pyspark 结构化数据开发实例
什么是SPARK?
1. 先进的大数据分布式编程和计算框架
2. 替换Hadoop 中的MR计算引擎。
3. 内存分布式计算:运行数度快
4. 可以使用不同的语言编程(java,scala,r 和python)
5. 可以从不同的数据源获取数据,可以从HDFS,Cassandea,HBase等等,同时可以支持很多的文件格式:text Seq AVRO Parquet
6. 实现不同的大数据功能:Spark Core,Sparc SQL等等
本文是基于pyspark 的进行数据ETL 和统计分析的代码示例,数据源来源于MySQL。 本文使用较小的数据量作为实例,当然同样适用于海量数据的情况。 运行本文代码的前提是
在Windows11 上搭建 pyspark 的开发环境。
我的环境:
1,jdk 1.8
2, hadoop 3.3.4
3, spark 3.3.1
4,python 3.9
代码设计要点:
1, 使用pyspark 读取 mysql 表数据。
2,使用rdd api 对 结构化数据做简单ETL,设置了简单的清洗规则。
1,cityCode 字段非空,全部为数字, 位数为9位, 前3位必须为”001“ 。
3, 使用3种抽象层级的API (RDD API , Dataframe api, SQL api )对数据进行分析计算 ,比较3种API的使用区别
4,包括了一些 rdd, Datafram 相互转换, ROW类型的使用
# Imports
from pyspark.sql import SparkSession # Create SparkSession
spark = SparkSession.builder \
.appName('SparkByExamples.com') \
.config("spark.jars", "mysql-connector-java-5.1.28.jar") \
.getOrCreate() # Read from MySQL Table
table_df = spark.read \
.format("jdbc") \
.option("driver", "com.mysql.jdbc.Driver") \
.option("url", "jdbc:mysql://134.**.**.**:9200/hesc_stm_xhm") \
.option("dbtable", "temp_user_grid") \
.option("user", "root") \
.option("password", "****") \
.load() # check read accessable
# print( table_df.count()) # 总行数 # etl 使用rdd 算子
rdd = table_df.rdd
# print(rdd.first()) # cityCode
# print(rdd.filter(lambda r: r(5) == None).count()) # gridCode为空的行数 rdd1 = rdd.filter(lambda r: Row.asDict(r).get("cityCode") != None).filter(
lambda r: len(Row.asDict(r).get("cityCode")) == 9) # print(rdd.map(lambda r: Row.asDict(r).get("cityCode")).take(5)) # ROW类型的元素读取 使用 r(19)读取列有问题 def checkCityCode(str):
# 判断字符串的格式,前3位为001,而且全为数字
if (str[:3] == '001') and str.isnumeric():
return True
else:
return False rdd2 = rdd1.filter(lambda r: checkCityCode(Row.asDict(r).get("cityCode")))
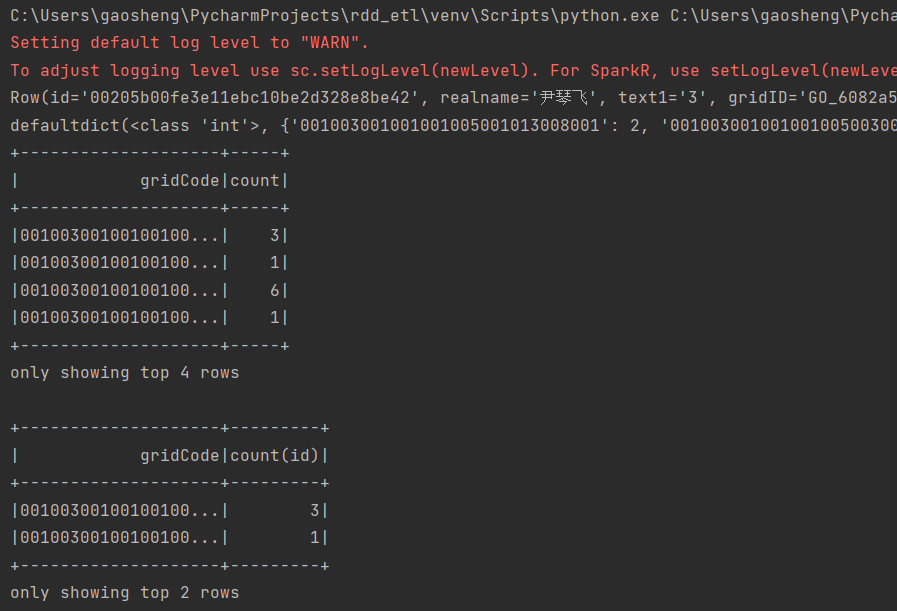
print(rdd2.first()) # 数据分析 使用 rdd df算子 sql 三种算子 ; 统计不同网格的人员数量。
# rdd operator map = rdd2.map(lambda r: (Row.asDict(r).get("gridCode"), Row.asDict(r).get("id"))).countByKey()
print(map) # 查询python rdd api # df/ds operator dataset 1.6之后加入, 整合了RDD 的强类型便于使用lambda函数以及 sqpark sql 优化引擎
# python 没有dataset 类型。java scala 可以。 dataframe是 dataset 的 一种。 dataframe 适用python . df = rdd2.toDF()
df1 = df.groupBy('gridCode').count() # dataframe 特定编程语言 对结构化数据操作, 也称 无类型dataset算子
df1.show(4) # sql operator
df.createOrReplaceTempView('temp_user_grip')
df2 = spark.sql("select gridCode, count(id) from temp_user_grip group by gridCode")
df2.show(2) spark.stop()
运行输出:
pyspark 结构化数据开发实例的更多相关文章
- seo之google rich-snippets丰富网页摘要结构化数据(微数据)实例代码
seo之google rich-snippets丰富网页摘要结构化数据(微数据)实例代码 网页摘要是搜索引擎搜索结果下的几行字,用户能通过网页摘要迅速了解到网页的大概内容,传统的摘要是纯文字摘要,而结 ...
- Bigtable:一个分布式的结构化数据存储系统
Bigtable:一个分布式的结构化数据存储系统 摘要 Bigtable是一个管理结构化数据的分布式存储系统,它被设计用来处理海量数据:分布在数千台通用服务器上的PB级的数据.Google的很多项目将 ...
- [Python]ctypes+struct实现类c的结构化数据串行处理
1. 用C/C++实现的结构化数据处理 在涉及到比较底层的通信协议开发过程中, 往往需要开发语言能够有效的表达和处理所定义的通信协议的数据结构. 在这方面是C/C++语言是具有天然优势的: 通过str ...
- Spark如何与深度学习框架协作,处理非结构化数据
随着大数据和AI业务的不断融合,大数据分析和处理过程中,通过深度学习技术对非结构化数据(如图片.音频.文本)进行大数据处理的业务场景越来越多.本文会介绍Spark如何与深度学习框架进行协同工作,在大数 ...
- 【阿里云产品公测】结构化数据服务OTS之JavaSDK初体验
[阿里云产品公测]结构化数据服务OTS之JavaSDK初体验 作者:阿里云用户蓝色之鹰 一.OTS简单介绍 OTS 是构建在阿里云飞天分布式系统之上的NoSQL数据库服务,提供海量结构化数据的存储和实 ...
- TensorFlow从1到2(六)结构化数据预处理和心脏病预测
结构化数据的预处理 前面所展示的一些示例已经很让人兴奋.但从总体看,数据类型还是比较单一的,比如图片,比如文本. 这个单一并非指数据的类型单一,而是指数据组成的每一部分,在模型中对于结果预测的影响基本 ...
- Solr系列四:Solr(solrj 、索引API 、 结构化数据导入)
一.SolrJ介绍 1. SolrJ是什么? Solr提供的用于JAVA应用中访问solr服务API的客户端jar.在我们的应用中引入solrj: <dependency> <gro ...
- Salesforce开源TransmogrifAI:用于结构化数据的端到端AutoML库
AutoML 即通过自动化的机器学习实现人工智能模型的快速构建,它可以简化机器学习流程,方便更多人利用人工智能技术.近日,软件行业巨头 Salesforce 开源了其 AutoML 库 Transmo ...
- Bigtable:结构化数据的分布式存储系统
Bigtable最初是谷歌设计用来存储大规模结构化数据的分布式系统,其可以在数以千计的商用服务器上存储高达PB级别的数据量.开源社区根据Bigtable的设计思路开发了HBase.其优势在于提供了高效 ...
- RocketMQ Schema——让消息成为流动的结构化数据
本文作者:许奕斌,阿里云智能高级研发工程师. Why we need schema RocketMQ 目前对于消息体没有任何数据格式的约束,可以是 JSON ,可以是对象 toString ,也可以只 ...
随机推荐
- 【转载】JAVA - 解决:Java.lang.NoClassDefFoundError: javax/xml/bind/JAXBException
抄:https://www.cnblogs.com/sunylat/p/13339507.html 问题原因: 高版本的JDK中不包含javax.xml.bind包了! 解决方法: 1,如果是mave ...
- JAVA虚拟机12--Class文件结构-属性表
1 属性表 1.1 简介 属性表(attribute_info)在前面的讲解之中已经出现过数次,Class文件.字段表.方法表都可以携带自己的属性表集合,以描述某些场景专有的信息. <Java虚 ...
- vue 事件中央总线
vue 事件中央总线 作用: 实现任意组件间的通信 实现的方法: 有以下两种方式 方式1: 全局事件总线 1.在main.js文件中定义 new Vue({ el: '#app', router, s ...
- 【CTO变形记】高维视角,跳出“农场主与火鸡”
前言:看待人事物的角度决定了我们的思考方向和处理事情的方式.在这些认识人事物的过程中,导致了一些"事故"发生:就好比"以手指月",原本要看"月亮&qu ...
- 软件设计师考试备考之UML
UML 统一建模语言是面向对象软件的标准化建模语言. 事务 结构事务 UML模型中的名称,它们通常是模型的静态部分,描述概念或物理元素 图形表示: 行为事务 UML模型中的动态部分.它们是模型中的动词 ...
- 多线程并发(二):聊聊AQS中的共享锁实现原理
在上一篇文章多线程并发(一)中我们通过acquire()详细地分析了AQS中的独占锁的获取流程,提到独占锁,自然少不了共享锁,所以我们这边文章就以AQS中的acquireShared()方法为例,来分 ...
- LeetCode ● 216.组合总和III ● 17.电话号码的字母组合
LeetCode 216.组合总和III 分析1.0 回溯问题 组合总和sum == n 时以及path中元素个数 == k 时,res.add(new path) 返回后递归删除掉当前值 class ...
- MongoDB从入门到实战之.NET Core使用MongoDB开发ToDoList系统(3)-系统数据集合设计
前言 前几章教程我们把ToDoList系统的基本框架搭建好了,现在我们需要根据我们的需求把ToDoList系统所需要的系统集合(相当于关系型数据库中的数据库表).接下来我们先简单概述一下这个系统主要需 ...
- K8S 实用工具之一 - 如何合并多个 kubeconfig?
开篇 引言: 磨刀不误砍柴工 工欲善其事必先利其器 K8S 集群规模,有的公司倾向于少量大规模 K8S 集群,也有的公司会倾向于大量小规模的 K8S 集群. 如果是第二种情况,是否有一个简单的 kub ...
- Docker安装和基础命令
每个优秀的人,背后都有一段沉默的时光 前言 学习Docker基础知识 安装 docker常见的有3种安装方式,yum.rpm包.脚本. 我们采用相对简单但对各种环境比较友好的方式:(关防火墙和seli ...