CPU TLB原理 [转载好文]
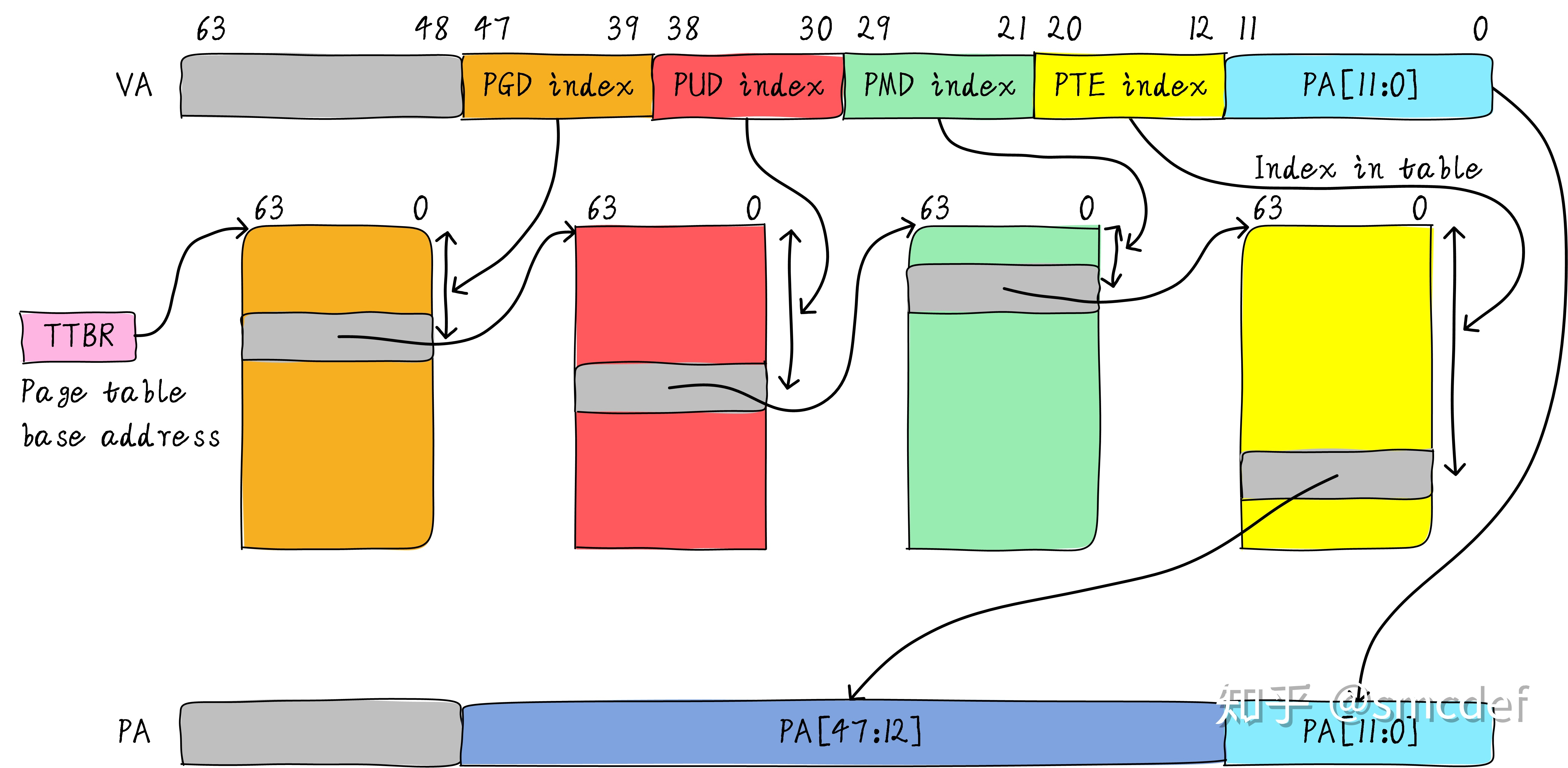
首先,我们知道MMU的作用是把虚拟地址转换成物理地址。虚拟地址和物理地址的映射关系存储在页表中,而现在页表又是分级的。64位系统常见的配置是4级页表,就以4级页表为例说明。分别是PGD、PUD、PMD、PTE四级页表。
在硬件上会有一个叫做页表基地址寄存器,它存储PGD页表的首地址。MMU就是根据页表基地址寄存器从PGD页表一路查到PTE,最终找到物理地址(PTE页表中存储物理地址)。
四级页表查找过程需要四次内存访问。延时可想而知,另外也很占用带宽。页表查找过程的示例如下图所示。
TLB 是如何工作的
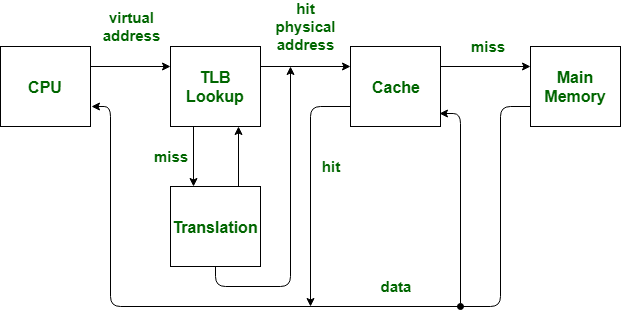
TLB(translation lookaside buffer),其实就是一块高速缓存。
- 数据cache缓存地址(虚拟地址或者物理地址)和数据。
- TLB缓存虚拟地址和其映射的物理地址。TLB根据虚拟地址查找cache,它没得选,只能根据虚拟地址查找。
- 跟CPU Cache一样,TLB也分D-TLB及I-TLB,也存在分组,也存在多级TLB;
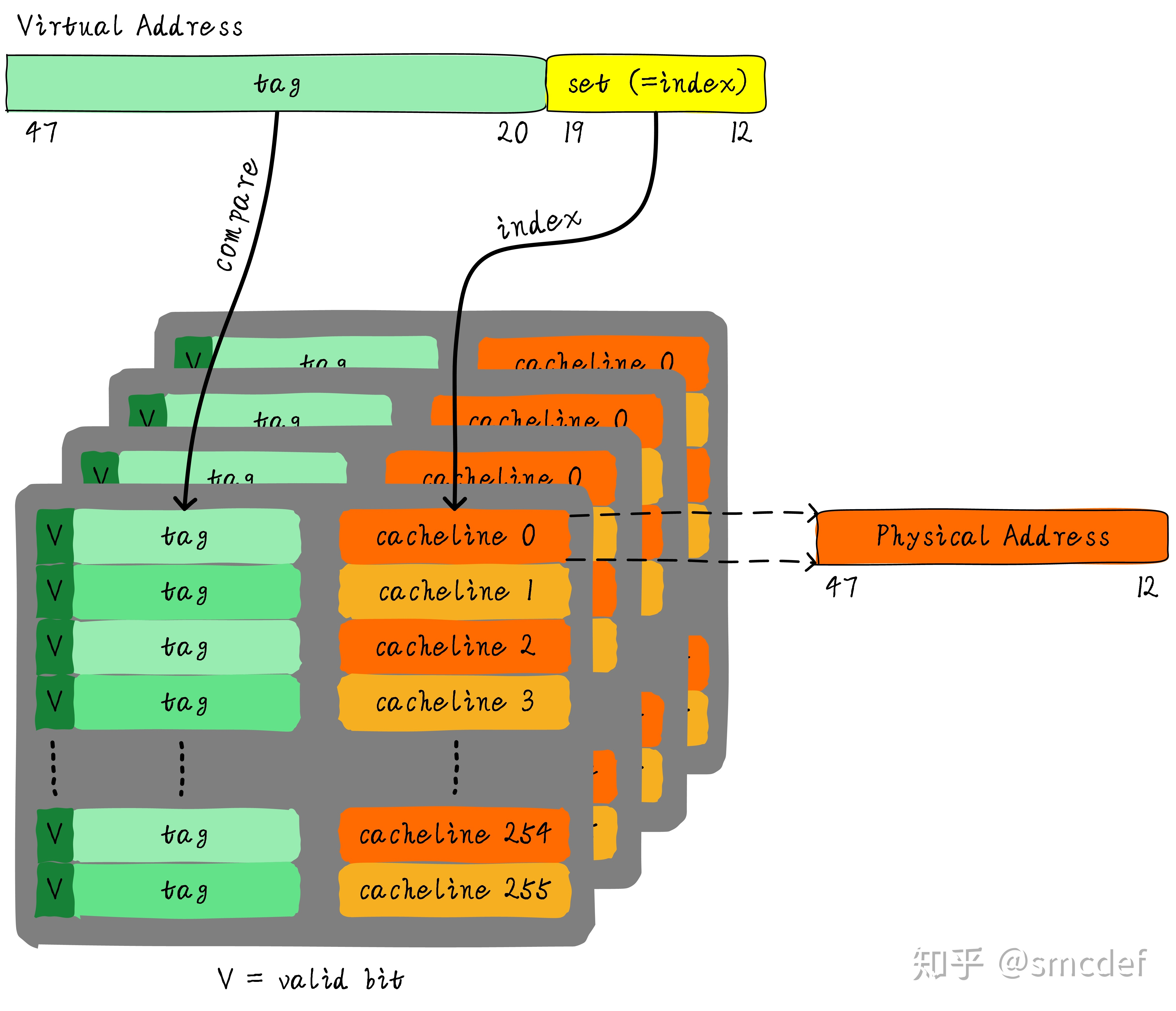
有了TLB后,虚拟地址到物理地址的转换过程发生了变化。虚拟地址首先发往TLB确认是否命中cache,如果cache hit直接可以得到物理地址。否则,一级一级查找页表获取物理地址。并将虚拟地址和物理地址的映射关系缓存到TLB中。
虚拟地址映射物理地址的最小单位是4KB。所以TLB其实不需要存储虚拟地址和物理地址的低12位(因为低12位是一样的,根本没必要存储)。另外,我们如果命中cache,肯定是一次性从cache中拿出整个数据。所以虚拟地址不需要offset域。index域是否需要呢?这取决于cache的组织形式。如果是全相连高速缓存。那么就不需要index。如果使用多路组相连高速缓存,依然需要index。下图就是一个四路组相连TLB的例子。现如今64位CPU寻址范围并没有扩大到64位。64位地址空间很大,现如今还用不到那么大。因此硬件为了设计简单或者解决成本,实际虚拟地址位数只使用了一部分。这里以48位地址总线为了例说明。
TLB 别名问题 (???)
我先来思考第一个问题,别名是否存在。我们知道PIPT的数据cache不存在别名问题。物理地址是唯一的,一个物理地址一定对应一个数据。但是不同的物理地址可能存储相同的数据。也就是说,物理地址对应数据是一对一关系,反过来是多对一关系。由于TLB的特殊性,存储的是虚拟地址和物理地址的对应关系。因此,对于单个进程来说,同一时间一个虚拟地址对应一个物理地址,一个物理地址可以被多个虚拟地址映射。将PIPT数据cache类比TLB,我们可以知道TLB不存在别名问题。而VIVT Cache存在别名问题,原因是VA需要转换成PA,PA里面才存储着数据。中间多经传一手,所以引入了些问题。
TLB 歧义问题
我们知道不同的进程之间看到的虚拟地址范围是一样的,所以多个进程下,不同进程的相同的虚拟地址可以映射不同的物理地址。这就会造成歧义问题。例如,进程A将地址0x2000映射物理地址0x4000。进程B将地址0x2000映射物理地址0x5000。当进程A执行的时候将0x2000对应0x4000的映射关系缓存到TLB中。当切换B进程的时候,B进程访问0x2000的数据,会由于命中TLB从物理地址0x4000取数据。这就造成了歧义。如何消除这种歧义,我们可以借鉴VIVT数据cache的处理方式,在进程切换时将整个TLB无效。切换后的进程都不会命中TLB,但是会导致性能损失。
如何尽可能的避免flush TLB
首先需要说明的是,这里的flush理解成使无效的意思。我们知道进程切换的时候,为了避免歧义,我们需要主动flush整个TLB。如果我们能够区分不同的进程的TLB表项就可以避免flush TLB。我们知道Linux如何区分不同的进程?每个进程拥有一个独一无二的进程ID。如果TLB在判断是否命中的时候,除了比较tag以外,再额外比较进程ID该多好呢!这样就可以区分不同进程的TLB表项。进程A和B虽然虚拟地址一样,但是进程ID不一样,自然就不会发生进程B命中进程A的TLB表项。所以,TLB添加一项ASID(Address Space ID)的匹配。ASID就类似进程ID一样,用来区分不同进程的TLB表项。这样在进程切换的时候就不需要flush TLB。但是仍然需要软件管理和分配ASID。
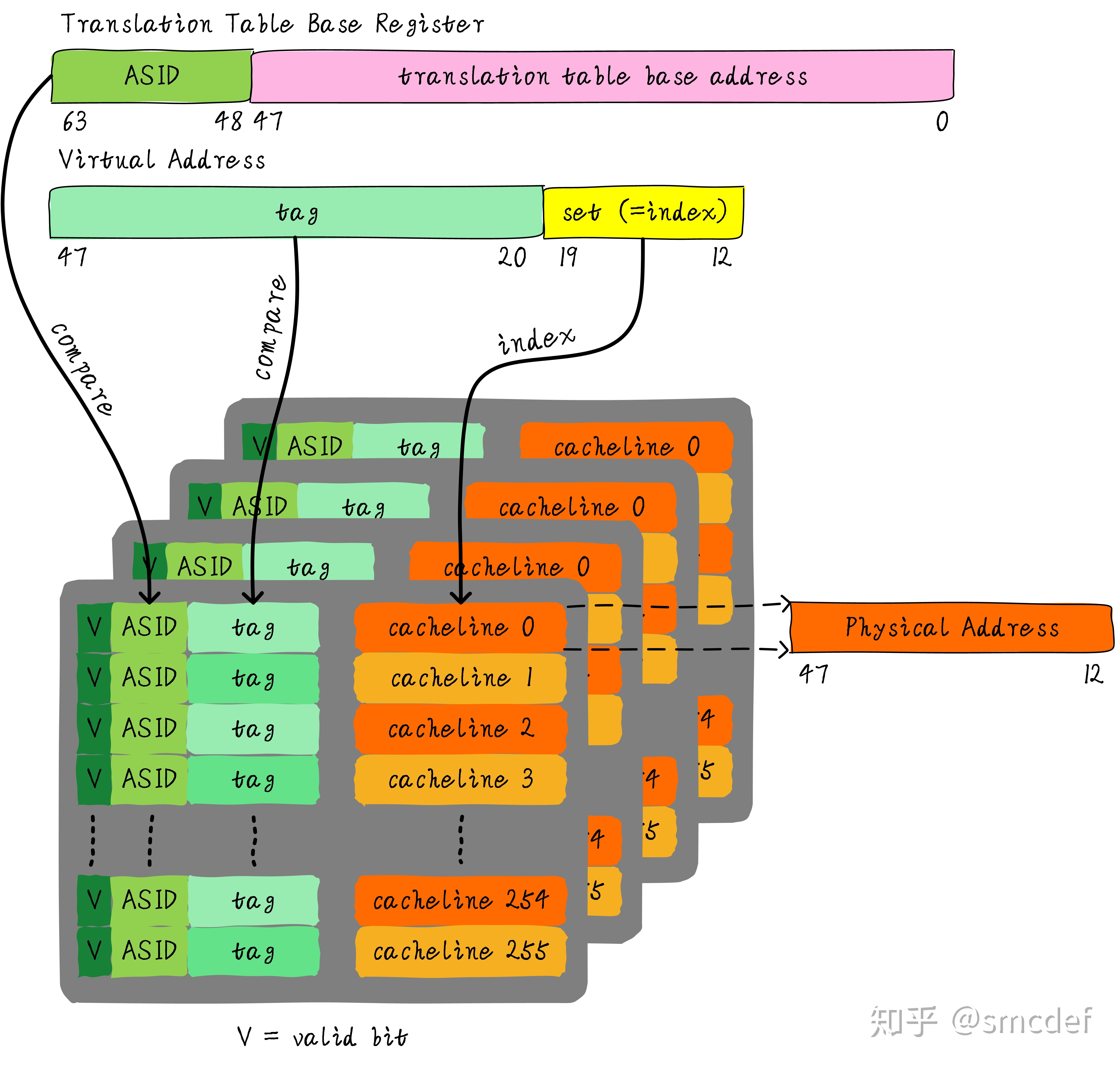
如何管理ASID
ASID和进程ID肯定是不一样的,别混淆二者。进程ID取值范围很大。但是ASID一般是8或16 bit。所以只能区分256或65536个进程。我们的例子就以8位ASID说明。所以我们不可能将进程ID和ASID一一对应,我们必须为每个进程分配一个ASID,进程ID和每个进程的ASID一般是不相等的。每创建一个新进程,就为之分配一个新的ASID。当ASID分配完后,flush所有TLB,重新分配ASID。所以,如果想完全避免flush TLB的话,理想情况下,运行的进程数目必须小于等于256。然而事实并非如此,因此管理ASID上需要软硬结合。 Linux kernel为了管理每个进程会有个task_struct结构体,我们可以把分配给当前进程的ASID存储在这里。页表基地址寄存器有空闲位也可以用来存储ASID。当进程切换时,可以将页表基地址和ASID(可以从task_struct获得)共同存储在页表基地址寄存器中。当查找TLB时,硬件可以对比tag以及ASID是否相等(对比页表基地址寄存器存储的ASID和TLB表项存储的ASID)。如果都相等,代表TLB hit。否则TLB miss。当TLB miss时,需要多级遍历页表,查找物理地址。然后缓存到TLB中,同时缓存当前的ASID。
更上一层楼
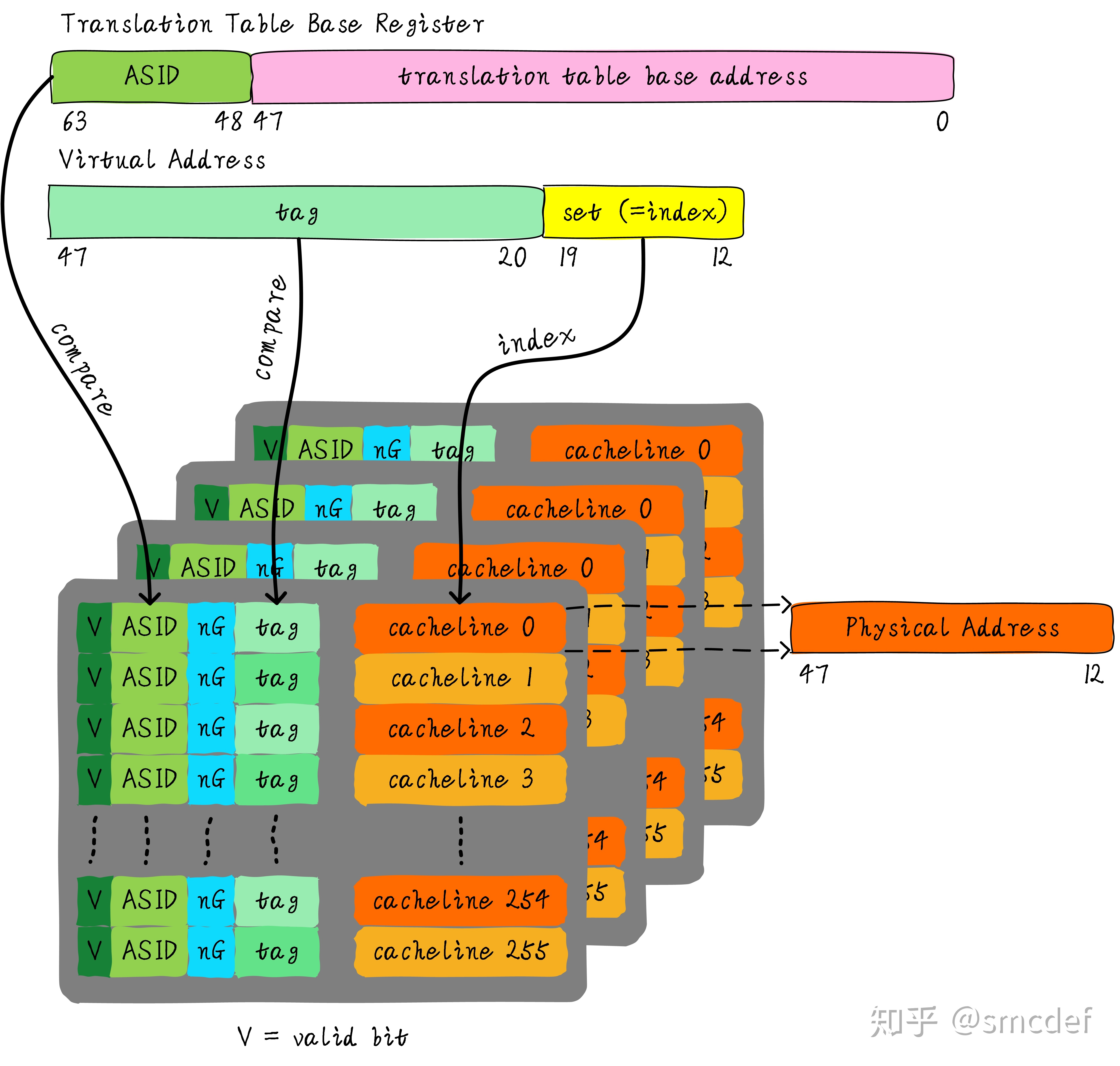
我们知道内核空间和用户空间是分开的,并且内核空间是所有进程共享。既然内核空间是共享的,进程A切换进程B的时候,如果进程B访问的地址位于内核空间,完全可以使用进程A缓存的TLB。但是现在由于ASID不一样,导致TLB miss。我们针对内核空间这种全局共享的映射关系称之为global映射。针对每个进程的映射称之为non-global映射。所以,我们在最后一级页表中引入一个bit(non-global (nG) bit)代表是不是global映射。当虚拟地址映射物理地址关系缓存到TLB时,将nG bit也存储下来。当判断是否命中TLB时,当比较tag相等时,再判断是不是global映射,如果是的话,直接判断TLB hit,无需比较ASID。当不是global映射时,最后比较ASID判断是否TLB hit。
ref
补充:TLB与CPU Cache
CPU TLB原理 [转载好文]的更多相关文章
- 「MoreThanJava」一文了解二进制和CPU工作原理
「MoreThanJava」 宣扬的是 「学习,不止 CODE」,本系列 Java 基础教程是自己在结合各方面的知识之后,对 Java 基础的一个总回顾,旨在 「帮助新朋友快速高质量的学习」. 当然 ...
- (转)计算机原理学习(1)-- 冯诺依曼体系和CPU工作原理
原文:https://blog.csdn.net/cc_net/article/details/10419645 对于我们80后来说,最早接触计算机应该是在95年左右,那个时候最流行的一个词语是多媒体 ...
- 计算机原理学习(1)-- 冯诺依曼体系和CPU工作原理
前言 对于我们80后来说,最早接触计算机应该是在95年左右,那个时候最流行的一个词语是多媒体. 依旧记得当时在同学家看同学输入几个DOS命令就成功的打开了一个游戏,当时实在是佩服的五体投地.因为对我来 ...
- CPU使用率原理及计算方式
本文转载自CPU使用率原理及计算方式 CPU:超线程和多核 超线程(Hyper-Threading ) 超线程是Intel最早提出一项技术,最早出现在2002年的Pentium4上.单个采用超线程的C ...
- Linux下高cpu解决方案(转载)
Linux下高cpu解决方案(转载 1.用top命令查看哪个进程占用CPU高gateway网关进程14094占用CPU高达891%,这个数值是进程内各个线程占用CPU的累加值. PID USER ...
- 深入浅出HTTPS工作原理(转载)
转载自: https://blog.csdn.net/wangtaomtk/article/details/80917081 深入浅出HTTPS工作原理 HTTP协议由于是明文传送,所以存在三大风险: ...
- EPOLL内核原理极简图文解读(转)
预备知识:内核poll钩子原理内核函数poll_wait把当前进程加入到驱动里自定义的等待队列上 当驱动事件就绪后,就可以在驱动里自定义的等待队列上唤醒调用poll的进程 故poll_wait作用:可 ...
- ahjesus 前端缓存原理 转载
LAMP缓存图 从图中我们可以看到网站缓存主要分为五部分 服务器缓存:主要是基于web反向代理的静态服务器nginx和squid,还有apache2的mod_proxy和mod_cache模 浏览器缓 ...
- [转载]在线文档预览方案-Office Web Apps
最近在做项目时,要在手机端实现在线文档预览的功能.于是百度了一下实现方案,大致是将文档转换成pdf,然后在通过插件实现预览.这些方案没有具体实现代码,也没有在线预览的地址,再加上项目时间紧迫.只能考虑 ...
- 汇编语言--寄存器(cpu工作原理)
本文地址:http://www.cnblogs.com/archimedes/p/assembly-register.html,转载请注明源地址. 本文主要将介绍的是8086 CPU中的寄存器, 寄存 ...
随机推荐
- spring的set注入方式流程图解
spring的set注入方式流程图解 自己学习spring的一些笔记,详细画出了spring的set方式实现依赖注入的流程. 注意:<property name="UserDao&qu ...
- Jsoup爬取网上数据完成翻译
Jsoup使用 首先进入Jsoup下载jar包 然后打开IDEA创建一个普通的java项目 在项目结构里创建 lib 目录 但是我们这样并不能直接进行使用 需要添加路径 右键点击 然后添加路径 选择模 ...
- 2、String类
String类 String 对象用于保存字符串,也就是一组字符序列 字符串常量对象是用双引号括起来的字符序列,例如:"你好"."12.07"."bo ...
- 6.第五篇 安装keepalived与Nginx
文章转载自:https://mp.weixin.qq.com/s?__biz=MzI1MDgwNzQ1MQ==&mid=2247483796&idx=1&sn=347664de ...
- logstash安装插件修改使用的gem源
gem source -l # 查看当前使用的gem源 gem source --remove https://rubygems.org/ # 移除gem源 gem source -a https:/ ...
- Alertmanager篇
报一直是整个监控系统中的重要组成部分,Prometheus监控系统中,采集与警报是分离的.警报规则在 Prometheus 定义,警报规则触发以后,才会将信息转发到给独立的组件 Alertmanage ...
- Ubuntu 20.04安装mysql后用mysql root无法登录
刚安装mysql后,执行 mysql -u root -p 提示无法执行 解决方案: sudo mysql -u root -p 使用root权限不用密码就能进入mysql 然后 >ALTER ...
- 洛谷P2627 [USACO11OPEN]Mowing the Lawn G (单调队列优化DP)
一道单调队列优化DP的入门题. f[i]表示到第i头牛时获得的最大效率. 状态转移方程:f[i]=max(f[j-1]-sum[j])+sum[i] ,i-k<=j<=i.j的意义表示断点 ...
- 记一次 .NET 某企业OA后端服务 卡死分析
一:背景 1.讲故事 前段时间有位朋友微信找到我,说他生产机器上的 Console 服务看起来像是卡死了,也不生成日志,对方也收不到我的httpclient请求,不知道程序出现什么情况了,特来寻求帮助 ...
- uoj349【WC2018】即时战略
题目链接 WC出了点意外滚粗了,来补补题. \(O(n^2)\)的时间复杂度,\(O(nlogn)\)的询问次数应该还是比较好想的,每次要打通到x的路径,对当前已知的树不断的找重心并询问在重心的哪颗子 ...