DeepSpeed框架:1-大纲和资料梳理
DeepSpeed是一个深度学习优化软件套件,使分布式训练和推理变得简单、高效和有效。它可以做些什么呢?训练/推理具有数十亿或数万亿参数的密集或稀疏模型;实现出色的系统吞吐量并有效扩展到数千个GPU;在资源受限的GPU系统上进行训练/推理;实现前所未有的低延迟和高吞吐量的推理;以低成本实现极限压缩,实现无与伦比的推理延迟和模型尺寸减小。特别说明,DeepSpeed在Windows上仅支持推理,不支持训练。
一.DeepSpeed四大创新支柱

1.DeepSpeed-Training
DeepSpeed提供了系统创新的融合,使大规模深度学习训练变得有效、高效,大大提高了易用性,并在可能的规模方面重新定义了深度学习训练版图。ZeRO、3D-Parallelism、DeepSpeed-MoE、ZeRO-Infinity等创新属于培训支柱[2]。
2.DeepSpeed-Inference
DeepSpeed汇集了tensor、pipeline、expert和ZeRO-parallelism等并行技术的创新,并将它们与高性能定制推理内核、通信优化和异构内存技术相结合,以前所未有的规模实现推理,同时实现无与伦比的延迟、吞吐量和性能。降低成本。这种推理系统技术的系统组合属于推理支柱[3]。
3.DeepSpeed-Compression
为了进一步提高推理效率,DeepSpeed为研究人员和从业人员提供易于使用且组合灵活的压缩技术来压缩他们的模型,同时提供更快的速度、更小的模型大小并显着降低的压缩成本。此外,ZeroQuant和XTC等SoTA在压缩方面的创新也包含在压缩支柱下[4]。
4.DeepSpeed4Science
觉得离自己好遥远,就不介绍这个了[5]。
5.DeepSpeed软件架构
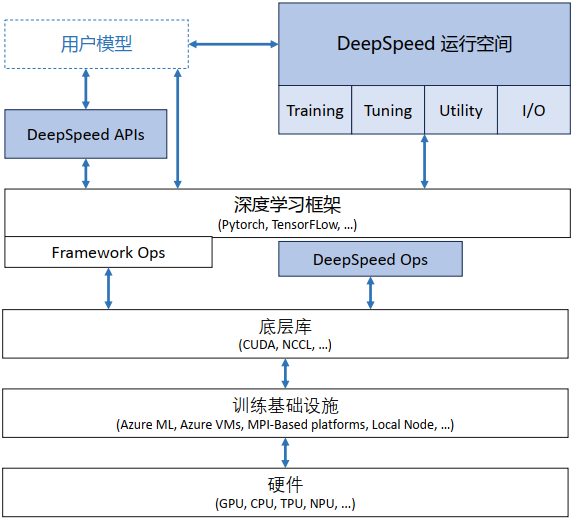
(1)APIs:配置参数都在ds_config.json文件中,上层通过简单的API接口就可以训练模型和推断。
(2)RunTime:DeepSpeed的核心运行时组件,使用Python语言实现,负责管理、执行和优化性能。它承担了将训练任务部署到分布式设备的功能,包括数据分区、模型分区、系统优化、微调、故障检测以及检查点的保存和加载等任务。
(3)DeepSpeed的底层内核组件,使用C++和CUDA实现。它优化计算和通信过程,提供了一系列底层操作等。
二.分布式模型训练
分布式模型训练包括:数据并行,模型并行(张量并行和流水线并行),混合并行。如下所示:
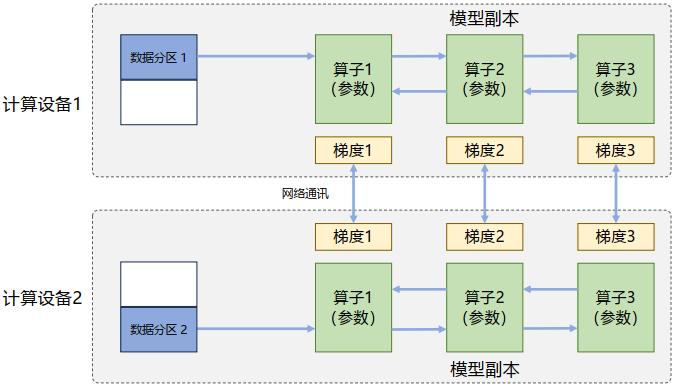
1.数据并行
在数据并行系统中,每个计算设备都有整个神经网络模型的完整副本(Model Replica),进行迭代时,每个计算设备只分配了一个批次数据样本的子集,并根据该批次样本子集的数据进行网络模型的前向计算。如下所示:
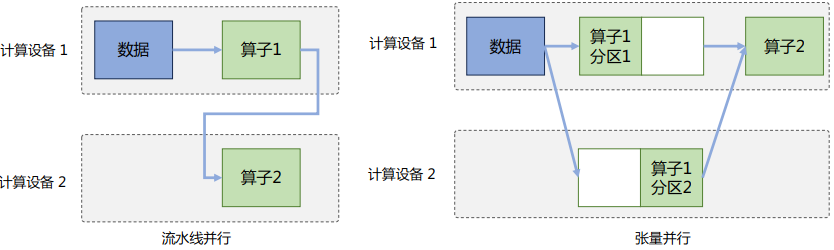
2.模型并行
模型并行(Model Parallelism)往往用于解决单节点内存不足的问题。模型并行可以从计算图角度,以下两种形式进行切分:按模型的层切分到不同设备,即层间并行或算子间并行(Inter-operator Parallelism),也称之为流水线并行(Pipeline Parallelism,PP);将计算图层内的参数切分到不同设备,即层内并行或算子内并行(Intra-operator Parallelism),也称之为张量并行(Tensor Parallelism,TP)。如下所示:
3.混合并行
混合并行(Hybrid Parallelism,HP)是将多种并行策略如数据并行、流水线并行和张量并行等进行混合使用。通过结合不同的并行策略,混合并行可以充分发挥各种并行策略的优点,以最大程度地提高计算性能和效率。如下所示:
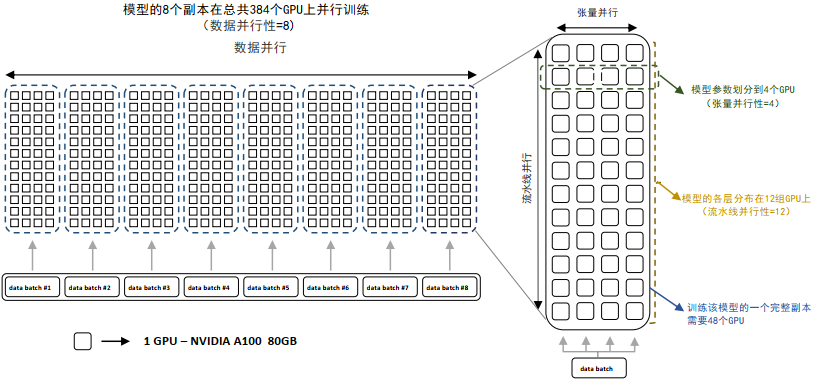
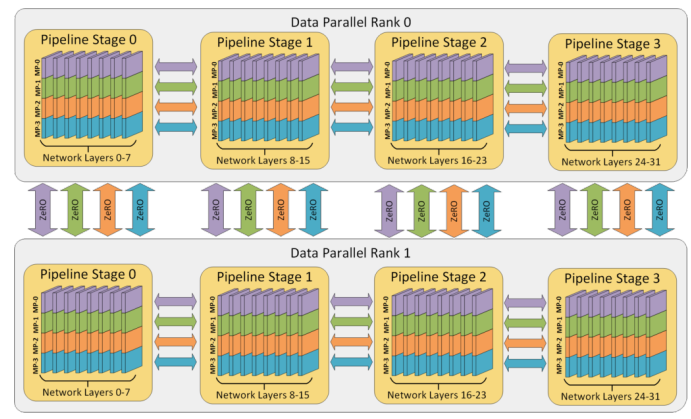
4.DeepSpeed 3D并行策略示意图
图中给出了包含32个计算设备进行3D并行的例子。神经网络的各层分为4个流水线阶段。每个流水线阶段中的层在4个张量并行计算设备之间进一步划分。最后,每个流水线阶段有两个数据并行实例,使用ZeRO内存优化在这2个副本之间划分优化器状态量。如下所示:
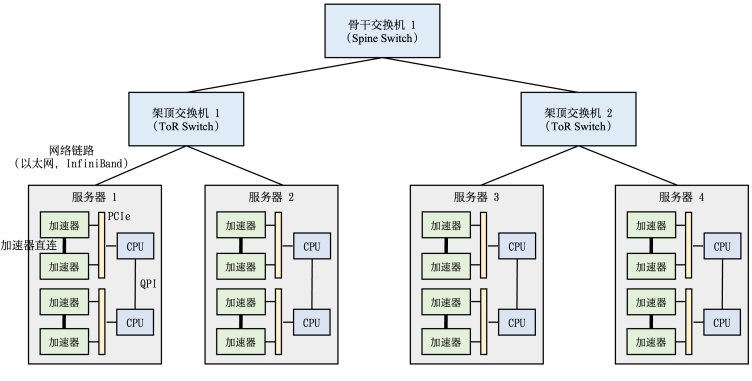
5.典型HPC集群硬件组成
整个计算集群包含大量带有计算加速设备的服务器。每个服务器中往往有多个计算加速设备(通常2-16个)。多个服务器会被放置在一个机柜(Rack)中,服务器通过架顶交换机(Top of Rack Switch,ToR)连接网络。在架顶交换机满载的情况下,可以通过在架顶交换机间增加骨干交换机(Spine Switch)进一步接入新的机柜。这种连接服务器的拓扑结构往往是一个多层树(Multi-Level Tree)。如下所示:
三.如何存储参数
1.Model States
解析:模型本身相关且必须存储的内容,如下所示:
(1)Parameters:模型参数
(2)Gradients:模型梯度
(3)Optimizer States:Adam优化算法中的momentum和variance
2.Residual States
解析:非模型本身必须,但在训练过程中产生的内容,如下所示:
(1)Activation:激活值
(2)Temporary Buffers:临时存储
(3)Unusable Fragmented Memory:碎片化存储空间
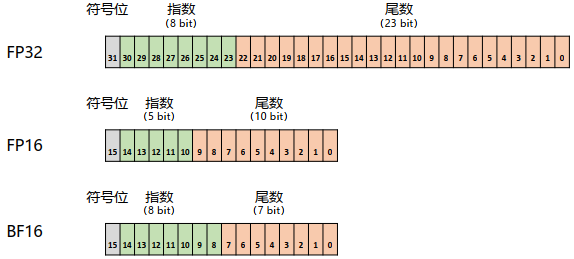
3.混合精度训练
解析:混合精度训练就是一部分参数使用FP16(4B)存储,另一部分参数使用FP16或BF16(2B)存储,以此来减轻存储压力。FP32中第31位为符号位,第30到第23位用于表示指数,第22到第0位用于表示尾数。FP16中第15位为符号位,第14到第10位用于表示指数,第9到第用于表示尾数。BF16中第15位为符号位,第14到第7位用于表示指数,第6到第0位用于表示尾数。如下所示:
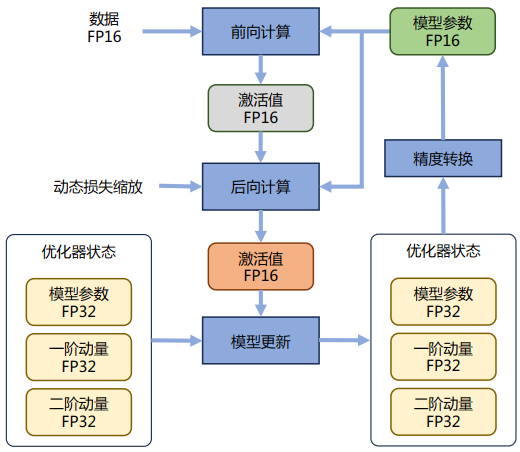
混合精度优化过程,如下所示:
四.如何优化储存
零冗余优化器(ZeRO)是一种用于大规模分布式深度学习的新颖内存优化技术,它可以大大减少模型和数据并行性所需的资源,同时可以大量增加可训练的参数数量。本质就是用完即弃,需要再补。如下所示:
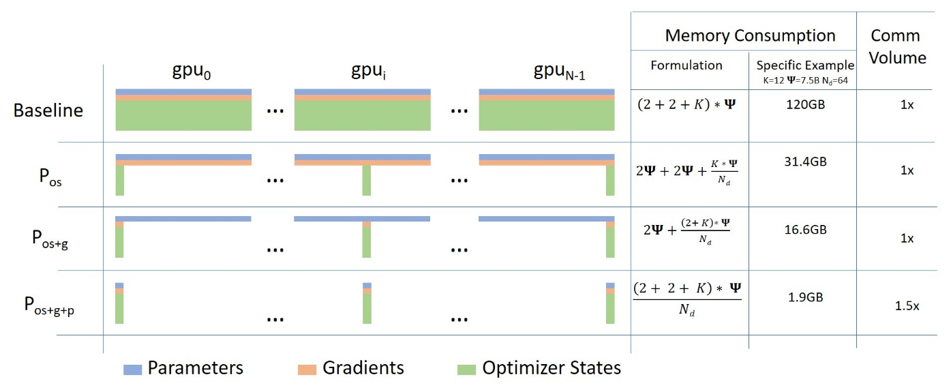
ZeRO是一系列显存优化方法的统称,它分为ZeRO-DP(Zero Redundancy Optimizer-Data Parallel)和ZeRO-R(Zero Redundancy Optimizer-Reduce)两部分。如下所示:
1.ZeRO-DP
(1)ZeRO-1
ZeRO-1对优化器状态都进行分片,占用内存为原始的1/4,通信容量与数据并行性相同。
(2)ZeRO-2
ZeRO-2对优化器状态和梯度都进行分片,占用内存为原始的1/8,通信容量与数据并行性相同。
(3)ZeRO-3
ZeRO-3对优化器状态、梯度以及模型参数都进行分片,内存减少与数据并行度和复杂度成线性关系,同时通信容量是数据并行性的1.5倍。
论文:ZeRO:Memory Optimizations Toward Training Trillion Parameter Models:https://arxiv.org/pdf/1910.02054.pdf
2.ZeRO-R
(1)激活检查点(Partitioned Activation Checkpointing)
activation的存储非常灵活,更需要设计好实验。
(2)临时缓冲区(Constant Size Buffer)
固定大小的内存Buffer。
(3)空间管理(Memory Defragmentation)
主要是将碎片化内存空间重新整合为连续存储空间。
3.ZeRO-Offload
本质就是显存不够,内存来凑。ZeRO-Offload分为Offload Strategy和Offload Schedule两部分,前者解决如何在GPU和CPU间划分模型的问题,后者解决如何调度计算和通信的问题。
论文:ZeRO-Offload:Democratizing Billion-Scale Model Training:https://arxiv.org/pdf/2101.06840.pdf
4.ZeRO-Infinity
ZeRO-Infinity是ZeRO-3的拓展,允许通过使用NVMe固态硬盘扩展GPU和CPU内存来训练大型模型。
论文:ZeRO-Infinity:Breaking the GPU Memory Wall for Extreme Scale Deep Learning:https://arxiv.org/pdf/2104.07857.pdf
本文只是一个大纲框架,后续打算针对DeepSpeed和Megatron-LM框架写一个源码解读教程,以前总认为写软件没啥意思,现在发现分布式机器学习系统还是很有意思的,如果算法给力,直观可见的节省存储,提高训练效率,降低推理的延时和增加高吞吐量。
参考文献:
[1]DeepSpeed项目地址:https://github.com/microsoft/DeepSpeed
[2]DeepSpeed训练:https://www.deepspeed.ai/training/
[3]DeepSpeed推理:https://www.deepspeed.ai/inference
[4]DeepSpeed压缩:https://www.deepspeed.ai/compression
[5]DeepSpeed4Science网站和教程:https://deepspeed4science.ai/和https://www.deepspeed.ai/deepspeed4science/
[6]DeepSpeed入门:https://www.deepspeed.ai/getting-started/
[7]DeepSpeed JSON配置:https://www.deepspeed.ai/docs/config-json/
[8]DeepSpeed API文档:https://deepspeed.readthedocs.io/en/latest/
[9]DeepSpeed教程:https://www.deepspeed.ai/tutorials/
[10]DeepSpeed博客:https://www.deepspeed.ai/posts/
[11]deepspeed-mii:https://github.com/microsoft/deepspeed-mii
[12]Transformer DeepSpeed集成:https://huggingface.co/docs/transformers/main/main_classes/deepspeed
[13]DeepSpeed官方文档:https://deepspeed.readthedocs.io/en/latest/
[14]ZeRO & DeepSpeed: New system optimizations enable training models with over 100 billion parameters:https://www.microsoft.com/en-us/research/blog/ZeRO-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters/
[15]《大规模语言模型:从理论到实践》
DeepSpeed框架:1-大纲和资料梳理的更多相关文章
- 《精通Python爬虫框架Scrapy》学习资料
<精通Python爬虫框架Scrapy>学习资料 百度网盘:https://pan.baidu.com/s/1ACOYulLLpp9J7Q7src2rVA
- 【微服务】使用spring cloud搭建微服务框架,整理学习资料
写在前面 使用spring cloud搭建微服务框架,是我最近最主要的工作之一,一开始我使用bubbo加zookeeper制作了一个基于dubbo的微服务框架,然后被架构师否了,架构师曰:此物过时.随 ...
- Java集合框架系列大纲
###Java集合框架之简述 Java集合框架之Collection Java集合框架之Iterator Java集合框架之HashSet Java集合框架之TreeSet Java集合框架之Link ...
- Java基础19:Java集合框架梳理
更多内容请关注微信公众号[Java技术江湖] 这是一位阿里 Java 工程师的技术小站,作者黄小斜,专注 Java 相关技术:SSM.SpringBoot.MySQL.分布式.中间件.集群.Linux ...
- 最新 iOS 框架整体梳理(二)
在前面一篇中整理出来了一些了,下面的内容是接着上面一篇的接着整理.上篇具体的内容可以点击这里查看: 最新 iOS 框架整体梳理(一) Part - 2 34.CoreTeleph ...
- 最全各种系统版本的XPosed框架资料下载整理
由于XPosed在不同安卓系统版本中对应的版本不同,给很多新手造成极大困扰,本文作者经过几番努力,给大家整理了各个版本对应的xposed框架版本以及相关资料,并附上相关下载链接,希望对大伙有所帮助. ...
- 【深度学习Deep Learning】资料大全
最近在学深度学习相关的东西,在网上搜集到了一些不错的资料,现在汇总一下: Free Online Books by Yoshua Bengio, Ian Goodfellow and Aaron C ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料(Chapter 2)
##机器学习(Machine Learning)&深度学习(Deep Learning)资料(Chapter 2)---#####注:机器学习资料[篇目一](https://github.co ...
- 前端Js框架汇总【转】
概述: 有些日子没有正襟危坐写博客了,互联网飞速发展的时代,技术更新迭代的速度也在加快.看着Java.Js.Swift在各领域心花路放,也是煞是羡慕.寻了寻.net的消息,也是振奋人心,.net co ...
- WEB前端JS与UI框架
前端Js框架汇总 概述: 有些日子没有正襟危坐写博客了,互联网飞速发展的时代,技术更新迭代的速度也在加快.看着Java.Js.Swift在各领域心花路放,也是煞是羡慕.寻了寻.net的消息,也是振奋人 ...
随机推荐
- 一文了解Go语言的I/O接口设计
1. 引言 I/O 操作在编程中扮演着至关重要的角色.它涉及程序与外部世界之间的数据交换,允许程序从外部,如键盘.文件.网络等地方读取数据,也能够将外界输入的数据重新写入到目标位置中.使得程序能够与外 ...
- JavaCV人脸识别三部曲之二:训练
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 本篇概览 本文是<JavaCV人脸识别三部曲&g ...
- 一个跨平台的`ChatGPT`悬浮窗工具
一个跨平台的ChatGPT悬浮窗工具 使用avalonia实现的ChatGPT的工具,设计成悬浮窗,并且支持插件. 如何实现悬浮窗? 在使用avalonia实现悬浮窗也是非常的简单的. 实现我们需要将 ...
- gitlab配置环境及pycharm配置
一.gitlab介绍 GitLab 是一个用于仓库管理系统的开源项目,使用Git作为代码管理工具,并在此基础上搭建起来的web服务 git.gitlab.GitHub的简单区别 git 是一种基于命令 ...
- TCP/IP网络体系结构中,各层的作用,以及各层协议的作用。
1.[TCP/IP]协议中每层的作用 从协议分层模型方面来讲,TCP/IP由四个层次组成:数据链路层(网络接口层).网络层.传输层.应用层 TCP/IP网络体系结构中,各层作用: 1.网络接口层:负责 ...
- QOJ 6504. CCPC Final 2022 D Flower's Land 2题解
QOJ 6504. CCPC Final 2022 D Flower's Land 2题解 题意简述 给你一个只含 \(0,1,2\) 的序列,相邻两个相同的数字可以直接消掉. 询问包含两种 区间所有 ...
- 【Azure API Management】实现在API Management服务中使用MI(管理标识 Managed Identity)访问启用防火墙的Storage Account
问题描述 在Azure的同一数据中心,API Management访问启用了防火墙的Storage Account,并且把APIM的公网IP地址设置在白名单.但访问依旧是403 原因是: 存储帐户部署 ...
- java协程线程之虚拟线程
前言 众所周知,java 是没有协程线程的,在我们如此熟知的jdk 1.8时代,大佬们想出来的办法就是异步io,甚至用并行的stream流来实现,高并发也好,缩短事件处理时间也好:大家都在想着自己认为 ...
- [Spring+SpringMVC+Mybatis]框架学习笔记(五):SpringAOP_顾问
上一章:[Spring+SpringMVC+Mybatis]框架学习笔记(四):Spring实现AOP 下一章:[Spring+SpringMVC+Mybatis]框架学习笔记(六):Spring_A ...
- Ubuntu16.04配置NTP时间同步
环境 查看系统版本:lsb_release -a 名词解释 PDT是指太平洋夏令时(Pacific Daylight Time),是美国西部地区和加拿大的一部分地区使用的时区.它位于UTC-7和UTC ...