论文解读(APCA)《Adaptive prototype and consistency alignment for semi-supervised domain adaptation》
[ Wechat:Y466551 | 付费咨询,非诚勿扰 ]
论文信息
论文标题:Adaptive prototype and consistency alignment for semi-supervised domain adaptation
论文作者:Jihong Ouyang、Zhengjie Zhang、Qingyi Meng
论文来源:2023 aRxiv
论文地址:download
论文代码:download
视屏讲解:click
1 介绍
2 问题定义
Formally, the semi-supervised domain adaptation scenario constitutes a labeled source domain $\mathcal{D}_{s}=\left\{\left(x_{i}^{s}, y_{i}^{s}\right)\right\}_{i=1}^{n_{s}}$ drawn from the distribution $P$ . For the target domain, a labeled set $\mathcal{D}_{t}=\left\{\left(x_{i}^{t}, y_{i}^{t}\right)\right\}_{i=1}^{n_{t}}$ and an unlabeled set $\mathcal{D}_{u}=\left\{x_{i}^{u}\right\}_{i=1}^{n_{u}}$ drawn from distribution $Q$ are given. The source and target domain are drawn from the same label space $y=\{1,2, \ldots, K\}$ . Usually, the number of labeled samples in $\mathcal{D}_{t}$ is minimal, e.g., one or three samples per class. SSDA aims to train the model on $\mathcal{D}_{s}$, $\mathcal{D}_{t}$ and $\mathcal{D}_{u}$ to correctly predict labels for samples in $\mathcal{D}_{u} $.
3 方法
3.1 模型框架
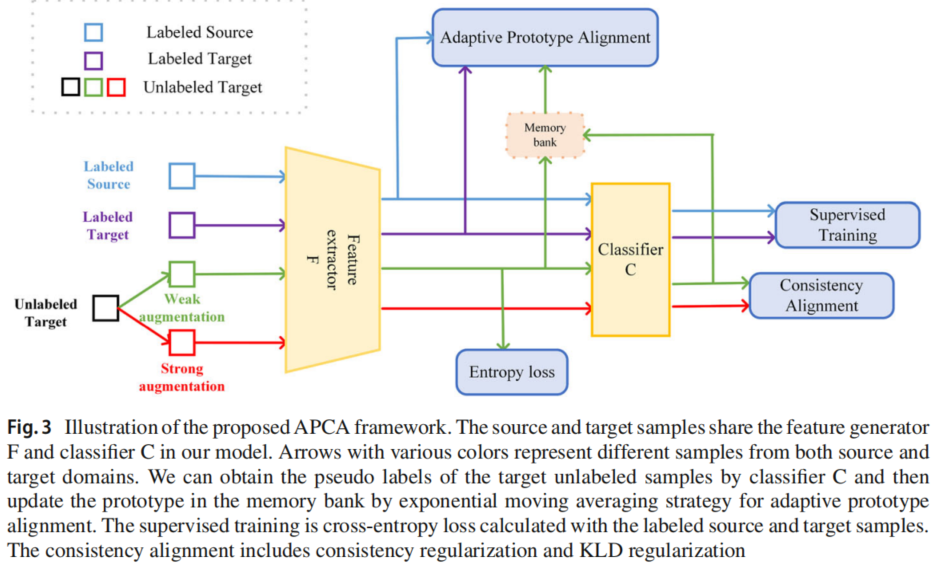
3.2 Supervised training
3.3 Adaptive prototype alignment
利用目标域代标记数据计算原型:
$\mathbf{c}_{k}^{\mathcal{T}}=\frac{1}{\left|\mathcal{D}_{k}\right|} \sum_{\left(x_{i}^{t}, y_{i}^{t}\right) \in \mathcal{D}_{k}} F\left(x_{i}^{t}\right)\quad\quad(3)$
利用目标域未带标记的数据计算原型(mini-batch级别):
$c_{k}^{u}=\frac{\sum_{i \in B_{t}} \mathbb{1}_{\left[k=\hat{y}_{i}\right]} F\left(x_{i}^{u}\right)}{\sum_{i \in B_{t}} \mathbb{1}_{\left[k=\hat{y}_{i}\right]}}\quad\quad(4)$
Note:目标域未带标记样本使用分类器给出伪标签;
$c_{k(m)}^{\mathcal{U}}=\eta c_{k}^{u}+(1-\eta) c_{k(m-1)}^{\mathcal{U}}\quad\quad(5)$
利用 EMA 修改用目标域未带标记样本计算的原型:
$c_{k(m)}^{\mathcal{U}}=\eta c_{k}^{u}+(1-\eta) c_{k(m-1)}^{\mathcal{U}}\quad\quad(6)$
目标域总的原型:
$c_{k}=\frac{\mathbf{c}_{k}^{\mathcal{T}}+c_{k(m)}^{\mathcal{U}}}{2}\quad\quad(7)$
对于源域带标记数据,可以通过目标类原型距离函数得到概率分布如下:
$p(y \mid x)=\frac{e^{-d\left(F(x), c_{y}\right)}}{\sum_{k} e^{-d\left(F(x), c_{k}\right)}}\quad\quad(8)$
然后,计算总体源样本的原型损失如下:
$\mathcal{L}_{A P A}=-\mathbb{E}_{\left(x_{i}^{s}, y_{i}^{s}\right) \in \mathcal{D}_{s}} \log p\left(y_{i}^{s} \mid x_{i}^{s}\right)\quad\quad(9)$
小结阐述:使用目标域数据(带、不带标记)计算目标域原型,然后预测源域样本的类别,并使用源域标签做监督;
3.4 Consistency alignment
如模型框架图所示,目标域未带标记数据被分为弱、强数据增强样本,对于弱数据增强样本,使用分类器得到硬标签,并计算交叉熵(基于阈值$\gamma$):
$\left.\ell_{c r}=-\mathbb{1}\left(\max \left(\mathbf{p}_{w}\right)>\tau\right) \log \mathbf{p}\left(y=\hat{p} \mid \mathcal{S}\left(x_{i}^{u}\right)\right)\right)\quad\quad(10)$
为了避免过拟合,使用多样性损失:
$\ell_{k l d}=-\mathbb{1}\left(\max \left(\mathbf{p}_{w}\right)>\tau\right) \sum_{k=1}^{C} \frac{1}{C} \log \mathbf{p}\left(y=k \mid \mathcal{S}\left(x_{i}^{u}\right)\right)\quad\quad(11)$
Note:KLD正则化鼓励预测结果接近均匀分布,从而使预测结果不会过拟合伪标签。
因此,一致性对齐模块的整体损失函数可以表示如下:
$\mathcal{L}_{C O N}=\mathbb{E}_{x_{i}^{u} \in \mathcal{D}_{u}}\left(\ell_{c r}+\lambda_{k l d} \ell_{k l d}\right)\quad\quad(12)$
3.5 Overall framework and training objective
本文方法是基于MME [45]的,它采用对抗性学习来改进域间自适应的样本特征对齐。将MME[45]中提到的熵损失纳入到本文的损失函数中。总体损失函数是上述损失函数的和,如下:
$\theta_{\mathcal{F}}=\underset{\theta_{\mathcal{F}}}{\arg \min } \mathcal{L}_{C E}+\mathcal{L}_{H}+\lambda_{1} \mathcal{L}_{A P A}+\lambda_{2} \mathcal{L}_{C O N}\quad\quad(13)$
$\theta_{\mathcal{C}}=\underset{\theta_{\mathcal{A}}}{\arg \min } \mathcal{L}_{C E}-\mathcal{L}_{H}+\lambda_{1} \mathcal{L}_{A P A}+\lambda_{2} \mathcal{L}_{C O N}$
其中:
$\mathcal{L}_{H}=-\mathbb{E}_{x_{i}^{u} \in \mathcal{D}_{u}} \sum_{i=1}^{K} p\left(y=i \mid x_{i}^{u}\right) \log p\left(y=i \mid x_{i}^{u}\right)$
3.6 算法框架

4 实验
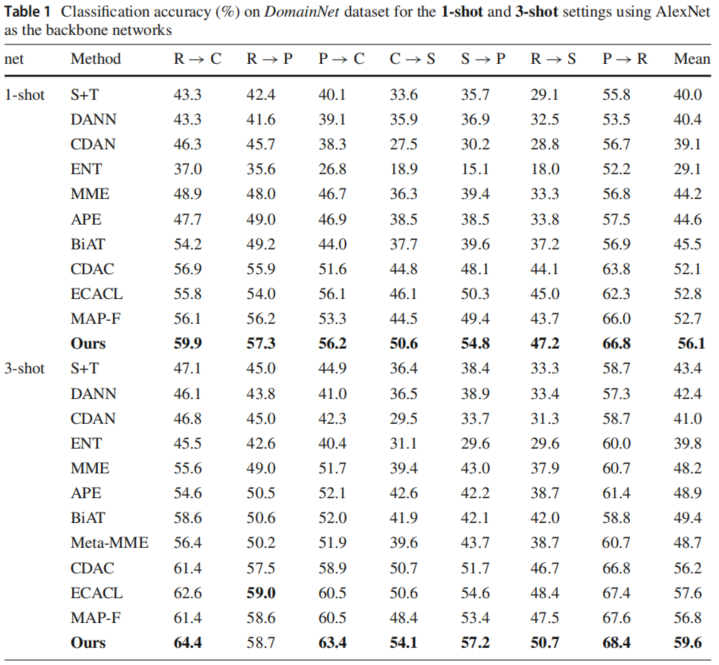
分类准确度
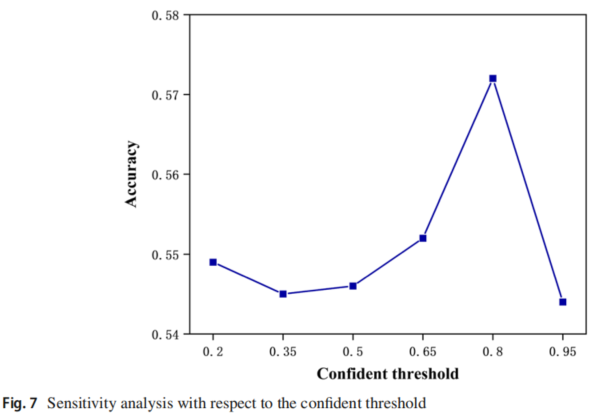
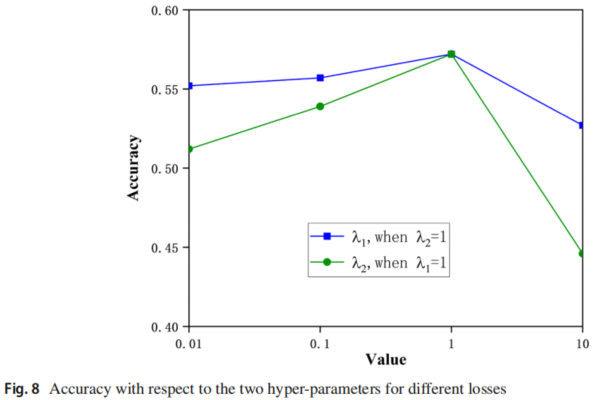
参数敏感性
消融实验

论文解读(APCA)《Adaptive prototype and consistency alignment for semi-supervised domain adaptation》的更多相关文章
- 论文解读(CDCL)《Cross-domain Contrastive Learning for Unsupervised Domain Adaptation》
论文信息 论文标题:Cross-domain Contrastive Learning for Unsupervised Domain Adaptation论文作者:Rui Wang, Zuxuan ...
- 论文解读(CDTrans)《CDTrans: Cross-domain Transformer for Unsupervised Domain Adaptation》
论文信息 论文标题:CDTrans: Cross-domain Transformer for Unsupervised Domain Adaptation论文作者:Tongkun Xu, Weihu ...
- 迁移学习()《Attract, Perturb, and Explore: Learning a Feature Alignment Network for Semi-supervised Domain Adaptation》
论文信息 论文标题:Attract, Perturb, and Explore: Learning a Feature Alignment Network for Semi-supervised Do ...
- 论文解读(AGC)《Attributed Graph Clustering via Adaptive Graph Convolution》
论文信息 论文标题:Attributed Graph Clustering via Adaptive Graph Convolution论文作者:Xiaotong Zhang, Han Liu, Qi ...
- 论文解读(AGE)《Adaptive Graph Encoder for Attributed Graph Embedding》
论文信息 论文标题:Adaptive Graph Encoder for Attributed Graph Embedding论文作者:Gayan K. Kulatilleke, Marius Por ...
- 论文解读(ToAlign)《ToAlign: Task-oriented Alignment for Unsupervised Domain Adaptation》
论文信息 论文标题:ToAlign: Task-oriented Alignment for Unsupervised Domain Adaptation论文作者:Guoqiang Wei, Cuil ...
- 《Stereo R-CNN based 3D Object Detection for Autonomous Driving》论文解读
论文链接:https://arxiv.org/pdf/1902.09738v2.pdf 这两个月忙着做实验 博客都有些荒废了,写篇用于3D检测的论文解读吧,有理解错误的地方,烦请有心人指正). 博客原 ...
- CVPR2020论文解读:OCR场景文本识别
CVPR2020论文解读:OCR场景文本识别 ABCNet: Real-time Scene Text Spotting with Adaptive Bezier-Curve Network∗ 论文 ...
- 自监督学习(Self-Supervised Learning)多篇论文解读(上)
自监督学习(Self-Supervised Learning)多篇论文解读(上) 前言 Supervised deep learning由于需要大量标注信息,同时之前大量的研究已经解决了许多问题.所以 ...
- 人工智能论文解读精选 | PRGC:一种新的联合关系抽取模型
NLP论文解读 原创•作者 | 小欣 论文标题:PRGC: Potential Relation and Global Correspondence Based Joint Relational ...
随机推荐
- Redis主从和哨兵搭建
今天主要分享Redis主从架构和哨兵的搭建. 主从集群搭建 总共三个节点,一个主节点和两个从节点.都安装在一台机器上模拟主从集群,信息如下: IP PORT 角色 192.168.246.140 70 ...
- C# POST提交以及 解析 JSON 实例
一.解析的JSON字符串如下 {"tinyurl":"http:\/\/dwz.cn\/v9BxE","status":0,"lo ...
- 2022-12-07:删除重复的电子邮箱。删除重复数据后,id=3的数据被删除。请问sql语句如何写? DROP TABLE IF EXISTS `person`; CREATE TABLE `per
2022-12-07:删除重复的电子邮箱.删除重复数据后,id=3的数据被删除.请问sql语句如何写? DROP TABLE IF EXISTS `person`; CREATE TABLE `per ...
- 2021-01-02:java中,MinorGC、MajorGC、FullGC 什么时候发生?
福哥答案2021-01-02: MinorGC 在年轻代空间不足的时候发生.MajorGC 指的是老年代的 GC,出现 MajorGC 一般经常伴有 MinorGC.FullGC 老年代无法再分配内存 ...
- 2021-06-22:现有司机N*2人,调度中心会将所有司机平分给A、B两个区域,第 i 个司机去A可得收入为income[i][0],第 i 个司机去B可得收入为income[i][1],返回所有调
2021-06-22:现有司机N*2人,调度中心会将所有司机平分给A.B两个区域,第 i 个司机去A可得收入为income[i][0],第 i 个司机去B可得收入为income[i][1],返回所有调 ...
- 2021-08-19:超级洗衣机。假设有 n 台超级洗衣机放在同一排上。开始的时候,每台洗衣机内可能有一定量的衣服,也可能是空的。在每一步操作中,你可以选择任意 m (1 ≤ m ≤ n) 台洗衣机,
2021-08-19:超级洗衣机.假设有 n 台超级洗衣机放在同一排上.开始的时候,每台洗衣机内可能有一定量的衣服,也可能是空的.在每一步操作中,你可以选择任意 m (1 ≤ m ≤ n) 台洗衣机, ...
- 百度飞桨(PaddlePaddle) - PaddleOCR 文字识别简单使用
百度飞桨(PaddlePaddle)安装 OCR 文字检测(Differentiable Binarization --- DB) OCR的技术路线 PaddleHub 预训练模型的网络结构是 DB ...
- Vue——属性指令、style和class、条件渲染、列表渲染、事件处理、数据双向绑定、过滤案例
vm对象 <body> <div id="app"> <h1>{{name}}</h1> <button @click=&qu ...
- .net 温故知新【11】:Asp.Net Core WebAPI 入门使用及介绍
在Asp.Net Core 上面由于现在前后端分离已经是趋势,所以asp.net core MVC用的没有那么多,主要以WebApi作为学习目标. 一.创建一个WebApi项目 我使用的是VS2022 ...
- Taurus.mvc .Net Core 微服务开源框架发布V3.1.7:让分布式应用更高效。
前言: 自首个带微服务版本的框架发布:Taurus.MVC V3.0.3 微服务开源框架发布:让.NET 架构在大并发的演进过程更简单 已经过去快1年了,在这近一年的时间里,版本经历了N个版本的迭代. ...