mongoDB实现MapReduce
一、MongoDB Map Reduce
Map-Reduce是一种计算模型,简单的说就是将大批量的工作(数据)分解(MAP)执行,然后再将结果合并成最终结果(REDUCE)。MongoDB提供的Map-Reduce非常灵活,对于大规模数据分析也相当实用。
基本语法:
db.collection.mapReduce(
function() {emit(key,value);}, //map 函数
function(key,values) {return reduceFunction}, //reduce 函数
{
out: collection,
query: document,
sort: document,
limit: number
}
)
使用 MapReduce 要实现两个函数 Map 函数和 Reduce 函数,Map 函数调用 emit(key, value), 遍历 collection 中所有的记录, 将 key 与 value 传递给 Reduce 函数进行处理。
Map 函数必须调用 emit(key, value) 返回键值对。
参数说明:
- map :映射函数 (生成键值对序列,作为 reduce 函数参数)。
- reduce 统计函数,reduce函数的任务就是将key-values变成key-value,也就是把values数组变成一个单一的值value。。
- out 统计结果存放集合 (不指定则使用临时集合,在客户端断开后自动删除)。
- query 一个筛选条件,只有满足条件的文档才会调用map函数。(query。limit,sort可以随意组合)
- sort 和limit结合的sort排序参数(也是在发往map函数前给文档排序),可以优化分组机制
- limit 发往map函数的文档数量的上限(要是没有limit,单独使用sort的用处不大)
二、示例
我们通过下面的一个例子来理解上面的概念
mongodb的student集合中存在以下数据:
/* 1 */
{
"_id" : ObjectId("5c735e26b21aeac107319873"),
"stu_name" : "张三",
"course" : "英语",
"score" : 70,
"level" : "C"
} /* 2 */
{
"_id" : ObjectId("5c735e26b21aeac107319874"),
"stu_name" : "张三",
"course" : "数学",
"score" : 95,
"level" : "A"
} /* 3 */
{
"_id" : ObjectId("5c735e26b21aeac107319875"),
"stu_name" : "张三",
"course" : "语文",
"score" : 91,
"level" : "A"
} /* 4 */
{
"_id" : ObjectId("5c735e26b21aeac107319876"),
"stu_name" : "张三",
"course" : "历史",
"score" : 98,
"level" : "A"
} /* 5 */
{
"_id" : ObjectId("5c735e26b21aeac107319877"),
"stu_name" : "李四",
"course" : "数学",
"score" : 88,
"level" : "B"
} /* 6 */
{
"_id" : ObjectId("5c735e26b21aeac107319878"),
"stu_name" : "李四",
"course" : "英语",
"score" : 93,
"level" : "A"
} /* 7 */
{
"_id" : ObjectId("5c735e26b21aeac107319879"),
"stu_name" : "李四",
"course" : "语文",
"score" : 99,
"level" : "A"
}
要求:统计出每个学生的level为A的成绩的总和,并按学生名字进行分组显示
其执行的逻辑过程如下图所示:

在mongo shell里面执行:
db.student.mapReduce(
function() { emit(this.stu_name,this.score); },
function(key, values) {return Array.sum(values)},
{
query:{level:"A"},
out:"total_score"
}
)
/* 1 */
{
"result" : "total_score",
"timeMillis" : 171.0,
"counts" : {
"input" : 5,
"emit" : 5,
"reduce" : 2,
"output" : 2
},
"ok" : 1.0
}
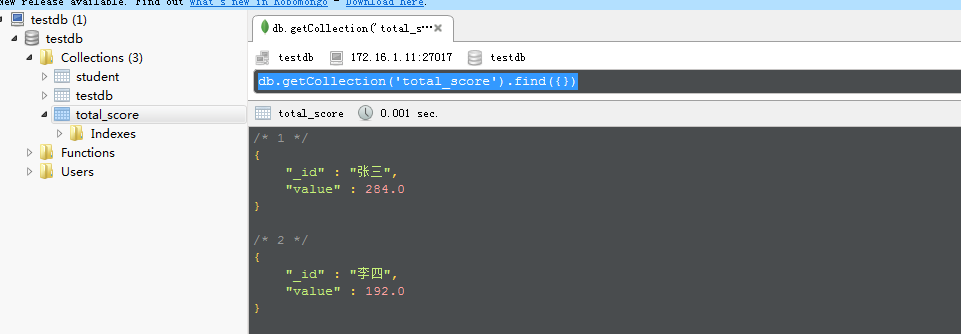
结果表明,共有 5 个符合查询条件("level":"A")的student, 在map函数中生成了 5 个键值对文档,最后使用reduce函数将相同的键值分为 2 组。
具体参数说明:
- result:储存结果的collection的名字,这是个临时集合,MapReduce的连接关闭后自动就被删除了。
- timeMillis:执行花费的时间,毫秒为单位
- input:满足条件被发送到map函数的文档个数
- emit:在map函数中emit被调用的次数,也就是所有集合中的数据总量
- ouput:结果集合中的文档个数(count对调试非常有帮助)
- ok:是否成功,成功为1
- err:如果失败,这里可以有失败原因,不过从经验上来看,原因比较模糊,作用不大
查看真正的统计结果:
三、用spring-boot-starter-data-mongodb来实现上面的操作
1、新建maven工程:mongo-mapreduce
引入springboot依赖和mongodb依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>com.mongo.mapreduce</groupId>
<artifactId>mongo-mapreduce</artifactId>
<version>1.0-SNAPSHOT</version>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.4.1.RELEASE</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency> <dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
<exclusions>
<exclusion>
<artifactId>spring-boot-starter-logging</artifactId>
<groupId>org.springframework.boot</groupId>
</exclusion>
</exclusions>
</dependency> </dependencies>
</project>
2、创建配置文件application.yml,map函数:map.js,reduce函数:reduce.js
server:
port:
context-path: /
spring:
data:
mongodb:
uri: mongodb://admin:admin@172.16.1.11:,172.16.1.11:/testdb?AutoConnectRetry=true
map.js
function() {
emit(this.stu_name,this.score);
}
reduce.js
function(key,values) {
var sum = 0;
for (var i = 0; i < values.length; i++)
sum += values[i];
return sum;
}
3、创建springboot启动主类
package com.mongo.mapreduce; import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication; /**
* @author Administrator
* @date 2019/02/25
*/
@SpringBootApplication
public class Application {
public static void main(String[] args){
SpringApplication.run(Application.class, args);
}
}
4、创建接收mapreduce结果的实体类
package com.mongo.mapreduce.model; /**
* @author Administrator
* @date 2019/02/25
*/
public class MapReduceResult {
private String id;
private Integer value; public String getId() {
return id;
} public void setId(String id) {
this.id = id;
} public Integer getValue() {
return value;
} public void setValue(Integer value) {
this.value = value;
}
}
5、创建controller
package com.mongo.mapreduce.controller; import com.mongo.mapreduce.model.MapReduceResult;
import com.sun.beans.decoder.ValueObject;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.mongodb.core.MongoTemplate;
import org.springframework.data.mongodb.core.mapreduce.MapReduceOptions;
import org.springframework.data.mongodb.core.mapreduce.MapReduceResults;
import org.springframework.data.mongodb.core.query.Criteria;
import org.springframework.data.mongodb.core.query.Query;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RestController; import java.util.List; /**
* @author Administrator
* @date 2019/02/25
*/
@RestController
@RequestMapping("/map-reduce")
public class TestController { @Autowired
private MongoTemplate mongoTemplate; @RequestMapping(value = "/result",method = RequestMethod.GET)
public void postTest(){
//删除_id不等于空的数据,等于删除所有数据,目的是清空上一次mapreduce的结果
Criteria criteria=new Criteria("_id");
criteria.ne("");
Query query = new Query(criteria);
mongoTemplate.remove(query,"total_score"); //执行map reduce操作
Criteria criteria1=new Criteria("level");
criteria1.is("A");
Query query1 = new Query(criteria1);
MapReduceOptions options = MapReduceOptions.options();
options.outputCollection("total_score");
options.outputTypeReduce();
MapReduceResults<MapReduceResult> reduceResults =
mongoTemplate.mapReduce(query1,"student",
"classpath:map.js",
"classpath:reduce.js",
options,
MapReduceResult.class);
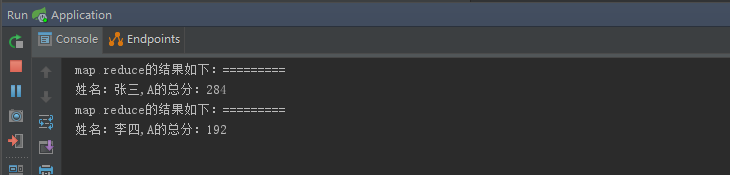
for(MapReduceResult reduceResult:reduceResults){
System.out.println("map reduce的结果如下:=========");
System.out.println("姓名:"+reduceResult.getId()+",A的总分:"+reduceResult.getValue());
}
}
}
6、用postman调用
mongoDB实现MapReduce的更多相关文章
- MongoDB 的 MapReduce 大数据统计统计挖掘
MongoDB虽然不像我们常用的mysql,sqlserver,oracle等关系型数据库有group by函数那样方便分组,但是MongoDB要实现分组也有3个办法: * Mongodb三种分组方式 ...
- MongoDb 用 mapreduce 统计留存率
MongoDb 用 mapreduce 统计留存率(金庆的专栏)留存的定义采用的是新增账号第X日:某日新增的账号中,在新增日后第X日有登录行为记为留存 输出如下:(类同友盟的留存率显示)留存用户注册时 ...
- MongoDB:Map-Reduce
Map-reduce是一个考虑大型数据得到实用聚集结果的数据处理程式(paradigm).针对map-reduce操作,MongoDB提供来mapreduce命令. 考虑以下的map-reduce操作 ...
- MongoDB中mapReduce的使用
MongoDB中mapReduce的使用 制作人:全心全意 mapReduce的功能和group by的功能类似,但比group by处理的数据量更大 使用示例: var map = function ...
- mongodb 聚合(Map-Reduce)
介绍 Map-reduce 是一种数据处理范式,用于将大量数据压缩为有用的聚合结果.对于 map-reduce 操作,MongoDB 提供MapReduce数据库命令. MongoDB中的MapRed ...
- 在MongoDB的MapReduce上踩过的坑
太久没动这里,目前人生处于一个新的开始.这次博客的内容很久前就想更新上来,但是一直没找到合适的时间点(哈哈,其实就是懒),主要内容集中在使用Mongodb时的一些隐蔽的MapReduce问题: 1.R ...
- MongoDB进行MapReduce的数据类型
有很长一段时间没更新博客了,因为最近都比较忙,今天算是有点空闲吧.本文主要是介绍MapReduce在MongoDB上的使用,它与sql的分组.聚集类似,也是先map分组,再用reduce统计,最后还可 ...
- mongoDB(3) mapReduce
mapReduce是大数据的核心内容,但实际操作中别用这个,所谓的mapReduce分两步 1.map:将数据分别取出,Map函数调用emit(key,value)遍历集合中所有的记录,将key与va ...
- MongoDB下Map-Reduce使用简单翻译及示例
目录 Map-Reduce JavaScript 函数 Map-Reduce 行为 一个简单的测试 原文地址https://docs.mongodb.com/manual/core/map-reduc ...
随机推荐
- KMS服务器激活WIN方法
KMS激活的过程简单说就是:欲激活的电脑向KMS服务器请求,KMS服务器做出回应同意激活. KMS激活软件是将KMS服务器用一段代码来模拟,做成一个可执行的程序(即所谓的KMS伺服器).KMS激活软件 ...
- Activiti流程设计工具
在Actitivi工程的src/main/resources新建一个文件夹diagrams 然后右键,创建一个activiti Diagram 取名为helloWorld后finish 中间区域,是我 ...
- java之try、catch、finally
结论:try和catch相当于程序分支,finally块中不会改变变量的指针(引用地址):和final修饰的变量类似. public class Test { public static AreaRQ ...
- js数组条件筛选——map()
在对象数组中检索属性为指定值得某个对象使用map()就非常方便. 对象数组 var studentArray = [ {"name":"小明","ge ...
- maven项目发布到tomcat的错误
Could not publish to the server. java.lang.IndexOutOfBoundsException "Updating status for Tomca ...
- maven pom.xml 项目报错
Failed to read artifact descriptor for org.springframework.boot:spring-boot-starter-web:jar:2.1.0.RE ...
- xtrabackup备份还原MySQL数据库
mysqldump 备份鉴于其自身的某些特性(锁表,本质上备份出来insert脚本或者文本,不支持差异备份),不太适合对实时性要求比较高的情况Xtrabackup可以解决mysqldump存在的上述的 ...
- Match-----Correlation-----find_ncc_model_exposure
* This example program shows how to use HALCON's correlation-based* matching. In particular it demon ...
- HttpRunnerManager安装部署
uname -a cat /etc/redhat-release 1.安装docker.mysql.rabbitmq sudo yum update curl -fsSL https://get.do ...
- oracle数据库名称已被一现有约束条件占用
使用oracle数据库出现名称已被一现有约束条件占用的错误,我的原因是在同一个库中有一个表使用了外键FK_SNO,自己新建的一个表中也使用了外键FK_SNO,导致出现了错误. 这时改变一下外键FK_S ...