【分布式搜索引擎】Elasticsearch写入和读取数据过程
一、Elasticsearch写人数据的过程
1)客户端选择一个node发送请求过去,这个node就是coordinating node(协调节点)
2)coordinating node,对document进行路由,将请求转发给对应的node(有primary shard)
3)实际的node上的primary shard处理请求,然后将数据同步到replica node
4)coordinating node,如果发现primary node和所有replica node都搞定之后,就返回响应结果给客户端
二、Elasticsearch读取数据的过程
1)客户端发送请求到任意一个node,成为coordinate node
2)coordinate node对document进行路由,将请求转发到对应的node,此时会使用round-robin随机轮询算法,在primary shard以及其所有replica中随机选择一个,让读请求负载均衡
3)接收请求的node返回document给coordinate node
4)coordinate node返回document给客户端
1.写入document时,每个document会自动分配一个全局唯一的id即doc id,同时也是根据doc id进行hash路由到对应的primary shard上。也可以手动指定doc id,比如用订单id,用户id。 2.读取document时,你可以通过doc id来查询,然后会根据doc id进行hash,判断出来当时把doc id分配到了哪个shard上面去,从那个shard去查询
三、Elasticsearch搜索数据过程
es最强大的是做全文检索
1)客户端发送请求到一个coordinate node
2)协调节点将搜索请求转发到所有的shard对应的primary shard或replica shard也可以
3)query phase:每个shard将自己的搜索结果(其实就是一些doc id),返回给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最终结果
4)fetch phase:接着由协调节点,根据doc id去各个节点上拉取实际的document数据,最终返回给客户端
搜索的底层原理:倒排索引
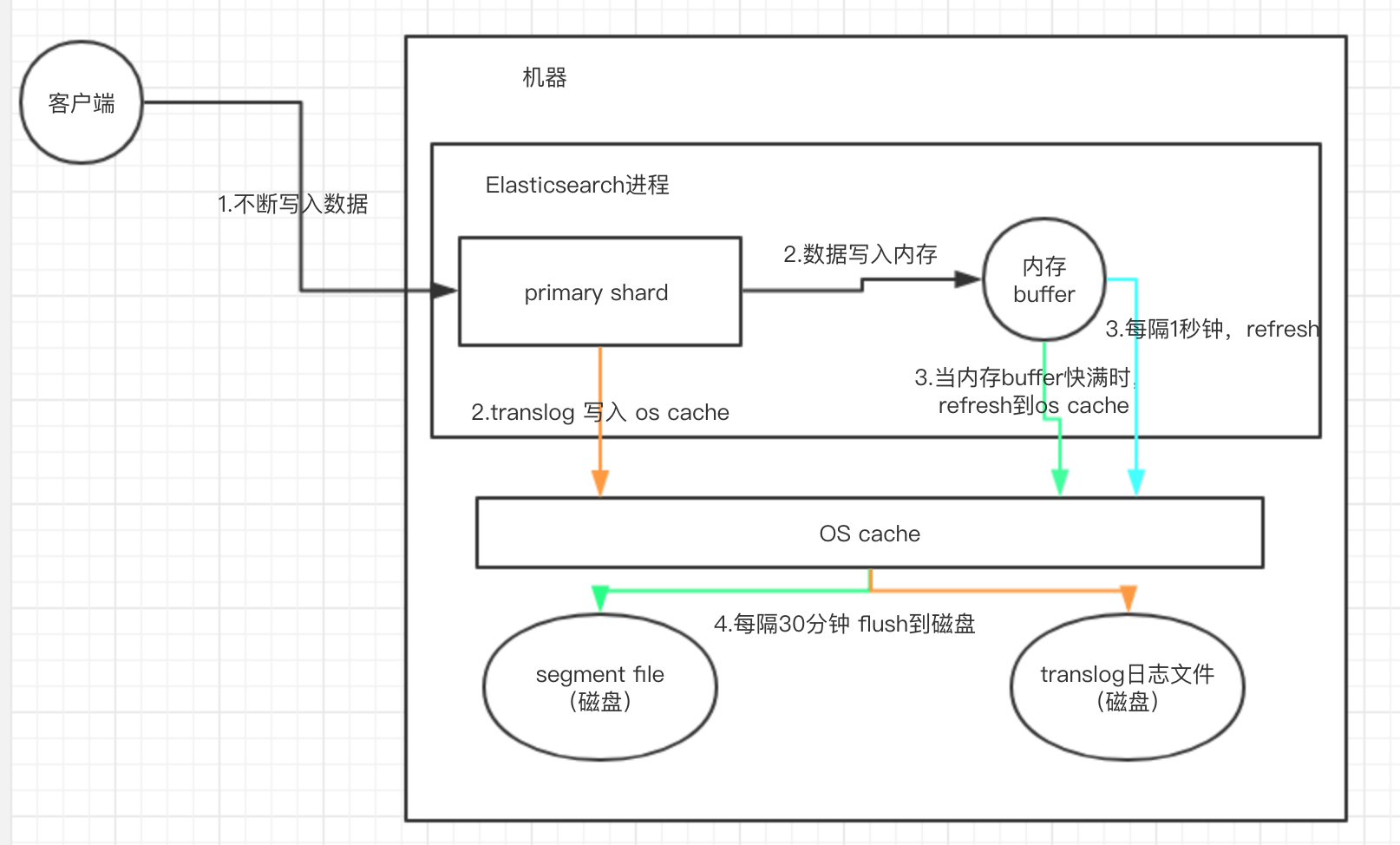
四、Elasticsearch写数据的底层原理
1)先写入buffer,在buffer里的时候数据是搜索不到的;同时将数据写入translog日志文件。
2)如果buffer快满了,或者到一定时间,就会将buffer数据refresh到一个新的segment file中,但是此时数据不是直接进入segment file的磁盘文件的,而是先进入os cache的。这个过程就是refresh。
每隔1秒钟,es将buffer中的数据写入一个新的segment file,每秒钟会产生一个新的磁盘文件,segment file,这个segment file中就存储最近1秒内buffer中写入的数据。
但是如果buffer里面此时没有数据,那当然不会执行refresh操作咯,每秒创建换一个空的segment file,如果buffer里面有数据,默认1秒钟执行一次refresh操作,刷入一个新的segment file中。
操作系统里面,磁盘文件其实都有一个东西,叫做os cache,操作系统缓存,就是说数据写入磁盘文件之前,会先进入os cache,先进入操作系统级别的一个内存缓存中去。
只要buffer中的数据被refresh操作,刷入os cache中,就代表这个数据就可以被搜索到了。
为什么叫es是准实时的?NRT,near real-time,准实时。默认是每隔1秒refresh一次的,所以es是准实时的,因为写入的数据1秒之后才能被看到。
可以通过es的restful api或者java api,手动执行一次refresh操作,就是手动将buffer中的数据刷入os cache中,让数据立马就可以被搜索到。
只要数据被输入os cache中,buffer就会被清空了,因为不需要保留buffer了,数据在translog里面已经持久化到磁盘去一份了。
【分布式搜索引擎】Elasticsearch写入和读取数据过程的更多相关文章
- Netty源码分析第5章(ByteBuf)---->第10节: SocketChannel读取数据过程
Netty源码分析第五章: ByteBuf 第十节: SocketChannel读取数据过程 我们第三章分析过客户端接入的流程, 这一小节带大家剖析客户端发送数据, Server读取数据的流程: 首先 ...
- 分布式搜索引擎Elasticsearch在CentOS7中的安装
1. 概述 随着企业业务量的不断增大,业务数据随之增加,传统的基于关系型数据库的搜索已经不能满足需要. 在关系型数据库中搜索,只能支持简单的关键字搜索,做不到分词和统计的功能,而且当单表数据量到达上百 ...
- Java笔记--java一行一行写入或读取数据
转自 Ruthless java一行一行写入或读取数据 链接:http://www.cnblogs.com/linjiqin/archive/2011/03/23/1992250.html 假如E:/ ...
- 分布式搜索引擎Elasticsearch的架构分析
一.写在前面 ES(Elasticsearch下文统一称为ES)越来越多的企业在业务场景是使用ES存储自己的非结构化数据,例如电商业务实现商品站内搜索,数据指标分析,日志分析等,ES作为传统关系型数据 ...
- 分布式搜索引擎Elasticsearch的简单使用
官方网址:https://www.elastic.co/products/elasticsearch/ 一.特性 1.支持中文分词 2.支持多种数据源的全文检索引擎 3.分布式 4.基于lucene的 ...
- 第十七章,txt文件的写入和读取数据结合练习(C++)
#include <iostream> #include <fstream> int main(int argc, char** argv) { std::string str ...
- java一行一行写入或读取数据
原文:http://www.cnblogs.com/linjiqin/archive/2011/03/23/1992250.html 假如E:/phsftp/evdokey目录下有个evdokey_2 ...
- 分布式搜索引擎Elasticsearch性能优化与配置
1.内存优化 在bin/elasticsearch.in.sh中进行配置 修改配置项为尽量大的内存: ES_MIN_MEM=8g ES_MAX_MEM=8g 两者最好改成一样的,否则容易引发长时间GC ...
- 分布式搜索引擎Elasticsearch的查询与过滤
一.写入 先来一个简单的官方例子,插入的参数为-XPUT,插入一条记录. curl -XPUT 'http://localhost:9200/test/users/1' -d '{ "use ...
随机推荐
- javaweb(3)之JSP&EL&JSTL
JSP(Java Server Page) 介绍 什么是 JSP ? 从用户角度看,JSP 就是一个网页. 从开发者角度看,它其实就是一个继承了 Servlet 的 java 类,所以可以直接说 JS ...
- 第一章 JQuery概述
1.JQuery的作用:访问和操作DOM元素控制页面样式对页面事件进行处理扩展新的JQuery插件与Ajax技术完美结合注:JQuery能完成的效果js都能完成,但是JQuery的开发效率更高,代码更 ...
- ATM目录结构
作者:高江平版本:1.0程序介绍: 实现ATM常用功能程序结构:atm实现|——README|——atm #ATM主程序目录| |——bin #ATM执行文件目录| | |——__init__.py| ...
- java解答:有17个人围成一圈(编号0~16),从第0号的人开始从1报数,凡报到3的倍数的人离开圈子,然后再数下去,直到最后只剩下一个人为止,问此人原来的位置是多少号?
package ttt; import java.util.HashMap; import java.util.Map.Entry; /** * 有17个人围成一圈(编号0~16),从第0号的人开始从 ...
- Vue系列之 => 命名视图实现经典布局
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <meta name ...
- Nginx 多域名配置
nginx绑定多个域名可又把多个域名规则写一个配置文件里,也可又分别建立多个域名配置文件,我一般为了管理方便,每个域名建一个文件,有些同类域名也可又写在一个总的配置文件里.一.每个域名一个文件的写法 ...
- Java代码质量改进之:同步对象的选择
在Java中,让线程同步的一种方式是使用synchronized关键字,它可以被用来修饰一段代码块,如下: synchronized(被锁的同步对象) { // 代码块:业务代码 } 当synchro ...
- 第二篇——Struts2的Action搜索顺序
Struts2的Action的搜索顺序: 地址:http://localhost:8080/path1/path2/student.action 1.判断package是否存在,例如:/pat ...
- MTCNN试用
检测工作想借用MTCNN里的48-net,源码来自CongWeilin Git 下下来就能跑,真是良心 进入pepare_data准备好数据以后进入48-net,目录下有一个pythonLayer.p ...
- jmeter对自身性能的优化
测试环境 apache-jmeter-2.13 1. 问题描述 单台机器的下JMeter启动较大线程数时可能会出现运行报错的情况,或者在运行一段时间后,JMeter每秒生成的请求数会逐步下降, ...