【论文阅读】IROS2017: Voxblox & RAL2019: Voxblox++
IROS2017: Voxblox & RAL2019: Voxblox++
Status: Finished
Type: RAL
Year: 2019
组织/Sensor: ETH-ASL
参考与前言
此文档涵盖了两篇内容,从2017年IROS的voxblox到2019年RAL的voxblox++,但是主要重点在voxblox哈~
论文链接:https://arxiv.org/abs/1611.03631 and https://arxiv.org/abs/1903.00268
代码链接:https://github.com/ethz-asl/voxblox and https://github.com/ethz-asl/voxblox-plusplus
voxblox的文档链接:https://voxblox.readthedocs.io/en/latest/index.html
后续 关于语义的 也可以看看,同ETH-ASL这篇:
voxblox实现了三种不同形式的积分策略:
- Fast
- Merged 应对大场景,将多个voxels捆绑在一起进行投影
- Simple 直接遍历的操作,很淳朴简单哈
与Octomap相比运行时间 Octomap对每个voxel都进行映射,但是voxblox面对大规模场景时候可以(使用Merged策略) 对voxel进行捆绑映射,能够在节省运行时间同时精度不产生明显下降。 版权声明:本文为CSDN博主「憨憨2号」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/qq_45401419/article/details/125125993
【语义地图】voxblox++ :Volumetric Semantic Mapping
使用一个在线的已经定位了的RGBD摄像机的扫描,能够增量式构建volumetric object-level 的地图。
- 使用一个帧帧分割框架 + instance-aware 的语义预测的无监督几何方法来同时检测已经识别过得场景元素和之前没有见过的物体
- data-association:在不同的帧之间追踪已经预测到的物体实例
- 一个地图整合策略把关于它们的3D形状,位置,以及语义信息融合进入一个全局栅格地图(global volume)
原文链接:https://zhuanlan.zhihu.com/p/117665107
前提知识:
- ESDFs (Euclidean Signed Distance Fields) are a voxel grid where every point contains its Euclidean distance to the nearest obstacle
- TSDFs (Truncated Signed Distance Fields) use projective distance, which is the distance along the sensor ray to the measured surface, and calculate these distances only within a short truncation radius around the surface boundary.
1. Motivation
因为小型无人机的规划需求,通过我们获取与障碍物之间的距离信息是通过 ESDFs。voxblox 主要是 使用 TSDF进行建图,然后增量构建ESDFs

voxblox++ 则是走到了object-level,所以voxblox++其实是在voxblox基础上加了语义的label

下面主要是介绍一下voxblox和其延续的voxblox++论文上提到的点。首先是voxblox中说明了为什么使用TSDF进行操作:TSDFs are fast to build and smooth out sensor noise over many observations, and are designed to produce surface meshes.
voxblox 主要还是关注在 无人机需要这个地图 是用来进行规划的,所以最终形态其实是ESDF 来做规划使用,对比之前的:
- [3] 可以增量式构建distance map,但是缺点是 maximum size of the map需要是已知,而且不能动态调整
- octomap[4] 虽然能使用,但是难以让人理解的 different for human to parse
为了解决以上问题 我们提出了voxblox 这样的系统,可以增量式构建ESDF,同时underlying map representation 可以可视化;同时从TSDF中直接提取距离信息来构建ESDF
而voxblox++ 指出在机械臂抓取中,我们通常需要知道更多信息,其中就包括了3D物体的模型大小,类型等,但是在真实世界中exhibit large variability in object appearance, shape, placement and location, posing a direct chagenge to robotic perception. 虽然CV有针对pixel-level的分割,但是仅识别训练中遇到的;完全基于几何的方法可以适用于openset,但是他们 tend to over-segment the reconstructed objects and additionally fail to provide any semantic information about them, making highlevel scene understanding and task planning impractical.
voxblox++ 系统主要就是增量的构建精确几何信息的volumetric maps,同时标注出所有的object instance,从[7] 的 incremental geometry-based scene segmentation approach然后扩展到完整的 instance-aware semantic mapping
Contribution
voxblox 的主要贡献就是第一个提出使用TSDFs 增量构建ESDFs,然后分析了不同的构建TSDFs的方式 在large voxels size的情况下,提升构建速度和表面精度。
而voxblox++ 则是专注于 语义的部分,首先是结合了geometric-semantic segmentation that extends object detection,同时有关于预测出的label怎样在多帧之间进行跟踪,匹配等
2. Method
voxblox:

为了exploration和mapping,使用了[12] 提出的voxel hashing;同时因为mapping的block position and their locations in memory通过hash table存储,可以实现O(1)的插入和查找,这种数据结构适合 flexible to growing maps,然后比Octomap更快 O(logn)
voxblox++:
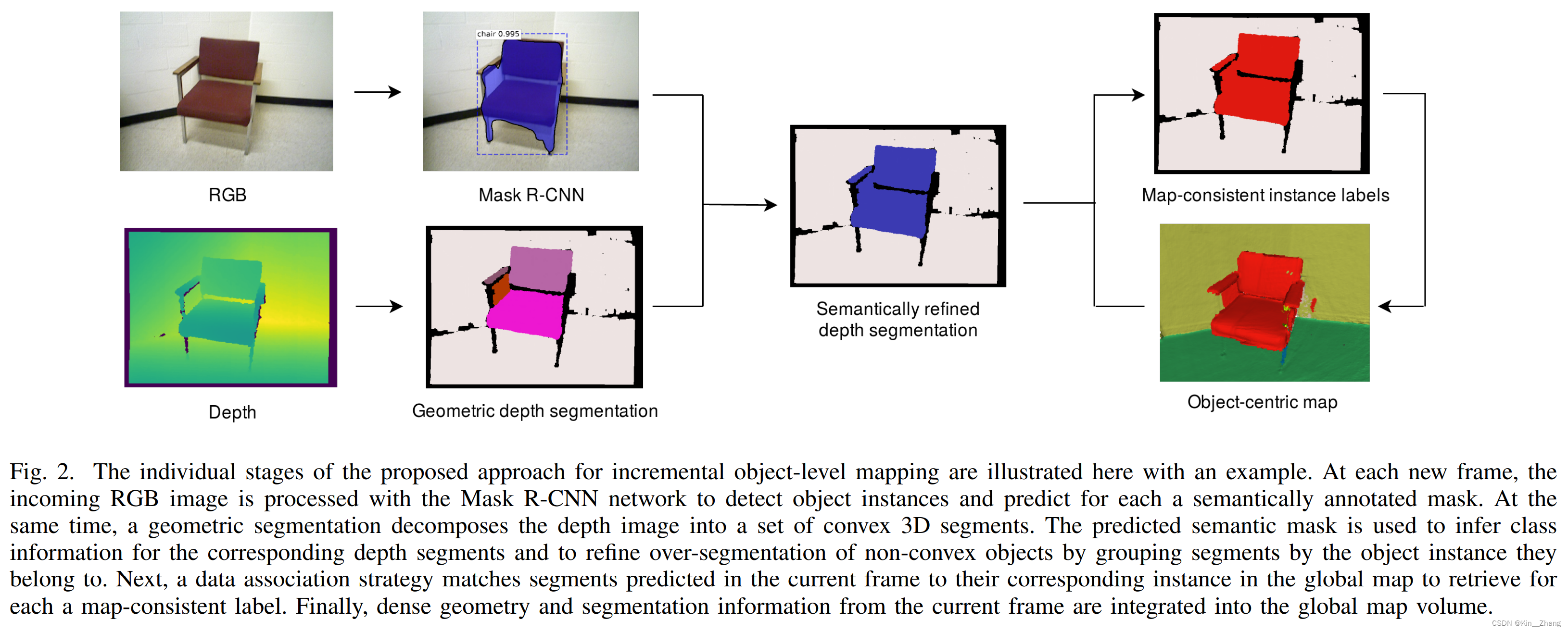
这样看来两个是不太一样的任务 不应该放在阅读 hhh ,进阶版干点语义的事 大概是这感觉,过程总结:
- A frame-wise segmentation scheme combines an unsupervised geometric segmentation of depth images [9] with semantic object predictions from RGB [1]. The use of semantics allows the system to infer the category of some of the 3D segments predicted in a frame, as well as to group segments by the object instance to which they belong. 所以主要是使用深度相机做无监督的几何分割,同时对RGB图片也做mask,得到refined
- The tracking of the individual predicted instances across multiple frames is addressed by matching perframe predictions to existing segments in the global map via a data association strategy.
- Observed surface geometry and segmentation information are integrated into a global Truncated Signed Distance Field (TSDF) map volume.
主要就是接受了Mask R-CNN 走到点云的点去给出label,注意有时候可能存在不同物体点之间有overlap,voxblox++ 论文中设了一个阈值

整理的integration 也就是使用了voxblox进行的进图,然后给每个voxel分配label info,选取各自最大的object label和semantic class
2.2 TSDF构建
对于文中更新的方式则是如下公式,\(\bf x, p, s \in \R^3\)
\]
- x表示current voxel的中心位置
- p表示传感器数据的3D point位置
- s表示传感器中心
- d为来自传感器点的新更新数据
最后关于如何merge 新收的数据和之前的voxel grid
- For each point in the sensor scan, we project its position to the voxel grid, and group it with all other points mapping to the same voxel.
- Then we take the weighted mean of all points and colors within each voxel, and do raycasting only once on this mean position
速度上比普通的raycasting方法快了20倍
在上面weight是常量为1,但是本文提出了使用更sophisticated weight,主要是[19]中针对RGB-D 发现 the \(\sigma\) of a single ray measurement varied predominantly with z2,其中z为相机坐标系下测量的深度信息,结合 对RGB-D model的 behind-surface drop-off的简单假设,设置如下权重:
\]
其中 truncation distance of \(\delta=4v \text{ and }\epsilon=v\),其中v 为voxel size
code对应 和 paper里中间那个条件没有对应起来:
// Thread safe.
float TsdfIntegratorBase::getVoxelWeight(const Point& point_C) const {
if (config_.use_const_weight) {
return 1.0f;
}
const FloatingPoint dist_z = std::abs(point_C.z());
if (dist_z > kEpsilon) {
return 1.0f / (dist_z * dist_z);
}
return 0.0f;
}
2.3 TSDF → ESDF
由voxblox 文档截图出来的:

代码主要在 esdf_integrator.cc 文件中
3. 实验及结果

从图五可以看出voxel size越小 error越小,大了之后的Quadratic Weight操作对于error的减小也有帮助,速度上 本篇提出的速度最快,耗时最少
voxblox++
定量结果 主要是和3D semantic instance-segmentation的一个方法对比IoU
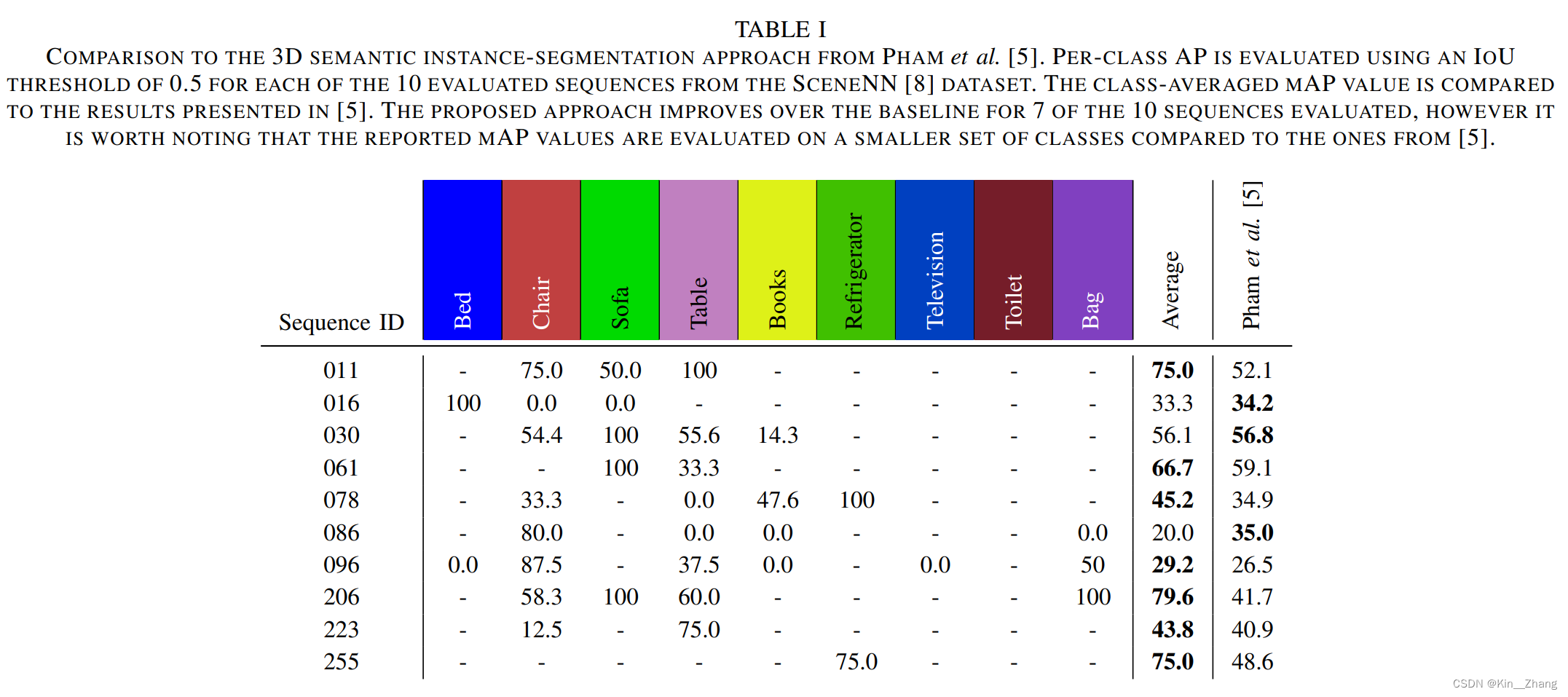
定性结果
同时还有每个部分所耗的时间,文中给出了计算平台型号

4. Conclusion
所以voxblox主要是把RGB-D收到的信息 做一个彩色建图,使用TSDF进行距离信息保留和构建,同时直接从TSDF增量生成ESDF给到规划使用,是一个非常明确下游任务需要的地图类型,real-time, efficient 也并未讨论未来工作
voxblox++添加了每个点上的object level和segmentation label信息,当然这样是耗时的,所以未来工作减少耗时,同时还有 involves investigating the optimal way to fuse RGB and depth information within a unified per-frame object detection, discovery and segmentation framework.
赠人点赞 手有余香 ;正向回馈 才能更好开放记录 hhh
【论文阅读】IROS2017: Voxblox & RAL2019: Voxblox++的更多相关文章
- 论文阅读(Xiang Bai——【PAMI2017】An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition)
白翔的CRNN论文阅读 1. 论文题目 Xiang Bai--[PAMI2017]An End-to-End Trainable Neural Network for Image-based Seq ...
- BITED数学建模七日谈之三:怎样进行论文阅读
前两天,我和大家谈了如何阅读教材和备战数模比赛应该积累的内容,本文进入到数学建模七日谈第三天:怎样进行论文阅读. 大家也许看过大量的数学模型的书籍,学过很多相关的课程,但是若没有真刀真枪地看过论文,进 ...
- 论文阅读笔记 - YARN : Architecture of Next Generation Apache Hadoop MapReduceFramework
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- 论文阅读笔记 - Mesos: A Platform for Fine-Grained ResourceSharing in the Data Center
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- Deep Reinforcement Learning for Dialogue Generation 论文阅读
本文来自李纪为博士的论文 Deep Reinforcement Learning for Dialogue Generation. 1,概述 当前在闲聊机器人中的主要技术框架都是seq2seq模型.但 ...
- 论文阅读笔记 Word Embeddings A Survey
论文阅读笔记 Word Embeddings A Survey 收获 Word Embedding 的定义 dense, distributed, fixed-length word vectors, ...
- 论文阅读笔记六:FCN:Fully Convolutional Networks for Semantic Segmentation(CVPR2015)
今天来看一看一个比较经典的语义分割网络,那就是FCN,全称如题,原英文论文网址:https://people.eecs.berkeley.edu/~jonlong/long_shelhamer_fcn ...
- 论文阅读笔记 Improved Word Representation Learning with Sememes
论文阅读笔记 Improved Word Representation Learning with Sememes 一句话概括本文工作 使用词汇资源--知网--来提升词嵌入的表征能力,并提出了三种基于 ...
- 论文阅读:Prominent Object Detection and Recognition: A Saliency-based Pipeline
论文阅读:Prominent Object Detection and Recognition: A Saliency-based Pipeline 如上图所示,本文旨在解决一个问题:给定一张图像, ...
- [置顶]
人工智能(深度学习)加速芯片论文阅读笔记 (已添加ISSCC17,FPGA17...ISCA17...)
这是一个导读,可以快速找到我记录的关于人工智能(深度学习)加速芯片论文阅读笔记. ISSCC 2017 Session14 Deep Learning Processors: ISSCC 2017关于 ...
随机推荐
- ubuntu安装 vmware workstation pro 15.1.1
BIOS开启虚拟化 如果没有就参考下面的连接地址设置 http://robotrs.lenovo.com.cn/ZmptY2NtYW5hZ2Vy/p4data/Rdata/Rfiles/726.htm ...
- Vue3 echarts 组件化使用 resizeObserver
点击查看代码 const resizeObserver = ref(null); //进行初始化和监听窗口变化 onMounted(async () => { await nextTick(() ...
- 基于FPGA的电子琴设计(按键和蜂鸣器)----第一版
欢迎各位朋友关注"郝旭帅电子设计团队",本篇为各位朋友介绍基于FPGA的电子琴设计(按键和蜂鸣器)----第一版. 功能说明: 外部输入七个按键,分别对应音符的"1.2. ...
- grpc使用nginx代理配置
参考:https://www.nginx.com/blog/nginx-1-13-10-grpc/ 重点是标记红色的部分 http { log_format main '$remote_addr - ...
- HTML——img标签
在HTML中,图像由标签定义的,它可以用来加载图片到html网页中显示.网页开发过程中,有三种图片格式被广泛应用到web里,分别是 jpg.png.gif. img标签的属性: /* src属性: 指 ...
- Android 13 - Media框架(19)- ACodec(一)
关注公众号免费阅读全文,进入音视频开发技术分享群! 这一节我们将会一起了解 ACodec 的设计方式,在看具体的实现细节前我们要先了解它内部的状态转换机制,这也是ACodec的核心难点之一. 1.AH ...
- 解决老旧电脑在win7中浏览器访问https网站出现的Let‘sEncrypt证书过期的问题
原因LetsEncrypt证书未过期,但是其顶级ca根证书 "DST Root CA X3"在2021-09-01过期了,老旧设备上的win系统会被影响到. 解决步骤下载三张Let ...
- windows7 + Qt(MSVC2017) + VS2019安装配置
在windows下使用qt时调用QWebEngineView 库会报错,即使在pro文件QT += webenginewidgets也找不到, 而在MinGW和MSVC2015的路径下我并没有找到这个 ...
- FFMPEG 信息查询
一.问题描述 最近测试反馈一个隐私模式的问题,主播端启用隐私模式之后,在观看端发现画面转菊花并且还有回跳的现象 二.问题分析: 从网上下载了直播的视频文件,进行了一下分析,发现视频长度和音频长度不匹配 ...
- html2canvas + jspdf导出pdf,文字重叠,样式不显示或者文字不显示
先在html引入cdn <script src="https://html2canvas.hertzen.com/dist/html2canvas.js"></s ...