【CV】CVPR2015_A Discriminative CNN Video Representation for Event Detection
A Discriminative CNN Video Representation for Event Detection
Note here: it's a learning note on the topic of video representation, based on the paper below.
Link: http://arxiv.org/pdf/1411.4006v1.pdf
Motivation:
The use of improved Dense Trajectories (IDT) has led good performance on the task of event detection, while the performance of CNN based video representation is worse than that. The author argues the following three main reasons:
- Lack of labeled video data to train good models.
- Video level event labels are too coarse to finetune a pre-trained model for adapting the event detection task.
- The use of average pooling to generate a discriminative video level representation from CNN frame level descriptors works worse than hand-crafted features like IDT.
Proposed Model:
This paper proposes a model mainly targetting at the third problem, namely how to build a cost-efficient and discrimintive video representation based on CNN.
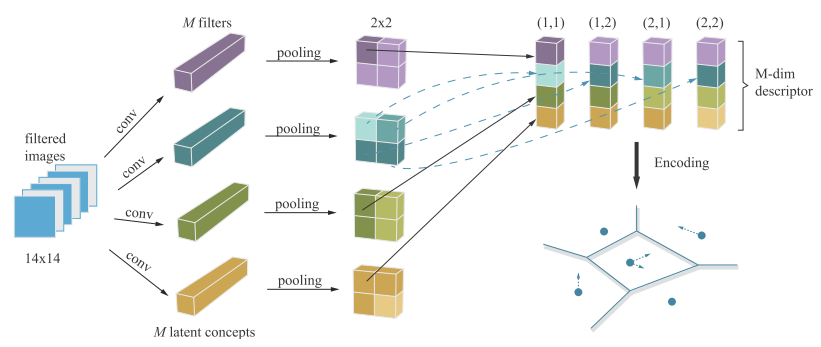
1) Firstly, we should extract frame-level descriptor:
We adopt M filters in the last convolutional layers as M latent concept classifiers. Each convolutional filter is corresponding to one latent concept, and each of it will apply on different location of the frame. So we’ll get responses of discrimintive latent concepts on different locations of the frame.
After that, we apply max-pooling operation on all concepts descriptors and concatenate different responses at the same location to form vectors each of which containing various concepts descriptions at this location.
By now, we’ve extract frame-level features.
(Actually, they didn’t do anything special at this step, they just give a new illustration of responses in CNN and rearrange those responses for further process.)
2) Secondly, we need to encode a discrimintive video-level descriptor from all these frame-level descriptors:
They introduce and compare three different encoding methods in the paper.
However, as I’m not proficient in the mathematical meanings of them, I can just give a briefly look at them instead of going further.
- Fisher Vector Encoding (refer to: http://blog.csdn.net/breeze5428/article/details/32706507 & http://www.cnblogs.com/CBDoctor/archive/2011/11/06/2236286.html)
- VLAD Encoding (simplified version of Fisher Vector Encoding)
- Average Pooling
Through experiment, they find out VLAD is better than other encoding methods. (You can refer to the paper for details about that experiment.)
"This is the first work on the video pooling of CNN descriptors and we broaden the encoding methods from local descriptors to CNN descriptors in video analysis."
(That's the takeaway in their work. They're the first to apply these encoding methods on the CNN descriptors. Previously, most of the works utilize Fisher Vector Encoding to encode a general feature of an image from local descriptors like HOG, SIFT, HOF and so on.)
3) Lastly, we get a video-level descriptor and feed it into a SVM to do detection task.
Two Tricks:
1) Spatial Pyramid Pooling: they apply four different CNN max-pooling operations to give more spatial locations for a single frame, which makes the descriptor more discrimintive. And that’s also more cost-friendly than applying spatial pyramid on raw frame.
2) Representation Compression: they do Product Quntization to compress the final representation while still maintain or even slightly improve the original performance.
【CV】CVPR2015_A Discriminative CNN Video Representation for Event Detection的更多相关文章
- 论文阅读(Weilin Huang——【TIP2016】Text-Attentional Convolutional Neural Network for Scene Text Detection)
Weilin Huang--[TIP2015]Text-Attentional Convolutional Neural Network for Scene Text Detection) 目录 作者 ...
- 【CV】ICCV2015_Unsupervised Learning of Visual Representations using Videos
Unsupervised Learning of Visual Representations using Videos Note here: it's a learning note on Prof ...
- 【PSMA】Progressive Sample Mining and Representation Learning for One-Shot Re-ID
目录 主要挑战 主要的贡献和创新点 提出的方法 总体框架与算法 Vanilla pseudo label sampling (PLS) PLS with adversarial learning Tr ...
- 【CV】ICCV2015_Learning Temporal Embeddings for Complex Video Analysis
Learning Temporal Embeddings for Complex Video Analysis Note here: it's a review note on novel work ...
- 【CV】ICCV2015_Unsupervised Visual Representation Learning by Context Prediction
Unsupervised Visual Representation Learning by Context Prediction Note here: it's a learning note on ...
- 【CV】ICCV2015_Unsupervised Learning of Spatiotemporally Coherent Metrics
Unsupervised Learning of Spatiotemporally Coherent Metrics Note here: it's a learning note on the to ...
- 【CV】ICCV2015_Describing Videos by Exploiting Temporal Structure
Describing Videos by Exploiting Temporal Structure Note here: it's a learning note on the topic of v ...
- 【ML】ICML2015_Unsupervised Learning of Video Representations using LSTMs
Unsupervised Learning of Video Representations using LSTMs Note here: it's a learning notes on new L ...
- 【实战问题】【3】iPhone无法播放video标签中的视频
问题:视频都是MP4格式,视频可以在手机上正常播放.video标签中的视频在安卓点击可以播放,但在iPhone无法播放 解决方案: 1,视频编码格式问题,具体iPhone手机支持的是哪些格式可见官方的 ...
随机推荐
- debian 7.4 安装配置
改用debian差不多有半年了,之前一直用fedora,大概3年多,虽然软件包都很新,总是不太稳定,有点软件用着用着就自动退出了. 换了debain之后,这半年还真是一直没啥问题,这里总结了一些安装配 ...
- 计算机基础-Ghost克隆
Ghost硬盘克隆 1.主要功能 (1)创建硬盘镜像备份文件 (2)将备份恢复到原硬盘上 (3)磁盘备份可以在各种不同的存储系统间进行 (4)可以将备份复制到别的硬盘上 (5)在复制过程中自动分区并格 ...
- 关于前缀和,A - Hamming Distance Sum
前缀和思想 Genos needs your help. He was asked to solve the following programming problem by Saitama: The ...
- C#泛型约束where T : class 解释
这是参数类型约束,指定T必须是Class类型. .NET支持的类型参数约束有以下五种:where T : struct | T必须是一个结构 ...
- python五十六课——正则表达式(常用函数之findall)
4).函数:findall(regex,string,[flags=0]): 参数: 和match.search一样理解 功能: 将所有匹配成功的子数据(子串),以列表的形式返回: 如果一个都没有匹配 ...
- python五十五课——calendar模块
4.calendar模块: 构造:calendar(year,[w=2,l=1,c=6]):返回year年的完整的日历信息对象 和闰年相关的函数如下: isleap(year):判断year是否是闰年 ...
- Java中关于AbstractQueuedSynchronizer的入门(二)
AQS是一个同步器的基础类,里面的关键字段: //如下关键字段都是volatile类型 /** * Head of the wait queue, lazily initialized. Except ...
- JS控制台打印佛祖加持护身符
console.log([ " _ooOoo_", " o8888888o" ...
- 编译安装nginx,并使用systemd管理nginx
#tar zxvf nginx-1.8.1.tar.gz #cd nginx-1.8.1/ #make && make install #cat /etc/systemd/system ...
- 一图尽知XMIND