AlexNet论文解读
前言
作为深度学习的开山之作AlexNet,确实给后来的研究者们很大的启发,使用神经网络来做具体的任务,如分类任务、回归(预测)任务等,尽管AlexNet在今天看来已经有很多神经网络超越了它,但是它依然是重要的。AlexNet的作者Alex Krizhevsky首次在两块GTX 580 GPU上做神经网络,并且在2012年ImageNet竞赛中取得了冠军,这是一件非常有意义的事情,为后来深度学习的兴起奠定了重要基础,包括现在的显卡公司NVIDIA的市值超越苹果,都有深度学习的一份功劳。
下面讲解一下AlexNet的网络结构和论文复现。实验为使用AlexNet网络做猫狗分类任务;实验经过了模型搭建,训练,测试以及结果分析。
1.网络结构
AlexNet的网络一共有8层,前5层是卷积层,剩下3层是全连接层,具体如下所示:
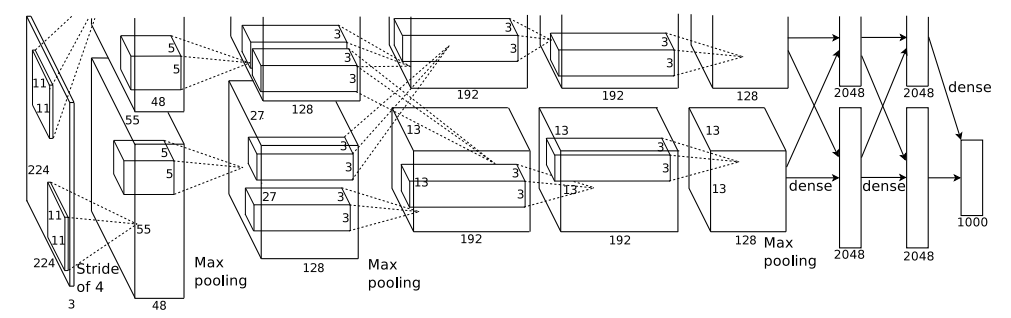
第一层:卷积层1,输入为 224 × 224 × 3 的图像,卷积核的数量为96,论文中两片GPU分别计算48个核; 卷积核的大小为 11 × 11 × 3;stride = 4, stride表示的是步长, pad = 0, 表示不扩充边缘;卷积后的图形大小为:wide = (224 + 2 * padding - kernel_size) / stride + 1 = 54,height = (224 + 2 * padding - kernel_size) / stride + 1 = 54,dimention = 96,然后进行 (Local Response Normalized), 后面跟着池化pool_size = (3, 3), stride = 2, pad = 0 最终获得第一层卷积的feature map;
第二层:卷积层2, 输入为上一层卷积的feature map, 卷积的个数为256个,论文中的两个GPU分别有128个卷积核。卷积核的大小为:5 × 5 × 48;pad = 2, stride = 1; 然后做 LRN,最后 max_pooling, pool_size = (3, 3), stride = 2;
第三层:卷积3, 输入为第二层的输出,卷积核个数为384,kernel_size = (3 × 3 × 128),padding = 1,第三层没有做LRN和Pool;
第四层:卷积4, 输入为第三层的输出,卷积核个数为384,kernel_size = (3 × 3 × 192),padding = 1,和第三层一样,没有LRN和Pool;
第五层:卷积5, 输入为第四层的输出,卷积核个数为256,kernel_size = (3 × 3 × 192),padding = 1。然后直接进行max_pooling, pool_size = (3, 3), stride = 2;
第6,7,8层是全连接层,每一层的神经元的个数为4096,最终输出softmax为1000,因为上面介绍过,ImageNet这个比赛的分类个数为1000。全连接层中使用了Relu和Dropout。
2.数据集
数据集为猫狗的图片,其中猫的图片12500张,狗的图片12500张;训练数据集猫12300张,狗12300张,验证集猫100张,狗100张,测试集猫100张,狗100张;数据集链接:https://pan.baidu.com/s/11UHodPIHRDwHiRoae_fqtQ 提取码:d0fa;下图为训练集示意图:

3.数据集分类
将数据集中的猫和狗分别放在train_0和train_1中:
import os
import re
import shutil
origin_path = '/workspace/src/how-to-read-paper/dataset/train'
target_path_0 = '/workspace/src/how-to-read-paper/dataset/train_0/0'
target_path_1 = '/workspace/src/how-to-read-paper/dataset/train_0/1'
os.makedirs(target_path_0, exist_ok=True)
os.makedirs(target_path_1, exist_ok=True)
file_list = os.listdir(origin_path)
for i in range(len(file_list)):
old_path = os.path.join(origin_path, file_list[i])
result = re.findall(r'\w+', file_list[i])[0]
if result == 'cat':
shutil.move(old_path, target_path_0)
else:
shutil.move(old_path, target_path_1)4.模型搭建
进行模型搭建和数据导入:
import torch
import os
from torch import nn
from torch.nn import functional as F
from torch.autograd import Variable
import matplotlib.pyplot as plt
from torchvision.datasets import ImageFolder
import torch.optim as optim
import torch.utils.data
from PIL import Image
import torchvision.transforms as transforms
# 超参数设置
DEVICE = torch.device('cuda'if torch.cuda.is_available() else 'cpu')
EPOCH = 100
BATCH_SIZE = 256
# 卷积层和全连接层、前向传播
class AlexNet(nn.Module):
def __init__(self, num_classes=2):
super(AlexNet, self).__init__()
# 卷积层
self.features = nn.Sequential(
nn.Conv2d(3, 48, kernel_size=11),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(48, 128, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(128, 192, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
# 全连接层q
self.classifier = nn.Sequential(
nn.Linear(6*6*128, 2048),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(2048, 2048),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(2048, num_classes),
)
# 前向传播
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
# 训练集、测试集、验证集的导入
# 归一化处理
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
# 训练集
path_1 = '/workspace/src/how-to-read-paper/dataset/train_0'
trans_1 = transforms.Compose([
transforms.Resize((65, 65)),
transforms.ToTensor(),
normalize,
])
# 数据集
train_set = ImageFolder(root=path_1, transform=trans_1)
# 数据加载器
train_loader = torch.utils.data.DataLoader(train_set, batch_size=BATCH_SIZE, shuffle=True, num_workers=0)
# 测试集
path_2 = '/workspace/src/how-to-read-paper/dataset/test'
trans_2 = transforms.Compose([
transforms.Resize((65, 65)),
transforms.ToTensor(),
normalize,
])
test_data = ImageFolder(root=path_2, transform=trans_2)
test_loader = torch.utils.data.DataLoader(test_data, batch_size=BATCH_SIZE, shuffle=True, num_workers=0)
# 验证集
path_3 = '/workspace/src/how-to-read-paper/dataset/valid'
trans_3 = transforms.Compose([
transforms.Resize((65, 65)),
transforms.ToTensor(),
normalize,
])
valid_data = ImageFolder(root=path_3, transform=trans_3)
valid_loader = torch.utils.data.DataLoader(valid_data, batch_size=BATCH_SIZE, shuffle=True, num_workers=0)5.训练
进行模型训练:
# 定义模型
model = AlexNet().to(DEVICE)
# 优化器的选择
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9, weight_decay=0.0005)
def train_model(model, device, train_loader, optimizer, epoch):
train_loss = 0
model.train()
for batch_index, (data, label) in enumerate(train_loader):
data, label = data.to(device), label.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.cross_entropy(output, label)
loss.backward()
optimizer.step()
if batch_index % 300 == 0:
train_loss = loss.item()
print('Train Epoch:{}\ttrain loss:{:.6f}'.format(epoch, loss.item()))
return train_loss
def test_model(model, device, test_loader):
model.eval()
correct = 0.0
test_loss = 0.0
# 不需要梯度的记录
with torch.no_grad():
for data, label in test_loader:
data, label = data.to(device), label.to(device)
output = model(data)
test_loss += F.cross_entropy(output, label).item()
pred = output.argmax(dim=1)
correct += pred.eq(label.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('Test_average_loss:{:.4f}, Accuracy:{:3f}\n'.format(test_loss, 100*correct/len(test_loader.dataset)))
acc = 100*correct / len(test_loader.dataset)
return test_loss, acc
# 开始训练¶
list = []
Train_Loss_list = []
Valid_Loss_list = []
Valid_Accuracy_list = []
for epoch in range(1, EPOCH+1):
# 训练集训练
train_loss = train_model(model, DEVICE, train_loader, optimizer, epoch)
Train_Loss_list.append(train_loss)
torch.save(model, r'/workspace/src/how-to-read-paper/model/model%s.pth' % epoch)
# 验证集进行验证
test_loss, acc = test_model(model, DEVICE, valid_loader)
Valid_Loss_list.append(test_loss)
Valid_Accuracy_list.append(acc)
list.append(test_loss)6.测试
进行模型测试:
# 验证集的test_loss
min_num = min(list)
min_index = list.index(min_num)
print('model%s' % (min_index+1))
print('验证集最高准确率:')
print('{}'.format(Valid_Accuracy_list[min_index]))
# 取最好的进入测试集进行测试
model = torch.load('/workspace/src/how-to-read-paper/model/model%s.pth' % (min_index+1))
model.eval()
accuracy = test_model(model, DEVICE, test_loader)
print('测试集准确率')
print('{}%'.format(accuracy))7.实验结果分析
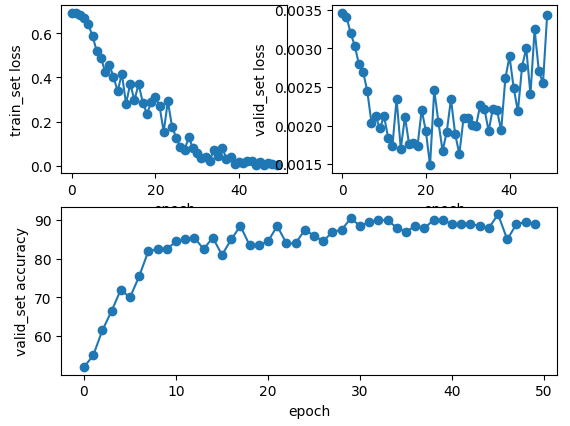
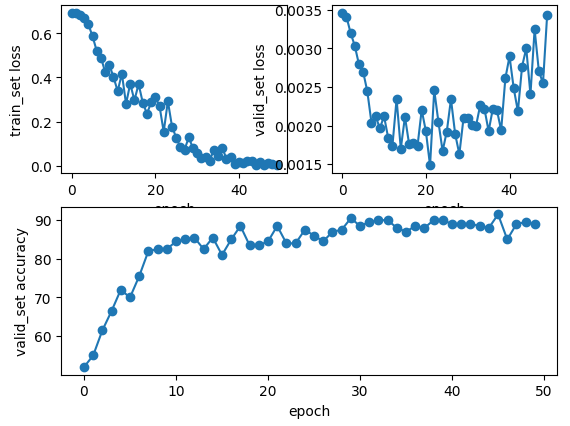
下图为epoch为50和100的loss和acc的折线图,其中使用最优的模型epoch=50时测试集的loss=0.00132, acc=89.0%;其中使用最优的模型epoch=100时测试集的loss=0.00203, acc=91.5%;从实验结果可以看出epoch=20时模型train已经很好了,那么想要train一个更好的模型有方法吗?答案肯定是有的,比如说做一下数据增强、使用正则化项、噪声注入等,这些大家都可以尝试一下。
注:本实验代码地址
AlexNet论文解读的更多相关文章
- AlexNet详细解读
AlexNet详细解读 目前在自学计算机视觉与深度学习方向的论文,今天给大家带来的是很经典的一篇文章 :<ImageNet Classification with Deep Convolutio ...
- 自监督学习(Self-Supervised Learning)多篇论文解读(下)
自监督学习(Self-Supervised Learning)多篇论文解读(下) 之前的研究思路主要是设计各种各样的pretext任务,比如patch相对位置预测.旋转预测.灰度图片上色.视频帧排序等 ...
- itemKNN发展史----推荐系统的三篇重要的论文解读
itemKNN发展史----推荐系统的三篇重要的论文解读 本文用到的符号标识 1.Item-based CF 基本过程: 计算相似度矩阵 Cosine相似度 皮尔逊相似系数 参数聚合进行推荐 根据用户 ...
- CVPR2019 | Mask Scoring R-CNN 论文解读
Mask Scoring R-CNN CVPR2019 | Mask Scoring R-CNN 论文解读 作者 | 文永亮 研究方向 | 目标检测.GAN 推荐理由: 本文解读的是一篇发表于CVPR ...
- AAAI2019 | 基于区域分解集成的目标检测 论文解读
Object Detection based on Region Decomposition and Assembly AAAI2019 | 基于区域分解集成的目标检测 论文解读 作者 | 文永亮 学 ...
- < AlexNet - 论文研读个人笔记 >
Alexnet - 论文研读个人笔记 一.论文架构 摘要: 简要说明了获得成绩.网络架构.技巧特点 1.introduction 领域方向概述 前人模型成绩 本文具体贡献 2.The Dataset ...
- Gaussian field consensus论文解读及MATLAB实现
Gaussian field consensus论文解读及MATLAB实现 作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 一.Introduction ...
- zz扔掉anchor!真正的CenterNet——Objects as Points论文解读
首发于深度学习那些事 已关注写文章 扔掉anchor!真正的CenterNet——Objects as Points论文解读 OLDPAN 不明觉厉的人工智障程序员 关注他 JustDoIT 等 ...
- NIPS2018最佳论文解读:Neural Ordinary Differential Equations
NIPS2018最佳论文解读:Neural Ordinary Differential Equations 雷锋网2019-01-10 23:32 雷锋网 AI 科技评论按,不久前,NeurI ...
- [论文解读] 阿里DIEN整体代码结构
[论文解读] 阿里DIEN整体代码结构 目录 [论文解读] 阿里DIEN整体代码结构 0x00 摘要 0x01 文件简介 0x02 总体架构 0x03 总体代码 0x04 模型基类 4.1 基本逻辑 ...
随机推荐
- 推文科技:AI解决方案助力内容出海
2017年,推文科技成立,推出业内针对网络文学的AI系统,助推网文批量出海.2018年,阿里云上线海外可用区,推文科技开始与阿里云合作. 创业宣言 创业是一件用行动去实践相信的事情,也许有一天,我 ...
- 最佳实践丨构建云上私有池(虚拟IDC)的5种方案详解
简介:云上私有池系列终篇终于来了,本文将重点介绍构建云上的私有池(虚拟IDC)的多种方案和各自的优缺点,并给出相关的性价比优化建议. 本文作者:阿里云技术专家李雨前 摘要 围绕私有池(虚拟IDC)的 ...
- dotnet 5 从 IL 层面分析协变返回类型新特性
在 C# 9.0 里面添加的一个新特性是支持协变返回类型,也就说子类重写了基类的抽象或虚拟方法,可以在返回值里面返回协变的类型,也就是返回值的类型可以是继承原本子类返回值类型的子类.本文将来从 IL ...
- Raft 共识算法4-选举限制
Raft 共识算法4-选举限制 Raft算法中译版地址:https://object.redisant.com/doc/raft中译版-2023年4月23日.pdf 英原论文地址:https://ra ...
- SQL server 游标使用实例
--创建一个游标 DECLARE my_cursor CURSOR FOR SELECT id, Bran_number, Bran_taxis FROM dbo.Base_Branch; --打开游 ...
- 推荐一款轻量级堡垒机系统让你防护“rm -rf 删库跑路”
大家好,我是 Java陈序员. 我们在开发工作中,会经常与服务器打交道,而服务器的资源又是十分宝贵,特别是服务器里面的数据资源. 但是,偶尔会经常因为疏忽而导致服务器数据资源丢失,给自己和公司带来巨大 ...
- Git——关于Git的一些补充(1)
Git--关于Git的一些补充(1) 提示:图床在国外且动图比较多的情况下,需要时间加载. 目录: 目录 Git--关于Git的一些补充(1) 提示:图床在国外且动图比较多的情况下,需要时间加载. 目 ...
- 一则current日志损坏的数据库恢复实例,隐藏参数的使用
场景 之前写了一篇文章,是redo日志全部丢失的情况下,数据库实例恢复的方式.但是,这次特殊在,实例恢复失败的情况下.非常规打开数据库(数据库已经不一致了,但是可以通过expdp导出,导出重要的数据) ...
- ruby http请求组件
github地址 https://github.com/rest-client/rest-client gemfile里添加 gem 'rest-client', '~> 2.0' 执行 bun ...
- 01. go-admin的下载与启动
目录 一.介绍 二.新建空文件夹 三.获取后台源码并启动 1.下载编译go代码 2.配置命令到goland IDE ,debug启动 四.获取前端ui源码并启动 1.下载编译go代码 2.启动项目 * ...