Python数据清洗基本流程
# -*- coding: utf-8 -*-
"""
Created on Wed Jul 4 18:40:55 2018
@author: zhen
"""
import pandas as pd
import numpy as np
# 创建空的df,保存测试数据
test_df = pd.DataFrame({'K1':['C1','C1','C2','C3','C4','C2','C1'],'K2':['A','A','B','C','D',np.NaN,np.NaN]})
# 按K1列进行分组,组内进行unique操作(去除重复元素,返回元组或列表)
test_df_unique = pd.DataFrame(test_df.groupby(['K1'])['K2'].agg('unique'))
# 自定义函数判断元组中是否含有nan
def has_nan(list):
flag = False
for x in list:
if x is np.NaN:
flag = True
break
return flag
# 自定义函数判断元组中是否不含有nan
def no_nan(list):
flag = True
for x in list:
if x is np.NaN:
flag = False
break
return flag
# 获取k2列含有nan的数据
test_df_unique_has_nan = test_df_unique[test_df_unique['K2'].apply(has_nan)]
# 获取k2列不含有nan的数据
test_df_unique_no_nan = test_df_unique[test_df_unique['K2'].apply(no_nan)]
# 管理测试数据,获取源数据
test_df_get = test_df[test_df['K1'].isin(test_df_unique_has_nan.index.tolist())]
test_df_alone = test_df[test_df['K1'].isin(test_df_unique_no_nan.index.tolist())]
# 去除含nan的重复数据
test_df_get_nonan = test_df_get[~test_df_get['K2'].isna()]
# 组合数据
result = test_df_get_nonan.append(test_df_alone)
# 去重,得到最终结果
result_save = result.drop_duplicates(subset=['K1','K2'],keep='last')
# 结果落地
result_save.to_excel('C:/Users/zhen/Desktop/数据清洗之去重.xlsx')
测试数据:
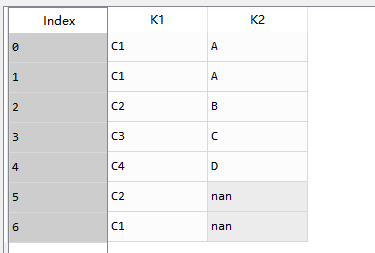
结果:

Python数据清洗基本流程的更多相关文章
- 数据挖掘:python数据清洗cvs里面带中文字符
数据清洗,使用python数据清洗cvs里面带中文字符,意图是用字典对应中文字符,即key值是中文字符,value值是index,自增即可:利用字典数据结构没有重复key值的特性,把中文字符映射到了数 ...
- Python 入门之流程控制语句
Python 入门之流程控制语句 1.if判断 (1) 单 if if –-如果 if 条件: 缩进 结果 (官方推荐4个空格,或者一个tab 不能空格和tab混合使用) money = 10 pri ...
- Python程序运行流程与垃圾回收机制
Python程序运行流程 Python解释器首先将程序将py文件编译成一个字节码对象PyCodeObject(只存在于内存中).(当这个模块的 Python 代码执行完后,就会将编译结果保存到了pyc ...
- Python基础之:Python中的流程控制
目录 简介 while语句 if 语句 for语句 Break Continue pass 简介 流程控制无非就是if else之类的控制语句,今天我们来看一下Python中的流程控制会有什么不太一样 ...
- python中的流程控制
目录 引言 流程控制的分类 分支结构 单if结构 if与else结构 if与elif与else结构 if分支的嵌套 循环结构 while循环 while + break循环 while + conti ...
- Python程序的流程
1 """ 2 python程序的流程 3 """ 4 # ------------- 分支结构---------------- 5 # i ...
- pip:带你认识一个 Python 开发工作流程中的重要工具
摘要:许多Python项目使用pip包管理器来管理它们的依赖项.它包含在Python安装程序中,是Python中依赖项管理的重要工具. 本文分享自华为云社区<使用Python的pip管理项目的依 ...
- python 数据清洗
前言 1. 删除重复 2. 异常值监测 3. 替换 4. 数据映射 5. 数值变量类型化 6. 创建哑变量 统计师的Python日记[第7天:数据清洗(1)] 前言 根据我的Python学习计划: N ...
- Python学习(七) 流程控制if语句
在Python中流程控制if语句采用如下格式: if expression : statement elif expression : statement elif expression : stat ...
随机推荐
- python(31)——【sys模块】【json模块 & pickle模块】
一.sys模块 import sys sys.argv #命令行参数List,第一个元素是程序本身路径 sys.exit() #退出程序,正常退出时exit(0) sys.version #获取pyt ...
- MapReduce对交易日志进行排序的Demo(MR的二次排序)
1.日志源文件 (各个列分别是: 账户,营业额,花费,日期) zhangsan@163.com 6000 0 2014-02-20 lisi@163.com 2000 0 2014-02-20 lis ...
- 关于vue项目中,手动定义的scrollTop的值
在项目中,有时需要控制scrollTop的值,比如有一个列表页,点击任意一个列表可以进入其详情页,这时如果你要返回的话, 肯定是希望还回到刚刚点击的地方,我当时的解决办法是,本地存下点击那一刻的scr ...
- kafka+elk
安装elasticsearch 下载:http://www.elastic.co/downloads/elasticsearch 下载后解压 修改配置文件,xxx是自定义目录 vi elasticse ...
- Netty自带连接池的使用
一.类介绍1.ChannelPool——连接池接口 2.SimpleChannelPool——实现ChannelPool接口,简单的连接池实现 3.FixedChannelPool——继承Simple ...
- Jquery 跨域访问 Lightswitch OData Service
修改lightswitch .server project web.config.添加如下内容就可以实现对ApplicationData.svc/跨域访问 <system.webServer&g ...
- Java设计模式学习记录-解释器模式
前言 这次介绍另一个行为模式,解释器模式,都说解释器模式用的少,其实只是我们在日常的开发中用的少,但是一些开源框架中还是能见到它的影子,例如:spring的spEL表达式在解析时就用到了解释器模式,以 ...
- [Luogu4986] 逃离
Description 给定次数为 \(n\) 的函数 \(A(x),B(x),C(x)\),求 \(A^2(x)+B^2(x)-C^2(x)\) 在 \([L,R]\) 的零点.\(n\leq 10 ...
- mysql 主从模式总结(一)
1. 主从模式的部署步骤 目标:部署一个有3台主机的单主模式的MySQL分组. Primary:192.168.197.110. Secondary:192.168.197.111. Secondar ...
- 【Java并发编程】22、Exchanger源码解析(JDK1.7)
Exchanger是双向的数据传输,2个线程在一个同步点,交换数据.先到的线程会等待第二个线程执行exchangeSynchronousQueue,是2个线程之间单向的数据传输,一个put,一个tak ...