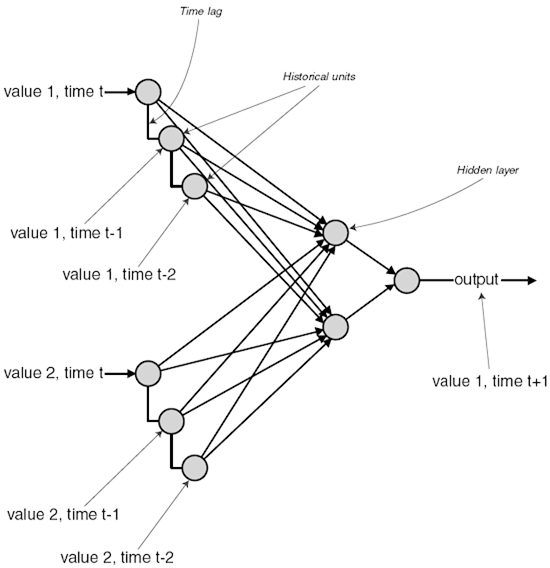
Elman network with additional notes
// Author: John McCullock
// Date: 10-15-05
// Description: Elman Network Example 1.
//http://www.mnemstudio.org/neural-networks-elman.htm
#include <iostream>
#include <iomanip>
#include <cmath>
#include <string>
#include <ctime>
#include <cstdlib> using namespace std; const int maxTests = 10000;
const int maxSamples = 4; const int inputNeurons = 6;
const int hiddenNeurons = 3;
const int outputNeurons = 6;
const int contextNeurons = 3; const double learnRate = 0.2; //Rho.
const int trainingReps = 2000; //beVector is the symbol used to start or end a sequence.
double beVector[inputNeurons] = {1.0, 0.0, 0.0, 0.0, 0.0, 0.0}; // 0 1 2 3 4 5
double sampleInput[3][inputNeurons] = {{0.0, 0.0, 0.0, 1.0, 0.0, 0.0},
{0.0, 0.0, 0.0, 0.0, 0.0, 1.0},
{0.0, 0.0, 1.0, 0.0, 0.0, 0.0}}; //Input to Hidden weights (with biases).
double wih[inputNeurons + 1][hiddenNeurons]; //Context to Hidden weights (with biases).
double wch[contextNeurons + 1][hiddenNeurons]; //Hidden to Output weights (with biases).
double who[hiddenNeurons + 1][outputNeurons]; //Hidden to Context weights (no biases).
double whc[outputNeurons + 1][contextNeurons]; //Activations.
double inputs[inputNeurons];
double hidden[hiddenNeurons];
double target[outputNeurons];
double actual[outputNeurons];
double context[contextNeurons]; //Unit errors.
double erro[outputNeurons];
double errh[hiddenNeurons]; void ElmanNetwork();
void testNetwork();
void feedForward();
void backPropagate();
void assignRandomWeights();
int getRandomNumber();
double sigmoid(double val);
double sigmoidDerivative(double val); int main(){ cout << fixed << setprecision(3) << endl; //Format all the output.
srand((unsigned)time(0)); //Seed random number generator with system time.
ElmanNetwork();
testNetwork(); return 0;
} void ElmanNetwork(){
double err;
int sample = 0;
int iterations = 0;
bool stopLoop = false; assignRandomWeights(); //Train the network.
do { if(sample == 0){
for(int i = 0; i <= (inputNeurons - 1); i++){
inputs[i] = beVector[i];
} // i
} else {
for(int i = 0; i <= (inputNeurons - 1); i++){
inputs[i] = sampleInput[sample - 1][i];
} // i
} //After the samples are entered into the input units, the sample are
//then offset by one and entered into target-output units for
//later comparison.
if(sample == maxSamples - 1){
for(int i = 0; i <= (inputNeurons - 1); i++){
target[i] = beVector[i];
} // i
} else {
for(int i = 0; i <= (inputNeurons - 1); i++){
target[i] = sampleInput[sample][i];
} // i
} feedForward(); err = 0.0;
for(int i = 0; i <= (outputNeurons - 1); i++){
err += sqrt(target[i] - actual[i]);
} // i
err = 0.5 * err; if(iterations > trainingReps){
stopLoop = true;
}
iterations += 1; backPropagate(); sample += 1;
if(sample == maxSamples){
sample = 0;
}
} while(stopLoop == false); cout << "Iterations = " << iterations << endl;
} void testNetwork(){
int index;
int randomNumber, predicted;
bool stopTest, stopSample, successful; //Test the network with random input patterns.
stopTest = false;
for(int test = 0; test <= maxTests; test++){ //Enter Beginning string.
inputs[0] = 1.0;
inputs[1] = 0.0;
inputs[2] = 0.0;
inputs[3] = 0.0;
inputs[4] = 0.0;
inputs[5] = 0.0;
cout << "(0) "; feedForward(); stopSample = false;
successful = false;
index = 0; //note:If failed then index start from 0 again
/*However, the nature of this kind of recurrent network is easier to understand (at least to me),
imply by referring to the unit's position in serial order (i.e.; Y0, Y1, Y2, Y3, ...).
So for the purpose of this illustration, I'll just use strings of numbers like: 0, 3, 5, 2, 0,
where 0 refers to Y0, 3 refers to Y3, 5 refers to Y5, etc. Each string begins and ends with a terminal symbol; I'll use 0 for this example.*/
randomNumber = 0;
predicted = 0; do { for(int i = 0; i <= 5; i++){
cout << actual[i] << " ";
if(actual[i] >= 0.3){
//The output unit with the highest value (usually over 3.0)
//is the network's predicted unit that it expects to appear
//in the next input vector.
//For example, if the 3rd output unit has the highest value,
//the network expects the 3rd unit in the next input to
//be 1.0
//If the actual value isn't what it expected, the random
//sequence has failed, and a new test sequence begins.
predicted = i;
}
} // i
cout << "\n"; randomNumber = getRandomNumber(); //Enter a random letter. index += 1; //Increment to the next position.
if(index == 5){
stopSample = true;
} else {
cout << "(" << randomNumber << ") ";
} for( i = 0; i <= 5; i++){
if(i == randomNumber){//note:i==randomNumber&&i == predicted then succeed
inputs[i] = 1.0;
if(i == predicted){
successful = true;
//for(int k=0;k<5;k++)//have a look;
// cout<<"\nTang :the sequence is:"<<inputs[k]<<'\t';
//cout<<endl;
} else {
//Failure. Stop this sample and try a new sample.
stopSample = true;
}
} else {
inputs[i] = 0.0;
}
} // i feedForward(); } while(stopSample == false); //Enter another letter into this sample sequence. if((index > 4) && (successful == true)){ //note: stop the iteration until success a sequence matching success at least 5 times.
//If the random sequence happens to be in the correct order,
//the network reports success.
cout << "Success." << endl;
cout << "Completed " << test << " tests." << endl;
stopTest = true;
break;
} else {
cout << "Failed." << endl;
if(test > maxTests){
stopTest = true;
cout << "Completed " << test << " tests with no success." << endl;
break;
}
}
} // Test
} void feedForward(){
double sum; //Calculate input and context connections to hidden layer.
for(int hid = 0; hid <= (hiddenNeurons - 1); hid++){
sum = 0.0;
//from input to hidden...
for(int inp = 0; inp <= (inputNeurons - 1); inp++){
sum += inputs[inp] * wih[inp][hid];
} // inp
//from context to hidden...
for(int con = 0; con <= (contextNeurons - 1); con++){
sum += context[con] * wch[con][hid];
} // con
//Add in bias.
sum += wih[inputNeurons][hid];
sum += wch[contextNeurons][hid];
hidden[hid] = sigmoid(sum);
} // hid //Calculate the hidden to output layer.
for(int out = 0; out <= (outputNeurons - 1); out++){
sum = 0.0;
for(int hid = 0; hid <= (hiddenNeurons - 1); hid++){
sum += hidden[hid] * who[hid][out];
} // hid //Add in bias.
sum += who[hiddenNeurons][out];
actual[out] = sigmoid(sum);
} // out //Copy outputs of the hidden to context layer.
for(int con = 0; con <= (contextNeurons - 1); con++){
context[con] = hidden[con];
} // con } void backPropagate(){ //Calculate the output layer error (step 3 for output cell).
for(int out = 0; out <= (outputNeurons - 1); out++){
erro[out] = (target[out] - actual[out]) * sigmoidDerivative(actual[out]);
} // out //Calculate the hidden layer error (step 3 for hidden cell).
for(int hid = 0; hid <= (hiddenNeurons - 1); hid++){
errh[hid] = 0.0;
for(int out = 0; out <= (outputNeurons - 1); out++){
errh[hid] += erro[out] * who[hid][out];
} // out
errh[hid] *= sigmoidDerivative(hidden[hid]);
} // hid //Update the weights for the output layer (step 4).
for( out = 0; out <= (outputNeurons - 1); out++){
for(int hid = 0; hid <= (hiddenNeurons - 1); hid++){
who[hid][out] += (learnRate * erro[out] * hidden[hid]);
} // hid
//Update the bias.
who[hiddenNeurons][out] += (learnRate * erro[out]);
} // out //Update the weights for the hidden layer (step 4).
for( hid = 0; hid <= (hiddenNeurons - 1); hid++){
for(int inp = 0; inp <= (inputNeurons - 1); inp++){
wih[inp][hid] += (learnRate * errh[hid] * inputs[inp]);
} // inp
//Update the bias.
wih[inputNeurons][hid] += (learnRate * errh[hid]);
} // hid } void assignRandomWeights(){ for(int inp = 0; inp <= inputNeurons; inp++){
for(int hid = 0; hid <= (hiddenNeurons - 1); hid++){
//Assign a random weight value between -0.5 and 0.5
wih[inp][hid] = -0.5 + double(rand()/(RAND_MAX + 1.0));
} // hid
} // inp for(int con = 0; con <= contextNeurons; con++){
for(int hid = 0; hid <= (hiddenNeurons - 1); hid++){
//Assign a random weight value between -0.5 and 0.5
wch[con][hid] = -0.5 + double(rand()/(RAND_MAX + 1.0));
} // hid
} // con for(int hid = 0; hid <= hiddenNeurons; hid++){
for(int out = 0; out <= (outputNeurons - 1); out++){
//Assign a random weight value between -0.5 and 0.5
who[hid][out] = -0.5 + double(rand()/(RAND_MAX + 1.0));
} // out
} // hid for(int out = 0; out <= outputNeurons; out++){
for(int con = 0; con <= (contextNeurons - 1); con++){
//These are all fixed weights set to 0.5
whc[out][con] = 0.5;
} // con
} // out } int getRandomNumber(){
//Generate random value between 0 and 6.
return int(6*rand()/(RAND_MAX + 1.0));
} double sigmoid(double val){
return (1.0 / (1.0 + exp(-val)));
} double sigmoidDerivative(double val){
return (val * (1.0 - val));
}
Elman network with additional notes的更多相关文章
- 论文笔记之:Progressive Neural Network Google DeepMind
Progressive Neural Network Google DeepMind 摘要:学习去解决任务的复杂序列 --- 结合 transfer (迁移),并且避免 catastrophic f ...
- 详解循环神经网络(Recurrent Neural Network)
本文结构: 模型 训练算法 基于 RNN 的语言模型例子 代码实现 1. 模型 和全连接网络的区别 更细致到向量级的连接图 为什么循环神经网络可以往前看任意多个输入值 循环神经网络种类繁多,今天只看最 ...
- Heterogeneous Self-Organizing Network for Access and Backhaul
This application discloses methods for creating self-organizing networks implemented on heterogeneou ...
- Real-time storage area network
A cluster of computing systems is provided with guaranteed real-time access to data storage in a sto ...
- Gitlab的搭建
从网上看了一大堆的资料,最终选定按照github上的文档来搭建,虽然本人英文不好,就这样看着 这个博客弯曲完全是拷贝过来的,只为了做个笔记 原文地址:https://github.com/gitlab ...
- CentOS6.5Minimal安装Gitlab7.5
文章出处:http://www.restran.net/2015/04/09/gilab-centos-installation-note/ 在 CentOS 6.5 Minimal 系统环境下,用源 ...
- Windows Server 2008 HPC 版本介绍以及的Pack
最近接触了下 这个比较少见的 Windows Server版本 Windows Server 2008 HPC 微软官方的介绍 http://www.microsoft.com/china/hpc/ ...
- 【Caffe 测试】Training LeNet on MNIST with Caffe
Training LeNet on MNIST with Caffe We will assume that you have Caffe successfully compiled. If not, ...
- rsync Backups for Windows
Transfer your Windows Backups to an rsync server over SSH rsync.net provides cloud storage for offsi ...
随机推荐
- .NET core实现一个简易的事件协调器(saga)
在领域驱动设计中,由于领域边界的存在,以往的分层设计中业务会按照其固有的领域知识被切分到不同的限界中,并且引入了领域事件这一概念来降低单个业务的复杂度,通过非耦合的事件驱动来完成复杂的业务.但是事件驱 ...
- Ribbon负载均衡及其应用
nginx - 随笔分类 - 池塘里洗澡的鸭子 - 博客园 (cnblogs.com)中涉及到负载均衡,为何此处由涉及Ribbon负载均衡呢?那是因为ngnix是服务端的负责均衡,而Ribbon是客户 ...
- Netty源码解析一——线程池模型之线程池NioEventLoopGroup
本文基础是需要有Netty的使用经验,如果没有编码经验,可以参考官网给的例子:https://netty.io/wiki/user-guide-for-4.x.html.另外本文也是针对的是Netty ...
- excel写入数值型内容
一开始的想法是设置单元格格式为数值型 XSSFDataFormat format= (XSSFDataFormat) workbook.createDataFormat(); CellStyle cs ...
- [Graphviz]一些简单的例子(未完待续)
本文参考:http://wenku.baidu.com/link?url=kTPIn5tBY4eboEPZeOZyLwHAq-fSMoTbagsqcG5-IcpL325tnnh3ES8aky-PBjP ...
- python中类似c++静态方法的一个记录
个人学习c++出身,在后面的工作中接触到python,见到一些classmethod的字眼有点疑惑,所以进行一些记录. 都知道的是,c/c++中有着静态成员,静态方法的存在,比如: class A: ...
- C# InterFace 接口
接口设计方式 自顶向下 (如图所示),自底向上. 接口成员: 事件 public interface IDrawingObject { event EventHandler ShapeChanged; ...
- 自己写了个Java RMI(远程方法调用)的实现案例
自己简单写了个Java RMI(远程方法调用)的实现案例. 为了更好理解RMI(远程方法调用).序列化的意义等等,花费三天多的时间肝了一个Java RMI的实现案例. !!!高能预警!!! 代码量有点 ...
- C语言while循环语句
循环语句三要素 1.在循环外给循环变量赋初值2.进入循环判断循环变量3.在循环体内修改循环变量,使循环趋近结束 2021-11-02
- 解压jdk报错gzip: stdin: not in gzip format
0x00 报错截图 0x01 下载方式 下载地址是直接在oracle官网[复制链接地址]获得. 0x02 解决问题 查看一下下载的文件 发现下载下来的是HTML文件. 然后就去oracle官网抓包看了 ...