GLM:通用语言模型
ChatGPT已经火了一段时间了,国内也出现了一些平替,其中比较容易使用的是ChatGLM-6B:https://github.com/THUDM/ChatGLM-6B ,主要是能够让我们基于单卡自己部署。ChatGLM的基座是GLM: General Language Model Pretraining with Autoregressive Blank Infilling论文中提出的模型,接下来我们来看看。
论文名称:GLM: General Language Model Pretraining with Autoregressive Blank Infilling
论文地址:https://aclanthology.org/2022.acl-long.26.pdf
代码地址:https://github.com/THUDM/GLM
介绍
预训练语言吗模型大体可以分为三种:自回归(GPT系列)、自编码(BERT系列)、编码-解码(T5、BART),它们每一个都在各自的领域上表现不俗,但是,目前没有一个预训练模型能够很好地完成所有任务。GLM是一个通用的预训练语言模型,它在NLU(自然语言理解)、conditional(条件文本生成) and unconditional generation(非条件文本生成)上都有着不错的表现。
GLM的核心是:Autoregressive Blank Infilling,如下图1所示:
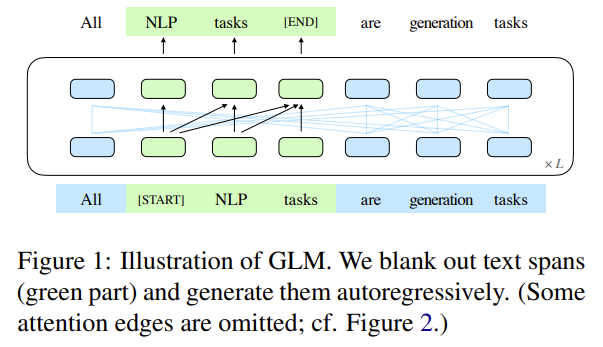
即,将文本中的一段或多段空白进行填充识别。具体细节如图2所示:

说明,对于一个文本:\(x_{1},x_{2},x_{3},x_{4},x_{5}\),空白长度会以\(\lambda=3\)的泊松分布进行采样。重复采样直到空白token的总数目占文本token数的15%。将文本分为两部分,A部分由原始token和[MASK]组成,B部分由空白token组成,最终将A部分和B部分进行拼接,同时B部分的每一个空白会被打乱,这样在自回归预测每个token的时候可以看到上下文的信息(具体通过注意力掩码来实现)。需要注意的是位置编码是2D的,位置编码1用于表示token在文本的位置,位置编码2用于表示原始文本和每一个空白中token的顺序。
多任务训练
为了能够兼顾NLU和文本生成,对于文档和句子采用不同的空白填充方式。
- 文档:span的长度从原始长度的50%-100%的均匀分布中抽取。该目标旨在生成长文本。
- 句子:限制masked span必须是完整的句子。多个span(句子)被取样,以覆盖15%的的原始标记。这个目标是针对seq2seq任务,其预测往往是完整的句子或段落。
模型架构
GLM使用单个Transformer,并对架构进行了修改:
(1)调整layer normalization和residual connection的顺序。
(2)使用单一线性层进行输出token预测。
(3)将ReLU激活函数替换为GeLUs。
2D位置编码
两个位置id通过可学习嵌入表投影到两个向量,这两个向量都被添加到输入标记嵌入中。该编码方法确保模型在重建时不知道被屏蔽的跨度的长度。这种设计适合下游任务,因为通常生成的文本的长度是事先未知的。
微调

对于分类任务,在模板后面预测类别。
- It’s a beautiful day, I’m in a great mood. it is [MASK]. [S] good
- I failed in the exam today. I was very depressed. it is [MASK] [S] bad
对于文本生成任务,输入的文本视为A部分,在该部分后面添加[MASK],使用自回归来生成文本。
这样的好处是预训练和微调是保持一致的。
结果
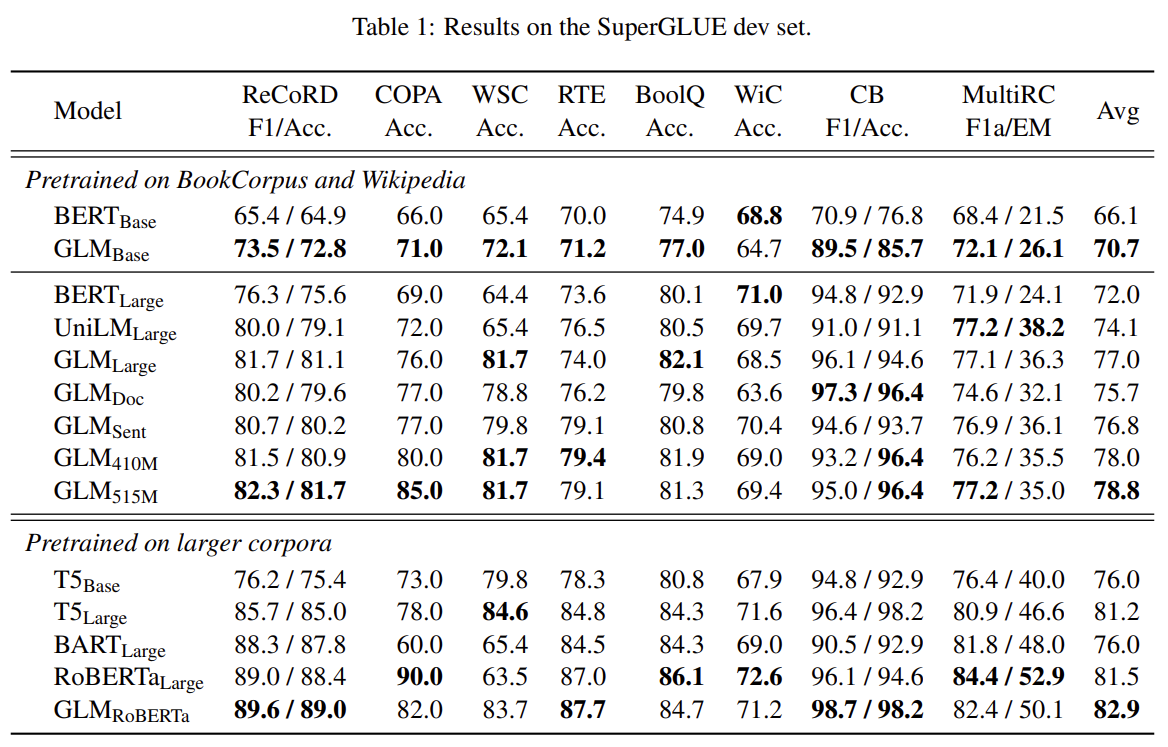
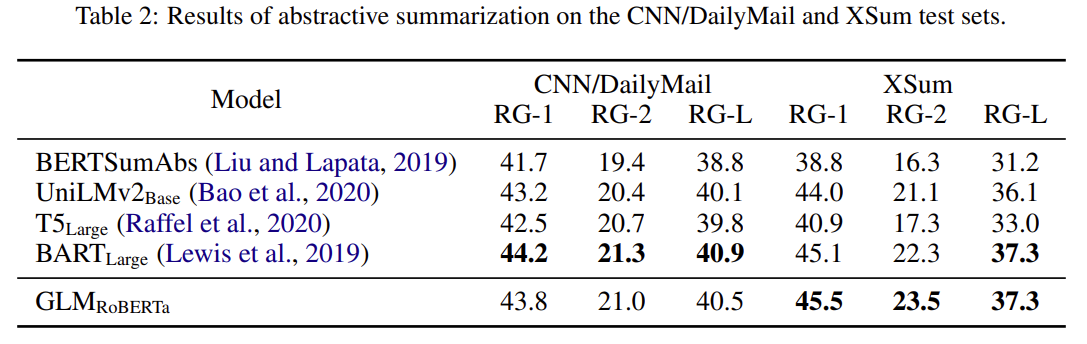
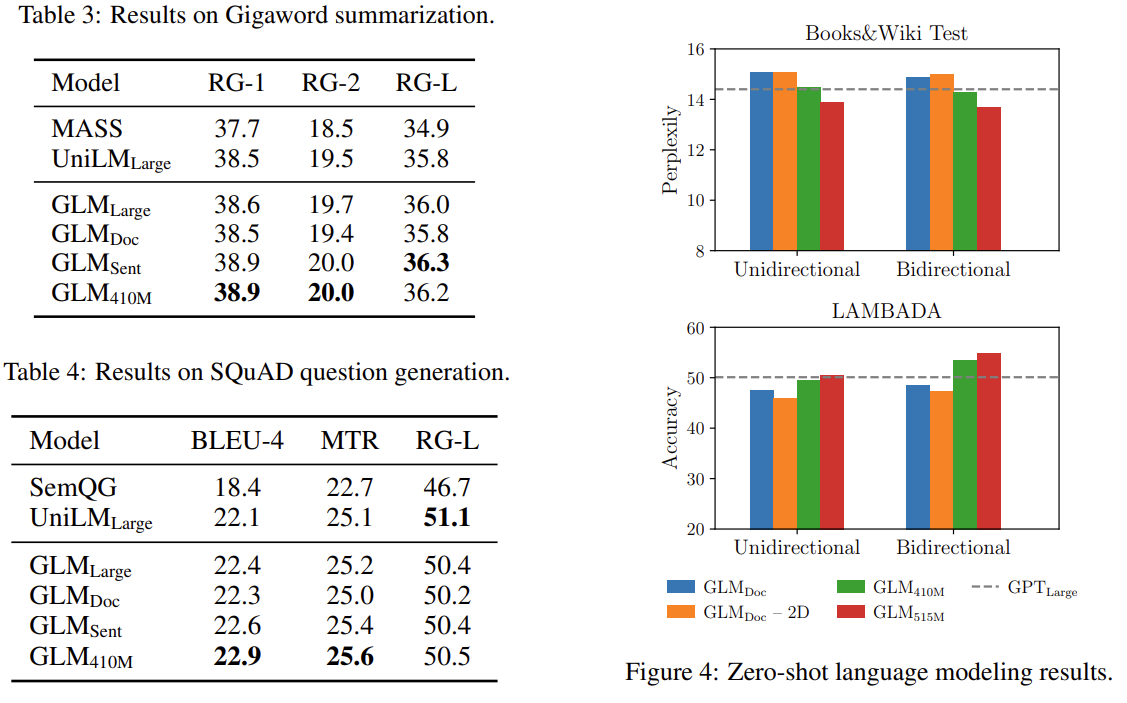
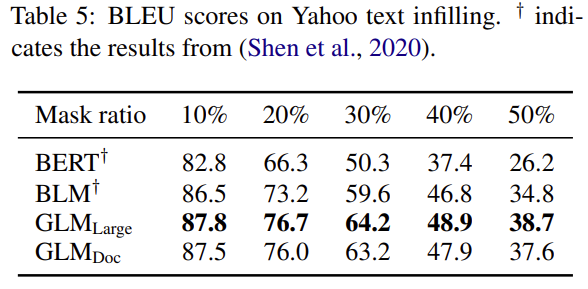
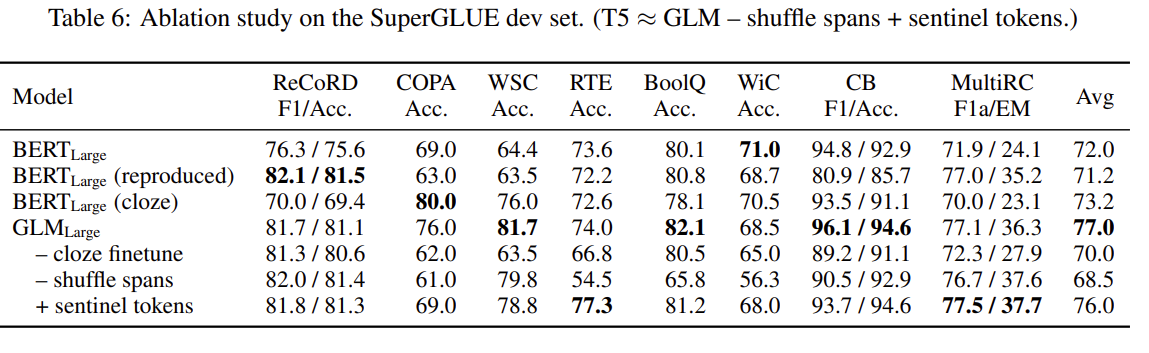
GLM:通用语言模型的更多相关文章
- 用迁移学习创造的通用语言模型ULMFiT,达到了文本分类的最佳水平
https://www.jqr.com/article/000225 这篇文章的目的是帮助新手和外行人更好地了解我们新论文,我们的论文展示了如何用更少的数据自动将文本分类,同时精确度还比原来的方法高. ...
- [转]语言模型训练工具SRILM
SRILM是一个建立和使用统计语言模型的开源工具包,从1995年开始由SRI 口语技术与研究实验室(SRI Speech Technology and Research Laboratory)开发,现 ...
- 斯坦福大学自然语言处理第四课“语言模型(Language Modeling)”
http://52opencourse.com/111/斯坦福大学自然语言处理第四课-语言模型(language-modeling) 一.课程介绍 斯坦福大学于2012年3月在Coursera启动了在 ...
- 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史(转载)
转载 https://zhuanlan.zhihu.com/p/49271699 首发于深度学习前沿笔记 写文章 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 张 ...
- 论文分享|《Universal Language Model Fine-tuning for Text Classificatio》
https://www.sohu.com/a/233269391_395209 本周我们要分享的论文是<Universal Language Model Fine-tuning for Text ...
- zz从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 Bert最近很火,应该是最近最火爆的AI进展,网上的评价很高,那么Bert值得这么高的评价吗?我个人判断是值得.那为什么 ...
- NLP基础
1 自然语言处理三大特征抽取器(CNN/RNN/TF)比较 白衣骑士Transformer:盖世英雄站上舞台 华山论剑:三大特征抽取器比较 综合排名情况 以上介绍内容是从几个不同角度来对RNN/CN ...
- NLP获取词向量的方法(Glove、n-gram、word2vec、fastText、ELMo 对比分析)
自然语言处理的第一步就是获取词向量,获取词向量的方法总体可以分为两种两种,一个是基于统计方法的,一种是基于语言模型的. 1 Glove - 基于统计方法 Glove是一个典型的基于统计的获取词向量的方 ...
- 斯坦福NLP课程 | 第15讲 - NLP文本生成任务
作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www. ...
- 视觉享受,兼顾人文观感和几何特征的字体「GitHub 热点速览 v.22.46」
GitHub 上开源的字体不在少数,但是支持汉字以及其他非英文语言的字体少之又少,记得上一个字体还是 霞鹜文楷,本周 B 站知名设计 UP 主开源了的得意黑体在人文观感和几何特征之间找到了美的平衡. ...
随机推荐
- js处理树形数组扁平化
// 树形数组扁平化 const extractTree = (data: TagsParams[]) => { if (!data.length) return []; const l ...
- c++学习6 指针变量
一 指针变量的定义 *是用来修饰指针变量的,通常情况下我们定义的手法都是"类型名"+"*"+"指针变量名称". 有一种简单无脑的" ...
- kali 下安装tplmap
kali 下安装tplmap 1. 安装kali下的python2的pip工具 kali2020版及以上, 输入python2命令会执行python2, python3也存在. 但pip默认是pip3 ...
- PLC入门笔记11
1.开关? 输入 拨杆开关.点动开关.常开.常闭开关 霍尔接近开关(磁场 N极导通 3线+-DC24V ).电容接近开关(非金属).电感接近开关(金属) 2.输入接线? NPN型,不需要外接电源,直接 ...
- jq的用法
选择页面中的元素,得到jQuery实例对象 ID选择器$("#save") 类选择器$(".class") 标签选择器$("div") 复合 ...
- LeetCode 之 111. 二叉树的最小深度
原题链接 思路: 递归计算每个子树的深度,返回左右子树中深度小的值: 由于题目中要求的是到最近叶子节点的深度,所以需要判断 左右子树为空的情况: python/python3: class Solut ...
- js 遍历对象属性
function* objectEntries(obj) { let propKeys = Reflect.ownKeys(obj); for (let propKey of propKeys) { ...
- 反射(Reflect)
反射摘要: 反射是java中非常强大的工具,利用反射可以书写框架,而框架就是半完成的代码.反射就是对类中的各个部分进行封装为其它对象,并且可以随时提取出Class或Object成员的属性,例如成员变量 ...
- []Python][simple]Serialize data with Pickle and deserialize data from pickle
序列化 import pickle friend = {"Dan": [20, "Lodon", 123123], "Mary" : [24 ...
- Postman设置Cookie参数为全局变量-环境变量设置IP参数
前提:在遇到多接口测试时,容易出现限制登录的情况 可以使用两种情况: 1.在调用其他接口前,先调用登录接口:这个方法在一般情况下可以,但是对于有些环境,比如像小程序登录时token(或cookie)是 ...