网络爬虫值scrapy框架基础
简介
Scrapy是一个高级的Python爬虫框架,它不仅包含了爬虫的特性,还可以方便的将爬虫数据保存到csv、json等文件中。
首先我们安装Scrapy。
其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下

安装
linux或者mac
pip3 install scrapy
windows
#下载twisted
http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted #安装wheel模块之后才能安装.whl文件
pip3 install wheel #安装twisted
pip install Twisted‑18.4.0‑cp36‑cp36m‑win_amd64.whl pip3 install pywin32 #安装scrapy
pip3 install scrapy
使用
创建项目
格式:scrapy startproject 项目名
scrapy startproject spider
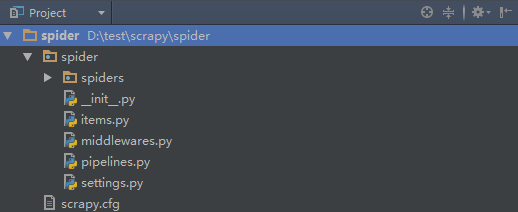
创建项目之后就会生成一个目录,如下:
项目名称/
- spiders # 爬虫文件
- chouti.py
- cnblgos.py
....
- items.py # 持久化
- pipelines # 持久化
- middlewares.py # 中间件
- settings.py # 配置文件(爬虫)
scrapy.cfg # 配置文件(部署)
创建爬虫
格式:
cd 项目名
scrapy genspider 爬虫名 将要爬的网站
cd spider scrapy genspider chouti chouti.com
创建完爬虫之后会在spiders文件夹里生成一个文件
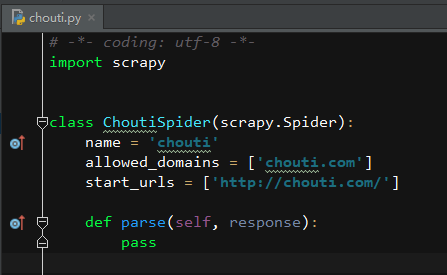
打开chouti.py之后如下:
运行爬虫
scrapy crawl chouti
scrapy crawl chouti --nolog # 不打印日志
示例
# -*- coding: utf-8 -*-
import scrapy class ChoutiSpider(scrapy.Spider):
'''
爬去抽屉网的帖子信息
'''
name = 'chouti'
allowed_domains = ['chouti.com']
start_urls = ['http://chouti.com/'] def parse(self, response):
# 获取帖子列表的父级div
content_div = response.xpath('//div[@id="content-list"]') # 获取帖子item的列表
items_list = content_div.xpath('.//div[@class="item"]') # 打开一个文件句柄,目的是为了将获取的东西写入文件
with open('articles.log','a+',encoding='utf-8') as f:
# 循环item_list
for item in items_list:
# 获取每个item的第一个a标签的文本和url链接
text = item.xpath('.//a/text()').extract_first()
href = item.xpath('.//a/@href').extract_first()
# print(href, text.strip())
# print('-'*100)
f.write(href+'\n')
f.write(text.strip()+'\n')
f.write('-'*100+'\n') # 获取分页的页码,然后让程序循环爬去每个链接
# 页码标签对象列表
page_list = response.xpath('//div[@id="dig_lcpage"]')
# 循环列表
for page in page_list:
# 获取每个标签下的a标签的url,即每页的链接
page_a_url = page.xpath('.//a/@href').extract()
# 将域名和url拼接起来
page_url = 'https://dig.chouti.com' + page_a_url # 重要的一步!!!!
# 导入Request模块,然后实例化一个Request对象,然后yield它
# 就会自动执行Request对象的callback方法,爬去的是url参数中的链接
from scrapy.http import Request
yield Request(url=page_url,callback=self.parse)
网络爬虫值scrapy框架基础的更多相关文章
- Python网络爬虫之Scrapy框架(CrawlSpider)
目录 Python网络爬虫之Scrapy框架(CrawlSpider) CrawlSpider使用 爬取糗事百科糗图板块的所有页码数据 Python网络爬虫之Scrapy框架(CrawlSpider) ...
- 16.Python网络爬虫之Scrapy框架(CrawlSpider)
引入 提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模块递归回调parse方法). 方法 ...
- 16,Python网络爬虫之Scrapy框架(CrawlSpider)
今日概要 CrawlSpider简介 CrawlSpider使用 基于CrawlSpider爬虫文件的创建 链接提取器 规则解析器 引入 提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话, ...
- 网络爬虫之scrapy框架设置代理
前戏 os.environ()简介 os.environ()可以获取到当前进程的环境变量,注意,是当前进程. 如果我们在一个程序中设置了环境变量,另一个程序是无法获取设置的那个变量的. 环境变量是以一 ...
- 网络爬虫之scrapy框架(CrawlSpider)
一.简介 CrawlSpider其实是Spider的一个子类,除了继承到Spider的特性和功能之外,还派生了其自己独有的更强大的特性和功能.其中最显著的功能就是"LinkExtractor ...
- 网络爬虫之scrapy框架详解
twisted介绍 Twisted是用Python实现的基于事件驱动的网络引擎框架,scrapy正是依赖于twisted, 它是基于事件循环的异步非阻塞网络框架,可以实现爬虫的并发. twisted是 ...
- 爬虫之Scrapy框架介绍及基础用法
今日内容概要 爬虫框架之Scrapy 利用该框架爬取博客园 并发编程 今日内容详细 爬虫框架Scrapy 1.什么是框架? 框架类似于房子的结构,框架会提前帮你创建好所有的文件和内部环境 你只需要往对 ...
- Python逆向爬虫之scrapy框架,非常详细
爬虫系列目录 目录 Python逆向爬虫之scrapy框架,非常详细 一.爬虫入门 1.1 定义需求 1.2 需求分析 1.2.1 下载某个页面上所有的图片 1.2.2 分页 1.2.3 进行下载图片 ...
- 爬虫之scrapy框架
解析 Scrapy解释 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓 ...
随机推荐
- 浅析StackTrace
我们在学习函数调用时,都知道每个函数都拥有自己的栈空间.一个函数被调用时,就创建一个新的栈空间.那么通过函数的嵌套调用最后就形成了一个函数调用堆栈.在c#中,使用StackTrace记录这个堆栈.你可 ...
- git学习(一):git的版本库在哪儿
查看版本 git --version # 查看git的版本 设置或者查看用户名和邮箱 git config --global user.name "tuhooo" // 如果后面没 ...
- MDI多文档窗体--在一个窗体中装载多个窗体
创建MDI窗体之前,首先要明确两个概念:父窗体和子窗体,在MDI窗体中,起到容器作用的窗体被称为“父窗体”, 可放在父窗体中的其他窗体被称为子窗体,也成为MDI子窗体.当应用程序启动时,首先会显示父窗 ...
- Js常用插件介绍
*各种JS功能介绍 1.zDialog.js 各种弹窗插件详细案例:http://www.2ky.cn/Pri_upfile/txdemo/0811/zDialog/zDialogDemo.html ...
- [转]解决Cannot change version of project facet Dynamic web module to 2.5
我们用Eclipse创建Maven结构的web项目的时候选择了Artifact Id为maven-artchetype-webapp,由于这个catalog比较老,用的servlet还是2.3的,而一 ...
- 原生js怎么删除一个 div
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- git 停止在12% writing objects 怎么回事?
git 停止在12% writing objects 怎么回事? 输入以下代码试一下: git config --global http.postBuffer 524288000
- 第二百七十一节,Tornado框架-CSRF防止跨站post请求伪造
Tornado框架-CSRF防止跨站post请求伪造 CSRF是什么 CSRF是用来在post请求时做请求验证的,防止跨站post请求伪造 当用户访问一个表单页面时,会自动在表单添加一个隐藏的inpu ...
- PHPMailer发送邮箱
1.可以参考的链接.http://www.helloweba.com/view-blog-205.html 2.下载最新的PHPMailer文件库 3.主要代码 class.phpmailer.php ...
- loadruner11 socket脚本-10053错误
背景: socket 10053异常:软件主动放弃一个连接,原因是超时或协议错误.如果LR客户端报10053异常,说明LR在执行套接字操作时,发生通信超时.网络中断或其它异常,主动将Socket连接断 ...