如何优雅重启 kubernetes 的 Pod

最近在升级服务网格 Istio,升级后有个必要的流程就是需要重启数据面的所有的 Pod,也就是业务的 Pod,这样才能将这些 Pod 的 sidecar 更新为新版本。
方案 1
因为我们不同环境的 Pod 数不少,不可能手动一个个重启;之前也做过类似的操作:
kubectl delete --all pods --namespace=dev
这样可以一键将 dev 这个命名空间下的 Pod 删掉,kubernetes 之后会自动将这些 Pod 重启,保证和应用的可用性。
但这有个大问题是对 kubernetes 的调度压力较大,一般一个 namespace 下少说也是几百个 Pod,全部需要重新调度启动对 kubernetes 的负载会很高,稍有不慎就会有严重的后果。
所以当时我的第一版方案是遍历所有的 deployment,删除一个 Pod 后休眠 5 分钟再删下一个,伪代码如下:
deployments, err := clientSet.AppsV1().Deployments(ns).List(ctx, metav1.ListOptions{})
if err != nil {
return err
}
for _, deployment := range deployments.Items {
podList, err := clientSet.CoreV1().Pods(ns).List(ctx, metav1.ListOptions{
LabelSelector: fmt.Sprintf("app=%s", deployment.Name),
})
err = clientSet.CoreV1().Pods(pod.Namespace).Delete(ctx, pod.Name, metav1.DeleteOptions{})
if err != nil {
return err
}
log.Printf(" Pod %s rebuild success.\n", pod.Name)
time.Sleep(time.Minute * 5)
}
存在的问题
这个方案确实是简单粗暴,但在测试的时候就发现了问题。
当某些业务只有一个 Pod 的时候,直接删掉之后这个业务就挂了,没有多余的副本可以提供服务了。
这肯定是不能接受的。
甚至还有删除之后没有重启成功的:
- 长期没有重启导致镜像缓存没有了,甚至镜像已经被删除了,这种根本就没法启动成功。
- 也有一些 Pod 有
Init-Container会在启动的时候做一些事情,如果失败了也是没法启动成功的。
总之就是有多种情况导致一个 Pod 无法正常启动,这在线上就会直接导致生产问题,所以方案一肯定是不能用的。
方案二
为此我就准备了方案二:
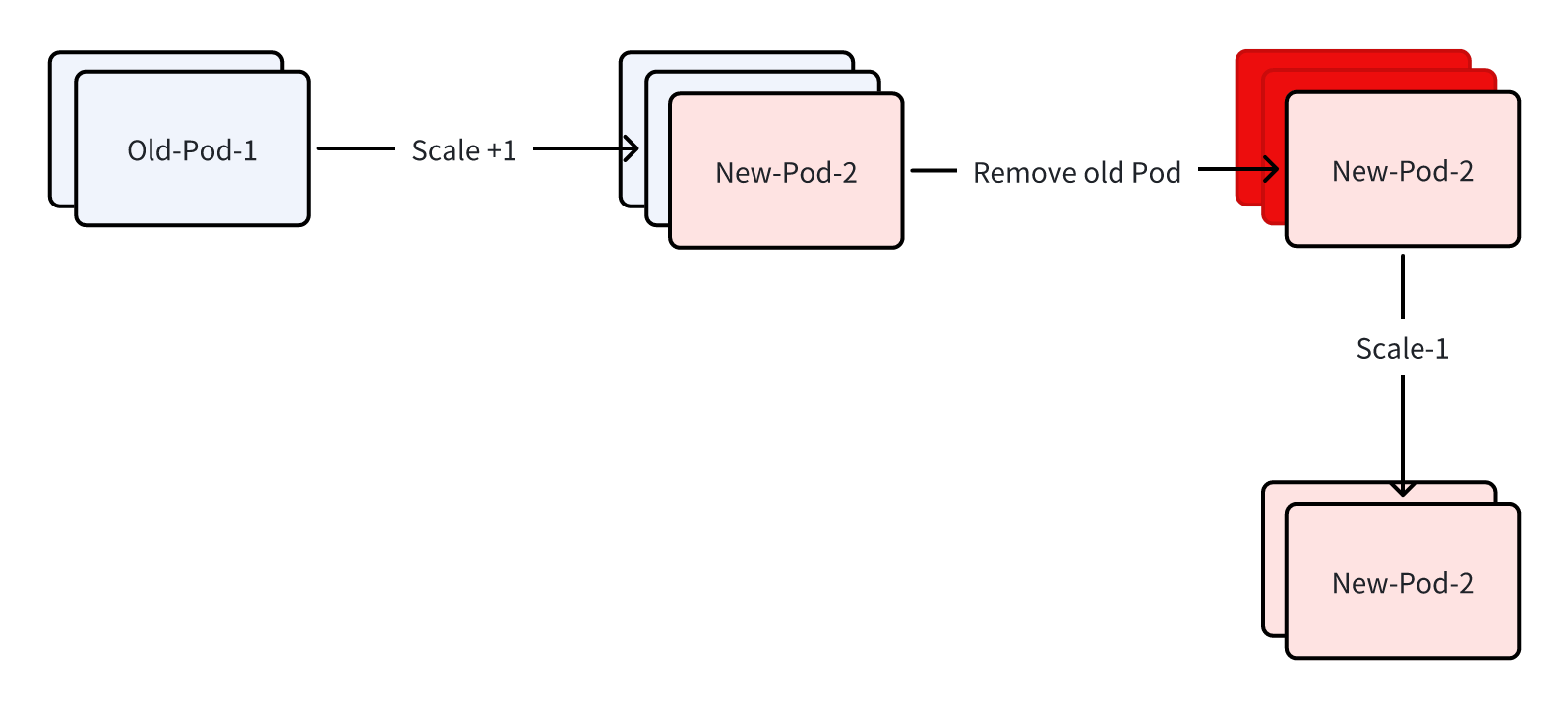
- 先将副本数+1,这是会新增一个 Pod,也会使用最新的 sidecar 镜像。
- 等待新建的 Pod 重启成功。
- 重启成功后删除原有的 Pod。
- 再将副本数还原为之前的数量。
这样可以将原有的 Pod 平滑的重启,同时如果新的 Pod 启动失败也不会继续重启其他 Deployment 的 Pod,老的 Pod 也是一直保留的,对服务本身没有任何影响。
存在的问题
看起来是没有什么问题的,就是实现起来比较麻烦,流程很繁琐,这里我贴了部分核心代码:
func RebuildDeploymentV2(ctx context.Context, clientSet kubernetes.Interface, ns string) error {
deployments, err := clientSet.AppsV1().Deployments(ns).List(ctx, metav1.ListOptions{})
if err != nil {
return err
}
for _, deployment := range deployments.Items {
// Print each Deployment
log.Printf("Ready deployment: %s\n", deployment.Name)
originPodList, err := clientSet.CoreV1().Pods(ns).List(ctx, metav1.ListOptions{
LabelSelector: fmt.Sprintf("app=%s", deployment.Name),
})
if err != nil {
return err
}
// Check if there are any Pods
if len(originPodList.Items) == 0 {
log.Printf(" No pod in %s\n", deployment.Name)
continue
}
// Skip Pods that have already been upgraded
updateSkip := false
for _, container := range pod.Spec.Containers {
if container.Name == "istio-proxy" && container.Image == "proxyv2:1.x.x" {
log.Printf(" Pod: %s Container: %s has already upgrade, skip\n", pod.Name, container.Name)
updateSkip = true
}
}
if updateSkip {
continue
}
// Scale the Deployment, create a new pod.
scale, err := clientSet.AppsV1().Deployments(ns).GetScale(ctx, deployment.Name, metav1.GetOptions{})
if err != nil {
return err
}
scale.Spec.Replicas = scale.Spec.Replicas + 1
_, err = clientSet.AppsV1().Deployments(ns).UpdateScale(ctx, deployment.Name, scale, metav1.UpdateOptions{})
if err != nil {
return err
}
// Wait for pods to be scaled
for {
podList, err := clientSet.CoreV1().Pods(ns).List(ctx, metav1.ListOptions{
LabelSelector: fmt.Sprintf("app=%s", deployment.Name),
})
if err != nil {
log.Fatal(err)
}
if len(podList.Items) != int(scale.Spec.Replicas) {
time.Sleep(time.Second * 10)
} else {
break
}
}
// Wait for pods to be running
for {
podList, err := clientSet.CoreV1().Pods(ns).List(ctx, metav1.ListOptions{
LabelSelector: fmt.Sprintf("app=%s", deployment.Name),
})
if err != nil {
log.Fatal(err)
}
isPending := false
for _, item := range podList.Items {
if item.Status.Phase != v1.PodRunning {
log.Printf("Deployment: %s Pod: %s Not Running Status: %s\n", deployment.Name, item.Name, item.Status.Phase)
isPending = true
}
}
if isPending == true {
time.Sleep(time.Second * 10)
} else {
break
}
}
// Remove origin pod
for _, pod := range originPodList.Items {
err = clientSet.CoreV1().Pods(ns).Delete(context.Background(), pod.Name, metav1.DeleteOptions{})
if err != nil {
return err
}
log.Printf(" Remove origin %s success.\n", pod.Name)
}
// Recover scale
newScale, err := clientSet.AppsV1().Deployments(ns).GetScale(ctx, deployment.Name, metav1.GetOptions{})
if err != nil {
return err
}
newScale.Spec.Replicas = newScale.Spec.Replicas - 1
newScale.ResourceVersion = ""
newScale.UID = ""
_, err = clientSet.AppsV1().Deployments(ns).UpdateScale(ctx, deployment.Name, newScale, metav1.UpdateOptions{})
if err != nil {
return err
}
log.Printf(" Depoloyment %s rebuild success.\n", deployment.Name)
log.Println()
}
return nil
}
看的出来代码是比较多的。
最终方案
有没有更简单的方法呢,当我把上述的方案和领导沟通后他人都傻了,这也太复杂了:kubectl 不是有一个直接滚动重启的命令吗。
❯ k rollout -h
Manage the rollout of one or many resources.
Available Commands:
history View rollout history
pause Mark the provided resource as paused
restart Restart a resource
resume Resume a paused resource
status Show the status of the rollout
undo Undo a previous rollout
kubectl rollout restart deployment/abc
使用这个命令可以将 abc 这个 deployment 进行滚动更新,这个更新操作发生在 kubernetes 的服务端,执行的步骤和方案二差不多,只是 kubernetes 实现的比我的更加严谨。
后来我在查看 Istio 的官方升级指南中也是提到了这个命令:

所以还是得好好看官方文档
整合 kubectl
既然有现成的了,那就将这个命令整合到我的脚本里即可,再遍历 namespace 下的 deployment 的时候循环调用就可以了。
但这个 rollout 命令在 kubernetes 的 client-go 的 SDK 中是没有这个 API 的。
所以我只有参考 kubectl 的源码,将这部分功能复制过来;不过好在可以直接依赖 kubect 到我的项目里。
require (
k8s.io/api v0.28.2
k8s.io/apimachinery v0.28.2
k8s.io/cli-runtime v0.28.2
k8s.io/client-go v0.28.2
k8s.io/klog/v2 v2.100.1
k8s.io/kubectl v0.28.2
)
源码里使用到的 RestartOptions 结构体是公共访问的,所以我就参考它源码魔改了一下:
func TestRollOutRestart(t *testing.T) {
kubeConfigFlags := defaultConfigFlags()
streams, _, _, _ := genericiooptions.NewTestIOStreams()
ns := "dev"
kubeConfigFlags.Namespace = &ns
matchVersionKubeConfigFlags := cmdutil.NewMatchVersionFlags(kubeConfigFlags)
f := cmdutil.NewFactory(matchVersionKubeConfigFlags)
deploymentName := "deployment/abc"
r := &rollout.RestartOptions{
PrintFlags: genericclioptions.NewPrintFlags("restarted").WithTypeSetter(scheme.Scheme),
Resources: []string{deploymentName},
IOStreams: streams,
}
err := r.Complete(f, nil, []string{deploymentName})
if err != nil {
log.Fatal(err)
}
err = r.RunRestart()
if err != nil {
log.Fatal(err)
}
}
最终在几次 debug 后终于可以运行了,只需要将这部分逻辑移动到循环里,加上 sleep 便可以有规律的重启 Pod 了。
参考链接:
- https://istio.io/latest/docs/setup/upgrade/canary/#data-plane
- https://github.com/kubernetes/kubectl/blob/master/pkg/cmd/rollout/rollout_restart.go
如何优雅重启 kubernetes 的 Pod的更多相关文章
- kubernetes之pod中断
系列目录 目标读者: 想要构建高可用应用的应用所有者,因此需要知道pod会发生哪些类型的中断 想要执行自动化(比如升级和自动扩容)的集群管理员. 自愿和非自愿的中断 pod不会自动消息,除非有人(可能 ...
- Kubernetes之Pod使用
一.什么是Podkubernetes中的一切都可以理解为是一种资源对象,pod,rc,service,都可以理解是 一种资源对象.pod的组成示意图如下,由一个叫”pause“的根容器,加上一个或多个 ...
- Kubernetes探索学习004--深入Kubernetes的Pod
深入研究学习Pod 首先需要认识到Pod才是Kubernetes项目中最小的编排单位原子单位,凡是涉及到调度,网络,存储层面的,基本上都是Pod级别的!官方是用这样的语言来描述的: A Pod is ...
- kubernetes之pod健康检查
目录 kubernetes之pod健康检查 1.概述和分类 2.LivenessProbe探针(存活性探测) 3.ReadinessProbe探针(就绪型探测) 4.探针的实现方式 4.1.ExecA ...
- Kubernetes基石-pod容器
引用三个问题来叙述Kubernetes的pod容器 1.为什么不直接在一个Docker容器中运行所有的应用进程. 2.为什么pod这种容器中要同时运行多个Docker容器(可以只有一个) 3.为什么k ...
- kubernetes concepts -- Pod Overview
This page provides an overview of Pod, the smallest deployable object in the Kubernetes object model ...
- Kubernetes服务pod的健康检测liveness和readiness详解
Kubernetes服务pod的健康检测liveness和readiness详解 接下来给大家讲解下在K8S上,我们如果对我们的业务服务进行健康检测. Health Check.restartPoli ...
- pod(五):pod hook(pod钩子)和优雅的关闭nginx pod
目录 一.系统环境 二.前言 三.pod hook(pod钩子) 四.如何优雅的关闭nginx pod 一.系统环境 服务器版本 docker软件版本 Kubernetes(k8s)集群版本 CPU架 ...
- Kubernetes核心技术Pod
Kubernetes核心技术Pod Pod概述 Pod是K8S系统中可以创建和管理的最小单元,是资源对象模型中由用户创建或部署的最小资源对象模型,也是在K8S上运行容器化应用的资源对象,其它的资源对象 ...
- Apache 优雅重启 Xampp开机自启 - 【环境变量】用DOS命令在任意目录下启动服务
D:\xampp\apache\bin\httpd.exe" -k runservice Apache 优雅重启 :httpd -k graceful Xampp开机自启动 参考文献:ht ...
随机推荐
- Windows/DOS与Unix文件格式之间的相互转换(/r/n问题)
PS:今天遇到一个文件转换问题,现在将网上搜索到资料贴出来.. 第一个资料 Windows/DOS与Unix文件格式是不同的,问题一般就是出在/r/n问题上. 回车(CR)和换行(LF)符都是用来表示 ...
- 一次oracle行级锁导致的问题
分析问题:我在plsql/developer是用的system用户连接的数据库,而在crt用 sqlplus / as sysdba 连接数据库,是sys用户.现在在plsql/developer ...
- ZEGO全新语音聊天解决方案,4步搭建爆火的语音聊天室
最近,国外一款语音聊天软件成功火出圈. 与此同时,该类产品也引发了国内互联网的关注,除了争相下载试用之外,不少社交.泛娱乐行业从业者也表示要跟进对应玩法. 据了解,不少泛娱乐玩家已经在加班加点抢占先机 ...
- 在windows平台使用Visual Studio 2017编译动态库并使用
使用VS stdio制作顺序表的库文件 .lib与.dll 区别 lib是编译时需要的 dll是运行时需要的 1.新建头文件和源文件 SeqList.h // SeqList.h #ifndef SE ...
- Node: Module not found: Can't resolve 'xlsx'
报错信息 解决方案 npm install xlsx --save 参考链接 https://github.com/securedeveloper/react-data-export/issues/8 ...
- PowerShell:因为在此系统上禁止运行脚本,解决方法
解决方案 get-executionpolicy set-executionpolicy remotesigned 输入Y 至此问题解决
- [k8s]使用nfs挂载pod的应用日志文件
前言 某些特殊场景下应用日志无法通过elk.grafana等工具直接查看,需要将日志文件挂载出来再处理.本文以nfs作为远程存储,统一存放pod日志. 系统版本:CentOS 7 x86-64 宿主机 ...
- 二代水务系统架构设计分享——DDD+个性化
系统要求 C/S架构的单体桌面应用,可以满足客户个性化需求,易于升级和维护.相比于一代Winform,界面要求美观,控件丰富可定制. 解决方案 依托.Net6开发平台,采用模块化思想设计(即分而治之的 ...
- 自治系统/自治域和自治系统编号(ASN)
定义: 自治系统或自治域(英文:Autonomous system, AS)是指在互联网中,一个或多个实体管辖下的所有IP网络和路由器的组合,它们对互联网执行共同的路由策略.参看RFC 1930中更新 ...
- .NET Core多线程 (2) 异步 - 上
去年换工作时系统复习了一下.NET Core多线程相关专题,学习了一线码农老哥的<.NET 5多线程编程实战>课程,我将复习的知识进行了总结形成本专题. 本篇,我们来复习一下异步的相关知识 ...