如何做出一个更好的Machine Learning预测模型【转载】
链接:https://zhuanlan.zhihu.com/p/25013834
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
初衷
这篇文章主要从工程角度来总结在实际运用机器学习进行预测时,我们可以用哪些tips来提高最终的预测效果,主要分为Data Cleaning,Features Engineering, Models Training三个部分,可以帮助大家在实际的工作中取得更好的预测效果或是在kaggle的比赛里取得更好的成绩和排位。
Data Cleaning
1. 移除多余的duplicate features(相同或极为相似的features)
2. 移除constant features(只有一个value的feature)
#R里面可以使用unique()函数判断,如果返回值为1,则意味着为constant features
3. 移除方差过小的features(方差过小意味着提供信息很有限)
#R中可以使用caret包里的nearZeroVar()函数
#Python里可以使用sklearn包里的VarianceThreshold()函数
4. 缺失值处理:将missing value重新编为一类。
#比如原本-1代表negative,1代表positive,那么missing value就可以全部标记为0
#对于多分类的features做法也类似二分类的做法
#对于numeric values,可以用很大或很小的值代表missing value比如-99999.
5. 填补缺失值
可以用mean,median或者most frequent value进行填补
#R用Hmisc包中的impute()函数
#Python用sklearn中的Imputer()函数
6. 高级的缺失值填补方法
利用其他column的features来填补这个column的缺失值(比如做回归)
#R里面可以用mice包,有很多方法可供选择
注意:不是任何时候填补缺失值都会对最后的模型预测效果带来正的效果,必须进行一定的检验。
Features Engineering
1. Data Transformation
a. Scaling and Standardization
#标准化,R用scale(), Python用StandardScaler()
#注意:Tree based模型无需做标准化
b. Responses Transformation
#当responses展现skewed distribution时候用,使得residual接近normal distribution
#可以用log(x),log(x+1),sqrt(x)等
2. Features Encoding
#把categorical features变成numeric feature
#Label encoding:Python 用 LabelEncoder()和OneHotEncoder(), R用dummyVars()
3. Features Extraction
#主要是针对文本分析
4. Features Selection
a. 方法很多:
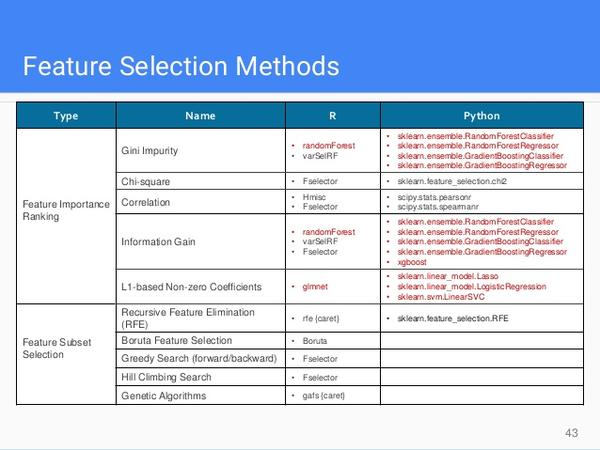 注:其中randomForest以及xgboost里的方法可以判断features的Importance
注:其中randomForest以及xgboost里的方法可以判断features的Importance
b. 此外,PCA等方法可以生成指定数量的新features(映射)
c. 擅对features进行visualization或correlation的分析。

Models Trainning
1. Mostly Used ML Models
尝试多一些的模型,比如下面这些:

2. 利用Grid Search进行hyper参数的选择
3. 利用Cross-Validation衡量训练效果
4. Ensemble Learning Methods
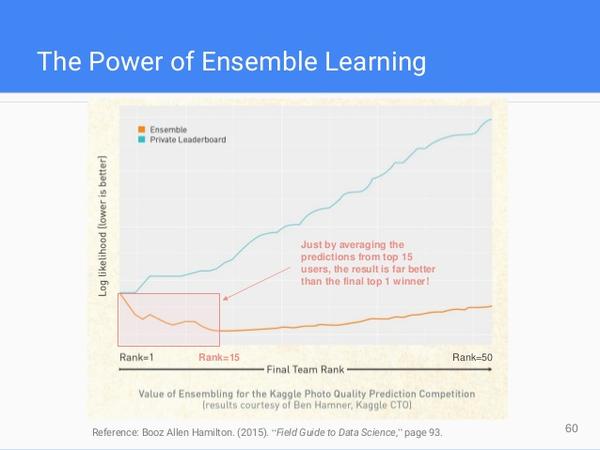
必读下面这个文档:Kaggle Ensembling Guide
文章原地址:https://zhuanlan.zhihu.com/p/25013834
如何做出一个更好的Machine Learning预测模型【转载】的更多相关文章
- Domain adaptation:连接机器学习(Machine Learning)与迁移学习(Transfer Learning)
domain adaptation(域适配)是一个连接机器学习(machine learning)与迁移学习(transfer learning)的新领域.这一问题的提出在于从原始问题(对应一个 so ...
- 【机器学习Machine Learning】资料大全
昨天总结了深度学习的资料,今天把机器学习的资料也总结一下(友情提示:有些网站需要"科学上网"^_^) 推荐几本好书: 1.Pattern Recognition and Machi ...
- Machine Learning Algorithms Study Notes(2)--Supervised Learning
Machine Learning Algorithms Study Notes 高雪松 @雪松Cedro Microsoft MVP 本系列文章是Andrew Ng 在斯坦福的机器学习课程 CS 22 ...
- Stanford机器学习笔记-7. Machine Learning System Design
7 Machine Learning System Design Content 7 Machine Learning System Design 7.1 Prioritizing What to W ...
- Machine Learning - 第7周(Support Vector Machines)
SVMs are considered by many to be the most powerful 'black box' learning algorithm, and by posing构建 ...
- Machine Learning - 第6周(Advice for Applying Machine Learning、Machine Learning System Design)
In Week 6, you will be learning about systematically improving your learning algorithm. The videos f ...
- Machine Learning - 第3周(Logistic Regression、Regularization)
Logistic regression is a method for classifying data into discrete outcomes. For example, we might u ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料【转】
转自:机器学习(Machine Learning)&深度学习(Deep Learning)资料 <Brief History of Machine Learning> 介绍:这是一 ...
- Coursera《machine learning》--(8)神经网络表述
本笔记为Coursera在线课程<Machine Learning>中的神经网络章节的笔记. 八.神经网络:表述(Neural Networks: Representation) 本节主要 ...
随机推荐
- Zookeeper的Watcher 机制的实现原理
基于 Java API 初探 zookeeper 的使用: 先来简单看一下API的使用: public class ConnectionDemo { public static void main(S ...
- python网络爬虫笔记(四)
一.python中的高阶函数算法 1.sorted()函数的排序 sorted()函数是一个高阶函数,还可以接受一个key函数来实现自定义的函数排序,key指定的函数作用于每个序列元素上,并根据k ...
- cf1121d 尺取
尺取,写起来有点麻烦 枚举左端点,然后找到右端点,,使得区间[l,r]里各种颜色花朵的数量满足b数组中各种花朵的数量,然后再judge区间[l,r]截取出后能否可以供剩下的n-1个人做花环 /* 给定 ...
- 浏览器URL中 encodeURIComponent()加密和decodeURIComponent()解码
encodeURIComponent()加密 定义和用法 encodeURIComponent() 函数可把字符串作为 URI 组件进行编码. 语法 encodeURIComponent(URIstr ...
- JS:事件循环机制、调用栈以及任务队列
点击查看原文 写在前面 js里的事件循环机制十分有趣.从很多面试题也可以看出来,考察简单的setTimeout也就是考察这个机制的. 在之前,我只是简单地认为由于函数执行很快,setTimeout执行 ...
- Python GUI界面编程
常用GUI框架 wxPython 安装wxPython pip install -U wxPython C:\Users> pip install -U wxPython Collecting ...
- python基础复习
复习-基础 一.review-base 其他语言吗和python的对比 c vs Python c语言是python的底层实现,解释器就是由python编写的. c语言开发的程序执行效率高,开发现率低 ...
- spring cloud Config--server
概述 使用Config Server,您可以在所有环境中管理应用程序的外部属性.客户端和服务器上的概念映射与Spring Environment和PropertySource抽象相同,因此它们与Spr ...
- rpm 命令使用 和 lsof -p 1406 使用
#安装RPM -v 显示详细信息 -h 显示进度 -i 安装 -U 升级 -q 查询 -ql 查看rpm 包装的文件 - qf 查看命令属于哪个RPM 包 -qi 查看RPM包的详细信息 [root@ ...
- 将txt文本转换为excel格式
将txt文本转换为excel格式,中间使用的列分割为 tab 键 一.使用xlwt模块 注:Excel 2003 一个工作表行数限制65536,列数限制256 需要模块:xlwt 模块安装:xlwt ...