文本分类TextCNN
参考来源:https://blog.csdn.net/u012762419/article/details/79561441
TextCNN结构
TextCNN的结构比较简单,输入数据首先通过一个embedding layer,得到输入语句的embedding表示,然后通过一个convolution layer,提取语句的特征,最后通过一个fully connected layer得到最终的输出,整个模型的结构如下图: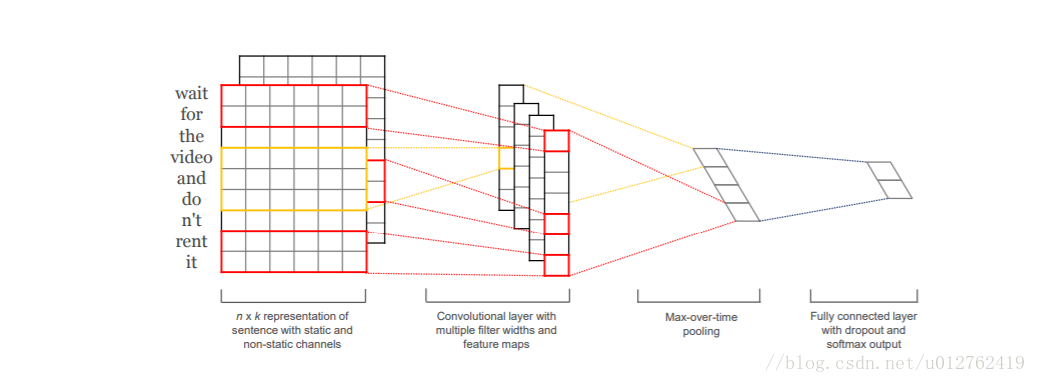
embedding layer:即嵌入层,这一层的主要作用是将输入的自然语言编码成distributed representation,具体的实现方法可以用word2vec/fasttext/glove,这里不再赘述。可以使用预训练好的词向量,也可以直接在训练textcnn的过程中训练出一套词向量,不过前者比或者快100倍不止。如果使用预训练好的词向量,又分为static方法和no-static方法,前者是指在训练textcnn过程中不再调节词向量的参数,后者在训练过程中调节词向量的参数,所以,后者的结果比前者要好。更为一般的做法是:不要在每一个batch中都调节emdbedding层,而是每个100个batch调节一次,这样可以减少训练的时间,又可以微调词向量。
convolution layer:这一层主要是通过卷积,提取不同的n-gram特征。输入的语句或者文本,通过embedding layer后,会转变成一个二维矩阵,假设文本的长度为|T|,词向量的大小为|d|,则该二维矩阵的大小为|T|x|d|,接下的卷积工作就是对这一个|T|x|d|的二维矩阵进行的。卷积核的大小一般设定为 nx|d|,
n是卷积核的长度,|d|是卷积核的宽度,这个宽度和词向量的维度是相同的,也就是卷积只是沿着文本序列进行的,n可以有多种选择,比如2、3、4、5等。对于一个|T|x|d|的文本,如果选择卷积核kernel的大小为2x|d|,则卷积后得到的结果是|T-2+1|x1的一个向量。在TextCNN网络中,需要同时使用多个不同类型的kernel,同时每个size的kernel又可以有多个。如果我们使用的kernel size大小为2、3、4、5x|d|,每个种类的size又有128个kernel,则卷积网络一共有4x128个卷积核。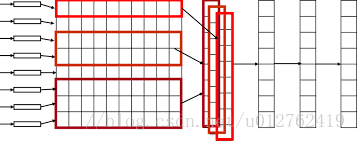
上图是从google上找到的一个不太理想的卷积示意图,我们看到红色的横框就是所谓的卷积核,红色的竖框是卷积后的结果。从图中看到卷积核的size=1、2、3, 图中上下方向是文本的序列方向,卷积核只能沿着“上下”方向移动。卷积层本质上是一个n-gram特征提取器,不同的卷积核提取的特征不同,以文本分类为例,有的卷积核可能提取到娱乐类的n-gram,比如范冰冰、电影等n-gram;有的卷积核可能提取到经济类的n-gram,比如去产能、调结构等。分类的时候,不同领域的文本包含的n-gram是不同的,激活对应的卷积核,就会被分到对应的类。
- max-pooling layer:最大池化层,对卷积后得到的若干个一维向量取最大值,然后拼接在一块,作为本层的输出值。如果卷积核的size=2,3,4,5,每个size有128个kernel,则经过卷积层后会得到4x128个一维的向量(注意这4x128个一维向量的大小不同,但是不妨碍取最大值),再经过max-pooling之后,会得到4x128个scalar值,拼接在一块,得到最终的结构—512x1的向量。max-pooling层的意义在于对卷积提取的n-gram特征,提取激活程度最大的特征。
fully-connected layer:这一层没有特别的地方,将max-pooling layer后再拼接一层,作为输出结果。实际中为了提高网络的学习能力,可以拼接多个全连接层。
在 word representation 处理上会有一些变种.
CNN-rand
设计好 embedding_size 这个 Hyperparameter 后, 对不同单词的向量作随机初始化, 后续BP的时候作调整.
static
拿 pre-trained vectors from word2vec, FastText or GloVe 直接用, 训练过程中不再调整词向量. 这也算是迁移学习的一种思想.
non-static
pre-trained vectors + fine tuning , 即拿word2vec训练好的词向量初始化, 训练过程中再对它们微调.
multiple channel
类比于图像中的RGB通道, 这里也可以用 static 与 non-static 搭两个通道来搞.
一些结果表明,max-pooling 总是优于 average-pooling ,理想的 filter sizes 是重要的,但具体任务具体考量,而用不用正则化似乎在NLP任务中并没有很大的不同。
文本分类TextCNN的更多相关文章
- 文本分类-TextCNN
简介 TextCNN模型是由 Yoon Kim提出的Convolutional Naural Networks for Sentence Classification一文中提出的使用卷积神经网络来处理 ...
- 文本分类实战(二)—— textCNN 模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- fastText、TextCNN、TextRNN……这里有一套NLP文本分类深度学习方法库供你选择
https://mp.weixin.qq.com/s/_xILvfEMx3URcB-5C8vfTw 这个库的目的是探索用深度学习进行NLP文本分类的方法. 它具有文本分类的各种基准模型,还支持多标签分 ...
- 文本分类(TFIDF/朴素贝叶斯分类器/TextRNN/TextCNN/TextRCNN/FastText/HAN)
目录 简介 TFIDF 朴素贝叶斯分类器 贝叶斯公式 贝叶斯决策论的理解 极大似然估计 朴素贝叶斯分类器 TextRNN TextCNN TextRCNN FastText HAN Highway N ...
- 基于Text-CNN模型的中文文本分类实战 流川枫 发表于AI星球订阅
Text-CNN 1.文本分类 转眼学生生涯就结束了,在家待就业期间正好有一段空闲期,可以对曾经感兴趣的一些知识点进行总结. 本文介绍NLP中文本分类任务中核心流程进行了系统的介绍,文末给出一个基于T ...
- 基于Text-CNN模型的中文文本分类实战
Text-CNN 1.文本分类 转眼学生生涯就结束了,在家待就业期间正好有一段空闲期,可以对曾经感兴趣的一些知识点进行总结. 本文介绍NLP中文本分类任务中核心流程进行了系统的介绍,文末给出一个基于T ...
- Bert文本分类实践(二):魔改Bert,融合TextCNN的新思路
写在前面 文本分类是nlp中一个非常重要的任务,也是非常适合入坑nlp的第一个完整项目.虽然文本分类看似简单,但里面的门道好多好多,博主水平有限,只能将平时用到的方法和trick在此做个记录和分享 ...
- 文本分类实战(十)—— BERT 预训练模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- 文本分类实战(九)—— ELMO 预训练模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
随机推荐
- Linux基础命令---lpstat查看打印任务
lpstat lpstat指令用来显示当前任务.打印机的状态.如果没有参数,那么就显示打印队列. 此命令的适用范围:RedHat.RHEL.Ubuntu.CentOS.Fedora.openSUSE. ...
- Linux操作oracle——关闭、停止、重启
基础命令: 在此之前,先介绍一下切换到oracle用户的命令 su - oracle (注意空格) 一.启动监听.启动数据库1.1启动监听1.切换到oracle用户下 2.启动监听: lsnrctl ...
- 尚硅谷面试第一季-13git分支相关命令
课堂重点:分支相关命令 实际应用-工作流程 实操命令及运行结果: 创建master分支并提交 git init git add . git commit -m "V1.0" git ...
- sql语句修改字段约束为不为空 并为其设置主键
alter table Drc_Project_Review alter column ReviewID uniqueidentifier not nullalter table Drc_Projec ...
- TCP协议三次握手、四次挥手
TCP的概述 TCP 把连接作为最基本的对象,每一条 TCP 连接都有两个端点,这种断点我们叫作套接字(socket),它的定义为端口号拼接到 IP 地址即构成了套接字,例如,若 IP 地址为 192 ...
- C++类的大小计算汇总
C++中类涉及到虚函数成员.静态成员.虚继承.多继承.空类等. 类,作为一种类型定义,是没有大小可言的. 类的大小,指的是类的对象所占的大小.因此,用sizeof对一个类型名操作,得到的是具有该类型实 ...
- 关系数据库、NoSQL和NewSQL数据库产品分类
- Codeforces Round #495 (Div. 2) C. Sonya and Robots
http://codeforces.com/contest/1004/problem/C 题意: 在一行上有n个数字,现在在最左边和最右边各放置一个机器人,左右机器人各有一个数字p和q.现在这两个机器 ...
- stlcky footers布局小技巧
sticky-footer解决方案 在网页设计中,Sticky footers设计是最古老和最常见的效果之一,大多数人都曾经经历过.它可以概括如下:如果页面内容不够长的时候,页脚块粘贴在视窗底部:如果 ...
- 【五】jquery之事件(focus事件与blur事件)[提示语的出现及消失时机]
例题:当鼠标移动到某个文本框时,提示语消失. 当失去焦点时,如果该文本框有内容,保存内容.没有内容,则恢复最初的提示语句 <!DOCTYPE html> <html> < ...