【分布式搜索引擎】Elasticsearch写入和读取数据过程
一、Elasticsearch写人数据的过程
1)客户端选择一个node发送请求过去,这个node就是coordinating node(协调节点)
2)coordinating node,对document进行路由,将请求转发给对应的node(有primary shard)
3)实际的node上的primary shard处理请求,然后将数据同步到replica node
4)coordinating node,如果发现primary node和所有replica node都搞定之后,就返回响应结果给客户端
二、Elasticsearch读取数据的过程
1)客户端发送请求到任意一个node,成为coordinate node
2)coordinate node对document进行路由,将请求转发到对应的node,此时会使用round-robin随机轮询算法,在primary shard以及其所有replica中随机选择一个,让读请求负载均衡
3)接收请求的node返回document给coordinate node
4)coordinate node返回document给客户端
1.写入document时,每个document会自动分配一个全局唯一的id即doc id,同时也是根据doc id进行hash路由到对应的primary shard上。也可以手动指定doc id,比如用订单id,用户id。 2.读取document时,你可以通过doc id来查询,然后会根据doc id进行hash,判断出来当时把doc id分配到了哪个shard上面去,从那个shard去查询
三、Elasticsearch搜索数据过程
es最强大的是做全文检索
1)客户端发送请求到一个coordinate node
2)协调节点将搜索请求转发到所有的shard对应的primary shard或replica shard也可以
3)query phase:每个shard将自己的搜索结果(其实就是一些doc id),返回给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最终结果
4)fetch phase:接着由协调节点,根据doc id去各个节点上拉取实际的document数据,最终返回给客户端
搜索的底层原理:倒排索引
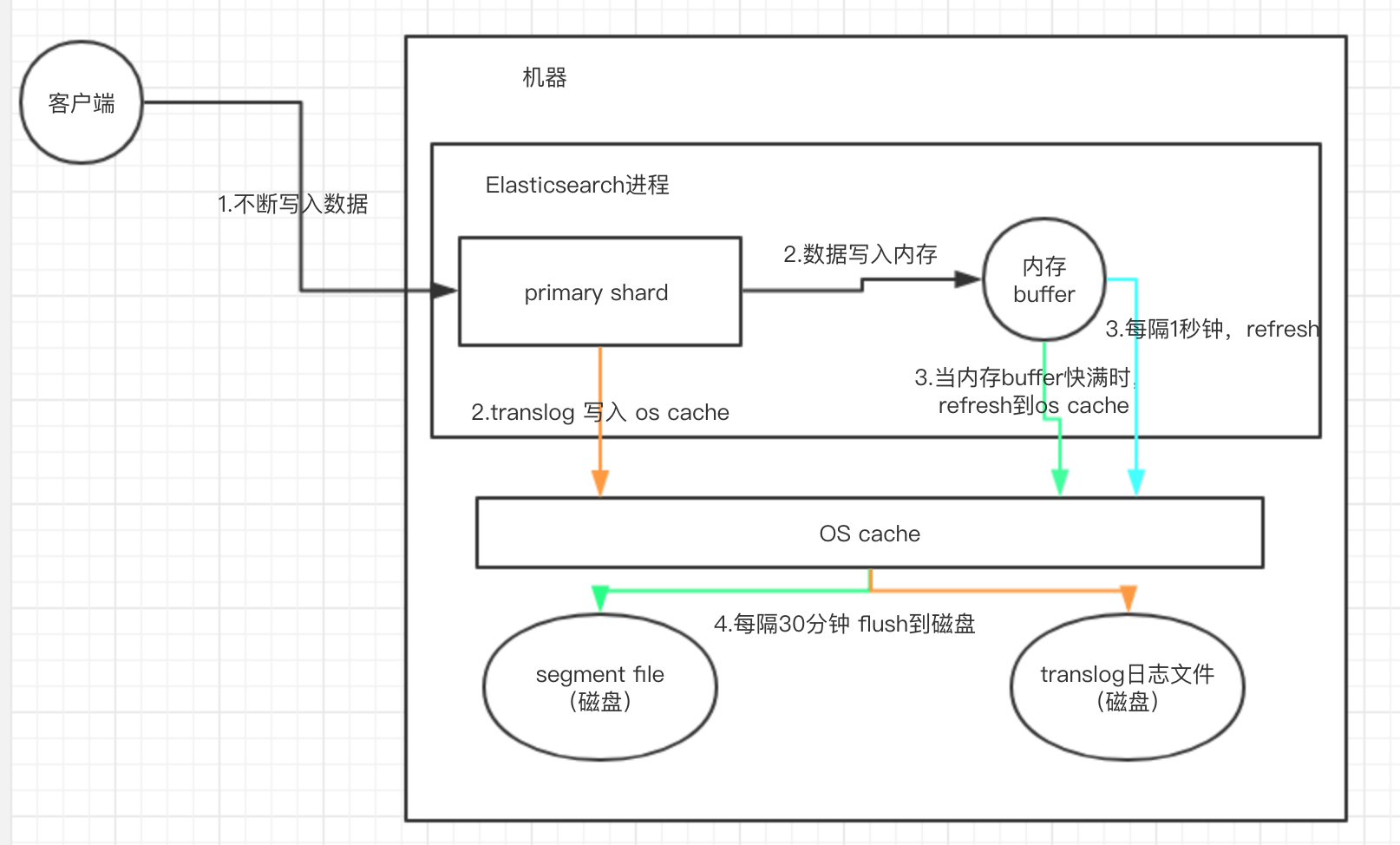
四、Elasticsearch写数据的底层原理
1)先写入buffer,在buffer里的时候数据是搜索不到的;同时将数据写入translog日志文件。
2)如果buffer快满了,或者到一定时间,就会将buffer数据refresh到一个新的segment file中,但是此时数据不是直接进入segment file的磁盘文件的,而是先进入os cache的。这个过程就是refresh。
每隔1秒钟,es将buffer中的数据写入一个新的segment file,每秒钟会产生一个新的磁盘文件,segment file,这个segment file中就存储最近1秒内buffer中写入的数据。
但是如果buffer里面此时没有数据,那当然不会执行refresh操作咯,每秒创建换一个空的segment file,如果buffer里面有数据,默认1秒钟执行一次refresh操作,刷入一个新的segment file中。
操作系统里面,磁盘文件其实都有一个东西,叫做os cache,操作系统缓存,就是说数据写入磁盘文件之前,会先进入os cache,先进入操作系统级别的一个内存缓存中去。
只要buffer中的数据被refresh操作,刷入os cache中,就代表这个数据就可以被搜索到了。
为什么叫es是准实时的?NRT,near real-time,准实时。默认是每隔1秒refresh一次的,所以es是准实时的,因为写入的数据1秒之后才能被看到。
可以通过es的restful api或者java api,手动执行一次refresh操作,就是手动将buffer中的数据刷入os cache中,让数据立马就可以被搜索到。
只要数据被输入os cache中,buffer就会被清空了,因为不需要保留buffer了,数据在translog里面已经持久化到磁盘去一份了。
【分布式搜索引擎】Elasticsearch写入和读取数据过程的更多相关文章
- Netty源码分析第5章(ByteBuf)---->第10节: SocketChannel读取数据过程
Netty源码分析第五章: ByteBuf 第十节: SocketChannel读取数据过程 我们第三章分析过客户端接入的流程, 这一小节带大家剖析客户端发送数据, Server读取数据的流程: 首先 ...
- 分布式搜索引擎Elasticsearch在CentOS7中的安装
1. 概述 随着企业业务量的不断增大,业务数据随之增加,传统的基于关系型数据库的搜索已经不能满足需要. 在关系型数据库中搜索,只能支持简单的关键字搜索,做不到分词和统计的功能,而且当单表数据量到达上百 ...
- Java笔记--java一行一行写入或读取数据
转自 Ruthless java一行一行写入或读取数据 链接:http://www.cnblogs.com/linjiqin/archive/2011/03/23/1992250.html 假如E:/ ...
- 分布式搜索引擎Elasticsearch的架构分析
一.写在前面 ES(Elasticsearch下文统一称为ES)越来越多的企业在业务场景是使用ES存储自己的非结构化数据,例如电商业务实现商品站内搜索,数据指标分析,日志分析等,ES作为传统关系型数据 ...
- 分布式搜索引擎Elasticsearch的简单使用
官方网址:https://www.elastic.co/products/elasticsearch/ 一.特性 1.支持中文分词 2.支持多种数据源的全文检索引擎 3.分布式 4.基于lucene的 ...
- 第十七章,txt文件的写入和读取数据结合练习(C++)
#include <iostream> #include <fstream> int main(int argc, char** argv) { std::string str ...
- java一行一行写入或读取数据
原文:http://www.cnblogs.com/linjiqin/archive/2011/03/23/1992250.html 假如E:/phsftp/evdokey目录下有个evdokey_2 ...
- 分布式搜索引擎Elasticsearch性能优化与配置
1.内存优化 在bin/elasticsearch.in.sh中进行配置 修改配置项为尽量大的内存: ES_MIN_MEM=8g ES_MAX_MEM=8g 两者最好改成一样的,否则容易引发长时间GC ...
- 分布式搜索引擎Elasticsearch的查询与过滤
一.写入 先来一个简单的官方例子,插入的参数为-XPUT,插入一条记录. curl -XPUT 'http://localhost:9200/test/users/1' -d '{ "use ...
随机推荐
- PHP调用接口用post方法传送json数据
1.核心代码: <?php require("helper.php"); header('content-type:text/html;charset=utf-8'); $k ...
- CentOS下rpm命令详解
CentOS下rpm命令详解 rpm,Redhat Package Manager,即为红帽公司为RHEL开发的专用包管理器,后来更改为RPM Package Manager,类似于GNU项目,使用递 ...
- mixpanel umeng talkingdata
市面上可以比较容易的接触到的实时大数据用户行为分析系统有很多,比如国外有著名的Mixpanel.Localytics.Google,国内有TalkingData.这些公司都提供基于云的大数据分析系统, ...
- wordpress调用the_excerpt()不带<p>标签
我们知道wordpress调用摘要内容用<?php the_excerpt(); ?>就可以,但是它会自动添加一个p标签,例如<p>这里是description</p&g ...
- java框架之SpringBoot(9)-数据访问及整合MyBatis
简介 对于数据访问层,无论是 SQL 还是 NOSQL,SpringBoot 默认采用整合 SpringData 的方式进行统一处理,添加了大量的自动配置,引入了各种 Template.Reposit ...
- java框架之SpringCloud(5)-Hystrix服务熔断、降级与监控
前言 分布式系统面临的问题 复杂分布式体系结构中的应用程序有数十个依赖关系,每个依赖关系在某些时候将不可避免地失败.不做任何处理的情况下,很容易导致服务雪崩. 服务雪崩:多个微服务之间调用的时候,假设 ...
- [js]js中函数传参判断
1,通过|| function fun(x,y){ x=x||0; y=y||1; alert(x+y); } fun(); 2.通过undefined对比 function fun(x,y){ if ...
- HBase 笔记1
cap理论: 一致性 可用性 可靠性 任何分布式系统只能最多满足上面2点,无法全部满足 NOSQL = Not Only SQL = 不只是SQL HBase速度并不快,知识当数据量很大时它慢 ...
- 记mysql中时间相关的一个奇怪问题
发现mysql中类型为时间的字段,在查询时显示的时间是什么是依赖于客户端的,不同的客户端查同一个时间,可能在客户端显示的时间是不一样的.至于这个在哪里配置,以及服务端如何依据这个配置为客户端返回结果, ...
- 前端学习历程--localstroge
一. localstorage的特性 1.需要ie8+ 2.浏览器中都会把localStorage的值类型限定为string类型,这个在对我们日常比较常见的JSON对象类型需要一些转换 3.local ...