Spark源码分析 – Dependency
Dependency
依赖, 用于表示RDD之间的因果关系, 一个dependency表示一个parent rdd, 所以在RDD中使用Seq[Dependency[_]]来表示所有的依赖关系
Dependency的base class
可见Dependency唯一的成员就是rdd, 即所依赖的rdd, 或parent rdd
/**
* Base class for dependencies.
*/
abstract class Dependency[T](val rdd: RDD[T]) extends Serializable
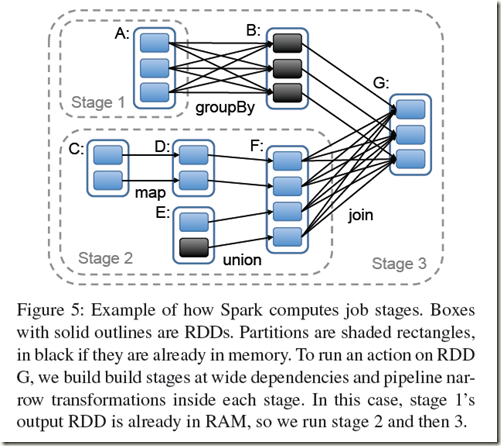
Dependency分为两种, narrow和shuffle
NarrowDependency
先看看比较简单的narrow
定义, parent RDD中的每个partition最多被child RDD中的一个partition使用, 即不需要shuffle
更直白点, 就是Narrow只有map, partition本身范围不会改变, 一个parititon经过transform还是一个partition, 虽然内容发生了变化, 所以可以在local完成
而wide就是, partition需要打乱从新划分, 存在shuffle的过程, partition的数目和范围都发生了变化
唯一的接口getParents, 即给定任一个partition-id, 得到所有依赖的parent partitions的id的seq
/**
* Base class for dependencies where each partition of the parent RDD is used by at most one
* partition of the child RDD. Narrow dependencies allow for pipelined execution.
*/
abstract class NarrowDependency[T](rdd: RDD[T]) extends Dependency(rdd) {
/**
* Get the parent partitions for a child partition.
* @param partitionId a partition of the child RDD
* @return the partitions of the parent RDD that the child partition depends upon
*/
def getParents(partitionId: Int): Seq[Int]
}
NarrowDependency又分为两种,
OneToOneDependency
最简单的依赖关系, 即parent和child里面的partitions是一一对应的, 典型的操作就是map, filter…
其实partitionId就是partition在RDD中的序号, 所以如果是一一对应, 那么parent和child中的partition的序号应该是一样的
/**
* Represents a one-to-one dependency between partitions of the parent and child RDDs.
*/
class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd) {
override def getParents(partitionId: Int) = List(partitionId) //序号一致
}
RangeDependency
虽然仍然是一一对应, 但是是parent RDD中的某个区间的partitions对应到child RDD中的某个区间的partitions
典型的操作是union, 多个parent RDD合并到一个child RDD, 故每个parent RDD都对应到child RDD中的一个区间
需要注意的是, 这里的union不会把多个partition合并成一个partition, 而是的简单的把多个RDD中的partitions放到一个RDD里面, partition不会发生变化, 可以参考Spark 源码分析 – RDD 中UnionRDD的实现
由于是range, 所以直接记录起点和length就可以了, 没有必要加入每个中间rdd, 所以RangeDependency优化了空间效率
/**
* Represents a one-to-one dependency between ranges of partitions in the parent and child RDDs.
* @param rdd the parent RDD
* @param inStart the start of the range in the parent RDD, parent RDD中区间的起始点
* @param outStart the start of the range in the child RDD, child RDD中区间的起始点
* @param length the length of the range
*/
class RangeDependency[T](rdd: RDD[T], inStart: Int, outStart: Int, length: Int)
extends NarrowDependency[T](rdd) { override def getParents(partitionId: Int) = {
if (partitionId >= outStart && partitionId < outStart + length) { //判断partitionId的合理性,必须在child RDD的合理partition范围内
List(partitionId - outStart + inStart) //算出parent RDD中对应的partition id
} else {
Nil
}
}
}
WideDependency
WideDependency, 也称为ShuffleDependency
首先需要基于PairRDD, 因为一般需要依据key进行shuffle, 所以数据结构往往是kv
即RDD中的数据是kv pair, [_ <: Product2[K, V]],
trait Product2[+T1, +T2] extends Product // Product2 is a cartesian product of 2 components
Product2是trait, 这里实现了Product2可以用于表示kv pair? 不是很理解
其次, 由于需要shuffle, 所以当然需要给出partitioner, 如何完成shuffle
然后, shuffle不象map可以在local进行, 往往需要网络传输或存储, 所以需要serializerClass
最后, 每个shuffle需要分配一个全局的id, context.newShuffleId()的实现就是把全局id累加
/**
* Represents a dependency on the output of a shuffle stage.
* @param rdd the parent RDD
* @param partitioner partitioner used to partition the shuffle output
* @param serializerClass class name of the serializer to use
*/
class ShuffleDependency[K, V](
@transient rdd: RDD[_ <: Product2[K, V]],
val partitioner: Partitioner,
val serializerClass: String = null)
extends Dependency(rdd.asInstanceOf[RDD[Product2[K, V]]]) { val shuffleId: Int = rdd.context.newShuffleId()
}
Spark源码分析 – Dependency的更多相关文章
- Spark源码分析 – 汇总索引
http://jerryshao.me/categories.html#architecture-ref http://blog.csdn.net/pelick/article/details/172 ...
- Spark源码分析 – SparkContext
Spark源码分析之-scheduler模块 这位写的非常好, 让我对Spark的源码分析, 变的轻松了许多 这里自己再梳理一遍 先看一个简单的spark操作, val sc = new SparkC ...
- Spark源码分析之七:Task运行(一)
在Task调度相关的两篇文章<Spark源码分析之五:Task调度(一)>与<Spark源码分析之六:Task调度(二)>中,我们大致了解了Task调度相关的主要逻辑,并且在T ...
- Spark源码分析之五:Task调度(一)
在前四篇博文中,我们分析了Job提交运行总流程的第一阶段Stage划分与提交,它又被细化为三个分阶段: 1.Job的调度模型与运行反馈: 2.Stage划分: 3.Stage提交:对应TaskSet的 ...
- Spark源码分析之三:Stage划分
继上篇<Spark源码分析之Job的调度模型与运行反馈>之后,我们继续来看第二阶段--Stage划分. Stage划分的大体流程如下图所示: 前面提到,对于JobSubmitted事件,我 ...
- Spark源码分析之二:Job的调度模型与运行反馈
在<Spark源码分析之Job提交运行总流程概述>一文中,我们提到了,Job提交与运行的第一阶段Stage划分与提交,可以分为三个阶段: 1.Job的调度模型与运行反馈: 2.Stage划 ...
- spark 源码分析之十九 -- DAG的生成和Stage的划分
上篇文章 spark 源码分析之十八 -- Spark存储体系剖析 重点剖析了 Spark的存储体系.从本篇文章开始,剖析Spark作业的调度和计算体系. 在说DAG之前,先简单说一下RDD. 对RD ...
- spark源码分析以及优化
第一章.spark源码分析之RDD四种依赖关系 一.RDD四种依赖关系 RDD四种依赖关系,分别是 ShuffleDependency.PrunDependency.RangeDependency和O ...
- Spark源码分析(三)-TaskScheduler创建
原创文章,转载请注明: 转载自http://www.cnblogs.com/tovin/p/3879151.html 在SparkContext创建过程中会调用createTaskScheduler函 ...
随机推荐
- web中文字体Font-family应该写什么?
最佳实践是: font-family: Helvetica, Tahoma, Arial, "Microsoft YaHei", "微软雅黑",STXihei, ...
- vue的路由使用
1). 安装 vue-router npm install vue-router --save 2). 新建路由配置 安装成功后,在 src 新建 router 文件夹,然后新建 index.js 文 ...
- SAP ECC6安装系列五:安装后 License 的处理
原作者博客 http://www.cnblogs.com/Michael_z/ ======================================== 我发现我确实比较懒,先和各位说声抱歉了 ...
- MySQL 找回密码
Windows: 1.关闭正在运行的MySQL. 2.打开DOS窗口,转到mysql\bin目录. 3.输入mysqld --skip-grant-tables回车.如果没有出现提示信息,那就对了. ...
- session监听器HttpSessionBindingListener
首先我在网上查了一下session的真正销毁条件: 1调用 session.invalidate();方法 2 session到了设置或者默认的超时时间,自动销毁(关闭浏览器此session还未销毁, ...
- Python入门教程 超详细1小时学会Python
Python入门教程 超详细1小时学会Python 作者: 字体:[增加 减小] 类型:转载 时间:2006-09-08我要评论 本文适合有经验的程序员尽快进入Python世界.特别地,如果你掌握Ja ...
- PLSQL 连接不上64位ORACLE数据库解决办法
http://it.oyksoft.com/post/6003/ huan jing bian liang TNS_ADMIN D:\OracleClient D:\OracleClient\TNS ...
- 你有自己的Web缓存知识体系吗?
赵舜东 江湖人称赵班长,曾在武警某部负责指挥自动化的架构和运维工作,2008年退役后一直从事互联网运维工作.曾带团队负责国内某电商的运维工作,<saltstack入门与实践>作者,某学院高 ...
- 第二百七十二节,Tornado框架-iframe标签框架伪造ajax
Tornado框架-iframe标签框架伪造ajax html <!DOCTYPE html> <html> <head lang="en"> ...
- 【UVa】Salesmen(dp)
http://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&page=show_problem&p ...