KNN算法之集美大学
在本篇文章中,我即将以在集美大学收集到的一些数据集为基础,使用KNN算法进行一系列的操作
一、KNN算法
首先,什么是KNN算法呢,这得用到老祖宗说的一句话“近朱者赤近墨者黑”,简单来讲就是,一个物体它靠近什么,我们也可以认为它就是什么。此算法运用广泛,生活中就有体现。比如,你是否发现,你好朋友刷到的抖音视频,你也可能提前刷到过,这就是KNN。
KNN也叫K近邻(K-Nearest Neighbor, KNN)是一种最经典和最简单的有监督学习方法之一。K-近邻算法是最简单的分类器,没有显式的学习过程或训练过程,是懒惰学习(Lazy Learning)。当对数据的分布只有很少或者没有任何先验知识时,K 近邻算法是一个不错的选择。
二、K自制数据集(基于集美大学)
集美大学于1918年始建,这所大学的名字很有意思,单纯从字面上看,这是一所集美丽于一身的大学。集美大学也正如名字所说,不仅学校美,周围的环境也跟着美。因为这所大学所在的地区被当地叫做集美学村,这个集美学村是一个旅游区,其中还包含了许多学府,从小学到大学一应俱全,集美大学就在其中,这里给人的感觉很大很美,既适合出行旅游观光,又是学术氛围浓厚之地。在集美大学读书感觉犹如在旅游一般,对于学生来说是一种美好的享受。
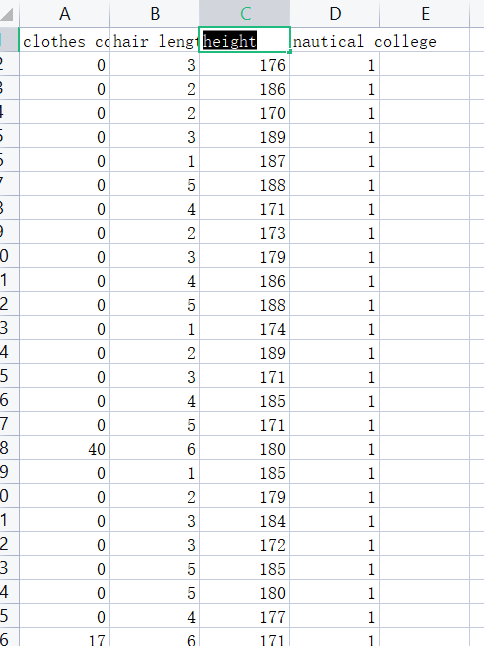
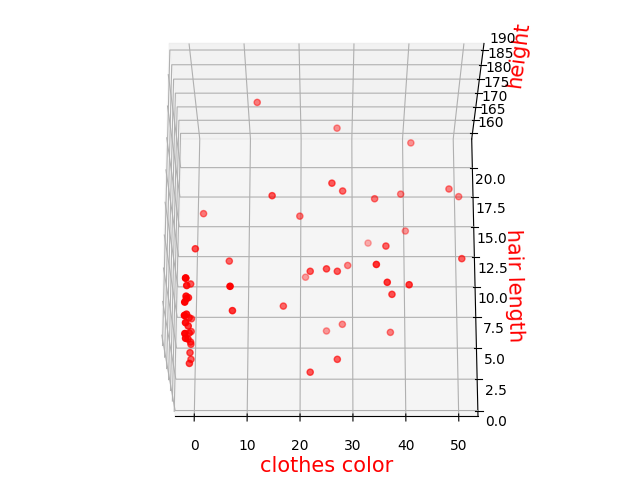
众所周知,航海是集美大学的特色专业,我运用Excel手动制作了一些数据,内容为航海学院和其他学院的学生数据差异。航海学院纪律严格,判断一个学生是不是航海学院的学子可以从以下角度分析:clothes color(航海学院身穿制度,颜色较为统一),hair length,height。如果是航海学院则nautical college置为1。还有数据三维散点图如下。

三、代码部分(主要运用了sklearn,pandas工具包)
1.预测
file = "sklearn/file/JMU.csv"
data = pd.read_csv(file)
lable = data.iloc[:, -1]
feature = data.iloc[:, :3]
# 2.划分数据集
x_train, x_test, y_train, y_test = train_test_split(feature, lable, test_size=0.2)
#网格搜索和交叉验证
para_dic={"n_neighbors":[i for i in range(1,20)]}
estimator=KNeighborsClassifier()
estimator=GridSearchCV(estimator,param_grid=para_dic)
estimator.fit(x_train,y_train)
# 模型评估
#1.比对真实值与预测值
# y_pre=estimator.predict(x_test)
# print("y_pre:\n",y_pre)
# print(y_pre==y_test)
#2.计算准确率
score=estimator.score(x_test,y_test)
print("准确率:\n",score) # 最佳参数
print("最佳参数:\n",estimator.best_params_)
# 最佳结果
print("最佳结果:\n",estimator.best_score_)
# 最佳估计器
print("最佳估计器:\n",estimator.best_estimator_)
准确率:
0.9166666666666666
最佳参数:
{'n_neighbors': 1}
最佳结果:
0.8936170212765957
最佳估计器:
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=1, p=2,
weights='uniform')
Process finished with exit code 0
2.作图
x = data.iloc[:, 0]
y = data.iloc[:, 1]
z = data.iloc[:, 2]
# 绘制散点图
fig = plt.figure()
ax = Axes3D(fig)
ax.scatter(x, y, z, color='r') # 添加坐标轴(顺序是Z, Y, X)
ax.set_zlabel('height', fontdict={'size': 15, 'color': 'red'})
ax.set_ylabel('hair length', fontdict={'size': 15, 'color': 'red'})
ax.set_xlabel('clothes color', fontdict={'size': 15, 'color': 'red'})
plt.show()
3.结果分析
通过网格搜索1到20的K值结果可知,最优K取值为1。也就是说找最近的一位同学是否属于航海学院,就能大概率判断这位未知同学是否也为海院学子。
思考,为什么会是K=1呢,通过散点图可以清楚看出,海院学子特征比较集中,所以只要距离海院学子特征最近,就大概率为海院学子。
KNN算法之集美大学的更多相关文章
- 【Machine Learning】KNN算法虹膜图片识别
K-近邻算法虹膜图片识别实战 作者:白宁超 2017年1月3日18:26:33 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现的深入理解.本系列文章是作者结 ...
- KNN算法
1.算法讲解 KNN算法是一个最基本.最简单的有监督算法,基本思路就是给定一个样本,先通过距离计算,得到这个样本最近的topK个样本,然后根据这topK个样本的标签,投票决定给定样本的标签: 训练过程 ...
- kNN算法python实现和简单数字识别
kNN算法 算法优缺点: 优点:精度高.对异常值不敏感.无输入数据假定 缺点:时间复杂度和空间复杂度都很高 适用数据范围:数值型和标称型 算法的思路: KNN算法(全称K最近邻算法),算法的思想很简单 ...
- 什么是 kNN 算法?
学习 machine learning 的最低要求是什么? 我发觉要求可以很低,甚至初中程度已经可以. 首先要学习一点 Python 编程,譬如这两本小孩子用的书:[1][2]便可. 数学方面 ...
- 数据挖掘之KNN算法(C#实现)
在十大经典数据挖掘算法中,KNN算法算得上是最为简单的一种.该算法是一种惰性学习法(lazy learner),与决策树.朴素贝叶斯这些急切学习法(eager learner)有所区别.惰性学习法仅仅 ...
- 机器学习笔记--KNN算法2-实战部分
本文申明:本系列的所有实验数据都是来自[美]Peter Harrington 写的<Machine Learning in Action>这本书,侵删. 一案例导入:玛利亚小姐最近寂寞了, ...
- 机器学习笔记--KNN算法1
前言 Hello ,everyone. 我是小花.大四毕业,留在学校有点事情,就在这里和大家吹吹我们的狐朋狗友算法---KNN算法,为什么叫狐朋狗友算法呢,在这里我先卖个关子,且听我慢慢道来. 一 K ...
- 学习OpenCV——KNN算法
转自:http://blog.csdn.net/lyflower/article/details/1728642 文本分类中KNN算法,该方法的思路非常简单直观:如果一个样本在特征空间中的k个最相似( ...
- KNN算法与Kd树
最近邻法和k-近邻法 下面图片中只有三种豆,有三个豆是未知的种类,如何判定他们的种类? 提供一种思路,即:未知的豆离哪种豆最近就认为未知豆和该豆是同一种类.由此,我们引出最近邻算法的定义:为了判定未知 ...
随机推荐
- HCIA-Datacom 3.3 实验三:以太网链路聚合实验
实验介绍 随着网络规模不断扩大,用户对骨干链路的带宽和可靠性提出越来越高的要求.在传统技术中,常用更换高速率的接口板或更换支持高速率接口板的设备的方式来增加带宽,但这种方案需要付出高额的费用,而且不够 ...
- 【Java】学习路径44-多线程入门篇
这一章,我们学习线程的创建.线程的启动.线程的名字设置.线程的休眠.线程的加入.守护线程. 一个线程是一个单独的类的对象. 想让一个普通的类变成多线程,那么这个类需要继承Thread. 创建多线程的步 ...
- 如何结合整洁架构和MVP模式提升前端开发体验 - 整体架构篇
本文不详细介绍什么是整洁架构以及 MVP 模式,自行查看文章结尾相关链接文章. 整洁架构粗略介绍 下图为整洁架构最原始的结构图: Entities/Models:实体层,官方说法就是封装了企业里最通用 ...
- C语言小游戏: 推箱子 支线(一)--1
好家伙,考完试了 回顾一下2021 回顾一下某次的作业 妙啊 所以, 做一个推箱子小游戏 1.先去4399找一下关卡灵感 就它了 2.在百度上搜几篇推箱子, 参考其中的"■ ☆"图 ...
- Linux常用基础命令三
一.ln 软链接 软链接也称为符号链接,类似于 windows 里的快捷方式,有自己的数据块,主要存放 了链接其他文件的路径. 在查看文件目录中,软连接是以'l'开头 创建软链接 ln -s [原文件 ...
- 当 SQL DELETE 邂逅 Table aliases,会擦出怎样的火花
开心一刻 晚上,女儿眼噙泪水躺在床上 女儿:你口口声声说爱我,说陪我,却天天想着骗我零花钱,你是我亲爹吗? 我:你想知道真相 女儿:想! 我:那你先给爸爸两百块钱! 环境准备 MySQL 不同版本 利 ...
- 复现禅道V16.5的SQL注入(CNVD-2022-42853)
漏洞详情 禅道V16.5未对输入的account参数内容作过滤校验,导致攻击者拼接恶意SQL语句执行. 环境搭建 环境下载:禅道V16.5 下载后双击运行,进入目录运行start.exe 直接访问即可 ...
- 面试突击87:说一下 Spring 事务传播机制?
Spring 事务传播机制是指,包含多个事务的方法在相互调用时,事务是如何在这些方法间传播的. 既然是"事务传播",所以事务的数量应该在两个或两个以上,Spring 事务传播机制的 ...
- 跟我学Python图像处理丨傅里叶变换之高通滤波和低通滤波
摘要:本文讲解基于傅里叶变换的高通滤波和低通滤波. 本文分享自华为云社区<[Python图像处理] 二十三.傅里叶变换之高通滤波和低通滤波>,作者:eastmount . 一.高通滤波 傅 ...
- 为什么数字化转型离不开 MES 系统?
确切的说应该是制造业企业的数字化转型离不开MES系统,原因很简单,制造业企业的核心工作是生产制造,做数字化转型就是对生产制造各个环节进行数字化改造,提质增效降成本,而MES系统是制造执行系统,是生产制 ...