Spark 动态(统一)内存管理模型
作者编辑:王玮,胡玉林
一.回顾
在前面的一篇文章中我们介绍了spark静态内存管理模式以及相关知识https://blog.csdn.net/anitinaj/article/details/80901328 在上一篇文章末尾,我们陈述了传统spark静态内存管理模式的局限性:
(1) 没有适用于所有应用的默认配置,通常需要开发人员针对不同的应用进行不同的参数配置。比如根据任务的执行逻辑,调整shuffle和storage内存占比来适应任务的需求。
(2) 这样需要开发人员具备较高的spark原理知识。
(3) 那些不cache数据的应用在运行时只占用一小部分可用内存,因为默认的内存配置中,storage用去了safety内存的60%。
因此,在1.6之后,spark引入了动态(统一)内存管理模式,本文将针对动态内存管理模式的设计理念以及原理进行相关陈述。
二.总体概览
spark从1.6版本以后,默认的内存管理方式就调整为统一内存管理模式。由UnifiedMemoryManager实现。Unified Memory Management模型,重点是打破运行内存和存储内存之间的界限,使spark在运行时,不同用途的内存之间可以实现互相的拆借。
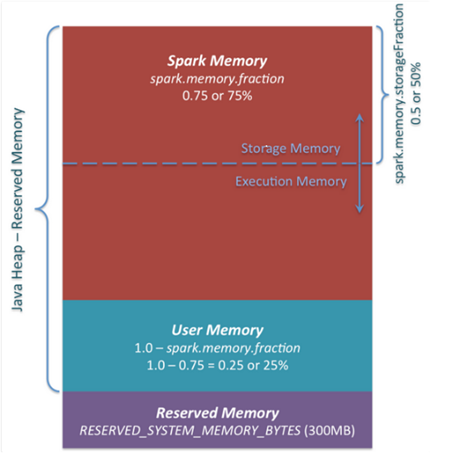
由下图可知,spark每个executor(JVM)内存由一下几个部分组成:
- Reserved Memory: 这部分内存是预留给系统使用, 在1.6.0默认为300MB, 这一部分内存不计算在spark execution和storage中。可通过spark.testing.reservedMemory进行设置。然后把实际可用内存减去这个reservedMemory得到usableMemory。ExecutionMemory 和 StorageMemory 会共享usableMemory * spark.memory.fraction(默认0.75)。
- User Memory : 分配Spark Memory剩余的内存,用户可以根据需要使用。默认占(Java Heap - Reserved Memory) * 0.25.
- Spark Memory: 计算方式为(Java Heap – Reserved Memory) spark.memory.fraction,在1.6.0中,默认为(Java Heap - 300M) 0.75。1. Spark Memory又分为Storage Memory和Execution Memory两部分。两个边界由spark.memory.storageFraction设定,默认为0.5
三.设计理念
本节将对第二部分各个内存的分布以及设计原理进行详细的阐述
相对于静态内存模型(即存储和运行内存相互隔离、彼此不可拆借),动态内存实现了存储和计算内存的动态拆借。也就是说,当计算内存超了,它会从空闲的存储内存中借一部分内存使用,存储内存不够用的时候,也会向空闲的计算内存中拆借。值得注意的地方是,被借走用来执行运算的内存,在执行完任务之前是不会释放内存的。通俗的讲,运行任务会借存储的内存,但是它直到执行完以后才能归还内存。
和动态内存相关的参数如下:
- spark.memory.fraction(默认0.75): 这个参数用来配置存储和计算内存占整个jvm的比例。这个参数设置的越低,也就是存储和计算内存占jvm的比例越低,就越可能频繁的发生内存的释放(将内存中的数据写磁盘或者直接丢弃掉)。反之,如果这个参数越高,发生释放内存的可能性就越小。这个参数的目的是在jvm中留下一部分空间用来保存spark内部数据,用户数据结构,并且防止对数据的错误预估可能造成OOM的风险。
- spark.memory.storageFraction(默认 0.5):在spark.memory.fraction中存储内存所占的比例,默认是0.5,如果使用的存储内存超过了这个范围,缓存的数据会被驱赶。
- spark.memory.useLegacyMode(default false): 设置是否使用saprk1.5及以前遗留的内存管理模型,即静态内存模型,上一篇文章我们介绍过这个,主要是设置以下几个参数,详见上一篇文章。
○ spark.storage.memoryFraction
○ spark.storage.safetyFraction
○ spark.storage.unrollFraction
○ spark.shuffle.memoryFraction
○ spark.shuffle.safetyFraction
- spark.memory.useLegacyMode(default false): 设置是否使用saprk1.5及以前遗留的内存管理模型,即静态内存模型,上一篇文章我们介绍过这个,主要是设置以下几个参数,详见上一篇文章。
下面对动态内存设计原理的一些取舍进行分析:
1.当内存压力上升的时候
因为内存可以被计算和存储内存拆借,我们必须明确在这种机制下,当内存压力上升的时候,我们如何取舍?接下来会从不同维度对下面三个取舍进行分析:
a、倾向于优先释放计算内存
b、倾向于优先释放存储内存
c、不偏不倚,平等竞争
维度1、释放内存的代价
释放存储内存的代价取决于storage level. 如果数据的存储level是MEMORY_ONLY的话代价最高,因为当你释放在内存中的数据的时候,你下次再复用的话只能重新计算了。如果数据的存储level是MEMORY_AND_DIS_SER的时候,释放内存的代价最低。因为这种方式,当内存不够的时候,它会将数据序列化后放在磁盘上,避免复用的时候再计算,唯一的开销只是I/O上。
释放计算内存的代价不是很显而易见。这里没有复用数据重计算的代价,因为计算内存中的任务数据会被移到硬盘,最后再归并起来。最近的spark版本将计算的中间数据进行压缩使得序列化的代价降到了最低。
值得注意的是,移到硬盘的数据总会再重新读回来,从存储内存移除的数据也许不会被用到,所以当没有重新计算的风险时,释放计算的内存要比释放存储内存的代价更高。
维度2、实现复杂度
实现释放存储内存的策略很简单:我们只需要用目前的内存释放策略释放掉存储内存中的数据就好了。
实现释放计算内存却相对来说很复杂。这里有几个实现该方案的思路:
a、当运行任务要拆借存储内存的时候,给所有这些任务注册一个回调函数以便日后调这个函数来回收内存
b、协同投票来进行内存的释放
值得我们注意的一个地方是,以上无论哪种方式,都需要考虑一个地方:即如果我要释放正在运行的任务的内存,同时我们想要cache到存储内存的一部分数据恰巧是由这个任务产生的,如果我们现在释放掉正在运行的任务的内存,就需要考虑在这种环境下会造成饥饿的情况:即生成cache的数据的任务没有足够的内存空间来跑出cache的数据一直处于饥饿状态。
此外,我们还需要考虑,一旦我们释放掉计算内存,那么那些需要cache的数据应该怎么办?最简单的方式就是等待,直到计算内存有足够的空闲,但是这样就可能会造成死锁,尤其是当新的数据块依赖于之前的计算内存中的数据块。另一个可选的操作就是丢掉那些最新写入到磁盘中的块并且一旦当计算内存够了又马上加载回来。为了避免总是丢掉那些等待中的块,我们可以设置一个小的内存空间(比如堆内存的5%)去确保内存中至少有一定的比例的的数据块。
所给的两种方法都会增加额外的复杂度, 这两种方式在第一次的实现中都被排除了。综上目前看来,释放掉存储内存中的计算任务在实现上比较繁琐,目前暂不考虑。
结论:我们倾向于优先释放掉存储内存。即如果存储内存拆借了计算内存,当计算内存需要进行计算并且内存空间不足的时候,优先把计算内存中这部分被用来存储的内存释放掉。
2.可选设计
可选的几种设计理念:结合我们前面的描述,针对在内存压力下释放存储内存有以下几个可选设计。
A: 释放存储内存数据块,完全平滑: 计算和存储内存共享一片统一的区域。内存压力上升,优先释放掉存储内存部分中的数据。如果压力没有缓解,开始将计算内存中运行的任务数据进行溢写磁盘。
B:释放存储内存数据块,静态存储空间预留:这种设计和A设计很像,不同的是会专门划分一个预留存储内存区域。在这个内存区域内,存储内存不会被释放,只有当存储内存超出这个预留区域,才会被释放。这个参数由spark.memory.storageFraction 配置。
C:释放存储内存数据块,动态存储空间预留:这种设计于设计B很相似,但是存储空间的那一部分区域不再是静态设置的了,而是动态分配。这样设置带来的不同是计算内存可以尽可能借走存储内存中可用的部分。
结论:最终采用的的是设计C。
设计A被拒绝的原因是:设计A不适合那些对cache内存重度依赖的saprk任务。
设计B被拒绝的原因是:设计B在很多情况下需要用户去设置存储内存中那部分最小的区域。另外无论我们设置一个什么值,只要它非0,那么计算内存最终也会达到一个上限,比如,如果我们将其设置为0.6,那么有效的执行内存就是堆内存的0.4 * 0.75=0.3,那么如果用户没有cache数据,或是cache的数据达不到设置的0.6,那么这种情况就又回到了静态内存模型那种情况,并没有改善什么。
设计C:设计C就避免了B中的问题,只要存储内存有空余的,那么计算内存就可以借用,需要关注的问题是当计算内存已经使用了存储内存中的所有可用内存但是又需要cache数据的时候应该怎么处理。最早的版本中直接释放最新的block来避免引入执行驱赶策略的复杂性
同时设计C是唯一一个同时满足下列条件的:
- 存储内存没有上限。
- 计算内存没有上限。
- 保障了存储空间有一个小的保留区域。
四.实现类分析-UnifiedMemoryManager
阐述该类的几个主要方法:
1. acquireExecutionMemory(numBytes: Long, taskAttemptId: Long, memoryMode: MemoryMode)方法:当前的任务尝试从executor中获取numBytes这么大的内存。该方法直接向ExecutionMemoryPool索要所需内存,索要内存有以下几个关注点:
- 当ExecutionMemory 内存充足,则不会触发向Storage申请内存。
- 每个Task能够被使用的内存被限制在 poolSize / (2 numActiveTasks) ~ maxPoolSize / numActiveTasks 之间。
val maxMemoryPerTask = maxPoolSize / numActiveTasks和 `val minMemoryPerTask = poolSize / (2numActiveTasks)`其中maxPoolSize= maxMemory(storage+execution的最大内存) - math.min(storageMemoryUsed, storageRegionSize),poolSize= 当前这个pool的大小。而maxPoolSize也代表了execution pool的最大内存。 - 索要的内存大小:
val memoryReclaimableFromStorage =math.max(storageMemoryPool.memoryFree, storageMemoryPool.poolSize - storageRegionSize)取决于StorageMemoryPool的剩余内存和 storageMemoryPool 从ExecutionMemory借来的内存哪个大,取最大的那个,作为可以重新归还的最大内存。用公式表达出来就是这一个样子:ExecutionMemory 能借到的最大内存= StorageMemory 借的内存 + StorageMemory 空闲内存当然,如果实际需要的小于能够借到的最大值,则以实际需要值为准。val spaceToReclaim = storageMemoryPool.freeSpaceToShrinkPool( math.min(extraMemoryNeeded, memoryReclaimableFromStorage))
ExecutionMemoryPool 的acquireMemory方法主要如下:
程序一直处理该task的请求,直到系统判定无法满足该请求或者已经为该请求分配到足够的内存为止。如果当前execution内存池剩余内存不足以满足此次请求时,会向storage部分请求释放出被借走的内存以满足此次请求。
根据此刻execution内存池的总大小maxPoolSize,以及从memoryForTask中统计出的处于active状态的task的个数计算出每个task能够得到的最大内存数maxMemoryPerTask = maxPoolSize / numActiveTasks。每个task能够得到的最少内存数minMemoryPerTask = poolSize / (2 * numActiveTasks)。
根据申请内存的task当前使用的execution内存大小决定分配给该task多少内存,总的内存不能超过maxMemoryPerTask。但是如果execution内存池能够分配的最大内存小于numBytes并且如果把能够分配的内存分配给当前task,但是该task最终得到的execution内存还是小于minMemoryPerTask时,该task进入等待状态,等其他task申请内存时将其唤醒。如果满足,就会返回能够分配的内存数,并且更新memoryForTask,将该task使用的内存调整为分配后的值。一个Task最少需要minMemoryPerTask才能开始执行。
2. acquireStorageMemory(blockId: BlockId,numBytes: Long, evictedBlocks: mutable.Buffer[(BlockId, BlockStatus)])方法:
- 流程和acquireExecutionMemory类似,当storage的内存不足时,同样会向execution借内存,但区别是当且仅当ExecutionMemory有空闲内存时,StorageMemory 才能借走该内存。能借到的内存数为:val memoryBorrowedFromExecution = Math.min(onHeapExecutionMemoryPool.memoryFree, numBytes)。所以StorageMemory从ExecutionMemory借走的内存,完全取决于当时ExecutionMemory是不是有空闲内存。借到内存后,storageMemoryPool增加借到的这部分内存,之后同上一样,会调用StorageMemoryPool的acquireMemory方法,主要如下:

在申请内存时,如果numBytes大于此刻storage内存池的剩余内存,即if (numBytesToFree > 0),那么需要storage内存池释放一部分内存以满足申请需求。释放内存后如果memoryFree >= numBytes,就会把这部分内存分配给申请内存的task,并且更新storage内存池的使用情况。同时他与ExecutionMemoryPool不同的是,他不会像前者那样分不到资源就进行等待,acquireStorageMemory只会返回一个true或是false,告知内存分配是否成功。
五.总结
结合两篇文章,我们对spark的两种内存管理模型都做了一个简单的介绍,两者的不同之处也做出了说明,希望这两篇文章对spark的使用者有一定的帮助,也欢迎大家交流。
参考内容:
- spark设计文档《unified-memory-management-spark》
- http://blog.csdn.net/dabokele/article/details/51475469
Spark 动态(统一)内存管理模型的更多相关文章
- Spark源码分析之九:内存管理模型
Spark是现在很流行的一个基于内存的分布式计算框架,既然是基于内存,那么自然而然的,内存的管理就是Spark存储管理的重中之重了.那么,Spark究竟采用什么样的内存管理模型呢?本文就为大家揭开Sp ...
- [译]C# 7系列,Part 10: Span<T> and universal memory management Span<T>和统一内存管理
原文:https://blogs.msdn.microsoft.com/mazhou/2018/03/25/c-7-series-part-10-spant-and-universal-memory- ...
- <Linux内核源码>内存管理模型
题外语:本人对linux内核的了解尚浅,如果有差池欢迎指正,也欢迎提问交流! 首先要理解一下每一个进程是如何维护自己独立的寻址空间的,我的电脑里呢是8G内存空间.了解过的朋友应该都知道这是虚拟内存技术 ...
- Spark两种内存管理
Spark动态内存管理 Spark 1.6 后改为动态内存管理(如果想启用静态内存管理,方法下面会介绍),启动动态主要体现在 存储内存和执行内存的动态.
- Memcached内存管理模型分析
Memcached 是一个高性能的分布式内存对象缓存系统,它通过在内存中缓存数据和对象来减少读取数据库的次数,从而减轻RDBMS的负担,提高服务的速度.提升可扩展性.本文将基于memcached1.4 ...
- spark调优篇-Spark ON Yarn 内存管理(汇总)
本文旨在解析 spark on Yarn 的内存管理,使得 spark 调优思路更加清晰 内存相关参数 spark 是基于内存的计算,spark 调优大部分是针对内存的,了解 spark 内存参数有也 ...
- 6 spark 存储体系 --内存管理
6.5 memoryMode
- Spark(二): 内存管理
Spark 作为一个以擅长内存计算为优势的计算引擎,内存管理方案是其非常重要的模块: Spark的内存可以大体归为两类:execution和storage,前者包括shuffles.joins.sor ...
- Spark内存管理机制
Spark内存管理机制 Spark 作为一个基于内存的分布式计算引擎,其内存管理模块在整个系统中扮演着非常重要的角色.理解 Spark 内存管理的基本原理,有助于更好地开发 Spark 应用程序和进行 ...
随机推荐
- 洛谷 P3804 【模板】后缀自动机
来一份模板 #include<cstdio> #include<algorithm> #include<cstring> #include<queue> ...
- MyEclipse常用设置记录
MyEclipse版本:MyEclipse 2014 Blue版本. 设置内容: 1.内存优化 <MyEclipse_ROOT>/myeclipse-blue.ini文件 主要修改-vma ...
- 442 Find All Duplicates in an Array 数组中重复的数据
给定一个整数数组 a,其中1 ≤ a[i] ≤ n (n为数组长度), 其中有些元素出现两次而其他元素出现一次.找到所有出现两次的元素.你可以不用到任何额外空间并在O(n)时间复杂度内解决这个问题吗? ...
- NSoup获取网页源代码
NSoup是JSoup的Net移植版本.使用方法基本一致. 如果项目涉及HTML的处理,强烈推荐NSoup,毕竟字符串截断太苦逼了. 下载地址:http://nsoup.codeplex.com/ # ...
- LN : leetcode 123 Best Time to Buy and Sell Stock III
lc 123 Best Time to Buy and Sell Stock III 123 Best Time to Buy and Sell Stock III Say you have an a ...
- 使用VirtualBox的时候虚拟机无法ping通windows主机,但是主机可以ping通虚拟机
问题原因是windows开启了防火墙导致的,将windows的防火墙关闭即可. 关闭windows防火墙后会有警告的信息出现,直接无视即可.
- mac webstrom 安装less
1.检验电脑是否安装less lessc -v 2.如果没有执行全局安装命令 npm install -g less 3.webstrom -> Preferencs-> File Wat ...
- Android(java)学习笔记192:ContentProvider使用之虚拟短信
1.虚拟短信应用场景: 急着脱身?应付老婆(老公.男女朋友查岗)? 使用虚拟通话短信吧.您只需通过简单设置,软件就会在指定时间会模拟一个“真实”来电或短信来迷惑对方,通过“真实”的证据让对方相 ...
- Shorthand Argument Names $0 : 只用于指代Closer声明中的形参
Shorthand Argument Names Swift automatically provides shorthand argument names to inline closures, w ...
- 在死循环中使用Scanner获得键盘输入
1. 编译时无错误和警告,且运行过程中无异常的代码示例 //编译时无错误和警告,且运行过程中无异常的代码示例package scanner_test; import java.util.*; publ ...