Pandas 使用教程 Series、DataFrame
Pandas 一个强大的分析结构化数据的工具集,基础是 Numpy(提供高性能的矩阵运算)
Pandas 可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据。
Pandas 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征。
Pandas 广泛应用在学术、金融、统计学等各个数据分析领域。
Pandas 的主要数据结构是 Series (一维数据)与 DataFrame(二维数据)
- Series 是一种类似于一维数组的对象,它由一组数据(各种Numpy数据类型)以及一组与之相关的数据标签(即索引)组成
- DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
Series (一维数据)
Pandas Series 类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型。
Series 由索引(index)和列组成,函数如下:
pandas.Series( data, index, dtype, name, copy)
参数说明:
- data:一组数据(ndarray 类型)。
- index:数据索引标签,如果不指定,默认从 0 开始。
- dtype:数据类型,默认会自己判断。
- name:设置名称。
- copy:拷贝数据,默认为 False。
import pandas as pd
a = [1, 2, 3]
myvar = pd.Series(a)
print(myvar)
print(myvar[1]) # 2
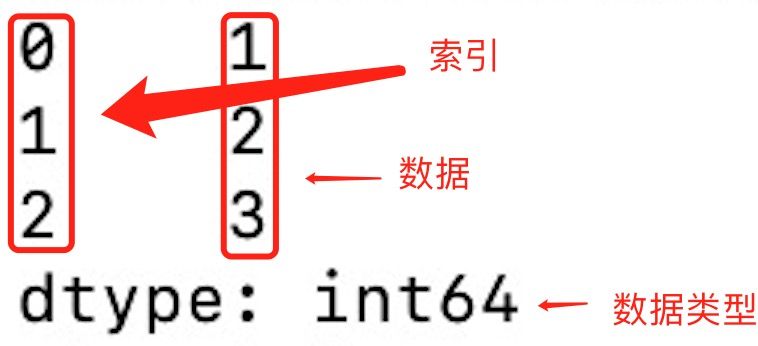
如果没有指定索引,索引值就从 0 开始,
指定索引值
如下实例:
import pandas as pd
a = ["Google", "Runoob", "Wiki"]
myvar = pd.Series(a, index = ["x", "y", "z"])
print(myvar)
print(myvar["y"]) # Runoob

使用 key/value 对象,创建对象
import pandas as pd
sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
myvar = pd.Series(sites)
print(myvar)

设置 Series 名称参数
import pandas as pd
sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
myvar = pd.Series(sites, index = [1, 2], name="RUNOOB-Series-TEST" )
print(myvar)

DataFrame(二维数据)
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
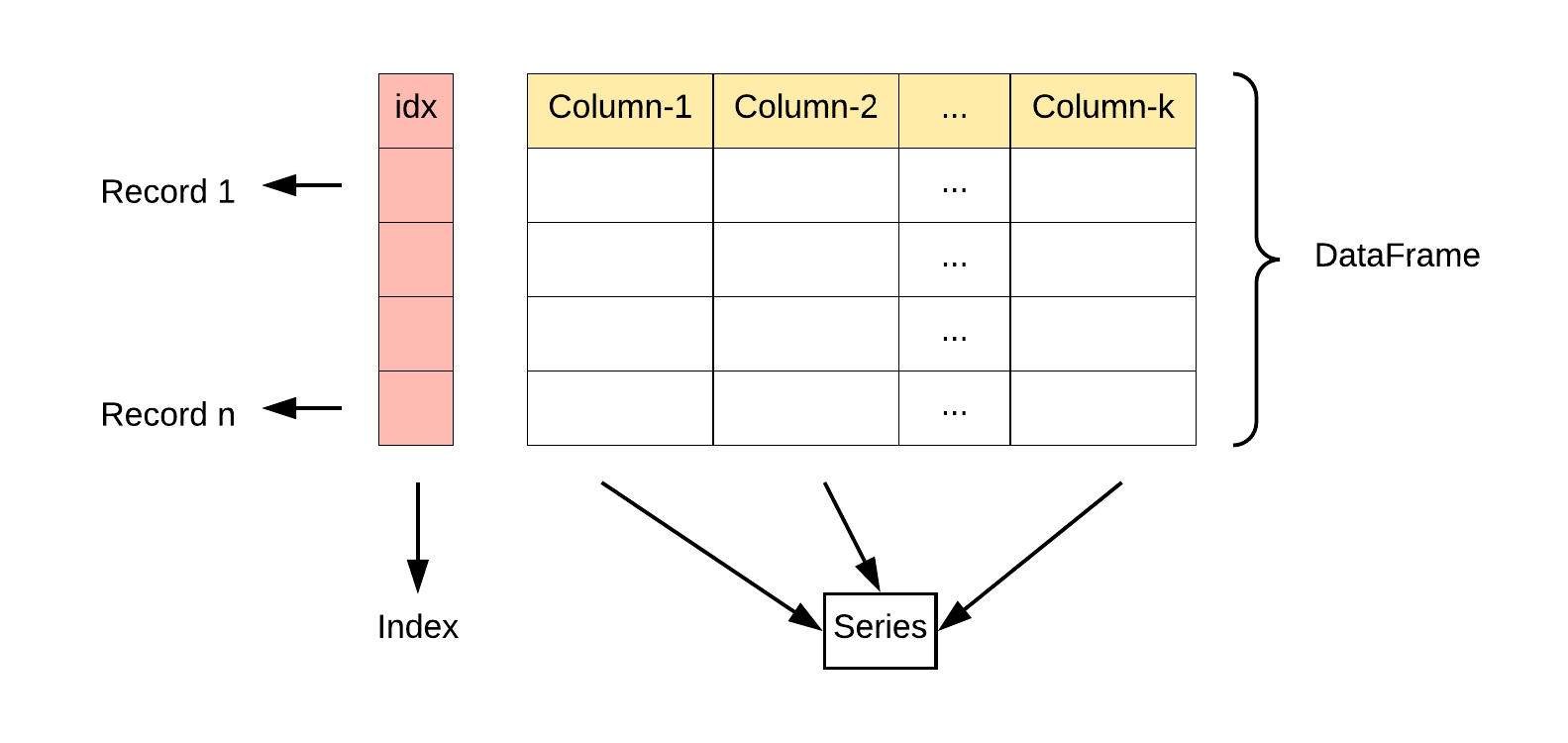
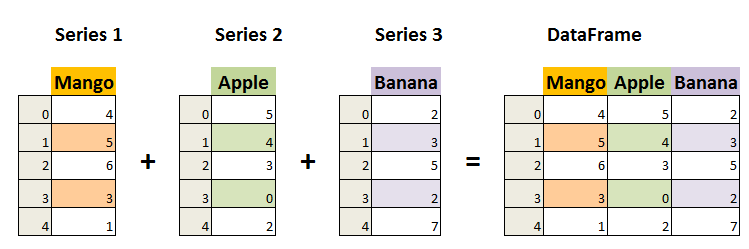
DataFrame 构造方法如下:
pandas.DataFrame( data, index, columns, dtype, copy)
参数说明:
- data:一组数据(ndarray、series, map, lists, dict 等类型)。
- index:索引值,或者可以称为行标签。
- columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。
- dtype:数据类型。
- copy:拷贝数据,默认为 False。
Pandas DataFrame 是一个二维的数组结构,类似二维数组。
import pandas as pd
data = [['Google',10],['Runoob',12],['Wiki',13]]
# data = {'Site':['Google', 'Runoob', 'Wiki'], 'Age':[10, 12, 13]} # 也可以这样写
df = pd.DataFrame(data,columns=['Site','Age'],dtype=float)
print(df)
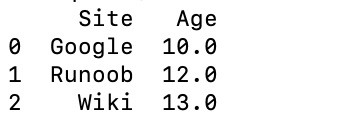
DataFrame 数据类型一个表格,包含 rows(行) 和 columns(列):

使用字典(key/value)创建
import pandas as pd
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
df = pd.DataFrame(data)
print (df)
输出
a b c
0 1 2 NaN
1 5 10 20.0
loc 属性返回指定行的数据
import pandas as pd
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
# 数据载入到 DataFrame 对象
df = pd.DataFrame(data)
# 返回第一行
# calories 420
# duration 50
print(df.loc[0])
# 返回第二行
# calories 380
# duration 40
print(df.loc[1])
# 返回第一行和第三行
# calories duration
#0 420 50
#2 390 45
print(df.loc[[0, 2]])
Pandas 使用教程 Series、DataFrame的更多相关文章
- pandas数据结构:Series/DataFrame;python函数:range/arange
1. Series Series 是一个类数组的数据结构,同时带有标签(lable)或者说索引(index). 1.1 下边生成一个最简单的Series对象,因为没有给Series指定索引,所以此时会 ...
- 利用Python进行数据分析:【Pandas】(Series+DataFrame)
一.pandas简单介绍 1.pandas是一个强大的Python数据分析的工具包.2.pandas是基于NumPy构建的.3.pandas的主要功能 --具备对其功能的数据结构DataFrame.S ...
- python pandas ---Series,DataFrame 创建方法,操作运算操作(赋值,sort,get,del,pop,insert,+,-,*,/)
pandas 是基于 Numpy 构建的含有更高级数据结构和工具的数据分析包 pandas 也是围绕着 Series 和 DataFrame 两个核心数据结构展开的, 导入如下: from panda ...
- python. pandas(series,dataframe,index) method test
python. pandas(series,dataframe,index,reindex,csv file read and write) method test import pandas as ...
- pandas 的数据结构Series与DataFrame
pandas中有两个主要的数据结构:Series和DataFrame. [Series] Series是一个一维的类似的数组对象,它包含一个数组数据(任何numpy数据类型)和一个与数组关联的索引. ...
- Pandas 之 Series / DataFrame 初识
import numpy as np import pandas as pd Pandas will be a major tool of interest throughout(贯穿) much o ...
- Python 数据处理库 pandas 入门教程
Python 数据处理库 pandas 入门教程2018/04/17 · 工具与框架 · Pandas, Python 原文出处: 强波的技术博客 pandas是一个Python语言的软件包,在我们使 ...
- pandas中数据结构-Series
pandas中数据结构-Series pandas简介 Pandas是一个开源的,BSD许可的Python库,为Python编程语言提供了高性能,易于使用的数据结构和数据分析工具.Python与Pan ...
- Pandas之:Pandas简洁教程
Pandas之:Pandas简洁教程 目录 简介 对象创建 查看数据 选择数据 loc和iloc 布尔索引 处理缺失数据 合并 分组 简介 pandas是建立在Python编程语言之上的一种快速,强大 ...
- Pandas之:Pandas高级教程以铁达尼号真实数据为例
Pandas之:Pandas高级教程以铁达尼号真实数据为例 目录 简介 读写文件 DF的选择 选择列数据 选择行数据 同时选择行和列 使用plots作图 使用现有的列创建新的列 进行统计 DF重组 简 ...
随机推荐
- 2021-12-10:64位的浮点数和64位的有符号整数,哪个能表示的数据个数多? A.整型多。 B.浮点型多。 C.与平台有关。 D.一样多。 来自qq群。
2021-12-10:64位的浮点数和64位的有符号整数,哪个能表示的数据个数多? A.整型多. B.浮点型多. C.与平台有关. D.一样多. 来自qq群. 答案2021-12-10: 答案选A. ...
- .NET 通过源码深究依赖注入原理
依赖注入 (DI) 是.NET中一个非常重要的软件设计模式,它可以帮助我们更好地管理和组织组件,提高代码的可读性,扩展性和可测试性.在日常工作中,我们一定遇见过这些问题或者疑惑. Singleton服 ...
- Visual Studio2019打开电脑摄像头
#include<iostream> //opencv头文件 #include<opencv2/opencv.hpp> using namespace std; using n ...
- web自动化08-下拉选择框、弹出框、滚动条
1.下拉选择框操作 下拉框就是HTML中<select>元素: 先列需求: 需求:使用'注册A.html'页面,完成对城市的下拉框的操作 1).选择'广州' 2).暂停2秒,选择'上海 ...
- 「GPT虚拟直播」实战篇|GPT接入虚拟人实现直播间弹幕回复
摘要 ChatGPT和元宇宙都是当前数字化领域中非常热门的技术和应用.结合两者的优势和特点,可以探索出更多的应用场景和商业模式.例如,在元宇宙中使用ChatGPT进行自然语言交互,可以为用户提供更加智 ...
- 由C# yield return引发的思考
前言 当我们编写 C# 代码时,经常需要处理大量的数据集合.在传统的方式中,我们往往需要先将整个数据集合加载到内存中,然后再进行操作.但是如果数据集合非常大,这种方式就会导致内存占用过高,甚至可能导致 ...
- Galaxy 生信平台(三):xlsx 上传与识别
我在<Firefox Quantum 向左,Google Chrome 向右>中,曾经吐槽过在 Firefox 中使用 Galaxy 上传本地的 Excel 文件时,会出现 xlsx 无法 ...
- 2023-06-08:给你一棵二叉树的根节点 root ,返回树的 最大宽度 。 树的 最大宽度 是所有层中最大的 宽度 。 每一层的 宽度 被定义为该层最左和最右的非空节点(即,两个端点)之间的长度
2023-06-08:给你一棵二叉树的根节点 root ,返回树的 最大宽度 . 树的 最大宽度 是所有层中最大的 宽度 . 每一层的 宽度 被定义为该层最左和最右的非空节点(即,两个端点)之间的长度 ...
- C# - XMLHelper :一个操作XML的简单类库
下午写了一个操作XML文件的类库,后来不用了,水篇文章存个档 整体功能 XMLHelper.cs主要提供以下功能: 加载XML文件:从文件路径或字符串中加载XML文档,并返回XmlDocument对象 ...
- Taurus .Net Core 微服务开源框架:Admin 插件【3】 - 指标统计管理
前言: 继上篇:Taurus .Net Core 微服务开源框架:Admin 插件[2] - 系统环境信息管理 本篇继续介绍下一个内容: 1.系统指标节点:Metric - API 界面 界面图如下: ...