SQLTest系列之INSERT语句测试
原文地址:https://yq.aliyun.com/articles/64375?spm=5176.100239.blogcont69187.22.fhUpoZ
摘要: 一款可以测试MSSQL Server的工具,这篇文章主要是分享下SQLTest之Insert语句测试。
场景引入
菜鸟不断又猛又持久的给老鸟惊喜以后,老鸟开始不断的折腾菜鸟:“鸟,你研究下有没有一款可以测试MSSQL Server的工具吧?”。
“这还不简单,用Red Gate的SQLTest呗”,于是菜鸟开始了工具的研究之旅:“要不,今天就分享下SQLTest之Insert语句测试吧”。
SQLTest简介
领了任务的菜鸟,由于之前对这个工具有所了解,所以还是比较轻车熟路的。让我们先来看看SQLTest是干什么的吧。
SQLTest是一款简单易用,非常容易上手的SQL Server性能、压力和单元测试工具。它既可以测试本地环境的SQL Server工作负载,也可以测试云环境的SQL Server服务。
SQLTest一键安装
SQLTest就是一个简单的SQL Server测试工具,所以,它的安装过程也简单。官方推荐一键安装,简单到令人发指的地步。
下载地址:
http://www.sqltest.org/Download
测试环境
在测试之前,菜鸟汇总自己的测试环境信息:
CPU:4 cores
Memory:4 GB
Disk: SSD
SQL Server: SQL Server 2008R2 SP2
SQLTest INSERT语句测试
老实讲,上面都不重要,看好了,这里才是本文的重点:如何使用SQLTest来测试INSERT的效率呢?如何测试INSERT语句在不同线程数量下的效率?不同的数据类型选择对INSERT效率的影响如何?
这里虚拟一个场景,假设我们有一张名为Orders的订单表,我们会根据Orders的主键数据类型的不同来测试INSERT的效率。
INT IDENTITY
创建测试数据库和Orders表
use master;
IF DB_ID('SQLTestDemo') IS NULL
CREATE DATABASE SQLTestDemo
go
use SQLTestDemo
go
IF OBJECT_ID('Orders','U') IS NOT NULL
BEGIN
TRUNCATE TABLE Orders
DROP TABLE Orders
END
GO
CREATE TABLE Orders (
OrderID INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED
, OrderDate datetime
, CustomerID int
, SourceID int
, StatusID int
, Amount decimal (18, 2)
, OrderDetails char(7000)
)
GO
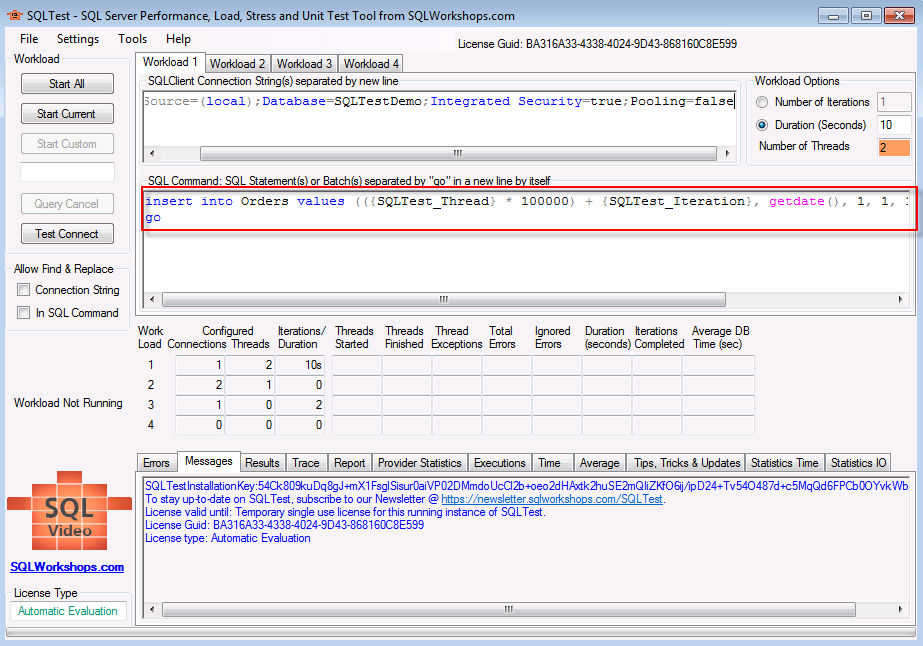
所有准备工作就绪,菜鸟迫不及待的开始测试了,开启SQLTest,设置SQLClient Connection String
Data Source=(local);Database=SQLTestDemo;Integrated Security=true;Pooling=false
SQL Command
insert into Orders values (getdate (), 1, 1, 1, 1, replicate ('a', 7000))
go
Number of Threads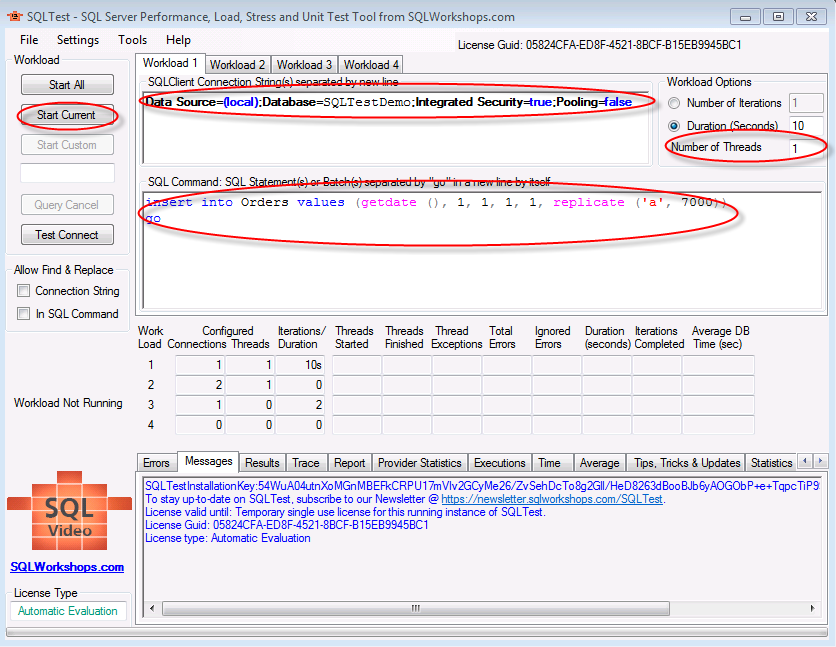
点击Start Current按钮,测试时间10秒后,得到如下截图:
1个线程运行10秒钟,迭代了12471次,每次迭代消耗数据库时间0.000秒。(由于这里精确到千分之一秒,也就是一毫秒,说明每次迭代耗时少于1毫秒)。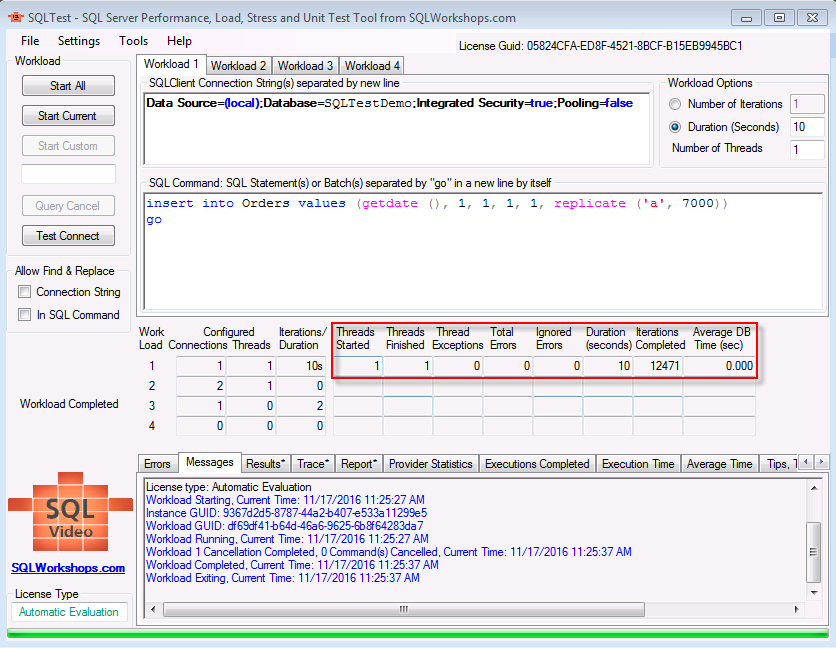
现在我们分别将线程数调整为2,4,8,16,32,64,128,256来测试,为了测试的相对准确性,请在测试之前执行“创建测试数据库和Orders表”中的代码,重新创建Orders表。SQLTest返回结果的设置方法如下:Settings => Workload Settings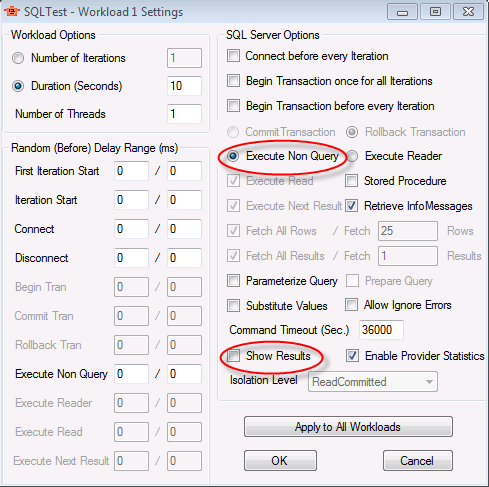
测试完毕后,我们可以得到如下表格数据:
将这些数据绘制成直方图和折线图: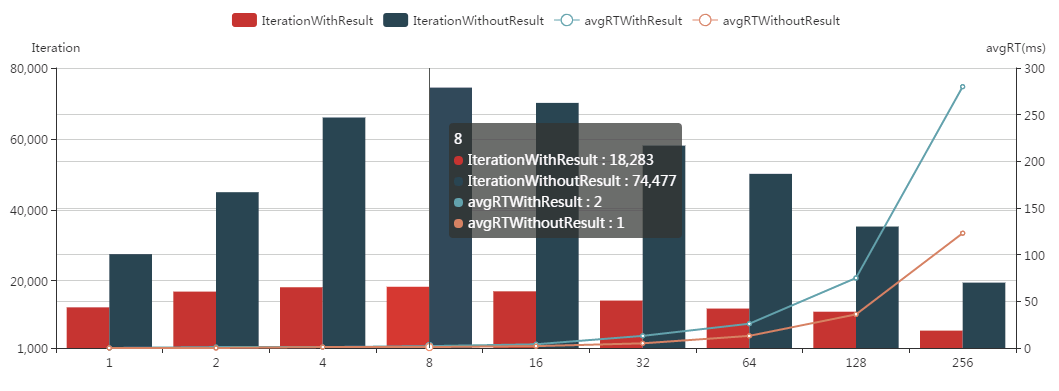
从这个图中,可以很直观的得出如下结论:
- 从吞吐量来看:无输出结果方式远远大于有输出结果方式,前者是后者的两倍还多;
- 从数据库平均耗时来看:无输出结果效率也远远高于有输出结果方式,后者是前者的两倍;
- 从线程数量来看:并不是线程数开得越多,SQL Server吞吐量越大,效率越高;无论是有输出结果方式还是无输出结果方式,并发8到16个线程SQL Server的吞吐量达到最大,效率最高;
注意:
最后一个结论不一定适用于所有的SQL Server,因为这个和SQL Server的版本,机器的CPU,Memory,磁盘等有密切的关系,用户在得到这个值之前需要自己严格测试。
提供INT值
完成了主键值INT IDENTITY的测试后,菜鸟陷入了疑惑:每个线程如何插入不同的值呢?于是有了这个测试方法:
use SQLTestDemo
go
IF OBJECT_ID('Orders','U') IS NOT NULL
begin
truncate table Orders
drop table Orders
end
go
create table Orders (OrderID int primary key clustered
, OrderDate datetime
, CustomerID int
, SourceID int
, StatusID int
, Amount decimal (18, 2)
, OrderDetails char (7000)
)
go
让每个线程生成不同的OrderID,我们可以使用SQLTest_Thread来代替线程数,SQLTest_Iteration代替迭代次数,最终将SQL Command修改为:
insert into Orders values (({SQLTest_Thread} * 100000) + {SQLTest_Iteration}, getdate(), 1, 1, 1, 1, replicate ('a', 7000))
go
UNIQUEIDENTIFIER with NEWID()
测试方法类似于“INT IDENTITY”章节,只是Orders表结构和SQL Command不一致。
use SQLTestDemo
go
IF OBJECT_ID('Orders','U') IS NOT NULL
begin
truncate table Orders
drop table Orders
end
go
create table Orders (
OrderID uniqueidentifier not null default newid () primary key clustered
, OrderDate datetime
, CustomerID int
, SourceID int
, StatusID int
, Amount decimal (18, 2)
, OrderDetails char (7000))
go
SQL Command
insert into Orders values (NEWID(),getdate (), 1, 1, 1, 1, replicate ('a', 7000))
go
UNIQUEIDENTIFIER with NEWSEQUENTIALID()
同上,测试方法类似于“INT IDENTITY”章节,只是Orders表结构和SQL Command不一致。
use SQLTestDemo
go
IF OBJECT_ID('Orders','U') IS NOT NULL
BEGIN
TRUNCATE TABLE Orders
DROP TABLE Orders
END
GO
CREATE TABLE Orders (
OrderID uniqueidentifier default newsequentialid () primary key clustered
, OrderDate datetime
, CustomerID int
, SourceID int
, StatusID int
, Amount decimal (18, 2)
, OrderDetails char (7000))
GO
SQL Command
insert into Orders(OrderDate,CustomerID,SourceID,StatusID,Amount,OrderDetails) values (getdate (), 1, 1, 1, 1, replicate ('a', 7000))
go
总结
将四种数据类型在No Result输出情况汇总统计如下表: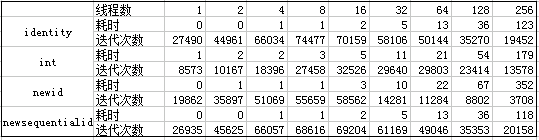
做一个漂亮炫酷的图表出来对比下: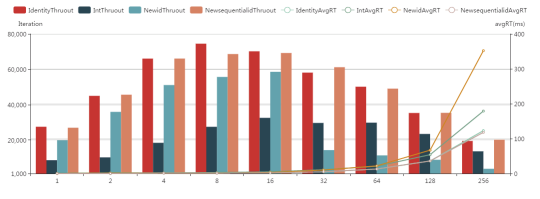
从这个图标,我们可以发现如下规律:
- 从吞吐量角度来看:所有数据类型,并发量聚集在8到16时,INSERT操作吞吐量达到最大值;
- 吞吐量表现最好的是int identity数据类型和uniqueidentifier + newsequentialid做为主键的表;
- 从数据库平均耗时角度:所有数据类型,并发量在8到16时,INSERT操作的平均时间消耗最小,接近64个线程时,平均耗时会急剧上升;
- 平均耗时表现最好的是int identity和Newsequentialid类型。
从结果来看,UNIQUEIDENTIFIER + NEWSEQUENTIALID和INT IDENTITY性能和吞吐量表现都非常好,我们到底该选择哪一个更好一些呢? 我的结论是选择IDENTITY属性的数字类型字段做为主键,因为它占的空间更小,INT为4个字节,BIGINT为8个字节而UNIQUEIDENTIFIER 占了36个字节。
SQLTest系列之INSERT语句测试的更多相关文章
- Sql Server系列:Insert语句
1 INSERT语法 [ WITH <common_table_expression> [ ,...n ] ] INSERT { [ TOP ( expression ) [ PERCEN ...
- 将表里的数据批量生成INSERT语句的存储过程 增强版
将表里的数据批量生成INSERT语句的存储过程 增强版 有时候,我们需要将某个表里的数据全部或者根据查询条件导出来,迁移到另一个相同结构的库中 目前SQL Server里面是没有相关的工具根据查询条件 ...
- 一条诡异的insert语句
问题背景 有同事反馈在mysql上面执行一条普通的insert语句,结果报错, execute failed due to >>> Incorrect string value: ' ...
- 将表里的数据批量生成INSERT语句的存储过程 继续增强版
文章继续 桦仔兄的文章 将表里的数据批量生成INSERT语句的存储过程 增强版 继续增强... 本来打算将该内容回复于桦仔兄的文章的下面的,但是不知为何博客园就是不让提交!.... 所以在这里贴出来吧 ...
- 把表里的数据转换为insert 语句
当表里面有数据时,怎么把表里的数据转换为insert 语句 (从别人那里看来的用SQLServer 2008 R2测试可用) CREATE PROC spGenInsertSQL @TableName ...
- SQL注入测试平台 SQLol -3.INSERT注入测试
访问首页的insert模块,http://127.0.0.1/sql/insert.php,开始对insert模块进行测试. insert语句: INSERT INTO [users] ([usern ...
- 一步一图:从SQLSERVER2005中导出insert语句
1.为什么要导出insert语句,我电脑装的是SQL Server Express免费版的,服务器上装的是正式版,在服务器上备份的数据库文件在本机上还原的时候 因为版本不一样,总是不成功.如果能直接使 ...
- 老李分享:MySql的insert语句的性能优化方案
老李分享:MySql的insert语句的性能优化方案 性能优化一直是测试人员比较感兴趣的内容,poptest在培训学员的时候也加大了性能测试调优的方面的内容,而性能优化需要经验的积累,经验的积累依 ...
- mybatis源码专题(2)--------一起来看下使用mybatis框架的insert语句的源码执行流程吧
本文是作者原创,版权归作者所有.若要转载,请注明出处.本文以简单的insert语句为例 1.mybatis的底层是jdbc操作,我们先来回顾一下insert语句的执行流程,如下 执行完后,我们看下数据 ...
随机推荐
- 神经网络优化方法总结:SGD,Momentum,AdaGrad,RMSProp,Adam
1. SGD Batch Gradient Descent 在每一轮的训练过程中,Batch Gradient Descent算法用整个训练集的数据计算cost fuction的梯度,并用该梯度对模型 ...
- WebMagic之爬虫监控
访问我的博客 前言 年前闲着无聊,研究了一阵子爬虫技术,接触到爬虫框架 WebMagic,感觉很好用. 在之后的工作中,接手了新站与第三方接口对接的工作,主要的工作是去抓取对方接口的内容:初始的时候, ...
- 回头再看看babel的实现原理
一.前言 babel在大家的工作中应该没少用,但是为什么它能将ES6转成ES5呢?一个有态度的前端er肯定会想抛开迷雾,看看其中的奥秘. 记得很早前自己有去了解过相关方面的内容,但是时间久远,现在已是 ...
- ConcurrentHashmap源码好好给你说明白
这个ConcurrentHashmap的设计非常精妙,如果有疑问的地方,欢迎大家在评论区进行激烈讨论! 一.静态工具方法 private static final int tableSizeFor(i ...
- zoj Beautiful Number(打表)
题目链接: http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemCode=2829 题目描述: Mike is very lucky, as ...
- WPF备忘录(2)WPF获取和设置鼠标位置与progressbar的使用方法
一.WPF 中获取和设置鼠标位置 方法一:WPF方法 Point p = Mouse.GetPosition(e.Source as FrameworkElement); Point p = (e.S ...
- mysql数据库自动备份脚本
#!/bin/bash #功能说明:本功能用于备份mysql数据库 #编写日期:2018/05/17 PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin ...
- 环境配置问题: 关于IDEA配置tomcat
1. 先下载并解压缩一个tomcat7 2.打开idea 3. -Xms256M -Xmx1024M -XX:PermSize=64M -XX:MaxPermSize=128M 关于热部署设置参考: ...
- Oracle总结之plsql编程(基础九)
原创作品,转自请注明出处:https://www.cnblogs.com/sunshine5683/p/10344302.html 接着上次总结,继续今天的总结,今天主要总结plsql中控制语句,如条 ...
- POJ3281(KB11-B 最大流)
Dining Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 19170 Accepted: 8554 Descripti ...