tcpreplay 缓存算法研究
一. 缓存算法
1.1 算法目的
流量拆分算法的运算会明显影响包的发送速率,为了提高发送速率, tcpreplay 使用了缓存机制,该部分代码也封装在tcpprep工具里,运行 tcpprep (tcp-preparation)工具,结果是一个针对性的缓存文件,该文件存放流量拆分算法的运算结果。同时,cache.c 存放了部分读取cachefile的函数。
1.2 算法思想
如何设计符合目的的缓存?达到即高效又节省?
最简单就是使用bool[SIZE] ,存放 0和1,这样的数据结构使用1个字节存放标识,可以表示2个方向的流量。但是用1个字节表示一个packet完全没必要,可以用1个bit表示一个packet。用如下方法可以做到:
使用一个比特位表示一个packet 的方法
包的id: packetid
Index = packetid/8
Bit = packetid%8
Byte = &Cache[Index]
写缓存: *Byte = *Byte + (1<<Bit)
读缓存: result = Cache[Index] & (char)(1 << Bit)
上述方法依然不完善,第一,pcap 包包含的 packets 的数量是未知的,用固定的 char 数组存放不够灵活。其二,如果缓存结果需要扩展,比如在‘客户端->服务端’‘服务端->客户端’两种packets状态之外,还有‘发送’‘不发送’(表示该packet发送与否),‘正确’‘错误’(表示该packet是否异常)等状态运算结果,上述算法无法扩展。
解决第一个问题,是使用数组链表的方式取代单一数组的方式。每个链表节点存放一个可配的小数组,当当前节点数组空间不够的时候,再生成一个小数组,连在链表后面。这样的缓存,可以根据具体的packets 数灵活得分配空间。
解决第二个问题,是设定一个参数 packets_per_byte ,表示一个字节可以容纳多少packets缓存信息,只有2种状态时该参数值为 8 ,表示4种状态时该参数值为 4。6 种状态值是2,以此类推。packets_per_byte = 1 时,1 个字节可以最多表示 16 种缓存状态。
Tcpprep3.4.4使用2个bit表示一个packet,下面是这种情况下算法思想的图形表示:
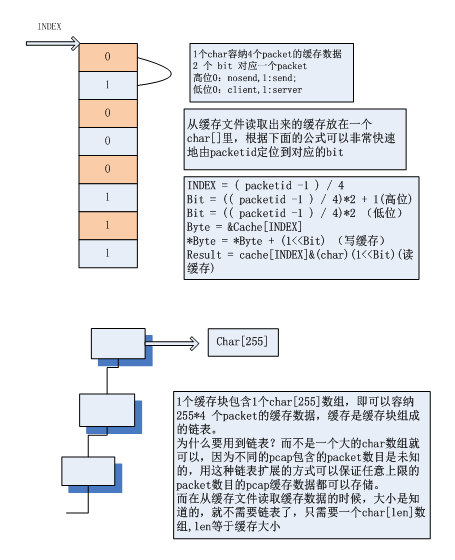
1.1 算法流程
使用缓存以及不使用缓存两种情况下的发包流程。
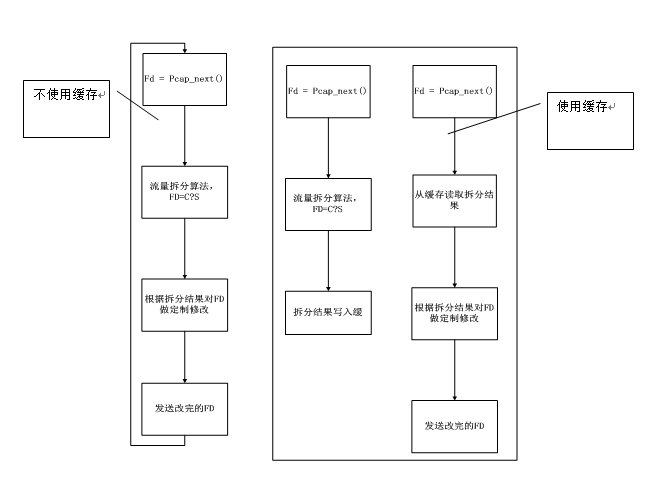
1.1 算法实现
1.1.1 数据结构
struct tcpr_cache_s { /*一个缓存节点的数据结构*/
char data[CACHEDATASIZE]; /*该节点的小数组*/
unsigned int packets; /*该节点已经存放缓存结果的packet的数目*/
struct tcpr_cache_s *next; /*链表指针*/
};
typedef struct tcpr_cache_s tcpr_cache_t;
struct tcpr_cache_file_hdr_s {/*缓存文件头数据结构*/
char magic[8]; /*文件标识*/
char version[4]; /*缓存版本*/
u_int64_t num_packets; /* total # of packets in file */
u_int16_t packets_per_byte; /*每个字节存放多少个packet的缓存数据*/
u_int16_t comment_len; /* how long is the user comment? */
} __attribute__((__packed__));
enum tcpr_dir_e { /*缓存运算结果种类*/
TCPR_DIR_ERROR = -1,/*异常packet,该状态没有加入缓存,而是作为返回值*/
TCPR_DIR_NOSEND = 0, /*是否发送*/
TCPR_DIR_C2S = 1, /* 客户端->服务器,从 PRIMARY 接口回放*/
TCPR_DIR_S2C = 2 /* 服务器->客户端,从SECONDARY接口回放 */
};
typedef enum tcpr_dir_e tcpr_dir_t;
1.1.2 主要函数实现
/**
*生成1个packet的缓存数据
*/
tcpr_dir_t
add_cache(tcpr_cache_t ** cachedata, const int send, const tcpr_dir_t interface)
{
static tcpr_cache_t *lastcache = NULL;
u_char *byte = NULL;
u_int32_t bit;
tcpr_dir_t result = TCPR_DIR_ERROR;
COUNTER index;
if (*cachedata == NULL) { /* 第一次运行,生成第一个节点 */
*cachedata = new_cache();
lastcache = *cachedata;
}
else {
if ((lastcache->packets + 1) > (CACHEDATASIZE *CACHE_PACKETS_PER_BYTE)) { /* 当前节点如果满了,生成一个新节点*/
lastcache->next = new_cache();
lastcache = lastcache->next;
}
}
lastcache->packets++;
if (send == SEND) { /* 是否发送的标志位赋值*/
index = (lastcache->packets - 1) / (COUNTER)CACHE_PACKETS_PER_BYTE;
bit = (((lastcache->packets - 1) % (COUNTER)CACHE_PACKETS_PER_BYTE) *
(COUNTER)CACHE_BITS_PER_PACKET) + 1;
byte = (u_char *) & lastcache->data[index];
*byte += (u_char) (1 << bit);
/* if true, set low order bit. else, do squat */
if (interface == TCPR_DIR_C2S) {/*流量方向的标志位赋值*/
*byte += (u_char)(1 << (bit - 1));
result = TCPR_DIR_C2S;
}
else { result = TCPR_DIR_S2C; }
}
else { result = TCPR_DIR_NOSEND; /*异常情况,结果返回异常*/ }
return result;
}
/**
* 下面函数显示如何根据packet id 读取缓存结果
*/
tcpr_dir_t
check_cache(char *cachedata, COUNTER packetid)
{
COUNTER index = 0;
u_int32_t bit;
if (packetid == 0) err(-1, "packetid must be > 0");
/* 定位到缓存数组的具体位 */
index = (packetid - 1) / (COUNTER)CACHE_PACKETS_PER_BYTE;
bit = (u_int32_t)(((packetid - 1) % (COUNTER)CACHE_PACKETS_PER_BYTE) *(COUNTER)CACHE_BITS_PER_PACKET) + 1;
if (!(cachedata[index] & (char)(1 << bit))) {
return TCPR_DIR_NOSEND; /*返回是否发送的标志位结果*/
}
/* go back a bit to get the interface */
bit--;
if (cachedata[index] & (char)(1 << bit)) { return TCPR_DIR_C2S; }
else { return TCPR_DIR_S2C; } /*返回流量方向结果*/
return TCPR_DIR_ERROR; /*如果上述情况都没发送,返回异常*/
}
1.2 实验结果
1.2.1 实验1
拥有14个packet的pcap生成的缓存文件

tcpreplay 缓存算法研究的更多相关文章
- tcpreplay 流量拆分算法研究
1.1 算法目的 现在网络架构一般是Client-Server架构,所以网络流量一般是分 C-S 和 S-C 两个方向.tcpdump等抓包工具获取的pcap包,两个流向的数据没有被区分.流量方向的 ...
- Akamai在内容分发网络中的算法研究(翻译总结)
作者 | 钱坤 钱坤,腾讯后台开发工程师,从事领域为流媒体CDN相关,参与腾讯TVideo平台开发维护. 原文是<Algorithmic Nuggets in Content Delivery& ...
- 静态频繁子图挖掘算法用于动态网络——gSpan算法研究
摘要 随着信息技术的不断发展,人类可以很容易地收集和储存大量的数据,然而,如何在海量的数据中提取对用户有用的信息逐渐地成为巨大挑战.为了应对这种挑战,数据挖掘技术应运而生,成为了最近一段时期数据科学的 ...
- 算法进阶面试题06——实现LFU缓存算法、计算带括号的公式、介绍和实现跳表结构
接着第四课的内容,主要讲LFU.表达式计算和跳表 第一题 上一题实现了LRU缓存算法,LFU也是一个著名的缓存算法 自行了解之后实现LFU中的set 和 get 要求:两个方法的时间复杂度都为O(1) ...
- Working Set缓存算法(转)
为了加深对缓存算法的理解,特转此篇,又由于本文内容过多,故不做翻译,原文地址Working Set页面置换算法 In the purest form of paging, processes are ...
- Android ImageCache图片缓存,使用简单,支持预取,支持多种缓存算法,支持不同网络类型,扩展性强
本文主要介绍一个支持图片自动预取.支持多种缓存算法的图片缓存的使用及功能.图片较大需要SD卡保存情况推荐使用ImageSDCardCache. 与Android LruCache相比主要特性:(1). ...
- 缓存算法之belady现象
前言 在使用FIFO算法作为缺页置换算法时,分配的缺页增多,但缺页率反而提高,这样的异常现象称为belady Anomaly. 虽然这种现象说明的场景是缺页置换,但在运用FIFO算法作为缓存算法时,同 ...
- android上的缓存、缓存算法和缓存框架
1.使用缓存的目的 缓存是存取数据的临时地,因为取原始数据代价太大了,加了缓存,可以取得快些.缓存可以认为是原始数据的子集,它是从原始数据里复制出来的,并且为了能被取回,被加上了标志. 在andr ...
- java缓存算法【转】
http://my.oschina.net/u/866190/blog/188712 提到缓存,不得不提就是缓存算法(淘汰算法),常见算法有LRU.LFU和FIFO等算法,每种算法各有各的优势和缺点及 ...
随机推荐
- C# 窗口关闭事件
首先添加一个退出事件函数 //退出按键 private void Form1_FormClosing(object sender, FormClosingEventArgs e) { DialogRe ...
- 笔记-python-lib-contextlib
笔记-python-lib-contextlib 1. contextlib with 语句很好用,但不想每次都写__enter_-和__exit__方法: py标准库也为此提供了工具模块c ...
- linux c scanf()小解
今天学习了新的内容,关于c语言的scanf()函数. scanf()函数,读取指定格式的值赋值给相应变量.空格(‘ ‘),回车('\n'),TAB是分隔符,轻易不会被读取.还有,该函数的返回值是正确读 ...
- 设计模式--单例模式Singleton
单例模式顾名思义整个程序下只有一个实例,例如一个国家只有一个皇帝,一个军队只有一个将军.单例模式的书写又分为饿汉模式和懒汉模式 饿汉模式 类中代码 package demo; public cla ...
- ThinkPad 触控板双指不可以滑动
我一直在想为什么,今天我想禁用触摸板的时候,我找到原因了. 是因为没有装驱动. http://think.lenovo.com.cn/support/driver/newdriversdownlist ...
- jQuery的.on方法
jQuery on()方法是官方推荐的绑定事件的一个方法. $(selector).on(event,childSelector,data,function,map)由此扩展开来的几个以前常见的方法有 ...
- gettid 和pthread_self的区别
转: Linux中,每个进程有一个pid,类型pid_t,由getpid()取得.Linux下的POSIX线程也有一个id,类型 pthread_t,由pthread_self()取得,该id由线程库 ...
- 【java并发编程实战】第二章:对象的共享
1.重要的属性 可见性,不变性,原子性 1.1可见性 当一个线程修改某个对象状态的时候,我们希望其他线程也能看到发生后的变化. 在没有同步的情况下,编译器和处理器会对代码的执行顺序进行重排.以提高效率 ...
- 孤荷凌寒自学python第六十五天学习mongoDB的基本操作并进行简单封装4
孤荷凌寒自学python第六十五天学习mongoDB的基本操作并进行简单封装4 (完整学习过程屏幕记录视频地址在文末) 今天是学习mongoDB数据库的第十一天. 今天继续学习mongoDB的简单操作 ...
- 椭圆曲线加密和rsa对比
最近在导师的要求下接手了基于欧洲标准的车联网项目中的安全层,需要学习密码学,以及网络安全的相关内容,这里做一个总结 引用的大部分内容为一个西安的大佬(哈哈我老家也是西安的),大佬主页:https:// ...