火山引擎DataLeap数据质量动态探查及相关前端实现
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
需求背景
- 无法看到探查的数据明细以及关联的行详情,无法对数据进行预处理操作。
- 探查还是需要资源调度,等待时长平均分钟级。
- 与质量监控没有打通,探查数据的后续走向不明确。
- 基于大数据预览的探查,支持对数据进行函数级别的预处理。
- 探查结果秒级更新,实时响应。
- 与数据监控打通,探索SQL的生成模式。
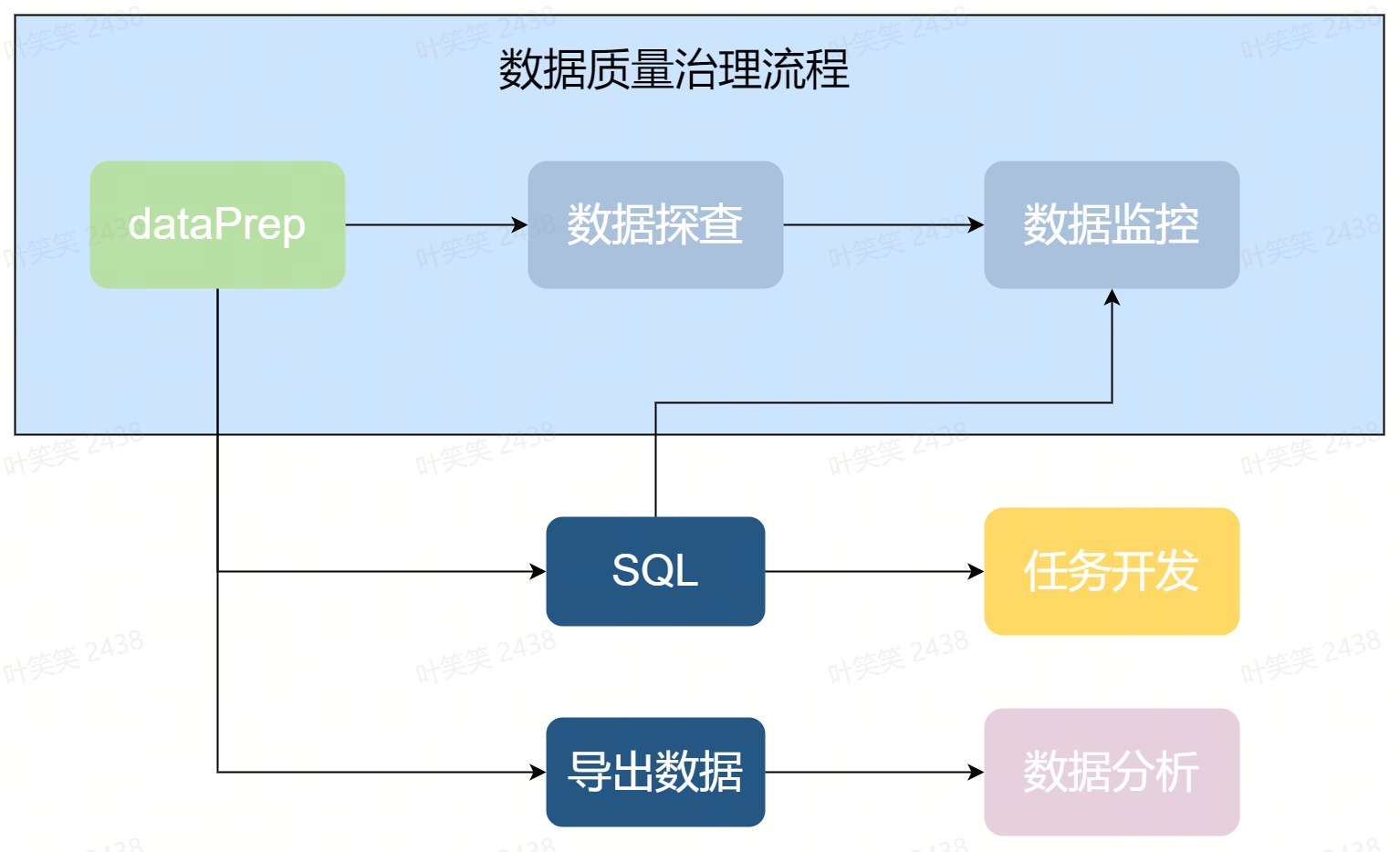
应用场景
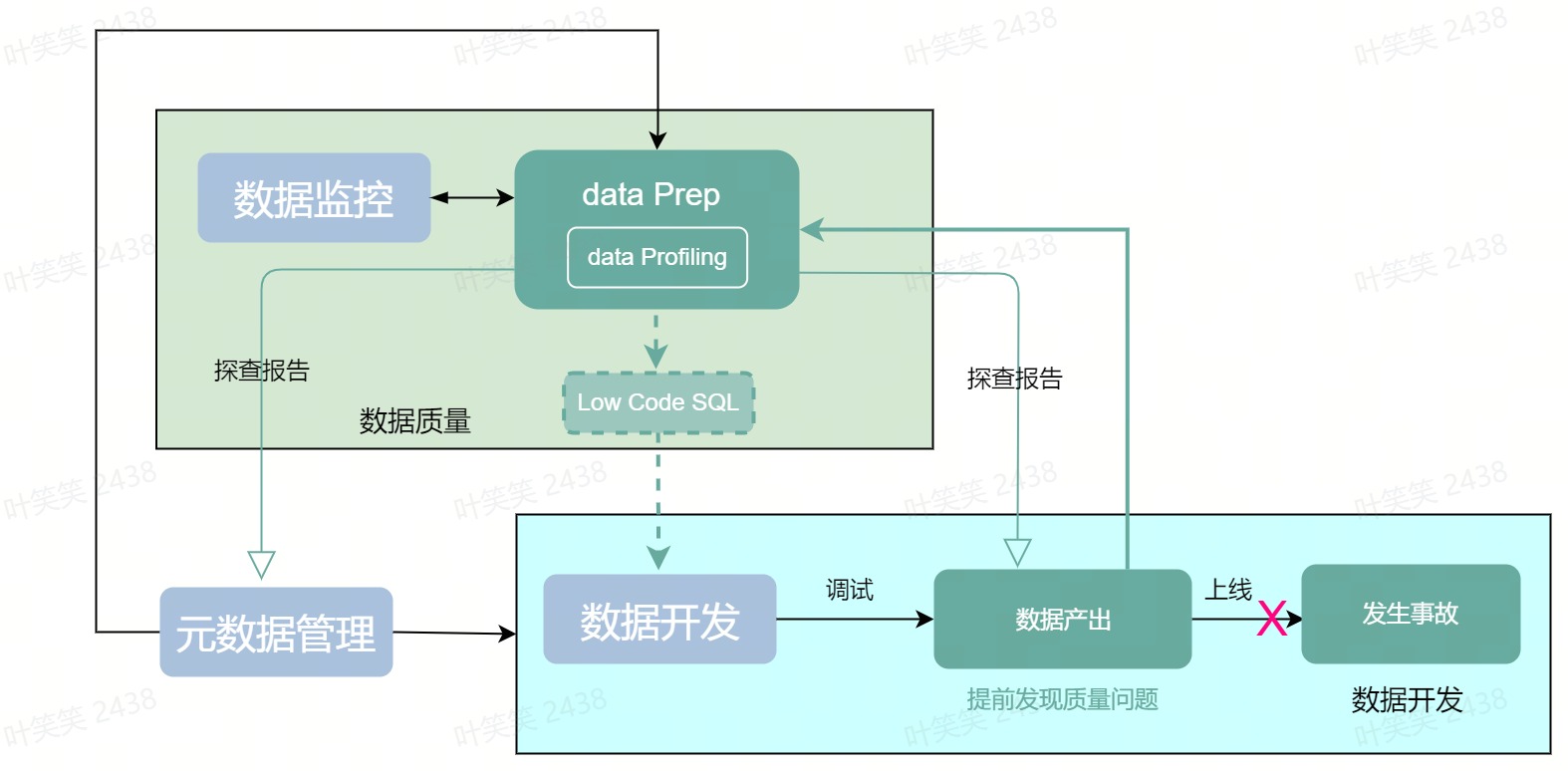
名词解释
全量探查:基于库表的全量探查,后端引擎执行,展示探查后列的统计分布结果。动态探查:基于抽样的部分数据探查,展示字段明细,可以使用操作对数据进行预处理,并实时动态的展示统计分布结果。数据获取后的过程都由前端执行。
技术实现
技术架构
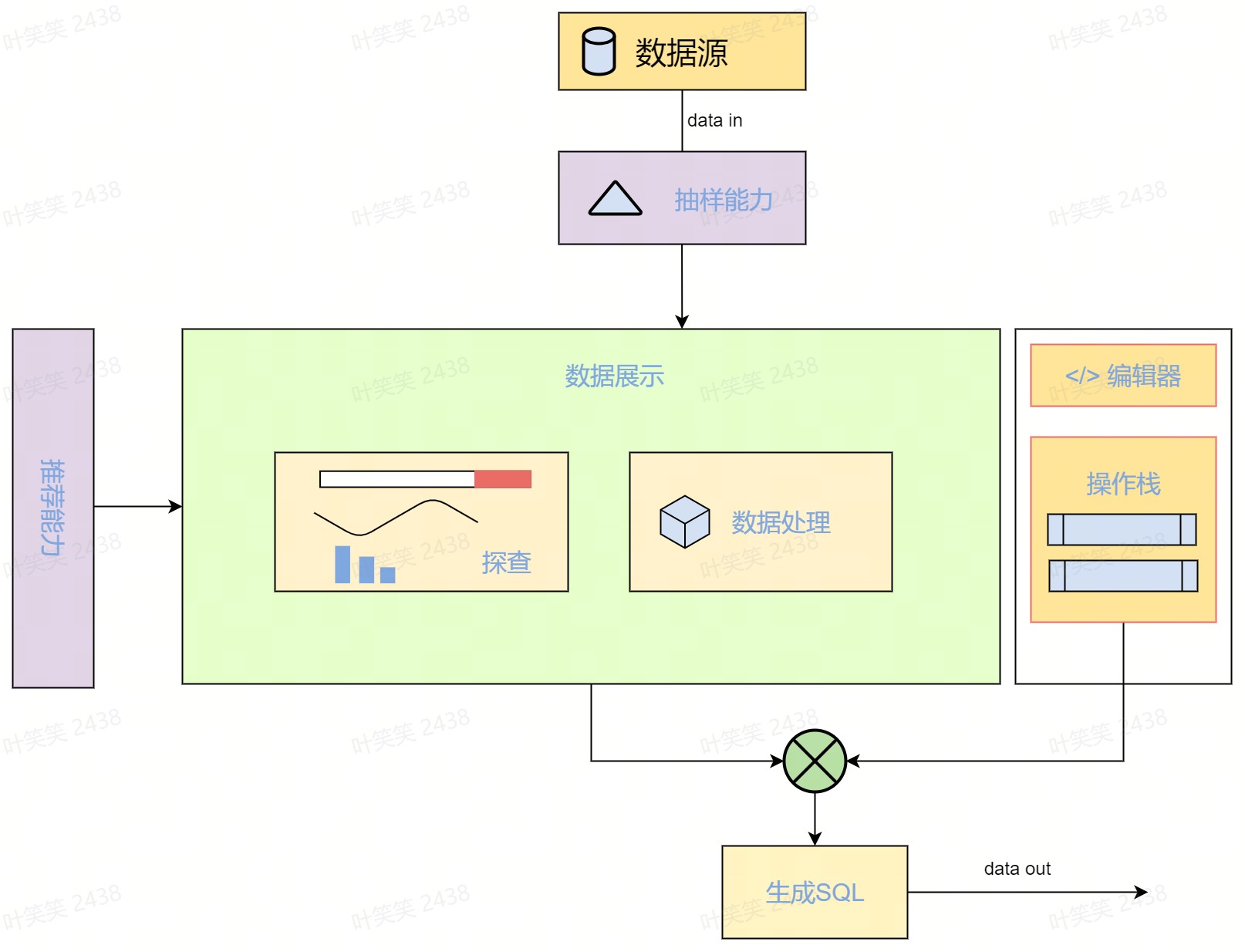
- 抽样能力:对数据进行基于质量分布特征的抽取。
- 数据展现:大容量的数据载体,支持对数据处理的实时展现。
- 前端探查:实时探查,可视化展现数据分布,突出质量指标。
- 数据处理能力:函数处理能力(GroupBy..)
- 操作栈:需要对数据操作进行管理和回溯
- 编辑器:提供完整函数的功能,需要:词法解析,智能提醒,语法高亮。
- 生成SQL:将可视化的交互式操作转换成可执行的SQL。
- 基于链式调用生成
- 基于标签模板生成
- 基于AST(抽象语法树)去做
关键技术及实现
大数据渲染
卡片联动

// 计算卡片中点坐标 index是卡片序号,adsorbSider表示是否吸边
getCardCenter(index: number, adsorbSider?: boolean) {
...
// 获取卡片信息
const cardBox: IBaseBox = this.cardList[index];
// 获取列信息
const colBox: IBaseBox = this.colList[index];
const clientWidth = getClientWidth();
if(adsorbSider) {
// 吸边处理
if(cardBox.offset < this.cardScroll) {
return cardBox.offset;
}
if(cardBox.offset + cardBox.width - this.cardScroll > clientWidth) {
return cardBox.offset + cardBox.width - clientWidth;
}
return this.cardScroll;
}
return getTargetPosition(colBox, this.tableScroll, cardBox);
} // 获取滚动目标位置
// originBox: 滚动起始对象
// originScroll: 滚动起始左侧scroll
// targetBox: 滚动结束对象
const getTargetPosition = (originBox: IBaseBox, originScroll: number, targetBox: IBaseBox) => {
const clientWidth = getClientWidth();
if(!originBox || !targetBox) return 0; let offsetLeftSider = Math.max(originBox?.offset - originScroll, 0);
if(offsetLeftSider + targetBox.width >= clientWidth) {
if(targetBox.offset + targetBox.width > clientWidth) {
// 此处容易出现吸边
return targetBox.offset + targetBox.width - clientWidth;
} else {
return 0;
}
}
const scroll = targetBox?.offset - offsetLeftSider + (targetBox.width - originBox.width) / 2;
return Math.max(
Math.min(targetBox.offset, scroll),
0
);
}
1. 选中卡片后,表格要自动滚动定位到下方居中对齐,无法满足对齐标准的,尽量靠近选中卡片位置。
2. 选中表格列后,卡片要自动滚动定位到上方居中对齐,无法满足对齐标准的,尽量靠近选中表格位置。
3. 搜索选中列后,卡片和表格要自动满足上面两个规则,并滚动到可视区域内。

操作栈
- 如何管理多种操作进行串行计算
Input + Logic = Ouput的结构,Input是输入参数,此处可以是指某一列的数据、上一步操作的结果或者其他计算值,Logic是操作的具体逻辑,负责根据Input转换生成Output,Output可以作为最终结果进行渲染,也可以再次进入下一环节参与计算,拿列删除操作举个栗子,下面是大体代码实现:class ColDelOpt {
run = (params: IOptEngineMetaInfo) => {
// 操作Input部分
const {
columns = [],
dataSourceMap = {}
} = params;
const {
fields = []
} = this.params;
// 操作Logic部分
const nextColumns = columns.filter((item) => !fields.includes(item.name));
// 操作的Output
return {
columns: nextColumns,
dataSourceMap
}
}
}
- 某个操作被修改后如何进行二次计算
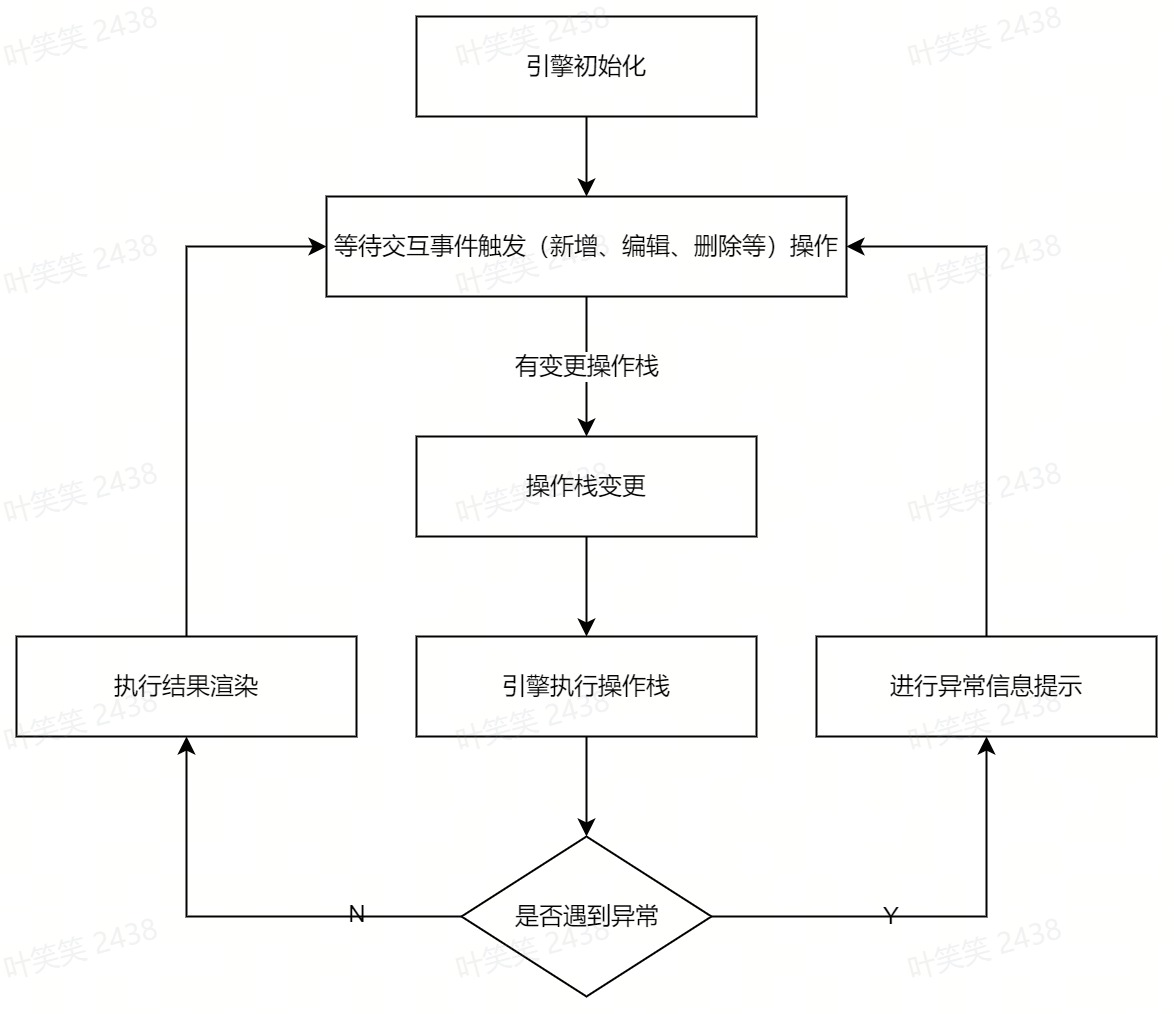
// 操作引擎
class OptEngine { // 操作列表
private optList: IOptEngineItem[] = []; // 原始数据
private metaData: IOptEngineMetaInfo = {
columns: [],
dataSourceMap: {},
}; // 执行算子
optRun = () => {
let {
columns = [],
dataSourceMap = {}
} = this.metaData; if(!this.optList.length) return {
columns,
dataSourceMap
}; for(let index = 0; index < this.optList.length; index++) {
// 读取操作算子
const optItem = this.optList[index];
let startTime = performance.now(); try {
// 执行算子计算
const result = optItem.run({
columns,
dataSourceMap
}); // 更新算子结果
columns = result.columns || [];
dataSourceMap = result.dataSourceMap || {};
} catch(e) {
// 报错后直接直接返回
return {
columns,
dataSourceMap,
// 装填报错信息
errorInfo: {
key: optItem.key || '',
message: e.message
}
}
}
} return {
columns,
dataSourceMap,
}
} autoRun = (
metaInfo: IOptEngineMetaInfo,
optList: IOptItem[],
callback: (params: IAutoRunResult) => void
) => {
// 装填数据
this.setupMetaData(metaInfo);
// 装填操作栈
this.setupOptList(optList.map((item) => {
// 行过滤
if(item.type === OPT_TYPE.FILTER) {
return new FilterOpt({
key: item.key,
params: item.params
})
}
// 其余类型操作
...
// 默认原值返回
return new IdentityOpt({
key: item.key,
})
})); // 执行操作计算
const result = this.optRun(); // 返回数据
return {
// 计算列
columns: result.columns,
// 执行结果
dataSource: Object.entries(result.dataSourceMap).map(([key, value]) => ({
field: key,
value
})),
// 操作栈执行异常信息
errorInfo: result.errorInfo
};
}
}
应用实践
后续计划
- 更多的探查类型和图表支持
- 操作栈的编辑器体验
- 操作流程的SQL生成
火山引擎DataLeap数据质量动态探查及相关前端实现的更多相关文章
- 火山引擎DataLeap数据调度实例的 DAG 优化方案
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,并进入官方交流群 实例 DAG 介绍 DataLeap 是火山引擎自研的一站式大数据中台解决方案,集数据集成.开发.运维.治理.资产管理能力 ...
- 火山引擎 DataLeap:揭秘字节跳动数据血缘架构演进之路
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维 ...
- 火山引擎 DataLeap:3 个关键步骤,复制字节跳动一站式数据治理经验
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,并进入官方交流群 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维.治理. ...
- 火山引擎 DataLeap:一家企业,数据体系要怎么搭建?
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 导读:经过十多年的发展,数据治理在传统行业以及新兴互联网公司都已经产生落地实践.字节跳动也在探索一种分布式的数据治 ...
- 火山引擎 DataLeap 的 Data Catalog 系统公有云实践
Data Catalog 通过汇总技术和业务元数据,解决大数据生产者组织梳理数据.数据消费者找数和理解数的业务场景.本篇内容源自于火山引擎大数据研发治理套件 DataLeap 中的 Data Ca ...
- 如何又快又好实现 Catalog 系统搜索能力?火山引擎 DataLeap 这样做
摘要 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维.治理.资产.安全等全套数据中台建设,降低工作成本和数据维护成本.挖掘数据价 ...
- DataLeap 数据资产实战:如何实现存储优化?
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 背景 DataLeap 作为一站式数据中台套件,汇集了字节内部多年积累的数据集成.开发.运维.治理.资产.安全等全 ...
- JuiceFS 在火山引擎边缘计算的应用实践
火山引擎边缘云是以云计算基础技术和边缘异构算力结合网络为基础,构建在边缘大规模基础设施之上的云计算服务,形成以边缘位置的计算.网络.存储.安全.智能为核心能力的新一代分布式云计算解决方案. 01- 边 ...
- 如何在HHDI中进行数据质量探查并获取数据剖析报告
通过执行多种数据剖析规则,对目标表(或一段SQL语句)进行数据质量探查,从而得到其数据质量情况.目前支持以下几种数据剖析类型,分别是:数字值分析.值匹配检查.字符值分析.日期值分析.布尔值分析.重复值 ...
- FME之于规划CAD数据质量检测
最近琢磨规划CAD数据转换入库GIS方面的技术问题,看过一些前辈的文章/文献,对于使用FME WorkBench方面,有了一些了解,往往直接转换数据丢失比较严重,而且GIS对图形属性和空间拓扑比较严格 ...
随机推荐
- P8815 [CSP-J 2022] 逻辑表达式
Problem 考察算法:后缀表达式计算.建表达式树.\(DFS\). 题目简述 给你一个中缀表达式,其中只有 \(\&\) 和 \(\mid\) 两种运算. 求:\(\&\) 和 \ ...
- QT(4)-QAbstractItemView
@ 目录 1 说明 2 常用函数 2.1 交替行颜色 2.1.1 alternatingRowColors 2.1.2 setAlternatingRowColors 2.2 autoScroll 2 ...
- 使用TS进行Vue-Router的Meta类型扩展
目录 1.前言 2.解决 1.前言 使用Vue-Router时,会将一些字段信息附加到路由的Meta对象里面,比如图标icon,标题,权限等,如下: { path: '/billboard/board ...
- 老知识复盘-SQL从提交到执行到底经历了什么
一.什么是SQL sql(Structured Query Language: 结构化查询语言)是高级的费过程化编程语言,允许用户在高层数据结构上工作, 是一种数据查询和程序设计语言, 也是(ANSI ...
- MySQL-防止误删除的方案就是删除,看不见岂不就是删除了吗,所以就是把它隐藏起来。
版权声明:原创作品,谢绝转载!否则将追究法律责任. ----- 作者:kirin 伪删除: 用update替代delete 1.添加状态列 ALTER TABLE student2 ADD state ...
- 使用Slurm集群进行分布式图计算:对Github网络影响力的系统分析
本文分享自华为云社区<基于Slurm集群的分布式图计算应用实践:Github协作网络影响力分析>,作者:yd_263841138 . 1. 引言 Slurm(Simple Linux Ut ...
- 深入解析LLaMA如何改进Transformer的底层结构
本文分享自华为云社区<大语言模型底层架构你了解多少?LLM大底层架构之LLM模型结构介绍>,作者: 码上开花_Lancer . 大语言模型结构当前绝大多数大语言模型结构都采用了类似GPT ...
- STM32外设:专用定时器 IWDG、WWDG、RTC
主要外设: IWDG:Independent Watch DoG 独立看门狗 WWDG:Window Watch DoG 窗口看门狗 RTC: Real-Time Clock 实时时钟 IWDG 主要 ...
- 研发提效必备技能:手把手教你基于Docker搭建Maven私服仓库
沉淀,成长,突破,帮助他人,成就自我. 大家好,我是冰河~~ 在研发的过程中,很多企业都会针对自身业务特点来定制研发一些工具类库,但是这些工具类库又不会对外公开,那如何在组织内部共享这些类库呢?一种很 ...
- NetSuite 开发日记:创建 Transfer(转账单)
经测试,截止到 2022.12.26,Transfer 只能使用 Client 脚本创建,使用服务端脚本创建报错:ReferenceError: "document" is not ...