hadoop 之Hadoop生态系统
1、Hadoop生态系统概况
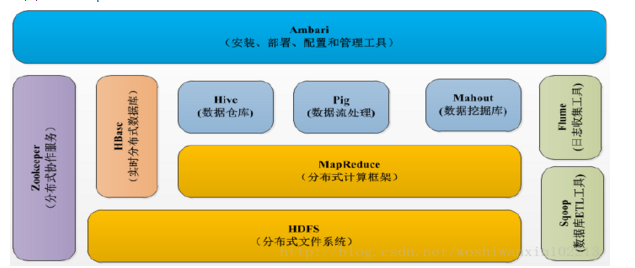
2、HDFS(Hadoop分布式文件系统)
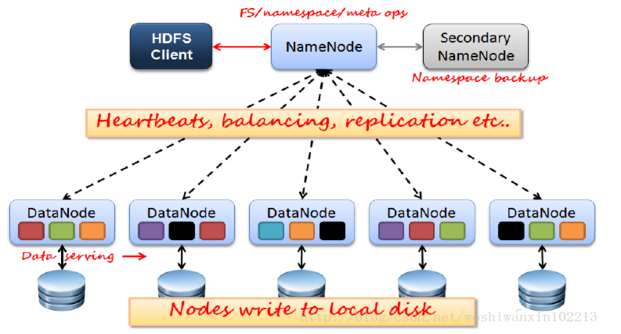
3、Mapreduce(分布式计算框架)
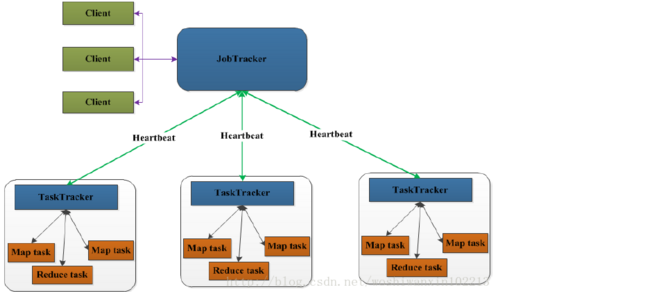

4、Hive(基于Hadoop的数据仓库)

5、Hbase(分布式列存数据库)
6、Zookeeper(分布式协作服务)
7、Sqoop(数据同步工具)
8、Pig(基于Hadoop的数据流系统)
9、Mahout(数据挖掘算法库)
10、Flume(日志收集工具)
hadoop 之Hadoop生态系统的更多相关文章
- [Hadoop 周边] Hadoop和大数据:60款顶级大数据开源工具(2015-10-27)【转】
说到处理大数据的工具,普通的开源解决方案(尤其是Apache Hadoop)堪称中流砥柱.弗雷斯特调研公司的分析师Mike Gualtieri最近预测,在接下来几年,“100%的大公司”会采用Hado ...
- Hadoop: Hadoop Cluster配置文件
Hadoop配置文件 Hadoop的配置文件: 只读的默认配置文件:core-default.xml, hdfs-default.xml, yarn-default.xml 和 mapred-defa ...
- [Linux][Hadoop] 将hadoop跑起来
前面安装过程待补充,安装完成hadoop安装之后,开始执行相关命令,让hadoop跑起来 使用命令启动所有服务: hadoop@ubuntu:/usr/local/gz/hadoop-$ ./sb ...
- Hadoop:搭建hadoop集群
操作系统环境准备: 准备几台服务器(我这里是三台虚拟机): linux ubuntu 14.04 server x64(下载地址:http://releases.ubuntu.com/14.04.2/ ...
- [Hadoop 周边] Hadoop资料收集【转】
原文网址: http://www.iteblog.com/archives/851 最直接的学习参考网站当然是官网啦: http://hadoop.apache.org/ Hadoop http:// ...
- hadoop数据[Hadoop] 实际应用场景之 - 阿里
上班之余抽点时间出来写写博文,希望对新接触的朋友有帮助.明天在这里和大家一起学习一下hadoop数据 Hadoop在淘宝和支付宝的应用从09年开始,用于对海量数据的离线处置,例如对日志的分析,也涉及内 ...
- Hadoop:Hadoop单机伪分布式的安装和配置
http://blog.csdn.net/pipisorry/article/details/51623195 因为lz的linux系统已经安装好了很多开发环境,可能下面的步骤有遗漏. 之前是在doc ...
- Hadoop:hadoop fs、hadoop dfs与hdfs dfs命令的区别
http://blog.csdn.net/pipisorry/article/details/51340838 'Hadoop DFS'和'Hadoop FS'的区别 While exploring ...
- Hadoop:Hadoop基本命令
http://blog.csdn.net/pipisorry/article/details/51223877 常用命令 启用hadoop start-dfs.sh start-hbase.sh 停止 ...
- 【云计算 Hadoop】Hadoop 版本 生态圈 MapReduce模型
忘的差不多了, 先补概念, 然后开始搭建集群实战 ... . 一 Hadoop版本 和 生态圈 1. Hadoop版本 (1) Apache Hadoop版本介绍 Apache的开源项目开发流程 : ...
随机推荐
- CAJ2PDF
该项目不成熟,很容易遇到转换失败的例子. https://github.com/JeziL/caj2pdf https://github.com/JeziL/caj2pdf/wiki caj2pdf ...
- eclipse使用lombok
1.下载lombok.jar,将lombok复制到eclipse的安装路径下,如图: 2.在eclipse.ini配置文件最后加入:-javaagent:D:\Program Files\Eclips ...
- Linux命令详解-rmdir
rmdir是常用的命令,该命令的功能是删除空目录,一个目录被删除之前必须是空的.(注意,rm - r dir命令可代替rmdir,但是有很大危险性.)删除某目录时也必须具有对父目录的写权限. 1.命令 ...
- 1-17-Linux中计划任务与日志的管理
本节所讲内容: 1-1 Linux中的计划任务 1-1-1 at计划任务的使用 1-1-2 cron 计划任务的使用 1-1 Linux服务器的日志管理 1-1-1 日志的种类和记录的方式 1-1-2 ...
- POJ 2891 中国剩余定理的非互质形式
中国剩余定理的非互质形式 任意n个表达式一对对处理,故只需处理两个表达式. x = a(mod m) x = b(mod n) km+a = b (mod n) km = (a-b)(mod n) 利 ...
- iOS Layout机制相关方法
iOS Layout机制相关方法 - (CGSize)sizeThatFits:(CGSize)size - (void)sizeToFit ——————- - (void)layoutSubview ...
- python进行linux系统监控
python进行linux系统监控 Linux系统下: 静态指标信息: 名称 描述 单位 所在文件 mem_total 内存总容量 KB /proc/meminfo disks 磁盘相关信息 - ...
- Linux 文件与目录管理,Linux系统用户组的管理
一.Linux 文件与目录管理 我们知道Linux的目录结构为树状结构,最顶级的目录为根目录 /. 其他目录通过挂载可以将它们添加到树中,通过解除挂载可以移除它们. 在开始本教程前我们需要先知道什 ...
- JavaScript---js的模块化
js的模块模式被定义为给类提供私有和公共封装的一种方法,也就是我们常说的“模块化”. 怎么实现“模块化”? 通过闭包的原理来实现“模块化” ,具体实现:1.必须有外部的封闭函数,该函数必须至少被调用 ...
- Django开发BUG "Model class WH_auth.models.User doesn't declare an explicit app_label and isn't in an application in INSTALLED_APPS."
当进行数据库迁移的时候发生问题,报错如下:RuntimeError: Model class WH_auth.models.User doesn't declare an explicit app_l ...