关于embedding-深度学习基本操作 【Word2vec, Item2vec,graph embedding】
https://zhuanlan.zhihu.com/p/26306795
https://arxiv.org/pdf/1411.2738.pdf
https://zhuanlan.zhihu.com/p/53194407
https://zhuanlan.zhihu.com/p/58805184 embedding入门到精通的paper,包括graph embedding
Word2Vec算法原理:
skip-gram: 用一个词语作为输入,来预测它周围的上下文
cbow: 拿一个词语的上下文作为输入,来预测这个词语本身
Skip-gram 和 CBOW 的简单情形:
当上下文只有一个词时,语言模型就简化为:用当前词 x 预测它的下一个词 y
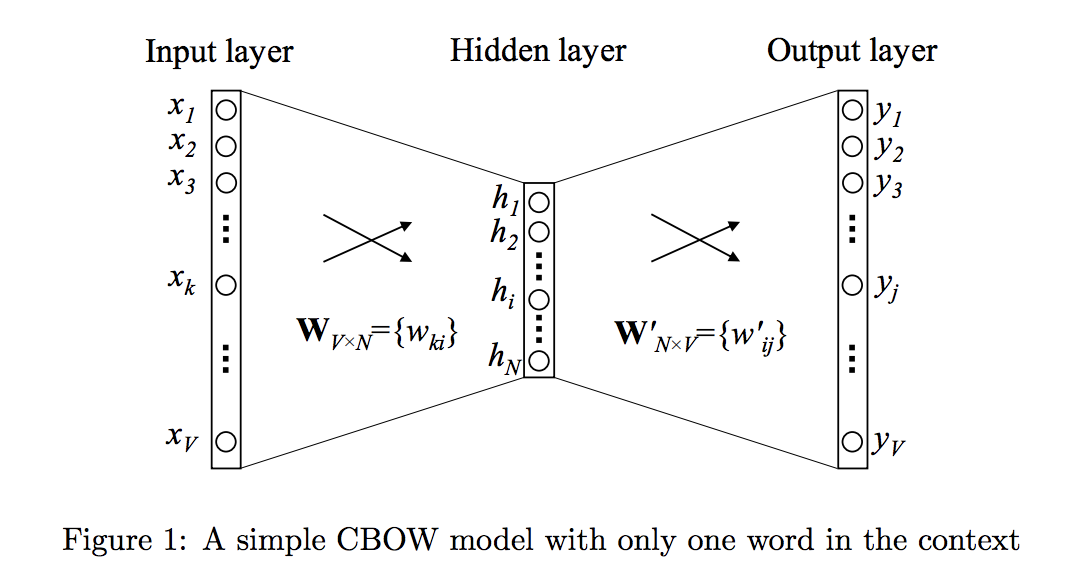
V是词库中词的数量,$x$ 是one-hot encoder 形式的输入,$y$ 是在这 V 个词上输出的概率。
隐层的激活函数是线性的,相当于没做任何处理(这也是 Word2vec 简化之前语言模型的独到之处)。当模型训练完后,最后得到的其实是神经网络的权重【输入层到隐层、隐层到输出层】,这就是生成的词向量,词向量的维度等于隐层的节点数。注意,由输入层到隐层的网络权重(输入向量)以及隐层到输出层的网络权重(输出向量)均可以作为词向量,一般我们用“输入向量”。
需要提到一点的是,这个词向量的维度(与隐含层节点数一致)一般情况下要远远小于词语总数 V 的大小,所以 Word2vec 本质上是一种降维操作—把词语从 one-hot encoder 形式的表示降维到 Word2vec 形式的表示。
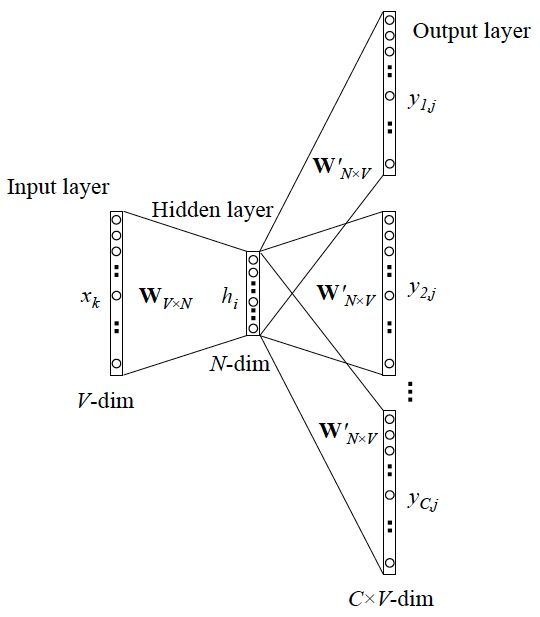
Skip-gram更一般的情形:
当 y 有多个词时,网络结构如下:
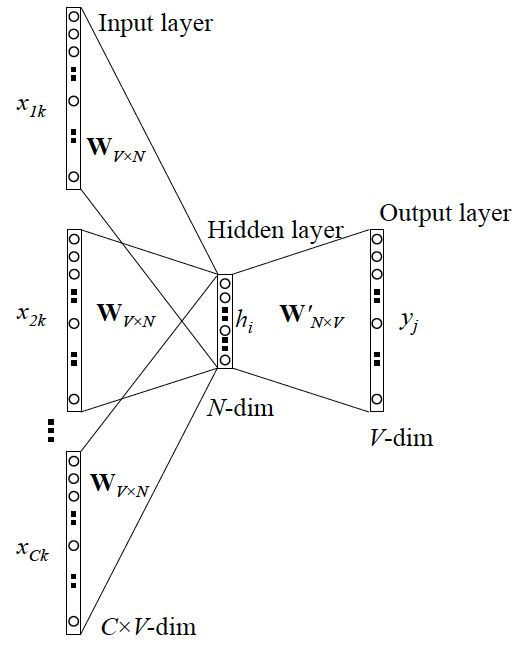
CBOW更一般的情形:
网络结构如下:
Word2vec 的训练trick
Word2vec 本质上是一个语言模型,它的输出节点数是 V 个,对应了 V 个词语,本质上是一个多分类问题,但实际当中,词语的个数非常非常多,会给计算造成很大困难,所以需要用技巧来加速训练。
hierarchical softmax:本质是把 N 分类问题变成 log(N)次二分类
negative sampling:本质是预测总体类别的一个子集
https://zhuanlan.zhihu.com/p/27234078 <= 这里阐述了word2vec样本相关的细节,非常好
如何构建训练集?
基于成对的单词来对神经网络进行训练,训练样本是 ( input word, output word ) 这样的单词对(采集自原始的句子),input word和output word都是one-hot编码的向量, 最终模型的输出是一个概率分布.
假设我们拥有10000个单词的词汇表,我们如果想嵌入300维的词向量,那么我们的输入-隐层权重矩阵和隐层-输出层的权重矩阵都会有 10000 x 300 = 300万个权重,在如此庞大的神经网络中进行梯度下降是相当慢的。更糟糕的是,你需要大量的训练数据来调整这些权重并且避免过拟合。百万数量级的权重矩阵和亿万数量级的训练样本意味着训练这个模型将会是个灾难。
解决方案:
- 将常见的单词组合(word pairs)或者词组作为单个“words”来处理。
- 对高频次单词进行抽样来减少训练样本的个数。基本思想:对于我们在训练原始文本中遇到的每一个单词,它们都有一定概率被我们从文本中删掉,而这个被删除的概率与单词的频率有关。
- 对优化目标采用“negative sampling(负采样)”方法,这样每个训练样本的训练只会更新一小部分的模型权重,从而降低计算负担。
当我们用训练样本 ( input word: "fox",output word: "quick") 来训练我们的神经网络时,“ fox”和“quick”都是经过one-hot编码的。如果我们的vocabulary大小为10000时,在输出层,我们期望对应“quick”单词的那个神经元结点输出1,其余9999个都应该输出0。在这里,这9999个我们期望输出为0的神经元结点所对应的单词我们称为“negative” word。
当使用负采样时,我们将随机选择一小部分的negative words(比如选5个negative words)来更新对应的权重。我们也会对我们的“positive” word进行权重更新(在我们上面的例子中,这个单词指的是”quick“)。
回忆一下我们的隐层-输出层拥有300 x 10000的权重矩阵。如果使用了负采样的方法我们仅仅去更新我们的positive word-“quick”的和我们选择的其他5个negative words的结点对应的权重,共计6个输出神经元,相当于每次只更新300 * 6 = 1800个权重。对于3百万的权重来说,相当于只计算了0.06%的权重,这样计算效率就大幅度提高。
如何选择negative words?
一个单词被选作negative sample的概率跟它出现的频次有关,出现频次越高的单词越容易被选作negative words。每个单词被赋予一个权重,即, 它代表着单词出现的频次,概率公式:
公式相关:https://www.cnblogs.com/pinard/p/7249903.html#!comments
Negative Sampling也是采用了二元逻辑回归来求解模型参数,通过负采样,我们得到了neg个负例$ (context(w_0), w_i), i = 1, 2...neg $。为了统一描述,我们将正例定义为$w_0$。
在逻辑回归中,我们的正例应该期望满足: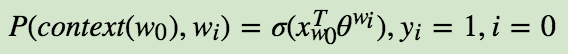
我们的负例期望满足: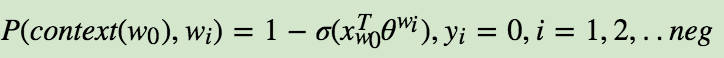
我们期望可以最大化下式: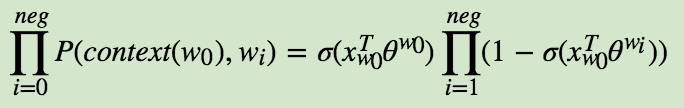
模型的似然函数为: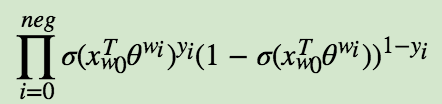
此时对应的对数似然函数为: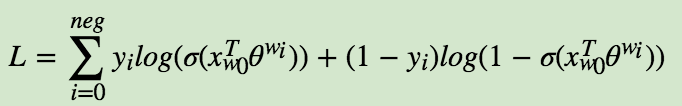
首先我们计算$\theta^{w_i}$的梯度:
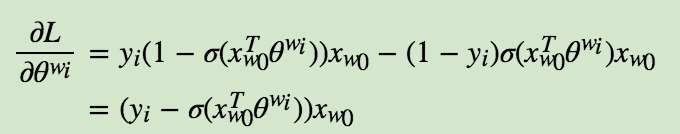
$x_{w_0}$的梯度如下:
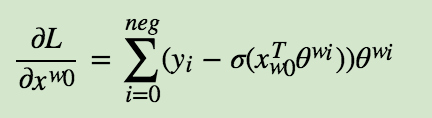
Item2vec算法原理
Item2vec中把用户浏览的商品集合等价于word2vec中的word的序列,即句子(忽略了商品序列空间信息spatial information),出现在同一个集合的商品对视为 positive。缺点:1、忽略了user行为序列信息; 2、没有建模用户对不同item的喜欢程度高低。
Graph Embedding算法原理
基于word2vec的一系列embedding方法主要是基于序列进行embedding,在当前商品、行为、用户等实体之间的关系越来越复杂化、网络化的趋势下,原有sequence embedding方法的表达能力受限,因此Graph Embedding方法的研究和应用成为了当前的趋势。
DeepWalk 算法:
DeepWalk的思想类似word2vec,使用图中节点与节点的共现关系来学习节点的向量表示。那么关键的问题就是如何来描述节点与节点的共现关系,DeepWalk给出的方法是使用随机游走(RandomWalk)的方式在图中进行节点采样。
RandomWalk是一种可重复访问已访问节点的深度优先遍历算法。给定当前访问起始节点,从其邻居中随机采样节点作为下一个访问节点,重复此过程,直到访问序列长度满足预设条件。
获取足够数量的节点访问序列后,使用skip-gram model 进行向量学习。
阿里论文阅读:http://d0evi1.com/aliembedding/
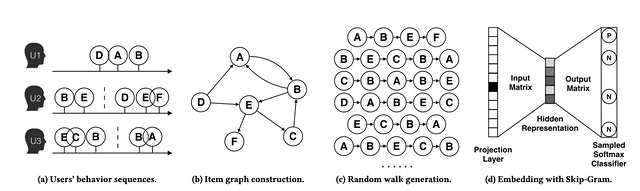
淘宝graph embedding总览: a) 用户行为序列:用户u1对应一个session,u2和u3分别各对应一个session;这些序列被用于构建item graph;b) 有向加权item graph $G = (V, E)$;c) 在item graph上由random walk生成的序列; d) 使用Skip-Gram生成embedding
1、根据用户行为构建item graph
我们设置了一个时间窗口,只选择用户在该窗口内的行为,这被称为是基于session的用户行为(session-based)。经验上,该时间窗口的区间是一个小时。
如果我们获取基于session的用户行为,若两个items它们连续出现,会通过一个有向边进行连接,例如:图2(b)的item D和item A是连接的,因为在图2(a)中用户u1u1顺序访问了item D和A。通过利用在淘宝上所有用户的协同行为,我们会为每条边eijeij基于在所有用户行为的行连接items中的出现总数分配一个权重。特别的,在所有用户行为历史中,该边的权重等于item i转向item j的频次。这种方法中,构建的item graph可以基于所有用户行为表示不同items间的相似度。
2、基于图的embedding 【捕获在用户行为序列上的更高阶相似度】
假设M表示G的邻近矩阵(adjacency matrix),$M_{ij}$表示从节点i指向节点j的加权边。我们首先基于随机游走生成节点序列,接着在这些序列上运行Skip-Gram算法。随机游走的转移概率定义如下:
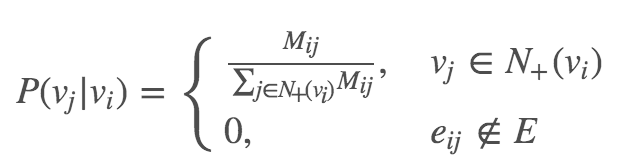 其中,$N_{+(v_i)}$表示出链(outlink)的邻节点集合,例如,从$v_i$出发指向在$N_{+(v_i)}$所有节点的边。通过运行随机游走,我们可以生成如图(c)所示的许多序列。
其中,$N_{+(v_i)}$表示出链(outlink)的邻节点集合,例如,从$v_i$出发指向在$N_{+(v_i)}$所有节点的边。通过运行随机游走,我们可以生成如图(c)所示的许多序列。
3、使用Side Information的GE
为了解决冷启动问题,我们提出了增强式BGE,它会使用side information来与冷启动items做绑定。在商业推荐系统的场景中,side information常指关于一个item的:类目(category),shop(商名),价格(price)等,我们可以通过将side information合并到graph embedding中来缓合cold-start问题。
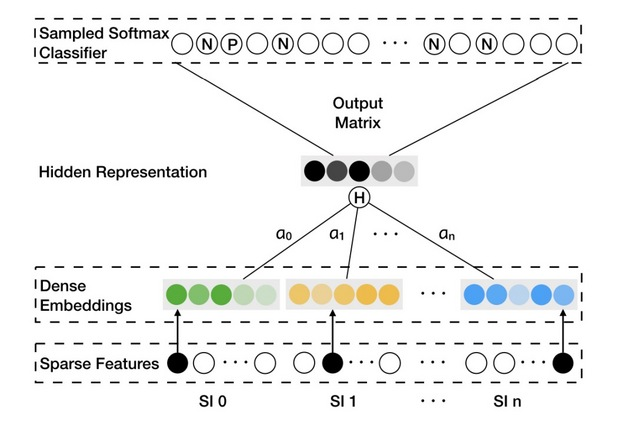
SI表示side information,其中”SI 0”表示item自身。惯例上,1)对于items和不同的SIs,稀疏特征趋向于one-hot-encoder vectors。 2) Dense embeddings是items和相应的SI的表示 ;3) hidden representation是一个item和它相应的SI的聚合embedding。
为了合并side information,我们为item v将n+1个embedding vectors进行拼接,增加一个layer,使用average-pooling操作来进行聚合。
https://zhuanlan.zhihu.com/p/53194407
代码实现:
https://spaces.ac.cn/archives/4515
https://github.com/xiaohan2012/sdne-keras
关于embedding-深度学习基本操作 【Word2vec, Item2vec,graph embedding】的更多相关文章
- 重磅︱文本挖掘深度学习之word2vec的R语言实现
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 笔者寄语:2013年末,Google发布的 w ...
- 深度解析Graph Embedding
Graph Embedding是推荐系统.计算广告领域最近非常流行的做法,是从word2vec等一路发展而来的Embedding技术的最新延伸:并且已经有很多大厂将Graph Embedding应用于 ...
- 回望2017,基于深度学习的NLP研究大盘点
回望2017,基于深度学习的NLP研究大盘点 雷锋网 百家号01-0110:31 雷锋网 AI 科技评论按:本文是一篇发布于 tryolabs 的文章,作者 Javier Couto 针对 2017 ...
- 深度学习在CTR预估中的应用
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由鹅厂优文发表于云+社区专栏 一.前言 二.深度学习模型 1. Factorization-machine(FM) FM = LR+ e ...
- 基于图嵌入的高斯混合变分自编码器的深度聚类(Deep Clustering by Gaussian Mixture Variational Autoencoders with Graph Embedding, DGG)
基于图嵌入的高斯混合变分自编码器的深度聚类 Deep Clustering by Gaussian Mixture Variational Autoencoders with Graph Embedd ...
- 深度学习word2vec笔记之应用篇
好不容易学了一个深度学习的算法,大家是否比较爽了?但是回头想想,学这个是为了什么?吹牛皮吗?写论文吗?参加竞赛拿奖吗? 不管哪个原因,都显得有点校园思维了. 站在企业的层面,这样的方式显然是不符合要求 ...
- 深度学习word2vec笔记之算法篇
深度学习word2vec笔记之算法篇 声明: 本文转自推酷中的一篇博文http://www.tuicool.com/articles/fmuyamf,若有错误望海涵 前言 在看word2vec的资料 ...
- (转)深度学习word2vec笔记之基础篇
深度学习word2vec笔记之基础篇 声明: 1)该博文是多位博主以及多位文档资料的主人所无私奉献的论文资料整理的.具体引用的资料请看参考文献.具体的版本声明也参考原文献 2)本文仅供学术交流,非商用 ...
- 深度学习word2vec笔记之基础篇
作者为falao_beiliu. 作者:杨超链接:http://www.zhihu.com/question/21661274/answer/19331979来源:知乎著作权归作者所有.商业转载请联系 ...
随机推荐
- Bit Operation妙解算法题
5道巧妙位操作的算法题. ***第一道*** 题目描述 给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现两次.找出那个只出现了一次的元素. 说明: 你的算法应该具有线性时间复杂度. ...
- 通过sql查询rman备份信息
通过sql查询rman备份信息 查看所有备份集 SELECT A.RECID "BACKUP SET", A.SET_STAMP, DECODE (B.INCREMENTAL_LE ...
- 习题:Dual Matrices(思路题/分治)
tyvj1764 描述一个N行M列的二维矩阵,矩阵的每个位置上是一个绝对值不超过1000的整数.你需要找到两个不相交的A*B的矩形,使得这两个矩形包含的元素之和尽量大.注:A*B的矩形指连续的A行.B ...
- CSA Round 84 Growing Trees
题目 题目大意 给定一棵有 $n$ 个节点的树,边的权值每天变化.对于第 $i$ 条边,在第 $0$ 天,其权值为 $c_i$,每天权值变化 $a_i$(即,在第 $k$ 天,其权值为 $c_i + ...
- 数组洗牌算法-shuffle
数组洗牌,最近直接的想法是从数组随机取出一个元素,放到另一个数组中,但是这样取出的元素会有重复,必须采取一定的方法保证: 1. 元素不能重复2. 元素被抽取的概率相等,即随机性 数组洗牌经典算法有两种 ...
- 从jekyll转向hexo
当年选择jekyll是因为看中了HCZ Material theme这个主题,折腾了很久才把博客搭建好,后来周边人准备些博客的时候已经不推荐使用jekyll了,推荐hexo给好几个人,不用他们折腾,( ...
- Eclipse 无法查看第三方jar包文件源代码解决方法
1.打开第三方依赖包,源文件的快捷键:ctrl + mouseClick 2.由于我们下载的第三方jar 包,如Spring等相关的依赖包时,并没有附加下载相应的源文件,所以经常出现如图的这种问题. ...
- 关于ofbiz13.07和ofbiz14.12部署的问题解决方法
必备软件 Jdk7 文件名:java_ee_sdk-6u4-jdk7-windows.exe eclipse MySQL Installer 5.6 for Windows MySql Connect ...
- USACO 刷题记录bzoj
bzoj 1606: [Usaco2008 Dec]Hay For Sale 购买干草——背包 #include<cstdio> #include<cstring> #incl ...
- 【HDOJ5973】Game of Taking Stones(Java,威佐夫博弈)
思路:有两堆石子,数量任意,可以不同.游戏开始由两个人轮流取石子. 游戏规定,每次有两种不同的取法,一是可以在任意的一堆中取走任意多的石子:二是可以在两堆中同时取走相同数量的石子. 最后把石子全部取完 ...