决策树算法原理(ID3,C4.5)
决策树可以作为分类算法,也可以作为回归算法,同时特别适合集成学习比如随机森林。
1. 决策树ID3算法的信息论基础
1970年昆兰找到了用信息论中的熵来度量决策树的决策选择过程,昆兰把这个算法叫做ID3。
熵度量了事物的不确定性,越不确定的事物,熵就越大。随机变量X的熵的表达式如下:
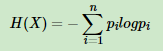
其中n代表X的n种不同的离散取值。而pi代表了X取值为i的概率,log为以2或者e为底的对数。举个例子,比如X有2个可能的取值,而这两个取值各为1/2时X的熵最大,此时X具有最大的不确定性。值为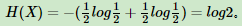 如果一个值概率大于1/2,另一个值概率小于1/2,则不确定性减少,对应的熵也会减少。比如一个概率1/3,一个概率2/3,则对应熵为
如果一个值概率大于1/2,另一个值概率小于1/2,则不确定性减少,对应的熵也会减少。比如一个概率1/3,一个概率2/3,则对应熵为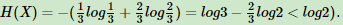
熟悉了一个变量X的熵,很容易推广到多个变量的联合熵,这里给出两个变量X和Y的联合熵表达式:
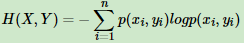
有了联合熵,又可以得到条件熵的表达式H(X|Y),条件熵类似于条件概率,它度量了我们的X在知道Y以后剩下的不确定性。表达式如下:
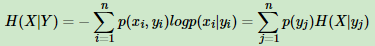
H(X)度量了X的不确定性,条件熵H(X|Y)度量了我们在知道Y以后X剩下的不确定性,H(X)-H(X|Y)度量了X在知道Y以后不确定性减少程度,这个度量我们在信息论中称为互信息,记为I(X,Y)。在决策树ID3算法中叫做信息增益。信息增益大,则越适合用来分类。
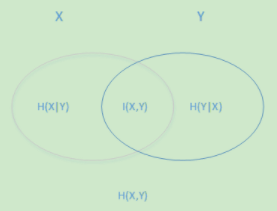
用下面这个图很容易明白他们的关系。左边的椭圆代表H(X),右边的椭圆代表H(Y),中间重合的部分就是我们的互信息或者信息增益I(X,Y), 左边的椭圆去掉重合部分就是H(X|Y),右边的椭圆去掉重合部分就是H(Y|X)。两个椭圆的并就是H(X,Y)。
2. 决策树ID3算法的思路
ID3算法思想:用信息增益最大的特征来建立决策树的当前节点。下面是一个具体例子。
15个样本D,其中9个输出为1,6个输出为0。样本中有特征A,取值为A1,A2,A3。在取值为A1的样本的输出中,有3个输出为1,2个输出为0,取值为A2的样本中,2个输出为1,3个输出为0,在取值为A3的样本中,4个输出为1,1个输出为0。
样本D的熵为: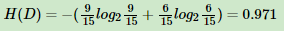
样本D在特征下的条件熵为: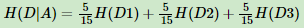
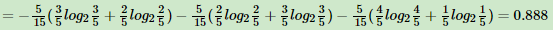
对应的信息增益为: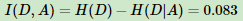
已知:输入的是m个样本,样本输出集合为D,每个样本有n个离散特征,特征集合即为A,输出为决策树T。

具体算法过程:
- 初始化信息增益的阈值ε
- 判断样本是否为同一类输出Di,如果是则返回单节点树T。标记类别为Di
- 判断特征是否为空,如果是则返回单节点树T,标记类别为样本中输出类别D实例数最多的类别
- 计算A中的各个特征(一共n个)对输出D的信息增益,选择信息增益最大的特征Ag
- 如果Ag的信息增益小于阈值ε,则返回单节点树T,标记类别为样本中输出类别D实例数最多的类别。
- 否则,按特征Ag的不同值Agi将对应的样本输出D分成不同的类别Di。每个类别产生一个子节点。对应特征值为Agi。返回增加了节点的数T。
- 对于所有子节点,令D = Di ,A = A- {Ag}递归调用2-6步,得到子树Ti并返回。
具体实例见:https://blog.csdn.net/gumpeng/article/details/51397737
3. 决策树ID3算法的不足
- ID3没考虑连续特征,比如长度,密度都是连续值,无法在ID3运用。
- ID3用信息增益作为标准容易偏向取值较多的特征。然而在相同条件下,取值比较多的特征比取值少的特征信息增益大。比如一个变量有2个值,各为1/2,另一个变量为3个值,各为1/3,其实他们都是完全不确定的变量,但是取3个值比取2个值的信息增益大。如何校正这个问题?
- ID3算法没考虑缺失值问题。
- 没考虑过拟合问题。
4. 决策树C4.5算法对ID3的改进
针对ID3算法4个主要的不足,一是不能处理连续特征,二是用信息增益作为标准容易偏向取值较多的特征,最后是缺失值处理的问题和过拟合问题。
(1)、对不能处理连续值特征,C4.5思路:将连续的特征离散化。
- 将m个连续样本从小到大排列。(比如 m 个样本的连续特征A有 m 个,从小到大排列 a1,a2,......am)
- 取相邻两样本值的平均数,会得m-1个划分点。(其中第i个划分点Ti表示为:
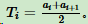 )
) - 对于这m-1个点,分别计算以该点作为二元分类点时的信息增益。选择信息增益最大的点作为该连续特征的二元离散分类点。(比如取到的增益最大的点为at,则小于at的值为类别1,大于at的值为类别2,这样就做到了连续特征的离散化。注意的是,与离散属性不同,如果当前节点为连续属性,则该属性后面还可以参与子节点的产生选择过程。)
- 用信息增益比选择最佳划分。
注意:选择连续特征的分类点采用信息增益这个指标,因为若采用增益比,影响分裂点信息度量准确性,若某分界点恰好将连续特征分成数目相等的两部分时其抑制作用最大,而选择属性的时候才使用增益比,这个指标能选择出最佳分类特征。
(2)、对于信息增益作为标准容易偏向于取值较多特征的问题。引入一个信息增益比 IR(Y, X),它是信息增益与特征熵(也称分裂信息)的比。表达式:
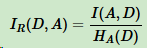
其中D为样本特征输出的集合,A为样本特征,对于特征熵 HA(D),表达式:
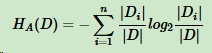
其中n为特征A的类别数,|Di|为特征A的第i个取值对应的样本个数。|D|为样本个数。
特征数越多的特征对应的特征熵越大,它作为分母,可以校正信息增益容易偏向于取值较多的特征的问题。
(3)、对于缺失值处理的问题,主要需要解决的是两个问题,一是在样本某些特征缺失的情况下选择划分的属性,二是选定了划分属性,对于在该属性上缺失特征的样本的处理。
对于第一个子问题,对于某一个有缺失特征值的特征A。C4.5的思路是将数据分成两部分,对每个样本设置一个权重(初始可以都为1),然后划分数据,一部分是有特征值A的数据D1,另一部分是没有特征A的数据D2. 然后对于没有缺失特征A的数据集D1来和对应的A特征的各个特征值一起计算加权重后的信息增益比,最后乘上一个系数,这个系数是无特征A缺失的样本加权后所占加权总样本的比例。
对于第二个子问题,可以将缺失特征的样本同时划分入所有的子节点,不过将该样本的权重按各个子节点样本的数量比例来分配。比如缺失特征A的样本a之前权重为1,特征A有3个特征值A1,A2,A3。 3个特征值对应的无缺失A特征的样本个数为2,3,4.则a同时划分入A1,A2,A3。对应权重调节为2/9,3/9, 4/9。
5. 决策树C4.5算法的不足与改进
(1)、决策树算法非常容易过拟合,因此对于生成的决策树要进行剪枝。C4.5的剪枝方法有优化的空间。思路主要是两种,一种是预剪枝,即在生成决策树的时候就决定是否剪枝。另一个是后剪枝,即先生成决策树,再通过交叉验证来剪枝。后面在下篇讲CART树的时候我们会专门讲决策树的减枝思路,主要采用的是后剪枝加上交叉验证选择最合适的决策树。
(2)、C4.5生成的是多叉树,在计算机中二叉树模型会比多叉树运算效率高。多叉树改二叉树,可以提高效率。
(3)、C4.5只能用于分类。
(4)、C4.5由于使用了熵模型,里面有大量的耗时的对数运算,如果是连续值还有大量的排序运算。如果能够加以模型简化减少运算强度但又不牺牲太多准确性的话,因此用基尼系数代替熵模型。
来自:https://www.cnblogs.com/pinard/p/6050306.html
来自:https://blog.csdn.net/zhangbaoanhadoop/article/details/79904091
来自:http://leijun00.github.io/2014/09/decision-tree/
(有例子容易理解)来自:https://blog.csdn.net/gumpeng/article/details/51397737
决策树算法原理(ID3,C4.5)的更多相关文章
- 决策树算法原理(CART分类树)
决策树算法原理(ID3,C4.5) CART回归树 决策树的剪枝 在决策树算法原理(ID3,C4.5)中,提到C4.5的不足,比如模型是用较为复杂的熵来度量,使用了相对较为复杂的多叉树,只能处理分类不 ...
- ID3决策树算法原理及C++实现(其中代码转自别人的博客)
分类是数据挖掘中十分重要的组成部分.分类作为一种无监督学习方式被广泛的使用. 之前关于"数据挖掘中十大经典算法"中,基于ID3核心思想的分类算法C4.5榜上有名.所以不难看出ID3 ...
- 机器学习回顾篇(7):决策树算法(ID3、C4.5)
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- 决策树算法原理--good blog
转载于:http://www.cnblogs.com/pinard/p/6050306.html (楼主总结的很好,就拿来主义了,不顾以后还是多像楼主学习) 决策树算法在机器学习中算是很经典的一个算法 ...
- 机器学习相关知识整理系列之一:决策树算法原理及剪枝(ID3,C4.5,CART)
决策树是一种基本的分类与回归方法.分类决策树是一种描述对实例进行分类的树形结构,决策树由结点和有向边组成.结点由两种类型,内部结点表示一个特征或属性,叶结点表示一个类. 1. 基础知识 熵 在信息学和 ...
- 决策树算法之ID3与C4.5的理解与实现
github:代码实现 本文算法均使用python3实现 1. 决策树 决策树(decision tree)是一种基本的分类与回归方法(本文主要是描述分类方法),是基于树结构进行决策的,可以将其认 ...
- 决策树算法原理及JAVA实现(ID3)
0 引言 决策树的目的在于构造一颗树像下面这样的树. 图1 图2 1. 如何构造呢? 1.1 参考资料. 本例以图2为例,并参考了以下资料. (1) http://www.cnblog ...
- 决策树算法(ID3)
Day Outlook Temperature Humidity Wind PlayTennis 1 Sunny Hot High Weak No 2 Sunny Hot High Strong No ...
- 决策树(ID3,C4.5,CART)原理以及实现
决策树 决策树是一种基本的分类和回归方法.决策树顾名思义,模型可以表示为树型结构,可以认为是if-then的集合,也可以认为是定义在特征空间与类空间上的条件概率分布. [图片上传失败...(image ...
随机推荐
- Codeforces 1043 - A/B/C/D/E/F - (Undone)
链接:http://codeforces.com/contest/1043 A - Elections - [水水水水题] 题意: 我和另一个人竞争选举,共有 $n$ 个人投票,每个人手上有 $k$ ...
- [No0000199]设计模式总结
设计模式之间的关系: 设计模式总概况: 一.设计原则 .单一职责原则 一个类,只有一个引起它变化的原因.应该只有一个职责.每一个职责都是变化的一个轴线,如果一个类有一个以上的职责,这些职责就耦合在了一 ...
- 使用Sublime Text 3进行Node.js开发
总体思路: 环境: Win7 64bit Sp1 1.官网下载node.js(我的是8.9.4LTS).注意:偶数开头的是稳定版,奇数开头的是测试版.目前我下的版本,已带npm 下载后直接下一步... ...
- Web开发——JavaScript基础(JSON教程)
参考: JSON:JavaScript 对象表示法(JavaScript Object Notation). JSON 是存储和交换文本信息的语法.类似 XML. JSON 比 XML 更小.更快,更 ...
- MAC OSX Xcode硬盘清理
1.移除对旧设备的支持影响:可重新生成:再连接旧设备调试时,会重新自动生成.我移除了4.3.2, 5.0, 5.1等版本的设备支持.路径:~/Library/Developer/Xcode/iOS D ...
- 2、LwIP协议栈规范翻译——协议层
2.协议层 TCP/IP套件中的协议是以层次的方式设计的,其中每个协议层解决了通信问题的单独部分.这种分层可以用作设计协议实现的指南,因为每个协议可以与另一个分开实现.然而,以严格分层的方式实现协议可 ...
- python练习题-员工信息表
周末大作业:实现员工信息表文件存储格式如下:id,name,age,phone,job1,Alex,22,13651054608,IT2,Egon,23,13304320533,Tearcher3,n ...
- python基础(17)-IO模型&selector模块
先说一下IO发生时涉及的对象和步骤.对于一个network IO (这里我们以read举例),它会涉及到两个系统对象,一个是调用这个IO的process (or thread),另一个就是系统内核(k ...
- 【UML】NO.52.EBook.5.UML.1.012-【UML 大战需求分析】- 交互概览图(Interaction Overview Diagram)
1.0.0 Summary Tittle:[UML]NO.52.EBook.1.UML.1.012-[UML 大战需求分析]- 交互概览图(Interaction Overview Diagram) ...
- 【LeetCode每天一题】Word Search(搜索单词)
Given a 2D board and a word, find if the word exists in the grid.The word can be constructed from le ...