json&pickle&shelve模块
之前我们学习过用eval内置方法可以将一个字符串转成python对象,不过,eval方法是有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,eval就不管用了,所以eval的重点还是通常用来执行一个字符串表达式,并返回表达式的值。
什么是序列化?
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
json
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
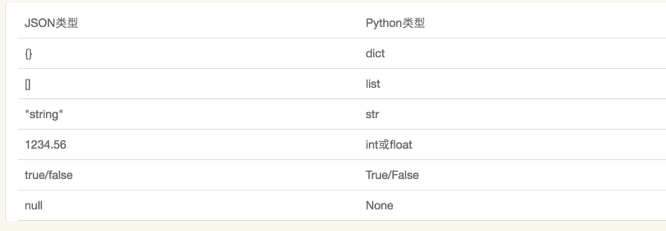
JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下:
#----------------------------序列化
import json dic={'name':'alvin','age':23,'sex':'male'}
print(type(dic))#<class 'dict'> j=json.dumps(dic)
print(type(j))#<class 'str'> f=open('序列化对象','w')
f.write(j) #-------------------等价于json.dump(dic,f)
f.close()
#-----------------------------反序列化<br>
import json
f=open('序列化对象')
data=json.loads(f.read())# 等价于data=json.load(f)
import json
#dct="{'1':111}"#json 不认单引号
#dct=str({"1":111})#报错,因为生成的数据还是单引号:{'one': 1} dct='{"1":"111"}'
print(json.loads(dct)) #conclusion:
# 无论数据是怎样创建的,只要满足json格式,就可以json.loads出来,不一定非要dumps的数据才能loads
pickle模块
##----------------------------序列化
import pickle dic={'name':'alvin','age':23,'sex':'male'} print(type(dic))#<class 'dict'> j=pickle.dumps(dic)
print(type(j))#<class 'bytes'> f=open('序列化对象_pickle','wb')#注意是w是写入str,wb是写入bytes,j是'bytes'
f.write(j) #-------------------等价于pickle.dump(dic,f) f.close()
#-------------------------反序列化
import pickle
f=open('序列化对象_pickle','rb') data=pickle.loads(f.read())# 等价于data=pickle.load(f) print(data['age'])
Pickle的问题和所有其他编程语言特有的序列化问题一样,就是它只能用于Python,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的数据,不能成功地反序列化也没关系。
shevel模块:
shelve模块比pickle模块简单,只有一个open函数,返回类似字典的对象,可读可写;key必须为字符串,而值可以是python所支持的数据类型
import shelve
f = shelve.open(r'shelve.txt')
# f['stu1_info']={'name':'alex','age':'18'}
# f['stu2_info']={'name':'alvin','age':'20'}
# f['school_info']={'website':'oldboyedu.com','city':'beijing'}
#
#
# f.close()
print(f.get('stu_info')['age'])
json&pickle&shelve模块的更多相关文章
- python序列化: json & pickle & shelve 模块
一.json & pickle & shelve 模块 json,用于字符串 和 python数据类型间进行转换pickle,用于python特有的类型 和 python的数据类型间进 ...
- python 常用模块 time random os模块 sys模块 json & pickle shelve模块 xml模块 configparser hashlib subprocess logging re正则
python 常用模块 time random os模块 sys模块 json & pickle shelve模块 xml模块 configparser hashlib subprocess ...
- day6_python序列化之 json & pickle & shelve 模块
一.json & pickle & shelve 模块 json,用于字符串 和 python数据类型间进行转换pickle,用于python特有的类型 和 python的数据类型间进 ...
- Python全栈之路----常用模块----序列化(json&pickle&shelve)模块详解
把内存数据转成字符,叫序列化:把字符转成内存数据类型,叫反序列化. Json模块 Json模块提供了四个功能:序列化:dumps.dump:反序列化:loads.load. import json d ...
- json,pickle,shelve模块,xml处理模块
常用模块学习—序列化模块详解 什么叫序列化? 序列化是指把内存里的数据类型转变成字符串,以使其能存储到硬盘或通过网络传输到远程,因为硬盘或网络传输时只能接受bytes. 为什么要序列化? 你打游戏过程 ...
- json & pickle & shelve 模块
JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下: # json序列化 import json,time user={'name':'egon' ...
- Python json & pickle & shelve模块
json & pickle 之前我们学习过用eval内置方法可以将一个字符串转成python对象,不过,eval方法是有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇 ...
- Python序列化,json&pickle&shelve模块
1. 序列化说明 序列化可将非字符串的数据类型的数据进行存档,如字典.列表甚至是函数等等 反序列化,将通过序列化保存的文件内容反序列化即可得到数据原本的样子,可直接使用 2. Python中常用的序列 ...
- Python json & pickle, shelve 模块
json 用于字符串和python的数据类型间的转换 四个功能 dumps dump loads load pickle 用于python特有的类型和python的数据类型进行转换 四个功能 dump ...
随机推荐
- 18-11-01 pandas 学习03
[python]pandas display选项 import pandas as pd 1.pd.set_option('expand_frame_repr', False) True就是可以换行显 ...
- Delphi 10.3.1 Secure File Sharing解决应用间文件共享
Delphi 10.3.1 为Android项目提供了Secure File Sharing选择项,默认是False.这一项是设置什么呢? 原来,Android 7及以后的版本,为了加强OS的安全性, ...
- 关于Idea启动配置tomcat
1.打开file中setting中搜索Application Servers,如下图 2.添加服务器类型,例如tomcat,如下图,添加完成之后可以选定tomcat的目录,tomcat Home配置t ...
- Oracle数据库死锁和MySQL死锁构造和比较
最近在复习数据库的事务隔离性,顺便构造了一下在Oracle上和MySQL上的死锁以比较异同. 在Oracle上面的实验 在Oracle中,因为是显式提交,所以默认可以认为在一个会话中若没有使用comm ...
- Git删除分支/恢复分支
• 删除一个已被终止的分支 如果需要删除的分支不是当前正在打开的分支,使用branch -d直接删除 git branch -d <branch_name> • 删除一个正打开的分支 如 ...
- Inotify机制的简单应用
编程之路刚刚开始,错误难免,希望大家能够指出. 一.Inotify机制 1.简单介绍inotify:Inotify可用于检测单个文件,也可以检测整个目录.当检测的对象是一个目录的时候,目录本身和目录里 ...
- keepalive实现MGR的自动切换(二)
10.0.0.7 lemon 10.0.0.8 lemon2 10.0.0.9 lemon3 程序代码里只需写一个VIP连接数据库即可,后面是连接在哪一台通过,keepalived的在服务端实现: ...
- Http原理与实践
Http原理 一.使用Http协议最简单的例子 1.输入URL打开网页 2.AJAX获取数据 3.img标签加载图片 二.Cache-Control 1.public.private 2.must-r ...
- 修改postgres密码
转载自:https://www.cnblogs.com/kaituorensheng/p/4735191.html 1. 修改PostgreSQL数据库默认用户postgres的密码 Postgr ...
- Aria2+百度网盘 无限制的下载神器
Aria2是一款免费开源跨平台且不限速的多线程下载软件,Aria2的优点是速度快.体积小.资源占用少:支持 HTTP / FTP / BT / Magnet 磁力链接等类型的文件下载:支持 Win.M ...