快速构建大数据存储分析平台-ELK平台安装
一、概述
ELK是由Elastic公司开发的Elasticsearch、Logstash、Kibana三款开源软件的缩写(但不限于这三款软件)。
为什么使用ELK?
在目前流行的微服务架构中,一个大型应用可能会被划分成几十甚至上百个微服务,这些微服务产生的日志也会分布在不同的服务器不同的目录下,按常规方式进行日志检查你会频繁登录每台服务器查找日志,所以你可能需要一个集中化的日志管理平台。
如果要对这些日志进行数据分析,常规方式可采用hadoop或spark等大数据技术手段来进行数据分析,但终究这些方式需要编写代码和相关专业知识,时间、人力成本略高,所以你可能需要一个开箱即用的搜索、聚合、可视化的数据分析平台。
综上所述,ELK首先是一个集中化日志管理平台,但同时也是一个快速的可视化数据分析平台。
架构选择
ELK架构很灵活,不同的架构适合不同的场景。
在文章末尾提供了一个链接,可作为不同架构方式的参考。
二、服务架构
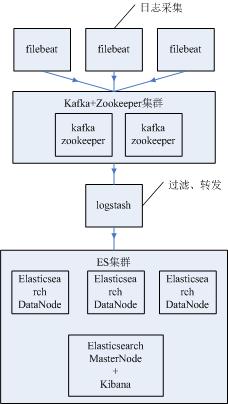
上图中分为4层,含义如下:
1、filebeat日志采集端,采集日志并将日志发送到kafka;
2、kafka+zookeeper集群,用于中转、缓冲海量日志;
3、logstash从kafka中拉取日志,并过滤、转发到elasticsearch中;
4、elasticsearch集群,用于存储日志;kibana将海量日志可视化展示、统计;
三、服务器\软件准备
| 服务器ip | 192.168.1.101 | 192.168.1.102 | 192.168.1.103 | 192.168.1.104 | 192.168.1.105 | 192.168.1.106 | 192.168.1.107 | 192.168.1.108 |
| 安装软件 | filebeat | kafka+zookeeper | kafka+zookeeper | logstash | elasticsearch dataNode | elasticsearch dataNode | elasticsearch dataNode | elasticsearch masterNode+kibana |
一共涉及6个软件包
四、软件安装
1、安装zookeeper
192.168.1.102、192.168.1.103两台服务器分别安装配置zookeeper集群
#安装目录/usr/local/zookeeper-3.4.13
>tar -zxvf zookeeper-3.4.13.tar.gz -C /usr/local/
>cd /usr/local/zookeeper-3.4.13/conf/
>cp zoo_sample.cfg zoo.cfg
>vim zoo.cfg
#修改以下配置
dataDir=/usr/local/zookeeper-3.4.13/zookeeper
server.1=192.168.1.102:12888:13888
server.2=192.168.1.103:12888:13888 #server.1执行(重要)
>echo 1 > /usr/local/zookeeper-3.4.13/zookeeper/myid
#server.2执行(重要)
>echo 2 > /usr/local/zookeeper-3.4.13/zookeeper/myid #两台服务器分别启动zookeeper
>cd /usr/local/zookeeper-3.4.13/bin/
>./zkServer.sh start
>netstat -lntp |grep 2181
2、安装kafka
192.168.1.102、192.168.1.103两台服务器分别安装配置kafka
#解压到/usr/local/kafka_2.11-2.0.1
>tar -zxvf kafka_2.11-2.0.1.tgz -C /usr/local/kafka_2.11-2.0.1
>cd /usr/local/kafka_2.11-2.0.1/config/
#修改以下配置文件
#注:两台服务器中broker.id、host.name需分别配置
>vim server.properties
broker.id=1
port = 9092
host.name = 192.168.1.102
log.dirs=/var/log/kafka
log.retention.hours=1
zookeeper.connect=192.168.1.102:2181,192.168.1.103:2181
default.replication.factor=2 #启动kafka服务,两台服务器中分别启动
>cd /usr/local/kafka_2.11-2.0.1/config
>./kafka-server-start.sh -daemon ../config/server.properties
验证kafka队列服务,正常情况下在生产者端输入数据并发送,消费者端会收到并打印数据
#创建消息主题
>./kafka-topics.sh --create --zookeeper 192.168.1.102:2181 --replication-factor 1 --partitions 2 --topic logs
#创建消息生产者
>./kafka-console-producer.sh --broker-list 192.168.1.102:9092 --topic logs
#创建消息消费者
>./kafka-console-consumer.sh --bootstrap-server 192.168.1.102:9092 --topic logs
3、安装logstash
192.168.1.104安装配置logstash
#通过rpm安装logstash
>rpm -ivh logstash-6.0.0.rpm
#配置数据的输入输出
>vim /etc/logstash/conf.d/syslog.conf
input {
kafka {
bootstrap_servers => "localhost:9092"
topics => ["logs"]#使用上文中创建的消息主题
}
} output {
elasticsearch {
hosts => ["localhost:9200"]
index => "logs-%{+YYYY.MM.dd}"
}
}
#启动服务
>systemctl start logstash
4、安装elasticsearch
192.168.1.108安装配置elasticsearch
#使用rpm方式安装软件
>rpm -ivh elasticsearch-6.0.0.rpm
#编辑配置
>vim /etc/elasticsearch/elasticsearch.yml
cluster.name: master-node # 集群中的名称
node.name: master # 该节点名称
node.master: true # 意思是该节点为主节点
node.data: false # 表示这不是数据节点
network.host: 0.0.0.0 # 监听全部ip,在实际环境中应设置为一个安全的ip
http.port: 9200 # es服务的端口号
discovery.zen.ping.unicast.hosts: ["192.168.1.105", "192.168.1.106", "192.168.1.107", "192.168.1.108"] # 配置自动发现
#启动服务
>systemctl start elasticsearch
#验证
>ps aux |grep elasticsearch
>curl 'localhost:9200/_cluster/health?pretty'
注:"192.168.1.105", "192.168.1.106", "192.168.1.107" 按照同样方法安装配置,但需要修改node.name、node.master改为false、node.data改为true
5、安装kibana
192.168.1.108安装配置kibana
>rpm -ivh kibana-6.0.0-x86_64.rpm
#编辑配置
>vim /etc/kibana/kibana.yml
elasticsearch.url: "http://192.168.1.108:9200"
logging.dest: /var/log/kibana.log #创建日志文件
>touch /var/log/kibana.log
>chmod 777 /var/log/kibana.log #启动服务
>systemctl start kibana #验证服务
>ps aux |grep kibana
>netstat -lntp |grep 5601
至此,服务架构中第2、3、4层已安装完毕
6、安装filebeat(日志采集端)
192.168.1.101安装配置filebeat
>rpm -ivh filebeat-6.0.0-x86_64.rpm
#修改或增加以下配置文件
>vi /etc/filebeat/filebeat.yml filebeat.prospectors:
- type: log
enabled: true
paths:
- /opt/*.out #日志目录 #日志数据输出到kafka
output.kafka:
enabled: true
hosts: ["172.17.224.159:9092"]
topic: ecplogs #启动并验证服务
>systemctl start filebeat
>ps axu |grep filebeat
五、验证
用浏览器打开kibana:http://192.168.1.108:5601
安装工作告一段落
参考博客:
Elastic Stack的演进
快速构建大数据存储分析平台-ELK平台安装的更多相关文章
- 大数据 -- Cloudera Manager(简称CM)+CDH构建大数据平台
一.Cloudera Manager介绍 Cloudera Manager(简称CM)是Cloudera公司开发的一款大数据集群安装部署利器,这款利器具有集群自动化安装.中心化管理.集群监控.报警等功 ...
- CDH构建大数据平台-配置集群的Kerberos认证安全
CDH构建大数据平台-配置集群的Kerberos认证安全 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 当平台用户使用量少的时候我们可能不会在一集群安全功能的缺失,因为用户少,团 ...
- 在HDInsight中从Hadoop的兼容BLOB存储查询大数据的分析
在HDInsight中从Hadoop的兼容BLOB存储查询大数据的分析 低成本的Blob存储是一个强大的.通用的Hadoop兼容Azure存储解决方式无缝集成HDInsight.通过Hadoop分布式 ...
- CDH构建大数据平台-使用自建的镜像地址安装Cloudera Manager
CDH构建大数据平台-使用自建的镜像地址安装Cloudera Manager 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.搭建CM私有仓库 详情请参考我的笔记: http ...
- CDH构建大数据平台-Kerberos高可用部署【完结篇】
CDH构建大数据平台-Kerberos高可用部署[完结篇] 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.安装Kerberos相关的软件包并同步配置文件 1>.实验环境 ...
- Storm 实战:构建大数据实时计算
Storm 实战:构建大数据实时计算(阿里巴巴集团技术丛书,大数据丛书.大型互联网公司大数据实时处理干货分享!来自淘宝一线技术团队的丰富实践,快速掌握Storm技术精髓!) 阿里巴巴集团数据平台事业部 ...
- SpringBoot构建大数据开发框架
http://blog.51cto.com/yixianwei/2047886 为什么使用SpringBoot 1.web工程分层设计,表现层.业务逻辑层.持久层,按照技术职能分为这几个内聚的部分,从 ...
- MapGis如何实现WebGIS分布式大数据存储的
作为解决方案厂商,MapGis是如何实现分布式大数据存储的呢? MapGIS在传统关系型空间数据库引擎MapGIS SDE的基础之上,针对地理大数据的特点,构建了MapGIS DataStore分布式 ...
- Sqlserver 高并发和大数据存储方案
Sqlserver 高并发和大数据存储方案 随着用户的日益递增,日活和峰值的暴涨,数据库处理性能面临着巨大的挑战.下面分享下对实际10万+峰值的平台的数据库优化方案.与大家一起讨论,互相学习提高! ...
随机推荐
- 创建型设计模式之建造者模式(Builder)
结构 意图 将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示. 适用性 当创建复杂对象的算法应该独立于该对象的组成部分以及它们的装配方式时. 当构造过程必须允许被构造的对象有不 ...
- Centos 6.3nginx安装
1. 增加源: vi /etc/yum.repos.d/nginx.repo CentOS: [nginx] name=nginx repo baseurl=http://nginx.org/pack ...
- 请求路径@PathVariable与请求参数@RequestParam的区别
转自:http://www.iteye.com/problems/101566: http://localhost:8080/Springmvc/user/page.do?pageSize=3& ...
- NetStream论文
https://max.book118.com/html/2016/0102/32573670.shtm http://www.docin.com/p-1568348795.html
- POJ 2524 Ubiquitous Religions (并查集)
Description 当今世界有很多不同的宗教,很难通晓他们.你有兴趣找出在你的大学里有多少种不同的宗教信仰.你知道在你的大学里有n个学生(0 < n <= 50000).你无法询问每个 ...
- Cookie和Session在Node.JS中的实践(二)
Cookie和Session在Node.JS中的实践(二) cookie篇在作者的上一篇文章Cookie和Session在Node.JS中的实践(一)已经是写得算是比较详细了,有兴趣可以翻看,这篇是s ...
- sort equal 确保记录按照 input顺序来
Usually you have a requirement of removing the duplicate records from a file using SORT with the opt ...
- 分享最新申请IDP账号的过程,包含duns申请的分享(2013年6月)
5月份接到公司要申请开发者账号的任务,就一直在各个论坛找申请的流程,但都是一些09年10年的比较旧的流程,现在都已经不适用了,好不容易找到2012年分享的流程吧,才发现申请过程中少了DUNS编码的步骤 ...
- Tiny 6410的Linux学习总结!
1.Tiny6410的Linux系统修改IP地址: vi /etc/eth0-setting 2.Ubuntu14.04自动以root身份登录系统: /etc/lightdm/lig ...
- Vue.js 2.0源码解析之前端渲染篇
一.前言 Vue.js框架是目前比较火的MVVM框架之一,简单易上手的学习曲线,友好的官方文档,配套的构建工具,让Vue.js在2016大放异彩,大有赶超React之势.前不久Vue.js 2.0正式 ...