windows中eclipse调试hadoop
下载eclipse:https://www.eclipse.org/downloads/eclipse-packages
下载hadoop eclipse插件:https://github.com/winghc/hadoop2x-eclipse-plugin/tree/master/release/hadoop-eclipse-plugin-2.6.0.jar
下载hadoop:http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.7.1/hadoop-2.7.1.tar.gz
下载hadoop2.7.1的window下编译好的bin目录:http://url.cn/4EO196a
1、配置hadoop环境变量
将下载的hadoop-2.7.1.tar.gz进行解压,复制解压路径,配置到系统环境变量中
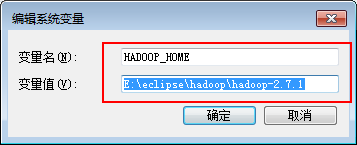
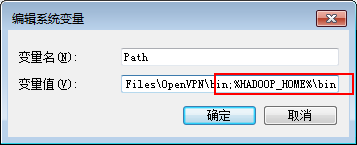
解压下载hadoop windowsbin目录包

将解压出来的内容复制到hadoop-2.7.1\bin 目录中,再将hadoop.dll文件复制到C:\Windows\System32中,然后重启机器;
2、配置eclipse
打开eclipse ,选择window/Peferences设置hadoop安装路径

在eclipse中的MapReduce面板右击新建hadoop localtion

在弹窗的面板中输入hadoop服务器的DFS Master ip和端口
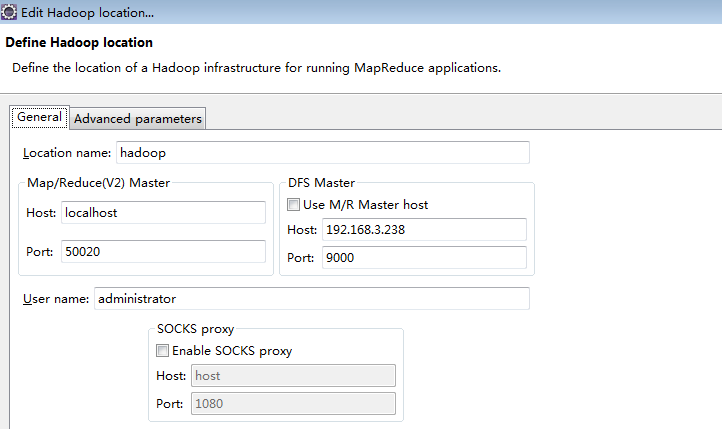
注意由于本机使用的是administrator的用户,所以访问服务器的DFS可能会有权限问题,可master服务器的hadoop/etc/hadoop/hdfs-site.xml 中添加如下配置
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
完成后可在Project Exploer中看到如下界面

3、新建hadoop项目


WordCount.java代码
package com.apache.hadoop.examples; import java.io.IOException;
import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser; public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1);
private Text word = new Text(); public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
} public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
在运行main方法前先配置参数,并且在项目跟目录(myFirstHadoop)下面新建input文件夹,再往里面添加测试文件,文件里面随意添加一些单词

执行后会在myFirstHadoop下出现一个output文件夹,里面的文件中会有运行的结果,注意下次运行的时候要删除output目录


4、在eclipse中连接服务器hdfs测试
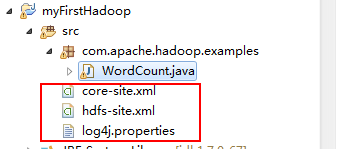
4.1、复制配置文件
在master服务器中下载三个配置文件core-site.xml,hdfs-site.xml,log4j.properties,并复制到项目的src下
4.2、修改运行参数
由于window中调用服务器的时候是使用的administrator账号,而服务器fdfs在使用相对路径时是相对/user/用户名的路径
而我们服务器中没有administrator用户,所以要将运行参数改成绝对路径

如图我使用的是hadoop的账号,运算后的输入路径为/user/hadoop/input,输出路径为/user/hadoop/output
4.3、新建目录并上传数据
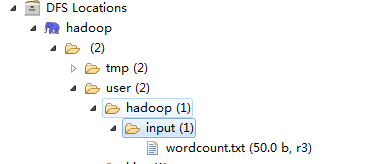
如图在user添加hadoop和input的目录与我们运行参数中的配置对应,然后上传我们的测试文件wordcount.txt
4.4、运行测试程序
运行配置和输入数据都准备好后执行程序,将在/user/hadoop/output中看到输出结果,结果应该和3中本地测试的结果一致;
4.5、导出测试的jar包到服务器运行
测试ok后可以将jar包进行导出,方便直接在服务器中运行使用
在项目上右击,选择Export,再选择JAR file
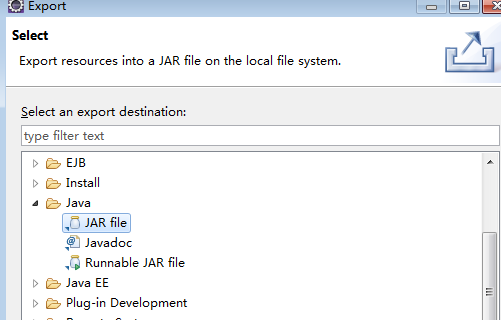
next后选择导出路径,将导出的wordcount.jar上传到hadoop的master服务器的/opt目录
通过hdfs dfs -put /opt/wordcount.txt input 往input目录中添加测试文件,文件的内容跟eclipse中一致,如果input目录不存在则要先新建input目录
hdfs dfs -mkdir input
执行:
hadoop jar /opt/wordcount.jar com.apache.hadoop.examples.WordCount input/wordcount.txt output
通过
hdfs dfs -cat /opt/test.txt output/part-r-00000
可看到输出和之前测试一样的结果
windows中eclipse调试hadoop的更多相关文章
- windows下本地调试hadoop代码,远程调试hadoop节点。
1.在github上搜索下载winutils.exe相关的一套文件,下载对应hadoop的版本. 2.将所有文件复制到hadoop的bin目录下 3.将hadoop.dll复制到windows\sys ...
- Windows下Eclipse连接hadoop
2015-3-27 参考: http://www.cnblogs.com/baixl/p/4154429.html http://blog.csdn.net/u010911997/article/de ...
- windows中eclipse连接虚拟机hdfs
1.修改配置文件core-site.xml,将其中localhost改为虚拟机的ip地址: 在Ubuntu中,打开控制台,使用命令ifconfig查看虚拟机ip,如图: 修改[hadoop安装路径]/ ...
- windows 中 Eclipse 打开当前文件所在文件夹
默认情况下使用eclipse打开当前文件所在文件夹很麻烦,需要右键点击 Package Explorer 中的节点选择属性,然后复制路径,再打开资源管理器,然后再把路径粘贴进去.而MyEclipse一 ...
- [原创] Windows下Eclipse连接hadoop
1 下载hadoop-eclipse-plugin :我用的是hadoop-eclipse-plugin1.2.1 ,百度自行下载 2 配置插件:将下载的插件解压,把插件放到..\eclipse\pl ...
- windows下使用eclipse调试C程序
一.环境描述 Eclipse IDE for C/C++ Developers version 4.4.0 MinGW gcc/g++ version 4.8.1;gdb version 7.6.1 ...
- Hadoop学习之配置Eclipse远程调试Hadoop
构建完毕Hadoop项目后,接下来就应该跟踪Hadoop的运行情况,比方在命令行运行hadoop namenode–format时运行了Hadoop的那些代码.当然也能够直接通过阅读源码的方式来做到这 ...
- 如何在Windows中使用Eclipse访问虚拟机Linux系统中的hadoop(伪分布式)
因为计算机配置过低,在虚拟机里几乎无法使用Eclipse,效率极低! 所以现在尝试使用Windows下Eclipse操作虚拟机中Hadoop,步骤如下: 开发环境:Hadoop2.7.1,Ubuntu ...
- eclipse远程调试Hadoop
环境需求: 系统:window 10 eclipse版本:Mars Hadoop版本:2.6.0 资源需求:解压后的Hadoop-2.6.0,原压缩包自行下载:下载地址 丑话前头说: 以下的操作中,e ...
随机推荐
- 用模糊查询like语句时如果要查是否包含%字符串该如何写
- Web 开发
Django(发音:[`dʒæŋɡəʊ]) 是一个开放源代码的Web应用框架,由Python写成.采用了MTV的框架模式,模型(Model).模板(Template)和视图(Views).
- Spring Boot项目简单上手+swagger配置+项目发布(可能是史上最详细的)
Spring Boot项目简单上手+swagger配置 1.项目实践 项目结构图 项目整体分为四部分:1.source code 2.sql-mapper 3.application.properti ...
- 天使投资、A轮、B轮、C轮
一般是这样划分的. A轮融资:公司产品有了成熟模样,开始正常运作一段时间并有完整详细的商业及盈利模式,在行业内拥有一定地位和口碑.公司可能依旧处于亏损状态.资金来源一般是专业的风险投资机构(VC).投 ...
- 主机网络ping: unknown host baidu.com问题解决
本机环境: 系统:Centos 网络:NAT 虚拟机之前一直都可以连外网,但最近不能连了,现状如下: [root@vhost03 ~]# ping baidu.comping: unknown hos ...
- nginx调优操作之nginx隐藏其版本号
1.nginx下载 下载网址:nginx.org 2.解压nginx [root@iZwz9cl4i8oy1reej7o8pmZ soft]# ls nginx-.tar.gz [root@iZwz9 ...
- Failed to place enough replicas
如果DataNode的dfs.datanode.data.dir全配置成SSD类型,则执行"hdfs dfs -put /etc/hosts hdfs:///tmp/"时会报如下错 ...
- css,jQuery,js部分注释
注释:在开头加上<!--,以-->结尾 alt属性,也被称为alt text, 是当图片无法加载时显示的替代文本 action属性的值指定了表单提交到服务器的地址 除了分别指定元素的 pa ...
- TCP、UDP网络通信
IP地址和端口号 端口号是用两个字节(16位的二进制数)表示的,它的取值范围是0~65535,其中,0~1023之间的端口号用于一些知名的网络服务和应用, 用户的普通应用程序需要使用1024以上的端口 ...
- Alpha冲刺 - (3/10)
Part.1 开篇 队名:彳艮彳亍团队 组长博客:戳我进入 作业博客:班级博客本次作业的链接 Part.2 成员汇报 组员1(组长)柯奇豪 过去两天完成了哪些任务 ssm框架的使用并实现简单的数据处理 ...