机器学习:PCA(人脸识别中的应用——特征脸)
一、思维理解
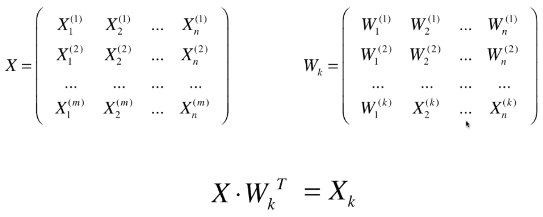
- X:原始数据集;
- Wk:原始数据集 X 的前 K 个主成分;
- Xk:n 维的原始数据降维到 k 维后的数据集;
- 将原始数据集降维,就是将数据集中的每一个样本降维:X(i) . WkT = Xk(i);
- 在人脸识别中,X 中的每一行(一个样本)就是一张人脸信息;
- 思维:其实 Wk 也有 n 列,如果将 Wk 的每一行看做一个样本,则第一行代表的样本为最重要的样本,因为它最能反映 X 中数据的分布,第二行为次重要的样本;在人脸识别中,X 中的每一行是一个人脸的图像,则 Wk 的每一行也可以理解为一个人脸图像,Wk 中的每一行代表的人脸图像就是特征脸。
- 之所以称 Wk 的每一行代表的人脸图像为特征脸,因为每一个特征脸对应一个主成分,它相当于表达了原始数据 X 中人脸数据所对应的特征。
二、特征脸
1)人脸数据集
- 获取
import numpy as np
import matplotlib.pyplot as plt from sklearn.datasets import fetch_lfw_people faces = fetch_lfw_people()
faces.keys()
# 输出:dict_keys(['data', 'images', 'target', 'target_names', 'DESCR']) faces.data.shape
# 输出:(3882, 2914) faces.images.shape
# 输出:(3882, 62, 47)
- fetcg_lfw_people:在 sklearn 中的封装的人脸识别数据集;
- faces:字典类型,其中 “target_names” 为每一个人脸样本对应的真实的人的姓名;
- (3882, 2914):数据集中共有 3882 张人脸,每张人脸有 2914 个特征;
- (3882, 62, 47):其中 62 * 47 = 2914,表示每张人脸都是 62 X 47 像素的图片;
- 从数据集 faces 中随机去除 36 张人脸样本,并绘制
随机抽取
# 对数据集faces.data 做乱序处理
random_indexes = np.random.permutation(len(faces.data))
X = faces.data[random_indexes] example_faces = X[:36]
example_faces.shape
# 输出:(36, 2914)绘制 n * n 张子图
def plot_faces(faces): fig, axes = plt.subplots(6, 6, figsize=(10, 10),
subplot_kw={'xticks':[], 'yticks':[]},
gridspec_kw=dict(hspace=0.1, wspace=0.1))
for i, ax in enumerate(axes.flat):
ax.imshow(faces[i].reshape(62, 47), cmap='bone') plt.show() plot_faces(example_faces)
2)特征脸
- faces.data 的所有主成分
from sklearn.decomposition import PCA # svd_solver='randomized':表示随机求取 pca,因为数据量较大,使用随机方式求解快些
# 此处没有指定 n_components,要求取所有主成分
pca = PCA(svd_solver='randomized')
pca.fit(X) pca.components_.shape
# 输出:(2914, 2914)
- svd_solver='randomized':表示随机求取 pca,使用随机方式求解速度更快;
- 绘制前 36 个特征脸
plot_faces(pca.components_[:36,:])

- 现象:排在前面的特征脸看上去相等笼统,从前到后,人脸样子越来越清晰;
- 要点一:通过特征脸,可以直观的看出在人脸识别的过程中,我们是怎么看到每一张人脸相应的特征的;
- 要点二:每一个人脸都是所有特征脸的线性组合,二特征脸依据重要程度,顺次的排列;
- 其它
faces2 = fetch_lfw_people(min_faces_per_person=50)
min_faces_per_person=30:数据集 fetch_lfw_people 中,同一个人名(target_names中的人名)至少用 30 个人脸图像,将这部分图像提取出来;
机器学习:PCA(人脸识别中的应用——特征脸)的更多相关文章
- 图像物体检測识别中的LBP特征
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/xinzhangyanxiang/article/details/37317863 图像物体检測识别中 ...
- Eigenface与PCA人脸识别算法实验
简单的特征脸识别实验 实现特征脸的过程其实就是主成分分析(Principal Component Analysis,PCA)的一个过程.关于PCA的原理问题,它是一种数学降维的方法.是为了简化问题.在 ...
- (转载)人脸识别中Softmax-based Loss的演化史
人脸识别中Softmax-based Loss的演化史 旷视科技 近期,人脸识别研究领域的主要进展之一集中在了 Softmax Loss 的改进之上:在本文中,旷视研究院(上海)(MEGVII Re ...
- 深度挖坑:从数据角度看人脸识别中Feature Normalization,Weight Normalization以及Triplet的作用
深度挖坑:从数据角度看人脸识别中Feature Normalization,Weight Normalization以及Triplet的作用 周翼南 北京大学 工学硕士 373 人赞同了该文章 基于深 ...
- 人脸识别中的重要环节-对齐之3D变换-Java版(文末附开源地址)
一.人脸对齐基本概念 人脸对齐通过人脸关键点检测得到人脸的关键点坐标,然后根据人脸的关键点坐标调整人脸的角度,使人脸对齐,由于输入图像的尺寸是大小不一的,人脸区域大小也不相同,角度不一样,所以要通过坐 ...
- 浅谈人脸识别中的loss 损失函数
浅谈人脸识别中的loss 损失函数 2019-04-17 17:57:33 liguiyuan112 阅读数 641更多 分类专栏: AI 人脸识别 版权声明:本文为博主原创文章,遵循CC 4.0 ...
- 知物由学 | 基于DNN的人脸识别中的反欺骗机制
"知物由学"是网易云易盾打造的一个品牌栏目,词语出自汉·王充<论衡·实知>.人,能力有高下之分,学习才知道事物的道理,而后才有智慧,不去求问就不会知道."知物 ...
- PCA人脸识别
人脸数据来自http://www.cl.cam.ac.uk/research/dtg/attarchive/facedatabase.html 实现代码和效果如下.由于图片数量有限(40*10),将原 ...
- 人脸识别中的Procruster analysis应用
本文中,我们通过Procrustes analysis来处理特征点,Procrustes analysis算法可以参考:http://en.wikipedia.org/wiki/Procrustes_ ...
随机推荐
- MongoDB快速入门(二)- 数据库
创建数据库 MongoDB use DATABASE_NAME 用于创建数据库.该命令如果数据库不存在,将创建一个新的数据库, 否则将返回现有的数据库. 语法 use DATABASE语句的基本语法如 ...
- window.open、window.showModalDialog和window.showModelessDialog 的区别[转]
一.前言 要打开一个可以载入页面的子窗口有三种方法,分别是window.open.window.showModalDialog和window.showModelessDialog. open方法就是打 ...
- Struts的url-pattern配置问题
一,servlet容器对url的匹配过程: 当一个请求发送到servlet容器的时候,容器先会将请求的url减去当前应用上下文的路径作为servlet的映射url,比如我访问的是http://loca ...
- centos下安装Anaconda
第一步:将下载好的Anaconda2-4.1.1-Linux-x86_64.sh软件传到linux下 第二步:[hadoop@spark1 ~]$ cd Desktop #进入到该软件所在目录,我的放 ...
- VC数据类型
不同编码格式下的字符串处理及相互转化: ◆ 大家在编程时经常遇到的数据类型:● Ansi:char.char * .const char *CHAR.(PCHAR.PSTR.LPSTR).LPCSTR ...
- QT Creator 代码自动补全
QT Creator 代码自动补全 用QT Creater编程,如果没有自动补全是很痛苦的事情,于是便查阅了QT的文档,发现CTRL+SPACE是自 动补全的快捷键;但是在 Creater里使用居然没 ...
- npm、模块暴露,小知识点区别
--save-dev与--save的区别 npm install xxx --save-dev 是指将包信息添加到 package.json 里的 devDependencies节点,表示开发时依赖的 ...
- 五一清北学堂培训之Day 3之DP
今天又是长者给我们讲小学题目的一天 长者的讲台上又是布满了冰红茶的一天 ---------------------------------------------------------------- ...
- WPF/WP/Silverlight/Metro App代码创建动画的思路
在2010年之前,我都是用Blend创建动画,添加触发器实现自动动画,后来写成代码创建的方式.如今Blend已经集成到Visual Studio安装镜像中了,最新的VS2015安装,Blend的操作界 ...
- mac上获取手机的uuid
把手机连上mac 终端中输入: system_profiler SPUSBDataType | grep "Serial Number:.*" 修改用 | sed s#" ...