Pandas 使用教程 Series、DataFrame
Pandas 一个强大的分析结构化数据的工具集,基础是 Numpy(提供高性能的矩阵运算)
Pandas 可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据。
Pandas 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征。
Pandas 广泛应用在学术、金融、统计学等各个数据分析领域。
Pandas 的主要数据结构是 Series (一维数据)与 DataFrame(二维数据)
- Series 是一种类似于一维数组的对象,它由一组数据(各种Numpy数据类型)以及一组与之相关的数据标签(即索引)组成
- DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
Series (一维数据)
Pandas Series 类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型。
Series 由索引(index)和列组成,函数如下:
pandas.Series( data, index, dtype, name, copy)
参数说明:
- data:一组数据(ndarray 类型)。
- index:数据索引标签,如果不指定,默认从 0 开始。
- dtype:数据类型,默认会自己判断。
- name:设置名称。
- copy:拷贝数据,默认为 False。
import pandas as pd
a = [1, 2, 3]
myvar = pd.Series(a)
print(myvar)
print(myvar[1]) # 2
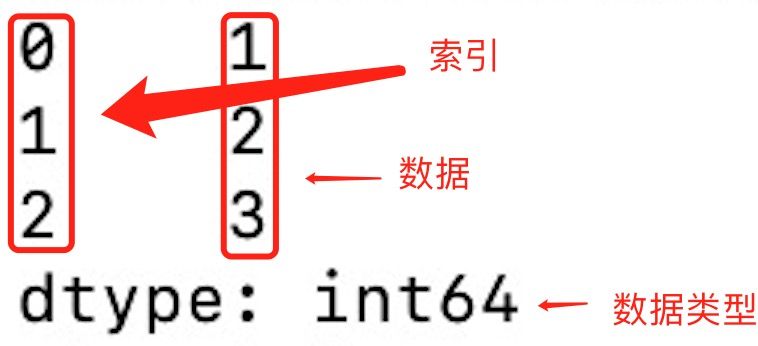
如果没有指定索引,索引值就从 0 开始,
指定索引值
如下实例:
import pandas as pd
a = ["Google", "Runoob", "Wiki"]
myvar = pd.Series(a, index = ["x", "y", "z"])
print(myvar)
print(myvar["y"]) # Runoob

使用 key/value 对象,创建对象
import pandas as pd
sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
myvar = pd.Series(sites)
print(myvar)

设置 Series 名称参数
import pandas as pd
sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
myvar = pd.Series(sites, index = [1, 2], name="RUNOOB-Series-TEST" )
print(myvar)

DataFrame(二维数据)
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
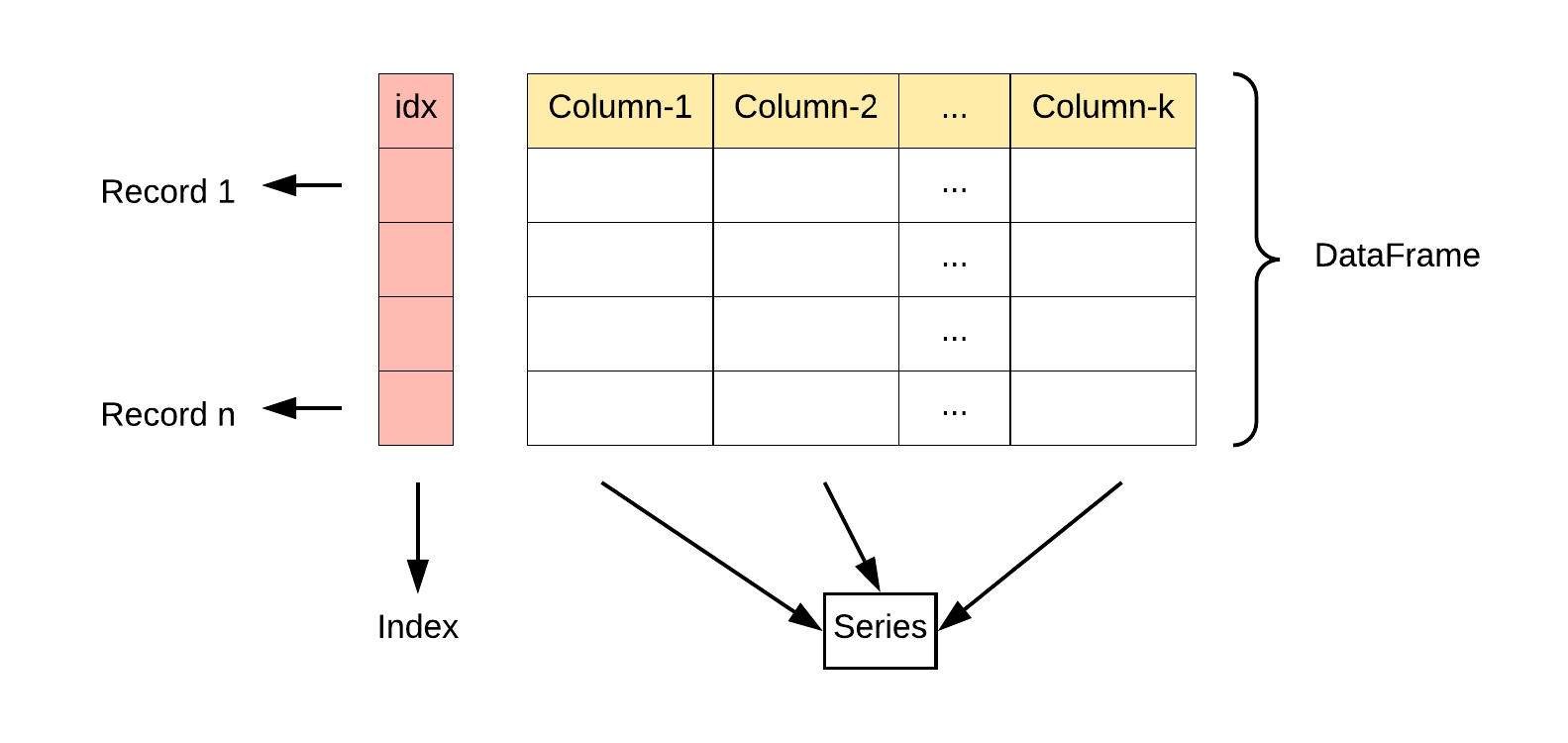
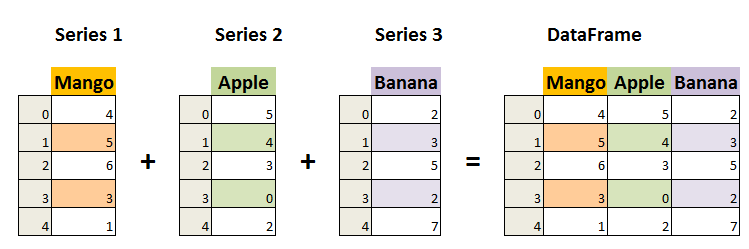
DataFrame 构造方法如下:
pandas.DataFrame( data, index, columns, dtype, copy)
参数说明:
- data:一组数据(ndarray、series, map, lists, dict 等类型)。
- index:索引值,或者可以称为行标签。
- columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。
- dtype:数据类型。
- copy:拷贝数据,默认为 False。
Pandas DataFrame 是一个二维的数组结构,类似二维数组。
import pandas as pd
data = [['Google',10],['Runoob',12],['Wiki',13]]
# data = {'Site':['Google', 'Runoob', 'Wiki'], 'Age':[10, 12, 13]} # 也可以这样写
df = pd.DataFrame(data,columns=['Site','Age'],dtype=float)
print(df)
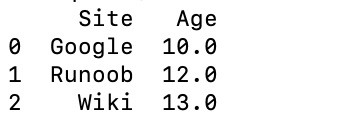
DataFrame 数据类型一个表格,包含 rows(行) 和 columns(列):

使用字典(key/value)创建
import pandas as pd
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
df = pd.DataFrame(data)
print (df)
输出
a b c
0 1 2 NaN
1 5 10 20.0
loc 属性返回指定行的数据
import pandas as pd
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
# 数据载入到 DataFrame 对象
df = pd.DataFrame(data)
# 返回第一行
# calories 420
# duration 50
print(df.loc[0])
# 返回第二行
# calories 380
# duration 40
print(df.loc[1])
# 返回第一行和第三行
# calories duration
#0 420 50
#2 390 45
print(df.loc[[0, 2]])
Pandas 使用教程 Series、DataFrame的更多相关文章
- pandas数据结构:Series/DataFrame;python函数:range/arange
1. Series Series 是一个类数组的数据结构,同时带有标签(lable)或者说索引(index). 1.1 下边生成一个最简单的Series对象,因为没有给Series指定索引,所以此时会 ...
- 利用Python进行数据分析:【Pandas】(Series+DataFrame)
一.pandas简单介绍 1.pandas是一个强大的Python数据分析的工具包.2.pandas是基于NumPy构建的.3.pandas的主要功能 --具备对其功能的数据结构DataFrame.S ...
- python pandas ---Series,DataFrame 创建方法,操作运算操作(赋值,sort,get,del,pop,insert,+,-,*,/)
pandas 是基于 Numpy 构建的含有更高级数据结构和工具的数据分析包 pandas 也是围绕着 Series 和 DataFrame 两个核心数据结构展开的, 导入如下: from panda ...
- python. pandas(series,dataframe,index) method test
python. pandas(series,dataframe,index,reindex,csv file read and write) method test import pandas as ...
- pandas 的数据结构Series与DataFrame
pandas中有两个主要的数据结构:Series和DataFrame. [Series] Series是一个一维的类似的数组对象,它包含一个数组数据(任何numpy数据类型)和一个与数组关联的索引. ...
- Pandas 之 Series / DataFrame 初识
import numpy as np import pandas as pd Pandas will be a major tool of interest throughout(贯穿) much o ...
- Python 数据处理库 pandas 入门教程
Python 数据处理库 pandas 入门教程2018/04/17 · 工具与框架 · Pandas, Python 原文出处: 强波的技术博客 pandas是一个Python语言的软件包,在我们使 ...
- pandas中数据结构-Series
pandas中数据结构-Series pandas简介 Pandas是一个开源的,BSD许可的Python库,为Python编程语言提供了高性能,易于使用的数据结构和数据分析工具.Python与Pan ...
- Pandas之:Pandas简洁教程
Pandas之:Pandas简洁教程 目录 简介 对象创建 查看数据 选择数据 loc和iloc 布尔索引 处理缺失数据 合并 分组 简介 pandas是建立在Python编程语言之上的一种快速,强大 ...
- Pandas之:Pandas高级教程以铁达尼号真实数据为例
Pandas之:Pandas高级教程以铁达尼号真实数据为例 目录 简介 读写文件 DF的选择 选择列数据 选择行数据 同时选择行和列 使用plots作图 使用现有的列创建新的列 进行统计 DF重组 简 ...
随机推荐
- Windows server 2012 r2 激活方法
slmgr /ipk W3GGN-FT8W3-Y4M27-J84CP-Q3VJ9 slmgr /skms kms.03k.org slmgr /ato
- select_related一对一、多对一查询优化
select_related一对一.多对一查询优化 Course.objects.all().select_related('teacher') 查询课程时顺带查出老师的信息
- drf——restful规范、序列化反序列化、drf介绍和快速使用、drf之APIView源码
1.restful规范 # restful是一种定义API接口的设计风格,API接口的编写规范,尤其适用于前后端分离的应用模式中 这种风格的理念人为后端开发任务就是提供数据的,对外提供的是数据资源的访 ...
- vscode运行java输出至指定文件夹
一.前言 最近呢,需要用vscode编写一点小的java程序,也就是单java文件,但是呢,我发现coderunner运行java,一个java文件编译出一个class文件,这也太乱了!不符合我简约的 ...
- 2014年蓝桥杯C/C++大学B组省赛真题(切面条)
题目描述: 一根高筋拉面,中间切一刀,可以得到2根面条. 如果先对折1次,中间切一刀,可以得到3根面条. 如果连续对折2次,中间切一刀,可以得到5根面条. 那么,连续对折10次,中间切一刀,会得到多少 ...
- python selenium框架解决ip代理框不能自动化登录,解决pyautogui开不了多线程问题
有时候我们使用python自动化框架的时候,打开一个网页的时候,它会出现出线这一种登录框,我们f12检查不了,用开发者工具强制检查里面没有任何属性. 那这时候我们就可以用到python第三方库:pya ...
- 如何在.net6webapi中配置Jwt实现鉴权验证
JWT(Json Web Token) jwt是一种用于身份验证的开放标准,他可以在网络之间传递信息,jwt由三部分组成:头部,载荷,签名.头部包含了令牌的类型和加密算法,载荷包含了用户的信息,签名则 ...
- SpringBoot进阶教程(七十六)多维度排序查询
在项目中经常能遇到,需要对某些数据集合进行多维度排序的需求.对于集合多条件排序解决方案也有很多,今天我们就介绍一种,思路大致是设置一个分值的集合,这个分值是按照需求来设定大小的,再根据分值的大小对集合 ...
- 【建议收藏】Log4j配置详解
大家在日常开发中必然会使用到日志组件,Log4j是Java方向上比较常用的日志组件,今天给大家分享下Log4j支持的配置项,强烈建议收藏,以便配置时查看 #展示log4j各种配置,私有部分见文件中注释 ...
- 【技术积累】JavaSciprt中的函数【一】
什么是函数?如何声明函数? JavaScript中的函数是一段可重复使用的代码块,它可以接受输入并返回输出. 在JavaScript中,函数是一种特殊的对象,因此可以将其存储在变量中,将其作为参数传递 ...