espnet中的transformer和LSTM语言模型对比实验
摘要:本文以aishell为例,通过对比实验为大家介绍transformer和LSTM语言模型。
本文分享自华为云社区《espnet中的transformer和LSTM语言模型对比---以aishell为例》,作者: 可爱又积极 。
NLP特征提取器简介 - RNN和Transformer
近年来,深度学习在各个NLP任务中都取得了SOTA结果,我们先了解一下现阶段在自然语言处理领域最常用的特征抽取结构。
长短期记忆网络(LSTM)
传统RNN的做法是将所有知识全部提取出来,不作任何处理的输入到下一个时间步进行迭代。就像参加考试一样,如果希望事先把书本上的所有知识都记住,到了考试的时候,早期的知识恐怕已经被近期的知识完全覆盖了,提取不到长远时间步的信息是很正常的。而人类是这样做的吗?显然不是的,我们通常的做法是对知识有一个理性判断,重要的知识给予更高的权重,重点记忆,不那么重要的可能没多久就忘了,这样,才能在面对考试的时候有较好的发挥。在我看来,LSTM的结构更类似于人类对于知识的记忆方式。理解LSTM的关键就在于理解两个状态ct和at和内部的三个门机制:
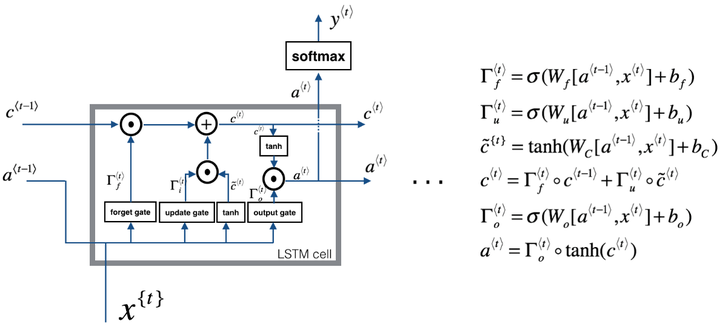
图中我们可以看见,LSTM Cell在每个时间步接收上个时间步的输入有两个,传给下一个时间步的输出也有两个。通常,我们将c(t)看作全局信息,at看作全局信息对下一个Cell影响的隐藏状态。
遗忘门、输入门(图中的update gate)和输出门分别都是一个激活函数为sigmoid的小型单层神经网络。由于sigmoid在(0,1)范围内的取值,有效的用于判断是保留还是“遗忘”信息(乘以接近1的值表示保留,乘以接近0的值表示遗忘),为我们提供了信息选择性传输的能力。
这样看下来,是不是觉得LSTM已经十分"智能"了呢?但实际上,LSTM还是有其局限性:时序性的结构一方面使其很难具备高效的并行计算能力(当前状态的计算不仅要依赖当前的输入,还要依赖上一个状态的输出),另一方面使得整个LSTM模型(包括其他的RNN模型,如GRU)总体上更类似于一个马尔可夫决策过程,较难以提取全局信息。
GRU可以看作一个LSTM的简化版本,其将at与ct两个变量整合在一起,且讲遗忘门和输入门整合为更新门,输出门变更为重制门,大体思路没有太大变化。两者之间的性能往往差别不大,但GRU相对来说参数量更少。收敛速度更快。对于较少的数据集我建议使用GRU就已经足够了,对于较大的数据集,可以试试有较多参数量的LSTM有没有令人意外的效果。
Transformer
图中红框内为Encoder框架,黄框内为Decoder框架,其均是由多个Transformer Block堆叠而成的。这里的Transformer Block就代替了我们LSTM和CNN结构作为了我们的特征提取器,也是其最关键的部分。
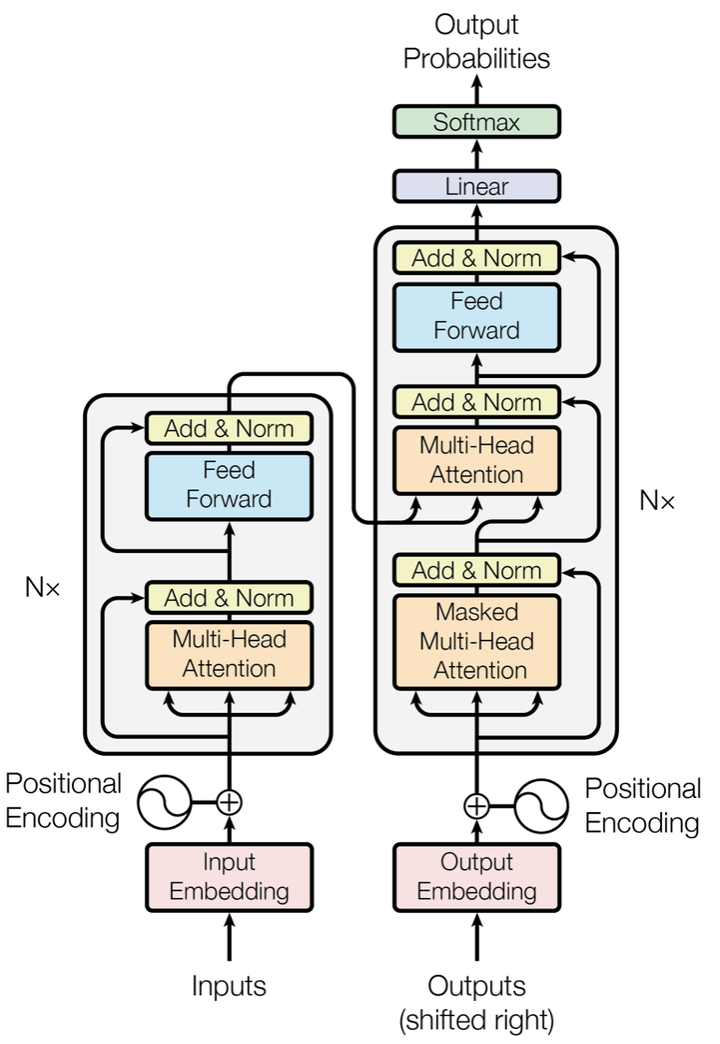
作者采用Attention机制的原因是考虑到RNN(或者LSTM,GRU等)的计算限制为是顺序的,也就是说RNN相关算法只能从左向右依次计算或者从右向左依次计算,这种机制带来了两个问题:
- 时间片t的计算依赖t-1时刻的计算结果,这样限制了模型的并行能力;
- 顺序计算的过程中信息会丢失,尽管LSTM等门机制的结构一定程度上缓解了长期依赖的问题,但是对于特别长期的依赖现象,LSTM依旧无能为力。
Transformer的提出解决了上面两个问题,首先它使用了Attention机制,将序列中的任意两个位置之间的距离是缩小为一个常量;其次它不是类似RNN的顺序结构,因此具有更好的并行性,符合现有的GPU框架。
从语义特征提取能力:Transformer显著超过RNN和CNN,RNN和CNN两者能力差不太多。
长距离特征捕获能力:CNN极为显著地弱于RNN和Transformer,Transformer微弱优于RNN模型,但在比较远的距离上(主语谓语距离大于13),RNN微弱优于Transformer,所以综合看,可以认为Transformer和RNN在这方面能力差不太多,而CNN则显著弱于前两者。这部分我们之前也提到过,CNN提取长距离特征的能力收到其卷积核感受野的限制,实验证明,增大卷积核的尺寸,增加网络深度,可以增加CNN的长距离特征捕获能力。而对于Transformer来说,其长距离特征捕获能力主要受到Multi-Head数量的影响,Multi-Head的数量越多,Transformer的长距离特征捕获能力越强。
任务综合特征抽取能力:通常,机器翻译任务是对NLP各项处理能力综合要求最高的任务之一,要想获得高质量的翻译结果,对于两种语言的词法,句法,语义,上下文处理能力,长距离特征捕获等方面的性能要求都是很高的。从综合特征抽取能力角度衡量,Transformer显著强于RNN和CNN,而RNN和CNN的表现差不太多。
并行计算能力:对于并行计算能力,上文很多地方都提到过,并行计算是RNN的严重缺陷,而Transformer和CNN差不多。
espnet中的transformer和LSTM语言模型对比实验
espnet所有的例子中语言模均默认是LSTM,这里我以aishell为例,epoch设置为20,batchsize=64。
LSTM结构配置:
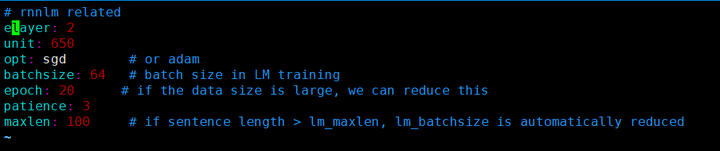
LSTM结果:
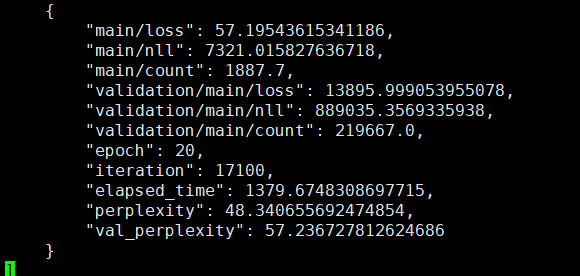
将语言模型换为transformer。transformer结构配置:
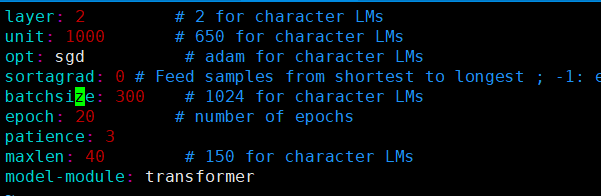
transformer结果:
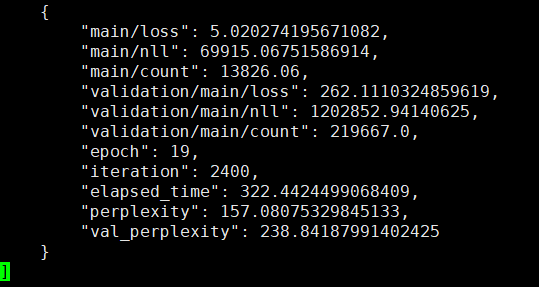
实验结论: transformer语言模型的loss确实比lstm要小,但由于语言模型序列信息是非常重要的,transformer只能获取模糊的位置信息,因此transformer的困惑度比lstm要大!后续应该就这一方面进行改进。
espnet中的transformer和LSTM语言模型对比实验的更多相关文章
- java中多种写文件方式的效率对比实验
一.实验背景 最近在考虑一个问题:“如果快速地向文件中写入数据”,java提供了多种文件写入的方式,效率上各有异同,基本上可以分为如下三大类:字节流输出.字符流输出.内存文件映射输出.前两种又可以分为 ...
- 011_Python中单线程、多线程和多进程的效率对比实验
Python是运行在解释器中的语言,查找资料知道,python中有一个全局锁(GIL),在使用多进程(Thread)的情况下,不能发挥多核的优势.而使用多进程(Multiprocess),则可以发挥多 ...
- 寻找丢失的微服务-HAProxy热加载问题的发现与分析 原创: 单既喜 一点大数据技术团队 4月8日 在一点资讯的容器计算平台中,我们通过HAProxy进行Marathon服务发现。本文记录HAProxy服务热加载后某微服务50%概率失效的问题。设计3组对比实验,验证了陈旧配置的HAProxy在Reload时没有退出进而导致微服务丢失,并给出了解决方案. Keywords:HAProxy热加
寻找丢失的微服务-HAProxy热加载问题的发现与分析 原创: 单既喜 一点大数据技术团队 4月8日 在一点资讯的容器计算平台中,我们通过HAProxy进行Marathon服务发现.本文记录HAPro ...
- 预训练中Word2vec,ELMO,GPT与BERT对比
预训练 先在某个任务(训练集A或者B)进行预先训练,即先在这个任务(训练集A或者B)学习网络参数,然后存起来以备后用.当我们在面临第三个任务时,网络可以采取相同的结构,在较浅的几层,网络参数可以直接加 ...
- string中Insert与Format效率对比、String与List中Contains与IndexOf的效率对比
关于string的效率,众所周知的恐怕是“+”和StringBuilder了,这些本文就不在赘述了.关于本文,请先回答以下问题(假设都是基于多次循环反复调用的情况下):1.使用Insert与Forma ...
- JAVA面试中问及HIBERNATE与 MYBATIS的对比,在这里做一下总结
我是一名java开发人员,hibernate以及mybatis都有过学习,在java面试中也被提及问道过,在项目实践中也应用过,现在对hibernate和mybatis做一下对比,便于大家更好的理解和 ...
- 并发编程中.net与java的一些对比
Java在并发编程中进行使用java.util.concurrent.atomic来处理一些轻量级变量 如AtomicInteger AtomicBoolean等 .Net中则使用Interlocke ...
- JAVA面试中问及HIBERNATE与 MYBATIS的对比,在这里做一下总结(转)
hibernate以及mybatis都有过学习,在java面试中也被提及问道过,在项目实践中也应用过,现在对hibernate和mybatis做一下对比,便于大家更好的理解和学习,使自己在做项目中更加 ...
- 学习笔记TF035:实现基于LSTM语言模型
神经结构进步.GPU深度学习训练效率突破.RNN,时间序列数据有效,每个神经元通过内部组件保存输入信息. 卷积神经网络,图像分类,无法对视频每帧图像发生事情关联分析,无法利用前帧图像信息.RNN最大特 ...
随机推荐
- Spring Boot自动配置SpringMVC(二)
Spring Boot自动配置SpringMVC(一) - 池塘里洗澡的鸭子 - 博客园 (cnblogs.com)讲述了关于DispatcherServlet注册到诸如tomcat容器中的自动配置过 ...
- 终极指南:企业级云原生 PaaS 平台日志分析架构全面解析
早些时候 Erda Show 针对微服务监控.日志等内容做了专场分享,很多同学听完后意犹未尽,想了解更多关于日志分析的内容.Erda 团队做日志分析也有一段时间了,所以这次打算和大家详细分享一下我们在 ...
- Oracle的常用命令和表空间
删除用户和表空间 ## 删除用户 drop user userName cascade; ## 如果用户无法删除,并报错: ## ERROR at line 1: ## ORA-01940: cann ...
- scrapy爬取《坏蛋是怎样练成的4》
scrapy具体介绍就不用说了,自己百度一下.或者参考以下文档 https://blog.csdn.net/u011054333/article/details/70165401 直接在cmd里运行 ...
- [Golang]Go语言入门笔记
跟着尚硅谷B站视频记的笔记 入门 go 编译和运行源代码 go build 编译源代码,生成可执行文件 go build -o newName.exe name.go go run 直接编译运行代码 ...
- 运维人员常用的Linux命令总结
转至:https://www.cnblogs.com/CHLL55/p/13698946.html 目录结构 目录 说明 /bin 存放可执行文件 /boot 核心与启动相关文件 /dev 设备有关的 ...
- PromQL全解析
PromQL(Prometheus Query Language)为Prometheus tsdb的查询语言.是结合grafana进行数据展示和告警规则的配置的关键部分. 本文默认您已了解Promet ...
- 01-RocketMQ介绍
一.MQ介绍 1.什么是MQ?为什么要用MQ? MQ:MessageQueue,消息队列. 队列,是一种FIFO 先进先出的数据结构.消息由生产者发送到MQ进行排队,然后按原来的顺序交由消息的消费者进 ...
- 【战略】以色列公司的数据驱动tip
Eric Rapps:我们的团队获得了大量的收入,并且持续保持着增长.如果获得我们的投资,实际上是你是获得了和相关领域技术积累.专家沟通的支持.但更重要的是,你可以近距离地接触我们的运营资源,您可以直 ...
- composer.json和composer.lock到底是什么以及区别?
composer方文档:https://docs.phpcomposer.com/04-schema.html我们在做项目的时候,总是要安装一些依赖.composer给我们提供了很多方便.直接运行co ...