机器学习:PCA(人脸识别中的应用——特征脸)
一、思维理解
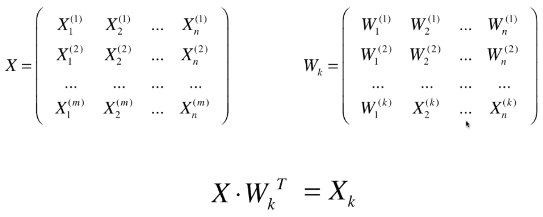
- X:原始数据集;
- Wk:原始数据集 X 的前 K 个主成分;
- Xk:n 维的原始数据降维到 k 维后的数据集;
- 将原始数据集降维,就是将数据集中的每一个样本降维:X(i) . WkT = Xk(i);
- 在人脸识别中,X 中的每一行(一个样本)就是一张人脸信息;
- 思维:其实 Wk 也有 n 列,如果将 Wk 的每一行看做一个样本,则第一行代表的样本为最重要的样本,因为它最能反映 X 中数据的分布,第二行为次重要的样本;在人脸识别中,X 中的每一行是一个人脸的图像,则 Wk 的每一行也可以理解为一个人脸图像,Wk 中的每一行代表的人脸图像就是特征脸。
- 之所以称 Wk 的每一行代表的人脸图像为特征脸,因为每一个特征脸对应一个主成分,它相当于表达了原始数据 X 中人脸数据所对应的特征。
二、特征脸
1)人脸数据集
- 获取
import numpy as np
import matplotlib.pyplot as plt from sklearn.datasets import fetch_lfw_people faces = fetch_lfw_people()
faces.keys()
# 输出:dict_keys(['data', 'images', 'target', 'target_names', 'DESCR']) faces.data.shape
# 输出:(3882, 2914) faces.images.shape
# 输出:(3882, 62, 47)
- fetcg_lfw_people:在 sklearn 中的封装的人脸识别数据集;
- faces:字典类型,其中 “target_names” 为每一个人脸样本对应的真实的人的姓名;
- (3882, 2914):数据集中共有 3882 张人脸,每张人脸有 2914 个特征;
- (3882, 62, 47):其中 62 * 47 = 2914,表示每张人脸都是 62 X 47 像素的图片;
- 从数据集 faces 中随机去除 36 张人脸样本,并绘制
随机抽取
# 对数据集faces.data 做乱序处理
random_indexes = np.random.permutation(len(faces.data))
X = faces.data[random_indexes] example_faces = X[:36]
example_faces.shape
# 输出:(36, 2914)绘制 n * n 张子图
def plot_faces(faces): fig, axes = plt.subplots(6, 6, figsize=(10, 10),
subplot_kw={'xticks':[], 'yticks':[]},
gridspec_kw=dict(hspace=0.1, wspace=0.1))
for i, ax in enumerate(axes.flat):
ax.imshow(faces[i].reshape(62, 47), cmap='bone') plt.show() plot_faces(example_faces)
2)特征脸
- faces.data 的所有主成分
from sklearn.decomposition import PCA # svd_solver='randomized':表示随机求取 pca,因为数据量较大,使用随机方式求解快些
# 此处没有指定 n_components,要求取所有主成分
pca = PCA(svd_solver='randomized')
pca.fit(X) pca.components_.shape
# 输出:(2914, 2914)
- svd_solver='randomized':表示随机求取 pca,使用随机方式求解速度更快;
- 绘制前 36 个特征脸
plot_faces(pca.components_[:36,:])

- 现象:排在前面的特征脸看上去相等笼统,从前到后,人脸样子越来越清晰;
- 要点一:通过特征脸,可以直观的看出在人脸识别的过程中,我们是怎么看到每一张人脸相应的特征的;
- 要点二:每一个人脸都是所有特征脸的线性组合,二特征脸依据重要程度,顺次的排列;
- 其它
faces2 = fetch_lfw_people(min_faces_per_person=50)
min_faces_per_person=30:数据集 fetch_lfw_people 中,同一个人名(target_names中的人名)至少用 30 个人脸图像,将这部分图像提取出来;
机器学习:PCA(人脸识别中的应用——特征脸)的更多相关文章
- 图像物体检測识别中的LBP特征
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/xinzhangyanxiang/article/details/37317863 图像物体检測识别中 ...
- Eigenface与PCA人脸识别算法实验
简单的特征脸识别实验 实现特征脸的过程其实就是主成分分析(Principal Component Analysis,PCA)的一个过程.关于PCA的原理问题,它是一种数学降维的方法.是为了简化问题.在 ...
- (转载)人脸识别中Softmax-based Loss的演化史
人脸识别中Softmax-based Loss的演化史 旷视科技 近期,人脸识别研究领域的主要进展之一集中在了 Softmax Loss 的改进之上:在本文中,旷视研究院(上海)(MEGVII Re ...
- 深度挖坑:从数据角度看人脸识别中Feature Normalization,Weight Normalization以及Triplet的作用
深度挖坑:从数据角度看人脸识别中Feature Normalization,Weight Normalization以及Triplet的作用 周翼南 北京大学 工学硕士 373 人赞同了该文章 基于深 ...
- 人脸识别中的重要环节-对齐之3D变换-Java版(文末附开源地址)
一.人脸对齐基本概念 人脸对齐通过人脸关键点检测得到人脸的关键点坐标,然后根据人脸的关键点坐标调整人脸的角度,使人脸对齐,由于输入图像的尺寸是大小不一的,人脸区域大小也不相同,角度不一样,所以要通过坐 ...
- 浅谈人脸识别中的loss 损失函数
浅谈人脸识别中的loss 损失函数 2019-04-17 17:57:33 liguiyuan112 阅读数 641更多 分类专栏: AI 人脸识别 版权声明:本文为博主原创文章,遵循CC 4.0 ...
- 知物由学 | 基于DNN的人脸识别中的反欺骗机制
"知物由学"是网易云易盾打造的一个品牌栏目,词语出自汉·王充<论衡·实知>.人,能力有高下之分,学习才知道事物的道理,而后才有智慧,不去求问就不会知道."知物 ...
- PCA人脸识别
人脸数据来自http://www.cl.cam.ac.uk/research/dtg/attarchive/facedatabase.html 实现代码和效果如下.由于图片数量有限(40*10),将原 ...
- 人脸识别中的Procruster analysis应用
本文中,我们通过Procrustes analysis来处理特征点,Procrustes analysis算法可以参考:http://en.wikipedia.org/wiki/Procrustes_ ...
随机推荐
- CentOS防火墙iptables-config的相关配置参数详解
默认/etc/sysoncifg/iptables-config的配置内容: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 2 ...
- java基础10(IO流)-字节流
IO流 输入与输出[参照物是程序] 如果从键盘.文件.网络甚至是另一个进程(程序或系统)将数据读入到程序或系统中,称为输入 如果是将程序或系统中的数据写到屏幕.硬件上的文件.网络上的另一端或者是一个进 ...
- spark学习2-1(hive1.2安装)
由于前面安装版本过老,导致学习过程中出现了很多问题,今天安装了一个新一点的版本.安装结束启动时遇到一点问题,记录在这里. 第一步:hive-1.2安装 通过WinSCP将apache-hive-1.2 ...
- Use default arguments instead of short circuiting or conditionals使用默认实参代替短路和条件
- 转 Nova: 虚机的块设备总结 [Nova Instance Block Device]
和物理机一样,虚拟机包括几个重要的部分:CPU.内存.磁盘设备.网络设备等.本文将简要总结虚机磁盘设备有关知识. 1. Nova boot CLI 中有关虚机块设备的几个参数 nova boot CL ...
- python基础3 - 变量的基本使用和命名
4.变量的基本使用 4.1 变量定义 在 Python 中,每个变量 在使用前都必须赋值,变量 赋值以后 该变量 才会被创建 等号(=)用来给变量赋值 = 左边是变量名 = 右边是存储在变量中的值 变 ...
- Redis缓存集群方案
由于单台Redis服务器的内存管理能力有限,使用过大内存的Redis又会使得服务器的性能急剧下降,一旦服务器发生故障将会影响更大范围业务,而Redis 3.0 beta1支持的集群功能还不适合生产环境 ...
- msdn - Developer Library(包括wpf)重要程度——5星*****
https://msdn.microsoft.com/zh-cn/library/ms754242(v=vs.110).aspx https://msdn.microsoft.com/zh-cn/li ...
- "阿拉伯""伊斯兰""穆斯林"三个概念怎么分?
伊斯兰.阿拉伯.穆斯林这三个概念到底有什么不同?要言君将用五分钟给您概述这三个概念,并厘清其边界,说明其交集,帮您迅速构建"阿拉伯.伊斯兰.穆斯林"知识结构概图.相信您得沉思一下费 ...
- url字符串中含中文的转码方法
凡是用get方法的,url里含中文的,都需要调用上面的函数进行编码.要不然会被当成二进制截断. //URL编码 +(NSString*)urlEncode:(NSString *)str { int ...