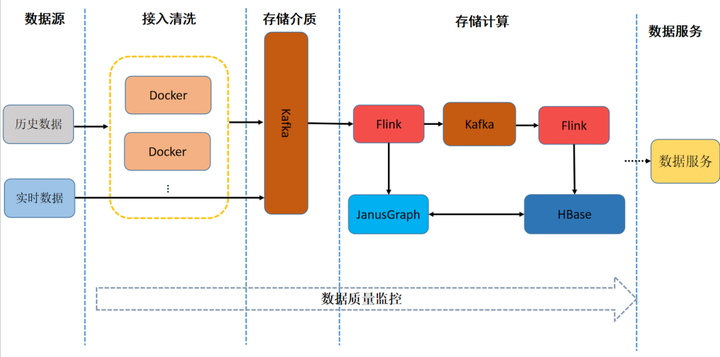
- 首先,这版的数据处理使用了自研的 Java 程序来实现。随着数据量上涨,自研 JAVA 程序由于数据量暴增导致 JVM 内存大小不可控,同时它的维护成本很高,因此我们决定在新版本中将处理逻辑全部迁移至 Flink 中。
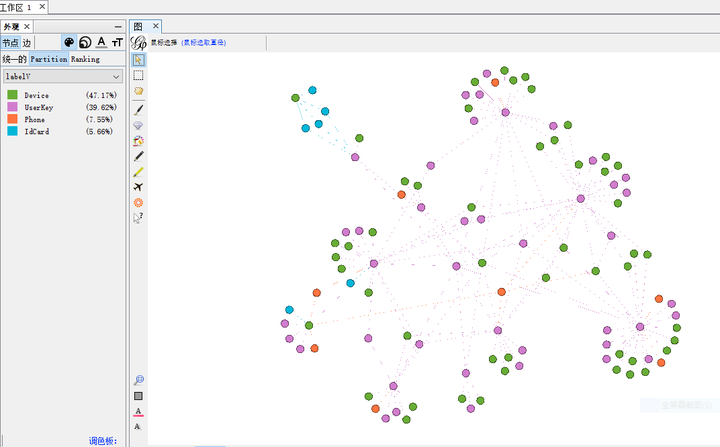
- 其次,在生成用户标签过程中,ID-Mapping 出现很多大的连通子图(如下图所示)。这通常是因为用户的行为数据比较随机离散,导致部分节点间连接混乱。这不仅增加了数据的维护难度,也导致部分数据被“污染”。另外这类异常大的子图会严重降低 JanusGraph 与 HBase 的查询性能。
- 最后,该版方案中数据经 Protocol Buffer(PB)序列化之后存入 HBase,这会导致合并 / 更新用户画像标签碎片的次数过多,使得一个标签需要读取多次 JanusGraph 与 HBase,这无疑会加重 HBase 读取压力。此外,由于数据经过了 PB 序列化,使得其原始存储格式不可读,增加了排查问题的难度。
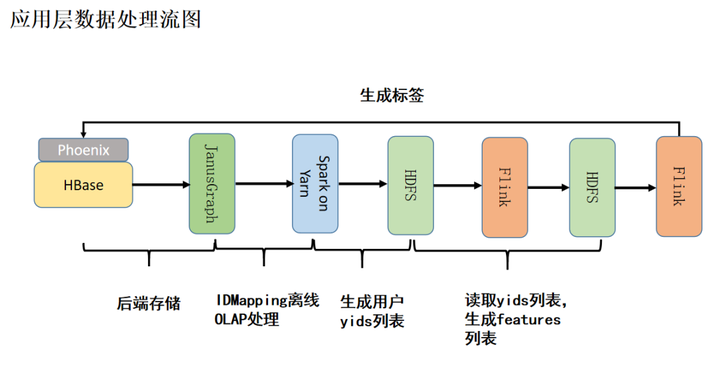
- 历史数据的离线补录方式由 JAVA 服务变更为使用 Flink 实现。
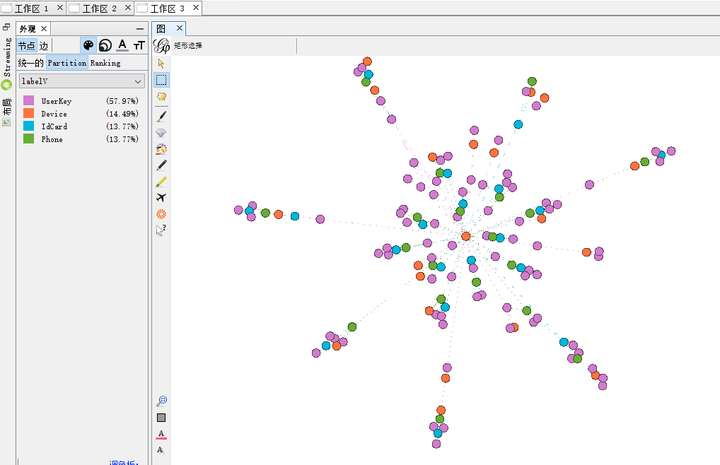
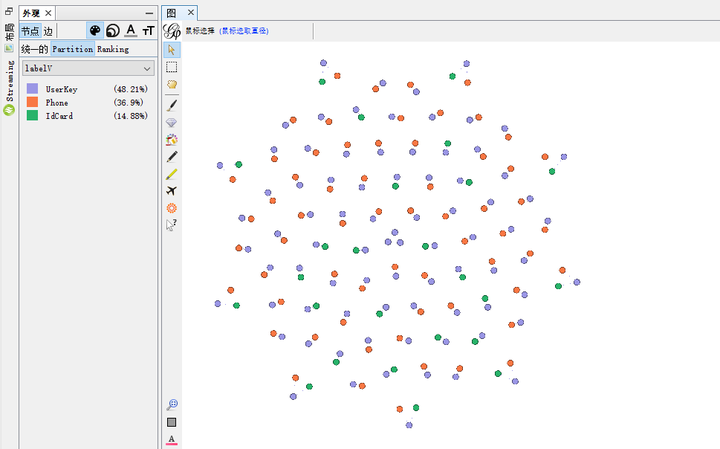
- 优化用户画像图数据结构模型,主要是对边的连接方式进行了修改。之前我们会判断节点的类型并根据预设的优先级顺序将多个节点进行连接,新方案则采用以 UserKey 为中心的连接方式。做此修改后,之前的大的连通子图(图 6)优化为下面的小的连通子图(图 8),同时解决了数据污染问题,保证了数据准确性。另外,1.0 版本中一条数据需要平均读取十多次 HBase 的情况也得到极大缓解。采用新方案之后平均一条数据只需读取三次 HBase,从而降低 HBase 六七倍的读取压力(此处优化是数据计算层优化)。
- 旧版本是用 Protocol Buffer 作为用户画像数据的存储对象,生成用户画像数据后作为一个列整体存入 HBase。新版本使用 Map 存储用户画像标签数据,Map 的每对 KV 都是单独的标签,KV 在存入 HBase 后也是单独的列。新版本存储模式利用 HBase 做列的扩展与合并,直接生成完整用户画像数据,去掉 Flink 合并 / 更新用户画像标签过程,优化数据加工流程。使用此方案后,存入 HBase 的标签数据具备了即席查询功能。数据具备即席查询是指在 HBase 中可用特定条件直接查看指定标签数据详情的功能,它是数据治理可以实现校验数据质量、数据生命周期、数据安全等功能的基础条件。
- 在数据服务层,我们利用 Flink 批量读取 HBase 的 Hive 外部表生成用户质量分等数据,之后将其存入 Phoenix。相比于旧方案中 Spark 全量读 HBase 导致其读压力过大,从而会出现集群节点宕机的问题,新方案能够有效地降低 HBase 的读取压力。经过我们线上验证,新方案对 HBase 的读负载下降了数十倍(此处优化与 2 优化不同,属于服务层优化)。
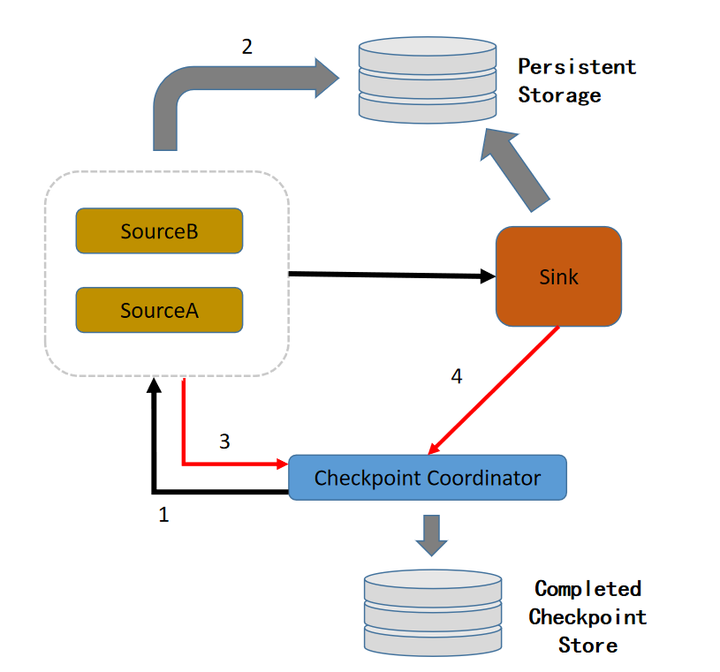
- Coordinator 向所有 Source 节点发出 Barrier。
- Task 从输入中收到所有 Barrier 后,将自己的状态写入持久化存储中,并向自己的下游继续传递 Barrier。
- 当 Task 完成状态持久化之后将存储后的状态地址通知到 Coordinator。
- 当 Coordinator 汇总所有 Task 的状态,并将这些数据的存放路径写入持久化存储中,完成 CheckPointing。
- 选择合适的 Checkpoint 存储方式
- 合理增加算子(Task)并行度
- 缩短算子链(Operator Chains)长度
- 上下游的并行度一致
- 下游节点的入度为 1
- 上下游节点都在同一个 Slot Group 中
- 下游节点的 Chain 策略为 ALWAYS
- 上游节点的 Chain 策略为 ALWAYS 或 HEAD
- 两个节点间数据分区方式是 Forward
- 用户没有禁用 Chain
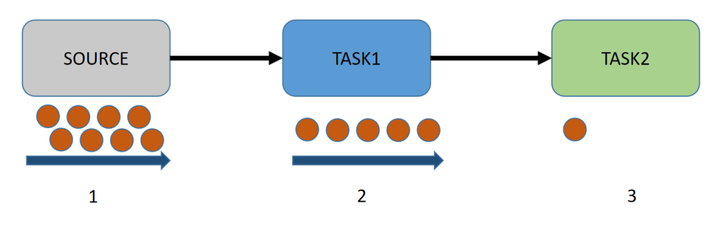
- 下游算子处理能力不足;
- 数据发生了倾斜。
日处理数据量超10亿:友信金服基于Flink构建实时用户画像系统的实践的更多相关文章
- 【转帖】影响超 10 亿设备,博通和 Cypress 芯片曝惊天漏洞,苹果、华为、三星等中招
影响超 10 亿设备,博通和 Cypress 芯片曝惊天漏洞,苹果.华为.三星等中招 https://www.infoq.cn/article/lpNEQGrxZL22gHDPBE2z 26 ...
- 【Spark深入学习 -10】基于spark构建企业级流处理系统
----本节内容------- 1.流式处理系统背景 1.1 技术背景 1.2 Spark技术很火 2.流式处理技术介绍 2.1流式处理技术概念 2.2流式处理应用场景 2.3流式处理系统分类 3.流 ...
- C#将dataGridView中显示的数据导出到Excel(大数据量超有用版)
开发中非常多情况下须要将dataGridView控件中显示的数据结果以Excel或者Word的形式导出来,本例就来实现这个功能. 因为从数据库中查找出某些数据列可能不是必需显示出来,在dataGrid ...
- Elasticsearch 对于大数据量(上亿量级)的聚合如何实现?
Elasticsearch 提供的首个近似聚合是 cardinality 度量.它提供一个字段的基数, 即该字段的 distinct 或者 unique 值的数目.它是基于 HLL 算法的.HLL 会 ...
- 浅谈PageHelper插件分页实现原理及大数据量下SQL查询效率问题解决
前因:项目一直使用的是PageHelper实现分页功能,项目前期数据量较少一直没有什么问题.随着业务扩增,数据库扩增PageHelper出现了明显的性能问题.几十万甚至上百万的单表数据查询性能缓慢,需 ...
- MERGE INTO 解决大数据量 10w 更新缓慢的问题
有个同事处理更新数据缓慢的问题,数据量超10w的量,更新速度太慢耗时较长,然后改成了 MERGE INTO 效率显著提高. 使用方法如下 MERGE INTO 表A USING 表B ON 关联条件 ...
- SQL Server 大数据量insert into xx select慢的解决方案
最近项目有个需求,把一张表中的数据根据一定条件增删改到另外一张表.按理说这是个很简单的SQL.可是在实际过程中却出现了超级长时间的执行过程. 后来经过排查发现是大数据量insert into xx s ...
- Linux服务器程序--大数据量高并发系统设计
在Linux服务器程序中,让系统能够提供以更少的资源提供更多的并发和响应效率决定了程序设计价值!怎样去实现这个目标,它其实是这么多年以来一直追逐的东西.最开始写代码时候,省去一个条件语句.用 ...
- FineUIPro v3.5.0发布了,减少 90% 的上行数据量,15行代码全搞定!
一切为客户着想 一切的一切还得从和一位台湾客户的沟通说起: 客户提到将ViewState保存在服务器端以减少上行数据量,从而加快页面的回发速度. 但是在FineUI中,控件状态都保存在FState中, ...
- (转)利用WPF的ListView进行大数据量异步加载
原文:http://www.cnblogs.com/scy251147/archive/2012/01/08/2305319.html 由于之前利用Winform的ListView进行大数据量加载的时 ...
随机推荐
- Atom 编辑器实时预览 HTML 页面经典方法
为什么需要这样一个工具? 每次预览 HTML 页面,都需要打开各种浏览器:哪怕不是调试,只是为了查看下效果:切换来切换去,各种刷新,感觉有些浪费时间:以前用过 DW 的实时预览,感觉这个功能很赞: ...
- Linux Char-Driver (字符驱动 摘要)(一)
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 前置说明 本文作为本人csdn blog的主站的备份.(Bl ...
- OkHttp请求耗时统计
目录介绍 01.先提问一个问题 02.EventListener回调原理 03.请求开始结束监听 04.dns解析开始结束监听 05.连接开始结束监听 06.TLS连接开始结束监听 07.连接绑定和释 ...
- 【Oracle】手动安装和卸载Oracle,这是最全的一篇了!!
写在前面 之前写过一篇在CentOS 7/8上安装Oracle的文章,按照我写的文章安装成功了,但是卸载Oracle时出现了问题.今天,我就整理一篇手动安装和卸载Oracle的文章吧.全文为实战型内容 ...
- vue项目,关闭eslint语法检测
vue.config.js文件中 module.exports = { lintOnSave:false //关闭语法检查 } 然后重启项目生效!
- KingbaseES中不同user之间的权限关系
1.概念 1.schema是每个database中特有的. schema概念有点像命名空间,这个逻辑空间包含若干表对象. 在DB里面,有了schema才可以创建对象,对象需要依赖于schema,默认为 ...
- C++设计模式 - 享元模式(Flyweight)
对象性能模式 面向对象很好地解决了"抽象"的问题,但是必不可免地要付出一定的代价.对于通常情况来讲,面向对象的成本大都可以忽略不计.但是某些情况,面向对象所带来的成本必须谨慎处理. ...
- #搜索,容斥#洛谷 2567 [SCOI2010]幸运数字
题目 问区间\([l,r],l,r\leq 10^{10}\)中有多少个数是 数位由6或8组成的数的倍数(包括本身) 分析 数位由6或8组成的数最多有两千多种, 这可以直接一遍暴搜得到 对于区间\([ ...
- 王莉:将开发文档英文化和本地化,我们努力让OpenHarmony走向全球
编者按:在 OpenHarmony 生态发展过程中,涌现了大批优秀的代码贡献者,本专题旨在表彰贡献.分享经验,文中内容来自嘉宾访谈,不代表 OpenHarmony 工作委员会观点. 王莉 华为技术有限 ...
- C# 通过ARP技术来观察目标主机数据包
由于之前写的C# 实现Arp欺诈的文章属于网络攻击,不能够被展示,所以这边我们稍微说一下C#调用ARP包以及查看其他电脑上网数据包的技术,委婉的说一下ARP在局域网之中的应用. 本文章纯属技术讨论,并 ...