基于.Net + SqlServer的分库分表设计方案
在说分库分表之前,先简单介绍下网站架构,这样有助于理解为何需要分库分表这种技术。因为所有的技术,大多都是因为业务的需要而产生的.
1、网站发展的第一阶段
大致架构如下,因为没有多少用户访问,所以单台服务器都搞定所有的事情,上面跑着数据库、资源站点、以及所有的业务站点.
2、网站发展的第二阶段
这个时候访问量开始增加,发现服务器的资源不够用了,用户体验越来越差,所以,第一想法,升级服务器配置.ok,暂时解决了问题,站点又能提供稳定且高效的服务.
3、网站发展的第三阶段
访问量持续增加,这个时候升级服务器的配置所产生的代价太大,而且,就算继续升级也无法解决本质的问题,所以开始考虑其它的方案!
很简单,将业务和数据分离,将业务站点和数据库和资源站点分开,如下架构:
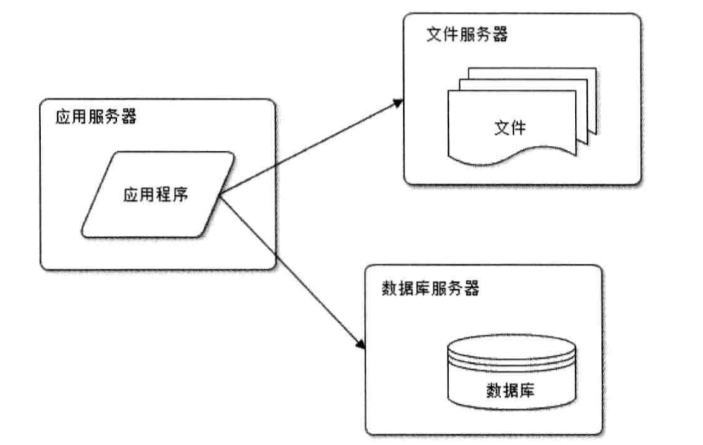
这里需要注意:业务站点需要处理大量的业务逻辑,所以CPU的性能一定要高,文件服务器则需要大一点的硬盘,数据库服务器则需要更快的硬盘和更大的内存.
ok,问题又解决了,站点又能提供稳定且高效的服务.
4、网站发展的第四阶段
访问量持续增加,单台应用服务器的IIS线程并发连接有限,而且随着用户的上升开始出现超时,异常,直至站点崩溃.所以必须解决这个问题.
ok,增加应用服务器,实现小集群(每次加一台),上nginx(关于nginx不了解请参考Nginx),做反向代理,分发用户的请求到不同的应用服务器,如果涉及登陆做下Ip_Hash.
ok,问题又解决了,站点又能提供稳定且高效的服务.
5、网站发展的第五阶段
访问量持续增加,应用服务器也越来越多,数据库的压力越来越大,而且数据随着用户的上升爆发时的增加,数据库面临了性能瓶颈,因为单表数据的上升,所以必须分表,提升查询的速度.所以必须开始动数据库了.
第一步:实现数据库的读写分离,主要是配置,网商有很多文章,自行参考
第二步:分库分表
6、关于分库分表常用的设计思路
按时间、按地区(IP)、按业务进行划分,无外乎这三种方式.下面简单的介绍个例子,假设站点是个登陆站点,主要分为QQ登陆和微信登陆,站点需要记录每次用户的登陆的一些信息.
假设每天有10万用户登陆.做过单表10万数据查询的知道,不加索引的情况下,还是有点慢的.所以我们需要对这个登陆记录表进行拆分.第一步按QQ登陆和微信登陆进行分库,将通过QQ登陆的用户登陆信息存储到QQ登陆库,微信同理,这样每个库每天承担5万的写操作.
但是单表5万记录查询还是有点慢,这个时候还可以进行细分,比如按用户Id,进行拆封按用户Id拆分一般有两种(用户Id算法):
(1)、如果Id是int整数(如SqlServer的自增Id),可以采用Id%10取余算法,找到目标表。采用这种算法,那么原先的单表被拆封成0~9十个表,每个表承担5000的写操作,这样压力瞬间就下来了
(2)、如果Id是Guid(长度固定,全大写),获取最后1个字母,找到目标表,采用这种算法,那么原先的单表被拆封成A-Z36个表,每个表承担写压力就更小了.
上面两个都可取,但是可以根据具体的业务酌情选择.
目前为止,解决了单天的性能瓶颈,但是每天都有10万数据进来,肯定是不行的,所以按照上面的思路每天的数据必须在当前被清空,因为不清空,随着数据每天加10万的操作,查询到最后还是受不了.
所以必须写个定时服务,每天在业务低峰期清除QQ登陆信息库和微信登陆信息库的数据,清楚的同时将它们迁移到对应QQ登陆信息历史库和微信登陆历史库中,关于历史库的构建就需要仔细考虑了.
考虑了几种方案:
(1)、就两个历史库(微信登陆历史库和QQ登陆历史库),直接Pass,每天10万数据的递增,不用一年就直接崩了.
(2)、按年分库 月+日+用户Id 进行分表 直接Pass,这个方案会产生大概3600个表
(3)、权衡考虑采用按年分库 月+用户Id 进行分表 如果用户Id采用用户Id算法的第一种,那么会产生大概120个表.
确定好历史库设计方案之后,将每天的登陆信息记录同步到对应的历史库中.
基于.Net + SqlServer的分库分表设计方案的更多相关文章
- 基于代理的数据库分库分表框架 Mycat实践
192.168.199.75 MySQL . MyCAT master 192.168.199.74 MySQL slave 192.168.199.76 MySQL standby master 如 ...
- 架构组件:基于Shard-Jdbc分库分表,数据库扩容方案
本文源码:GitHub·点这里 || GitEE·点这里 一.数据库扩容 1.业务场景 互联网项目中有很多"数据量大,业务复杂度高,需要分库分表"的业务场景. 这样分层的架构 (1 ...
- 分库分表中间件sharding-jdbc的使用
数据分片产生的背景,可以查看https://shardingsphere.apache.org/document/current/cn/features/sharding/,包括了垂直拆分和水平拆分的 ...
- 【分库分表】sharding-jdbc—解决的问题
一.遇到的问题 随着互联网技术和业务规模的发展,单个db的表里数据越来越多,sql的优化已经作用不明显或解决不了问题了,这时系统的瓶颈就是单个db了(或单table数据太大).这时候就涉及到分库分表的 ...
- 【MySQL】数据库(分库分表)中间件对比
分区:对业务透明,分区只不过把存放数据的文件分成了许多小块,例如mysql中的一张表对应三个文件.MYD,MYI,frm. 根据一定的规则把数据文件(MYD)和索引文件(MYI)进行了分割,分区后的表 ...
- 一种可以避免数据迁移的分库分表scale-out扩容方式
原文地址:http://jm-blog.aliapp.com/?p=590 目前绝大多数应用采取的两种分库分表规则 mod方式 dayofweek系列日期方式(所有星期1的数据在一个库/表,或所有?月 ...
- mysql分库分表(二)
mysql分库分表 参考: https://www.cnblogs.com/dongruiha/p/6727783.html https://www.cnblogs.com/oldUncle/p/64 ...
- [转]一种可以避免数据迁移的分库分表scale-out扩容方式
原文地址:http://jm-blog.aliapp.com/?p=590 目前绝大多数应用采取的两种分库分表规则 mod方式 dayofweek系列日期方式(所有星期1的数据在一个库/表,或所有?月 ...
- 一种可以避免数据迁移的分库分表scale-out扩容模式
转自: http://jm.taobao.org/ 一种可以避免数据迁移的分库分表scale-out扩容方式 目前绝大多数应用采取的两种分库分表规则 mod方式 dayofweek系列日期方式(所有星 ...
随机推荐
- @RequestBody jackson解析复杂的传入值的一个坑;jackson解析迭代数组;jackson多重数组;jakson数组
一.实际开发的一个问题. 传入一个json数组,数组中还嵌套数组,运用springboot+Jpa框架,@RequestBody注解传入数据 Controller @ApiOperation(valu ...
- vue的过渡和动画
简单过渡 .fade-enter-active, .fade-leave-active { transition: all .5s; } /*.fade-enter, .fade-leave-to { ...
- Redis-环境搭建
Redis官方不提供Windows版,不过微软开源组织提供了Windows版本的Redis,此处将安装Windows版的Reids,供学习使用. 1.下载Windows版Redis安装包: 安装包地址 ...
- python中的取整
处理数据时,经常会遇到取整的问题,现总结如下 1,向下取整 int() >>>a = 3.1 >>>b = 3.7 >>>int(a) 3 > ...
- Ng第五课:Octave 教程(Octave Tutorial)
5.1 基本操作 5.2 对数据进行灵活操作 5.3 计算数据 5.4 数据可视化 5.5 控制语句和函数 5.6 矢量化 官网安装:Installation 在线文档:http://ww ...
- UISegmentedControl 改变选中字体的颜色
//设置选中的字体颜色为蓝色 [segmentControll setTitleTextAttributes:@{NSForegroundColorAttributeName:[UIColor ...
- HDU2444 The Accomodation of Students
The Accomodation of Students Time Limit: 5000/1000 MS (Java/Others) Memory Limit: 32768/32768 K ( ...
- STL-容器库000
容器库已经作为class templates 实现. 容器库中是编程中常用的结构: (1)动态数组结构vector: (2)队列queue: (3)栈stack: (4)heaps 堆priority ...
- 12.equals()方法总结
超类Object中有这个equals()方法,该方法主要用于比较两个对象是否相等.该方法的源码如下: 我们知道所有对象都有表示(内存地址)和状态(数据),看上面代码是用"=="来比 ...
- hdu 5083 有坑+字符串模拟水题
http://acm.hdu.edu.cn/showproblem.php?pid=5083 机器码和操作互相转化 注意SET还要判断末5位不为0输出Error #pragma comment(lin ...