Kubernetes 调度 - 污点和容忍度详解
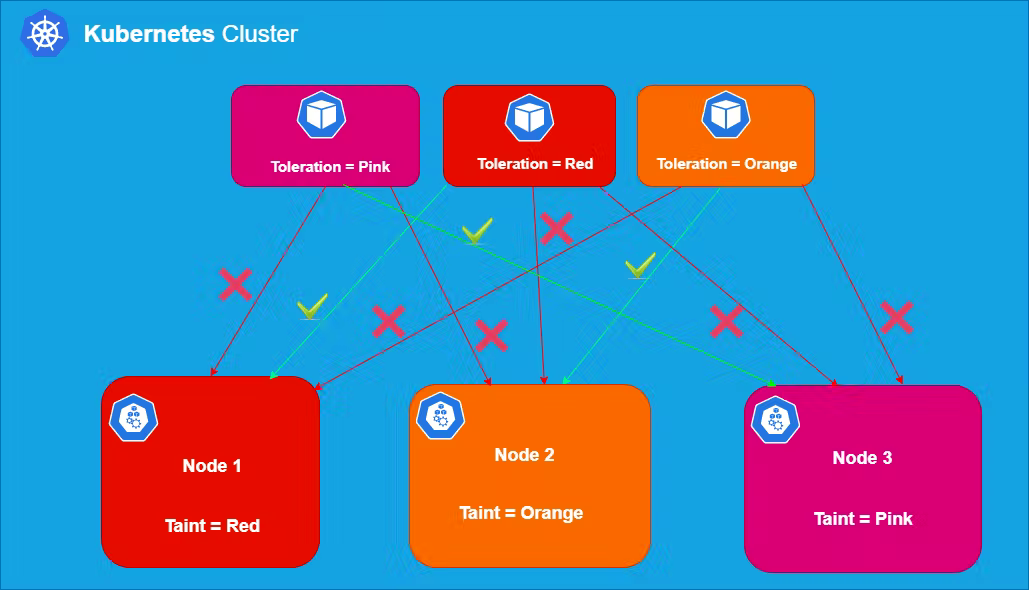
当我们使用节点亲和力(Pod 的一个属性)时,它会将Pod吸引到一组节点(作为偏好或硬性要求)。污点的行为完全相反,它们允许一个节点排斥一组 Pod。
在 Kubernetes 中,您可以标记(污染)一个节点,以便在该节点上不能调度任何 Pod,除非它们应用了明确的容忍度。Tolerations 应用于 Pod,并允许(但不要求)Pod 调度到具有匹配污点的节点上。
污点和容忍度协同工作可确保 Pod 不会被调度到不合适的节点上。
污点语法
常见的污点语法是:
key=value:Effect
可以分配三个不同的值effect:
- NoSchedule:如果至少有一个未被忽略的污点NoSchedule生效,那么 Kubernetes 不会将 pod 调度到该节点上。已经存在的不容忍这种污点的 Pod 不会被从该节点驱逐或删除。但是除非有匹配的容忍度,否则不会在这个节点上安排更多的 Pod。这是一个硬约束。
- PreferNoSchedule:如果至少有一个不可容忍的污点有影响,Kubernetes 将尝试不在节点上调度 Pod 。但是如果有一个 pod 可以容忍一个 taint,它可以被调度。这是一个软约束。
- NoExecute:如果至少有一个未被忽略的NoExecute taint 生效,那么 Pod 将从节点中被逐出(如果它已经在节点上运行),并且不会被调度到节点上(如果它还没有在节点上运行)节点)。这是一个强约束。
可以对单个节点应用多个污点,对单个 Pod 应用多个容忍度。
向节点添加污点
语法:
kubectl taint nodes <node_name> key=value:effect
看看不同节点上已经运行的 pod
root@kube-master:~# kubectl get pods -o wide

在节点上kube-worker2应用污点
root@kube-master:~# kubectl describe nodes kube-worker2 | grep -i taint
Taints: <none>
root@kube-master:~# kubectl taint nodes kube-worker2 new-taint=taint_demo:NoSchedule
node/kube-worker2 tainted
root@kube-master:~# kubectl describe nodes kube-worker2 | grep -i taint
Taints: new-taint=taint_demo:NoSchedule
在上面的示例中,在 kube-worker2 node 上应用了一个 taint new-taint=taint_demo:NoSchedule
现在让我们看看正在运行的 pod:
root@kube-master:~# kubectl get pods -o wide

根据NoSchedule约定,已经运行的 pod 不受影响。
现在让我们用同一个节点添加 NoExecute 污点。
root@kube-master:~# kubectl taint nodes kube-worker2 new-taint=taint_demo:NoExecute
node/kube-worker2 tainted
root@kube-master:~# kubectl describe nodes kube-worker2 | grep -i taint
Taints: new-taint=taint_demo:NoExecute
new-taint=taint_demo:NoSchedule
现在让我们看看正在运行的 pod:
root@kube-master:~# kubectl get pods -o wide
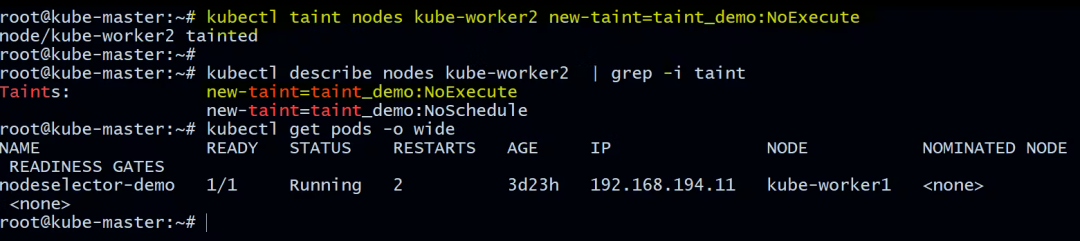
所有不能容忍污点的Pod都被驱逐了。
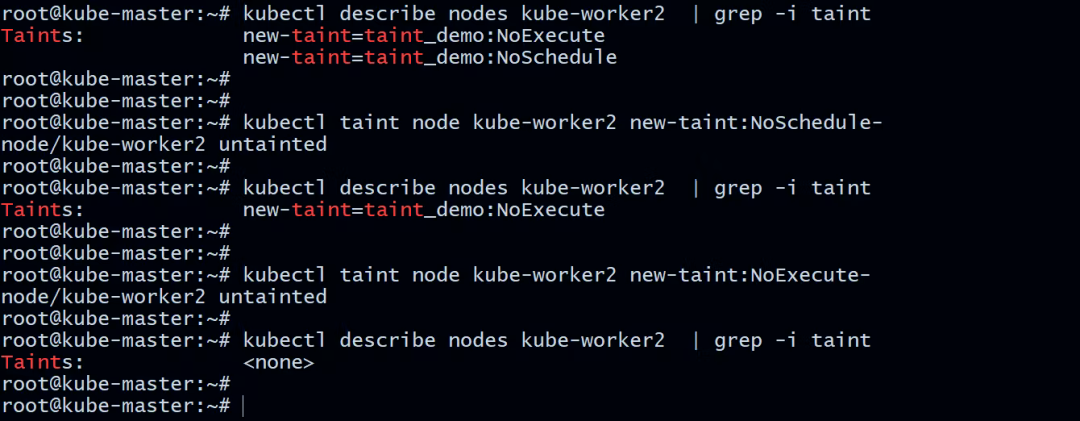
从节点中移除污点
如果您不再需要污点,请运行以下命令将其删除:
root@kube-master:~# kubectl taint node kube-worker2 new-taint:NoSchedule-
node/kube-worker2 untainted
root@kube-master:~# kubectl taint node kube-worker2 new-taint:NoExecute-
node/kube-worker2 untainted
为 Pod 添加容忍度
您可以在PodSpec添加容忍度. 让我们再查看添加NoSchedule污点的节点。
root@kube-master:~# kubectl taint nodes kube-worker2 new-taint=taint_demo:NoSchedule
node/kube-worker2 tainted
部署一个具有污点容忍度的 pod ,这是我们的清单文件:
root@kube-master:~/taint_tolerations# cat toleration.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-toleration-demo
labels:
env: staging
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
tolerations:
- key: "new-taint"
operator: "Equal"
value: "taint_demo"
effect: "NoSchedule"
Pod 的 toleration 具有 key new-taint、 value true和 effect NoSchedule,这与我们之前在 node 上应用节点kube-worker2上的 taint 相匹配。这意味着这个 pod 现在有资格被调度到节点kube-worker2。但是,这并不能保证这个 Pod 一定被调度,因为我们没有指定任何node affinity或者nodeSelector。
operator的默认值为Equal。(如果键相同且值相同,则容忍匹配污点)
运算符是Exists(这种情况下不应指定任何值)
应用 Pod 清单文件
root@kube-master:~/taint_tolerations# kubectl apply -f toleration.yaml
pod/nginx-toleration-demo created
验证 Pod 在哪个节点上运行
root@kube-master:~/taint_tolerations# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-toleration-demo 1/1 Running 0 7s 192.168.161.196 kube-worker2 <none> <none>
nodeselector-demo 1/1 Running 2 3d23h 192.168.194.11 kube-worker1 <none> <none>
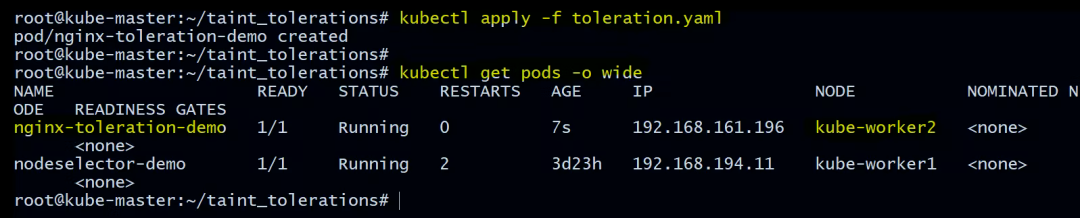
您可以在上面看到nginx-toleration-demo 被调度到 kube-worker2。
一个节点可以有多个污点,而 pod 可以有多个容忍度。Kubernetes 处理多个 taints 和 toleration 的方式就像一个过滤器:从节点的所有 taint 开始,然后忽略 pod 具有匹配 toleration 的那些;剩余的未被忽略的污点对 pod 有特定的影响。
关于容忍度的重要说明
- 如果至少有一个未被忽略的NoSchedule taint 生效,那么 Kubernetes 将不会把 pod 调度到该节点上。
- 如果没有未忽略的 NoSchedule taint 生效,但至少有一个未忽略的PreferNoSchedule taint 生效,则 Kubernetes 将尝试不把 pod 调度到节点上。
- 如果至少有一个未被忽略的NoExecute taint 生效,那么 pod 将从节点中被逐出(如果它已经在节点上运行),并且不会被调度到节点上(如果它还没有在节点上运行) )。
让我们举个例子:
我已经污染了的节点
root@kube-master:~# kubectl taint nodes kube-worker2 new-taint=taint_demo:NoExecute
root@kube-master:~# kubectl taint nodes kube-worker2 new-taint=taint_demo:NoSchedule
root@kube-master:~# kubectl taint nodes kube-worker2 new-taint2=taint_demo2:NoSchedule
验证应用的污点
root@kube-master:~# kubectl describe nodes kube-worker2 | grep -i taint
Taints: new-taint=taint_demo:NoExecute
new-taint=taint_demo:NoSchedule
new-taint2=taint_demo2:NoSchedule
Pod 清单文件
root@kube-master:~/taint_tolerations# cat toleration-2.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-toleration-demo
labels:
env: staging
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
tolerations:
- key: "new-taint"
operator: "Equal"
value: "taint_demo"
effect: "NoSchedule"
- key: "new-taint"
operator: "Equal"
value: "taint_demo"
effect: "NoExecute"
在这种情况下,pod 将无法调度到节点上,因为没有与第三个 taint 匹配的容忍度。但是如果在添加 taint 的时候已经在 node 上运行,它就可以继续运行,因为第三个 taint 是 Pod 不能容忍的三个 taint 中唯一的一个。
实际上任何不容忍NoExecute taint 的 pod 都将被立即驱逐,而能够容忍 taint 的 pod 将永远不会被驱逐。但是可以指定一个可选tolerationSeconds字段,该字段指示在添加污点后 pod 将保持绑定到节点的时间。例如:
tolerations:
- key: "new-taint"
operator: "Equal"
value: "taint_demo"
effect: "NoExecute"
tolerationSeconds: 3600
这意味着如果这个 pod 正在运行并且又一个匹配的 taint 被添加到该节点,那么该 pod 将保持绑定到该节点 3600 秒,然后被驱逐。如果在该时间之前移除了 taint,则 pod 不会被驱逐。
污点和容忍应用场景总结
- 专用节点:当您想将一组节点专用于专有工作负载或特定用户时,您可以向这些节点添加一个污点(例如kubectl taint nodes nodename dedicated=groupName:NoSchedule),然后向它们的 pod 添加相应的容忍度。
- 具有特殊硬件的节点:对于具有专用硬件(例如 GPU)的节点,我们只希望具有这些要求的 pod 在这些节点上运行。污染将帮助我们(例如kubectl taint nodes nodename special=true:NoScheduleor kubectl taint nodes nodename special=true:PreferNoSchedule)并为使用特殊硬件的 pod 添加相应的容忍度。
- 基于污点的驱逐:当节点存在问题时,每个 pod 可配置的驱逐行为。当某些条件为真时,节点控制器会自动污染节点。
如下是k8s给出内置污点:
- node.kubernetes.io/not-ready:节点没有准备好。
- node.kubernetes.io/unreachable:无法从节点控制器访问节点。准备就绪时NodeCondition为“未知”。
- node.kubernetes.io/memory-pressure:节点有内存压力。
- node.kubernetes.io/disk-pressure:节点有磁盘压力。
- node.kubernetes.io/pid-pressure:节点有 PID 压力。
- node.kubernetes.io/network-unavailable:节点的网络不可用。
- node.kubernetes.io/unschedulable:节点不可调度。
Kubernetes 调度 - 污点和容忍度详解的更多相关文章
- Kubernetes的污点和容忍(下篇)
背景 继上一篇<Kubernetes的污点和容忍(上篇)>,这是https://kubernetes.io/docs/concepts/configuration/taint-and-to ...
- Kubernetes的污点和容忍(上篇)
背景 搭建了一个k8s(Kubernetes)的事件监听服务,监听事件之后对数据做处理.有天报了一个问题经调查是新版本的k8s集群添加会把unschedule等信息通过污点的方式反映.而这些污点是只有 ...
- Kubernetes K8S之资源控制器Daemonset详解
Kubernetes的资源控制器Daemonset详解与示例 主机配置规划 服务器名称(hostname) 系统版本 配置 内网IP 外网IP(模拟) k8s-master CentOS7.7 2C/ ...
- storm源码之理解Storm中Worker、Executor、Task关系 + 并发度详解
本文导读: 1 Worker.Executor.task详解 2 配置拓扑的并发度 3 拓扑示例 4 动态配置拓扑并发度 Worker.Executor.Task详解: Storm在集群上运行一个To ...
- Docker Kubernetes Service 网络服务代理模式详解
Docker Kubernetes Service 网络服务代理模式详解 Service service是实现kubernetes网络通信的一个服务 主要功能:负载均衡.网络规则分布到具体pod 注 ...
- kubernetes运行应用2之DaemonSet详解
kubernetes运行应用1之Deployment详解 查看daemonset 如下,k8s自身的 DaemonSet kube-flannel-ds和kube-proxy分别负责在每个结点上运 ...
- Kubernetes K8S之资源控制器StatefulSets详解
Kubernetes的资源控制器StatefulSet详解与示例 主机配置规划 服务器名称(hostname) 系统版本 配置 内网IP 外网IP(模拟) k8s-master CentOS7.7 2 ...
- Kubernetes K8S之鉴权RBAC详解
Kubernetes K8S之鉴权概述与RBAC详解 K8S认证与授权 认证「Authentication」 认证有如下几种方式: 1.HTTP Token认证:通过一个Token来识别合法用户. H ...
- 基于kubernetes构建Docker集群管理详解-转
http://blog.liuts.com/post/247/ 一.前言 Kubernetes 是Google开源的容器集群管理系统,基于Docker构建一个容器的调度服务,提供资源调度 ...
随机推荐
- 问题:CondaHTTPError: HTTP 000 CONNECTION FAILED for url <https://mirrors.tuna.tsinghua.edu.cn/anaconda/pk
使用anaconda安装tensorflow (windows10环境) 遇到的问题:CondaHTTPError: HTTP 000 CONNECTION FAILED for url <ht ...
- Servlet-2获取请求,响应结果
获取请求参数值1)HttpServletRequest ① 该接口是ServletRequest接口的子接口,封装了HTTP请求的相关信息,由Servlet容器创建其实现类对象并传入serv ...
- labview从入门到出家6(进阶篇)--移位寄存器的使用
前面介绍了如何熟悉和使用Labview自带的库函数以及调试方式,大家后期基本可以凭借这两个方式从入门到出家了,哈哈,后面就靠各位同仁99%的努力了.这篇为啥要讲移位寄存器呢,主要是之前做的项目和经验告 ...
- BufferedWniter_字符缓冲输出流和BufferedReader_字符缓冲输入流
java.io.BufferedWriter extends Writer BufferedWriter:字符缓冲输出流 继承自父类的共性成员方法: -void write(int c)写入单个字符 ...
- CF1703B ICPC Balloons 题解
题意:输入每个团队及团队的解决问题数,若是第一次解决则获得两个气球,其余获得一个气球. 做法:开一个数组记录是否为第一次解决该问题,直接模拟. #include<cstdio> #incl ...
- SQL语句的整合
基础语法 https://blog.csdn.net/m0_37989980/article/details/103413942 CRUD 提供给数据库管理员的基本操作,CRUD(Create, Re ...
- python--函数参数传递
1. 调用函数时,实参会传递给形参,叫做参数传递. 2. 根据实际参数的类型不同,函数参数的传递方式可分为 2 种,分别为值传递和引用(地址)传递: 值传递:传递的实参类型为不可变类型(字符串.数字. ...
- 技术分享|MySQL caching_sha2_password认证异常问题分析
欢迎来到 GreatSQL社区分享的MySQL技术文章,如有疑问或想学习的内容,可以在下方评论区留言,看到后会进行解答 0. 导读 相同的账号.密码,手动客户端连接可以成功,通过MySQL Conne ...
- Luogu1769 淘汰赛制_NOI导刊2010提高(01)(概率DP)
第\(i\)次位置在\(pos_0 / 2^{i - 1}\) #include <iostream> #include <cstdio> #include <cstri ...
- Luogu3855 [TJOI2008]Binary Land (BFS)
#include <iostream> #include <cstdio> #include <cstring> #include <algorithm> ...