Python 康德乐大药房网站爬虫,使用bs4获取json,导入mysql
故事开端
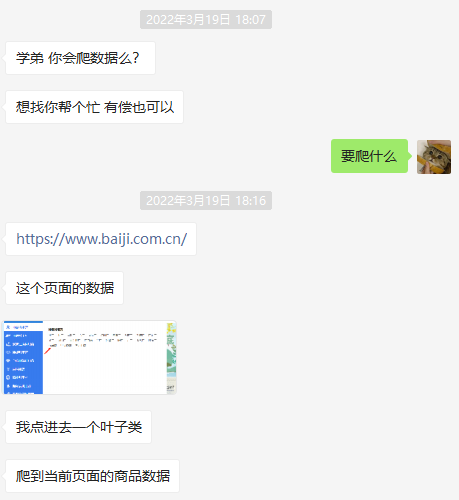
目标地址
https://www.baiji.com.cn 康德乐大药房
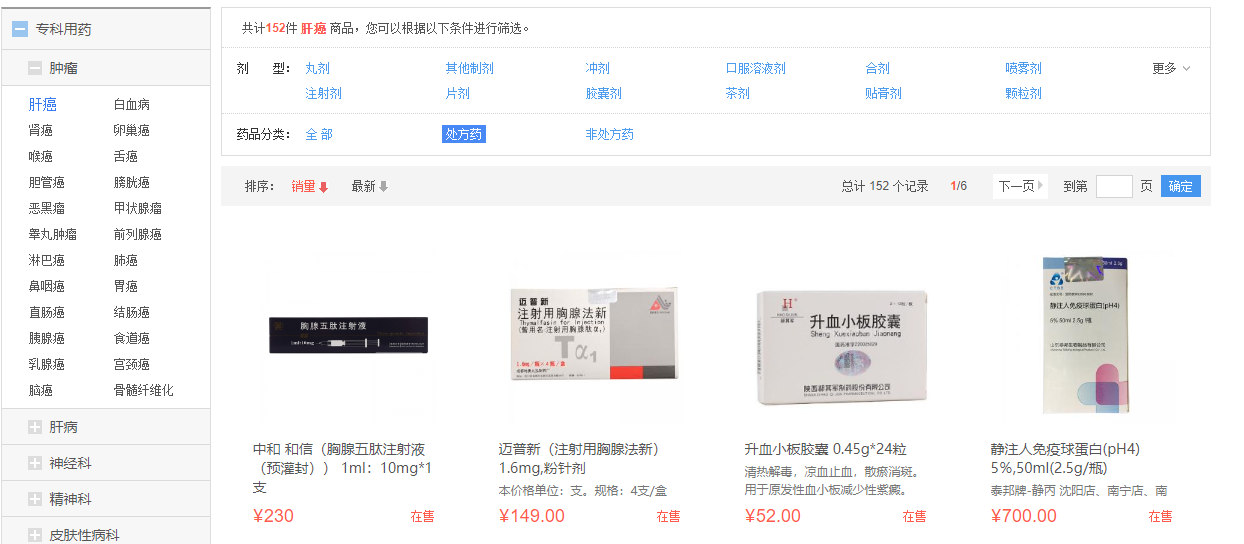
程序流程
"爬取数量是否达标"这块没有写代码,因为我发现单页数量够多了,每页爬一半数据大概有8000条
获取商品价格接口
我发现商品价格在soup结构里面没有生成,是空值,应该是动态请求加载的。
就讲一下这部分接口我是怎么获取的吧,使用软件 Fiddler 进行抓包,如果你不知道这是什么 Fiddler使用方式
随便打开一个网站
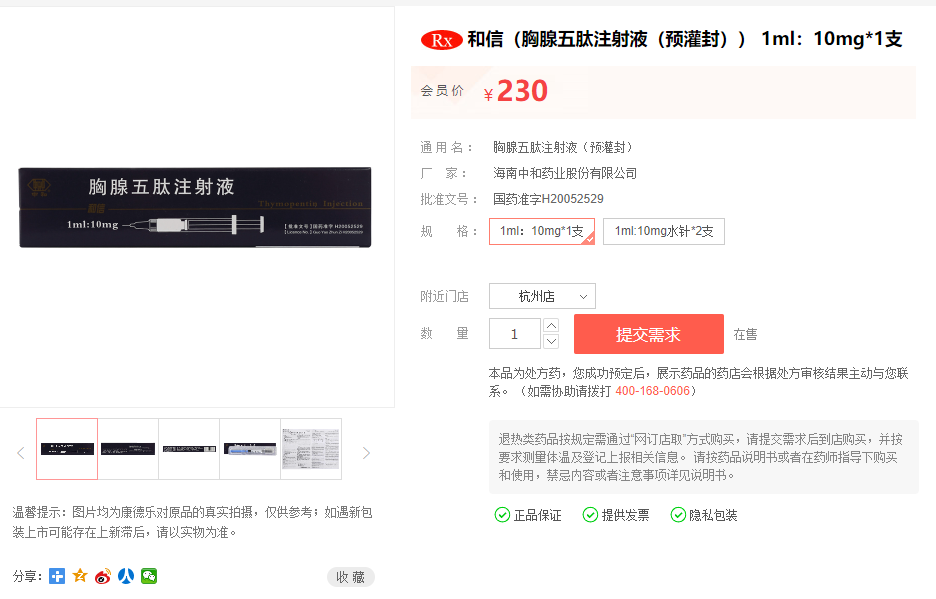

可以看到请求的地址,这是一个 get 请求,包含了三个参数分别是 jsonp+时间戳、act 方法、goods_id 商品id,返回体是一个json,显示商品价格(注意!商品可能缺货会返回 {"price":"特价中"},所以要做判断处理,可以看 spider.py 里的 product() 函数)
# ^ 获取价格
goods_id = re.search(r'\d+', href).group(0)
url = "https://www.baiji.com.cn/domain/goods_info.php?fn=jsonp{}&act=goods_info&goods_id={}".format(int(time.time()), goods_id)
headers_2 = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.39',
'Referer': "https://www.baiji.com.cn/goods-{}.html".format(goods_id)
}
cookie = {
'Cookie': 'NTKF_T2D_CLIENTID=guest59D35491-8F98-DD91-B9BE-A1ADEB5C6CBF; real_ipd=112.10.183.174; UserId=0; kdlusername=0; kdl_username=0; ECS_ID=887e4472a5a3613c59df1c0e60cc2a93a40d401e; nTalk_CACHE_DATA={uid:kf_9261_ISME9754_guest59D35491-8F98-DD,tid:1647709025522701}; ECS[history]=7526%2C7522%2C14684%2C15717%2C11560; arp_scroll_position=300'
}
res = requests.get(url, headers=headers_2, cookies=cookie, timeout=None)
res.encoding = "utf-8"
MyJson = loads_jsonp(res.text)
try:
price = float(MyJson['price'])
except:
price = 0
isStockOut = True可以看到我们先处理了 jsonp 转化为 json 对象,对取得的 json 的 price 键对应值进行 float 类型转换,如果转换失败会抛出异常,我们使用 try: ? expect: ? 的方式进行判断
代码
代码写的很难看,但是能用,Wow!It just works!
work.py
import os
import json
import threading
import requests
import re
import time
from spider import Spider
from bs4 import BeautifulSoup
class MyThread(threading.Thread):
"""重写多线程,使其能够返回值"""
def __init__(self, target=None, args=()):
super(MyThread, self).__init__()
self.func = target
self.args = args
def run(self):
self.result = self.func(*self.args)
def get_result(self):
try:
return self.result # 如果子线程不使用join方法,此处可能会报没有self.result的错误
except Exception:
return None
host = "https://www.baiji.com.cn"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.39'
}
res = requests.get(host, headers=headers)
res.encoding = "utf-8"
soup = BeautifulSoup(res.text, "html.parser")
item_list = soup.find_all(class_='tcon')
items = []
for item in item_list:
a = item.find_all('a')
for i in a:
href = i['href'].strip('// http:')
title = i['title']
if re.search('category', href) != None:
items.append((href, title))
# ^ only for test 暴力开启多线程
infos = []
threads = []
start = time.perf_counter()
for item in items:
t = MyThread(target=Spider, args=(item,))
threads.append(t)
t.start()
print('启动!')
# ^ 等待所有子线程结束,主线程再运行
for t in threads:
t.join()
result = t.get_result()
infos.extend(result)
with open('data.json', 'w', encoding='utf-8') as f:
f.write(json.dumps(infos, indent=4, ensure_ascii=False))
exit()spider.py
import time
import os
import json
import requests
import re
from bs4 import BeautifulSoup
COUNT = 0
host = "https://"
host_ = "https://www.baiji.com.cn/"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.39'
}
path = os.path.dirname(__file__)
# ^ 主入口
def Spider(item):
# temp = []
# isPrescription = False
category = item[1]
classes = CatchClasses(item[0])
infos = GoPage(classes, category)
return infos
# ^ 获取所有剂型
def CatchClasses(url):
res = requests.get(host+url, headers=headers)
res.encoding = "utf-8"
soup = BeautifulSoup(res.text, "html.parser")
temp = soup.find(class_="det").find_all('a')
classes = [a['href'] for a in temp]
titles = [a['title'] for a in temp]
return [classes, titles]
# ^ 进行爬虫
def GoPage(classes, category):
isPrescribed = True
length = len(classes[0])
href = classes[0]
titles = classes[1]
infos = []
for index, h_ in enumerate(href):
Collect(h_, '-0.html', titles, index, category, infos)
# ---------------------------------------------------------------------------- #
Collect(h_, '-1.html', titles, index, category, infos)
print('已处理', COUNT, '个商品')
return infos
def Collect(h_, add, titles, index, category, infos):
h = h_.replace('.html', add)
url = host_ + h
res = requests.get(url, headers=headers)
res.encoding = "utf-8"
# ^ 获取该类别共几条商品记录
target = re.findall(r'共计<strong class="red">\d+</strong>', res.text)
target = re.search(r'\d+', target[0]).group(0)
target = int(target)
# ^ 如果商品记录为 0 直接跳过
if target != 0:
# ^ 减少爬的数据量
target = int(target/2+1)
print(titles[index], "需要获取的数据条目", target)
isPrescribed = False
products = GetProducts(h)
print("非处方页面共有", len(products), "个商品", time.ctime())
for product in products:
info = Product(product, index)
info['category'] = category
info['isPrescribed'] = isPrescribed
info['class'] = titles[index]
infos.append(info)
# ^ 获取当前页面所有产品
def GetProducts(url):
res = requests.get(host_+url, headers=headers)
res.encoding = "utf-8"
soup = BeautifulSoup(res.text, "html.parser")
products = soup.find_all(class_='pro_boxin')
return products
# ^ 解析jsonp对象
def loads_jsonp(_jsonp):
try:
return json.loads(re.match(".*?({.*}).*", _jsonp, re.S).group(1))
except:
raise ValueError('Invalid Input')
# ^ 获取指定商品信息
# @ info 传入一个 class = pro_boxin 的soup对象
def Product(p, category):
global COUNT
COUNT += 1
a = p.find(class_="name").a
isStockOut = False # IMPORTANT
productname = a['title'] # IMPORTANT
QuantityPerunit = a.contents[0].strip().split(' ')[1] # IMPORTANT
describe = a.span.string # IMPORTANT
img = p.find('img')
try:
imageSrc = img['data-original'].strip('//') # IMPORTANT
# ^ 下载图片到本地
imageSrc = DownloadPic(imageSrc, category)
except:
imageSrc = None
# ^ 准备获取商品页面
href = a['href'] # IMPORTANT
# print(productname, unit, href)
# ^ 获取价格
goods_id = re.search(r'\d+', href).group(0)
url = "https://www.baiji.com.cn/domain/goods_info.php?fn=jsonp{}&act=goods_info&goods_id={}".format(int(time.time()), goods_id)
headers_2 = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.39',
'Referer': "https://www.baiji.com.cn/goods-{}.html".format(goods_id)
}
cookie = {
'Cookie': 'NTKF_T2D_CLIENTID=guest59D35491-8F98-DD91-B9BE-A1ADEB5C6CBF; real_ipd=112.10.183.174; UserId=0; kdlusername=0; kdl_username=0; ECS_ID=887e4472a5a3613c59df1c0e60cc2a93a40d401e; nTalk_CACHE_DATA={uid:kf_9261_ISME9754_guest59D35491-8F98-DD,tid:1647709025522701}; ECS[history]=7526%2C7522%2C14684%2C15717%2C11560; arp_scroll_position=300'
}
res = requests.get(url, headers=headers_2, cookies=cookie, timeout=None)
res.encoding = "utf-8"
MyJson = loads_jsonp(res.text)
try:
price = float(MyJson['price'])
except:
price = 0
isStockOut = True
# print(price)
return dict(
productname=productname,
QuantityPerunit=QuantityPerunit,
unitprice=price,
isStockOut=isStockOut,
notes=describe,
imageSrc=imageSrc
)
def DownloadPic(src, category):
category = str(category+1)
# print(src)
fileName = src.split('/')
fileName.reverse()
fileName = fileName[0].strip('/')
# print(fileName)
pic = requests.get(host+src)
savePath = path+'/goods_img/'+category+'/'
isExists = os.path.exists(savePath)
if not isExists:
# 如果不存在则创建目录
# 创建目录操作函数
os.makedirs(savePath)
with open(savePath+fileName, 'wb') as b:
b.write(pic.content)
return '/goods_img/'+category+'/'+fileName
json_to_mysql.py
import os
import json
import random
import mysql.connector
path = os.path.dirname(__file__)
db = mysql.connector.connect(
host="localhost",
user="root",
passwd="sql2008",
database="test",
auth_plugin='mysql_native_password'
)
cursor = db.cursor()
with open(path+'/data.json', 'r', encoding='utf-8') as f:
data = json.load(f)
print(data[0], len(data))
cursor.execute("SELECT categoryid, categoryname FROM t_categorytreeb")
res = cursor.fetchall()
categoryid = [i[0] for i in res]
categoryname = [i[1] for i in res]
print(categoryname.index('丙肝'))
cursor.execute("SELECT supplierid FROM t_suppliers")
res = cursor.fetchall()
suppliers = [i[0] for i in res]
print(suppliers)
# ^ 插入数据
sql = "INSERT INTO t_medicines(ProductName,QuantityPerunit,Unitprice,SupplierID,SubcategoryID,Photopath,notes,ytype,isPrescribed,isStockOut) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
val = [
]
print()
for item in data:
try:
# print(item['category'], categoryname.index(item['category']))
index = categoryname.index(item['category'].strip())
cid = categoryid[index]
except:
cid = None
val.append((
item["productname"],
item["QuantityPerunit"],
item["unitprice"],
random.choice(suppliers),
cid,
item["imageSrc"],
item["notes"],
item["class"],
item["isPrescribed"],
item["isStockOut"]
))
cursor.executemany(sql, val)
db.commit()
print(cursor.rowcount, "was inserted.")数据集
2020_3/data.zip (80MB)包括图片
故事结尾
Python 康德乐大药房网站爬虫,使用bs4获取json,导入mysql的更多相关文章
- (转)Python新手写出漂亮的爬虫代码2——从json获取信息
https://blog.csdn.net/weixin_36604953/article/details/78592943 Python新手写出漂亮的爬虫代码2——从json获取信息好久没有写关于爬 ...
- python下载各大主流视频网站电影
You-Get 是一个命令行工具, 用来下载各大视频网站的视频, 是我目前知道的命令行下载工具中最好的一个, 之前使用过 youtube-dl, 但是 youtube-dl 吧, 下载好的视频是分段的 ...
- python 全栈开发,Day134(爬虫系列之第1章-requests模块)
一.爬虫系列之第1章-requests模块 爬虫简介 概述 近年来,随着网络应用的逐渐扩展和深入,如何高效的获取网上数据成为了无数公司和个人的追求,在大数据时代,谁掌握了更多的数据,谁就可以获得更高的 ...
- (转)Python新手写出漂亮的爬虫代码1——从html获取信息
https://blog.csdn.net/weixin_36604953/article/details/78156605 Python新手写出漂亮的爬虫代码1初到大数据学习圈子的同学可能对爬虫都有 ...
- Python 利用 BeautifulSoup 爬取网站获取新闻流
0. 引言 介绍下 Python 用 Beautiful Soup 周期性爬取 xxx 网站获取新闻流: 图 1 项目介绍 1. 开发环境 Python: 3.6.3 BeautifulSoup: ...
- 零基础学完Python的7大就业方向,哪个赚钱多?
“ 我想学 Python,但是学完 Python 后都能干啥 ?” “ 现在学 Python,哪个方向最简单?哪个方向最吃香 ?” “ …… ” 相信不少 Python 的初学者,都会遇到上面的这些问 ...
- python学习笔记(11)--爬虫下载漫画图片
说明: 1. 某本子网站爬虫,现在只实现了扒取一页,已经凌晨两点了,又饿又困,先睡觉,明天再写总结吧! 2. 我是明天,我来写总结了! 3. 这个网站的结构是这样的: 主页: 主页-第1页-漫画1封面 ...
- Python爬取mc皮肤【爬虫项目】
首先,找到一个皮肤网站,其中一个著名的皮肤网站就是 https://littleskin.cn .进入网站,我们就会见到一堆皮肤,这就是今天我们要爬的皮肤.给各位分享一下代码. PS:另外很多人在学习 ...
- python基础--14大内置模块(下)
(9)正则表达式和re模块(重点模块) 在我们学习这个模块之前,我们先明确一个关系.模块和实际工作的关系. 1)模块和实际工作时间的关系 1.time模块和时间是什么关系?time模块和时间本身是没有 ...
随机推荐
- python基础之序列类型的方法——字符串方法
python基础之序列类型的方法--字符串方法 Hello大家好,我是python学习者小杨同学,经过一段时间的沉淀(其实是偷懒不想更新),我终于想起了自己的博客账号,所以这次带来的是序列方法的后半部 ...
- jdbc.properties/(驱动、URL、用户名、密码)跟换数据库时改该配置文件/Untitled Text File格式
背景:这几天从阿里云上面购买了云服务器,最垃圾的那种,还送oss和EDS数据库服务器,只不过EDS数据库服务器只有一个月的,就主动升级为一年的,49还是59忘了.对于配置这种EDS过程中,产生的一个念 ...
- Apple macOS Mojave Intel Graphics Driver组件任意代码执行漏洞
受影响系统:Apple macOS Mojave 10.14.5描述:CVE(CAN) ID: CVE-2019-8629 Apple macOS Mojave是苹果公司Mac电脑系列产品的操作系统. ...
- 浅谈systemd原理和应用
多不说,直接上代码(可谓配置): [Unit] Description=demo app After=network-is-online.target [Service] Type=Simple Ex ...
- leetcode210.拓扑排序
拓扑排序能否成功,其实就是看有没有环 有环:说明环内结点互为前置,永远也不可能完成 无环:是线性的,可以完成 DFS方法 思路: 逆向思维,遍历到边界点(无邻接点相当于叶子),再不断回溯将结点加入到结 ...
- SpringBoot中的日志使用:
SpringBoot中的日志使用(一) 一:日志简介: 常用的日志接口 commons-logging/slf4j 日志框架:log4j/logback/log4j2 日志接口屏蔽了日志框架的底层实现 ...
- ThreadPoolTaskExecutor原理、详解及案例
为什么要用线程池? 服务器应用程序中经常出现的情况是:单个任务处理的时间很短而请求的数目却是巨大的. 构建服务器应用程序的一个过于简单的模型应该是:每当一个请求到达就创建一个新线程,然后在新线程中为请 ...
- 解释一下Spring AOP里面的几个名词?
(1)切面(Aspect):被抽取的公共模块,可能会横切多个对象.在Spring AOP中,切面可以使用通用类(基于模式的风格)或者在普通类中以@AspectJ注解来实现. (2)连接点(Join p ...
- 有哪些不同类型的IOC(依赖注入)方式?
构造器依赖注入:构造器依赖注入通过容器触发一个类的构造器来实现的,该类有一系列参数,每个参数代表一个对其他类的依赖. Setter方法注入:Setter方法注入是容器通过调用无参构造器或无参stati ...
- MySQL安装速成指南(ZIP)
MySQL初始化数据库 第一步:将MySQL ZIP压缩包进行解压 第二部:在MySQL主目录创建my.ini文件,并添加以下内容 [client] port=3306 socket=/tmp/mys ...