HDFS 中文件操作的错误集锦
|
问题1 Java ApI执行追加写入时:无法写入 |
|
|
问题描述: ①当前数据节点无法写入,②追加文件需要再次请求。 |
|


|
问题2 命令行执行追加写入时:无法写入 |
|
|
问题描述: 当前数据节点无法写入 |
|

|
问题3 Java ApI上传时.crc校验文件的校检失败 |
|
|
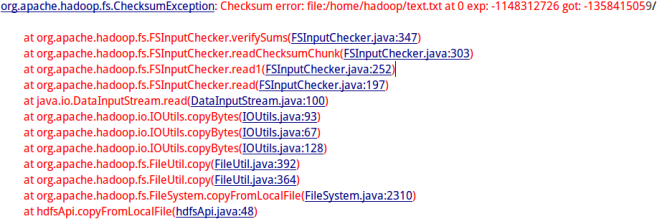
问题描述: Java ApI上传文件时对原文件进行检验,导致无法正常上传 |
|
|
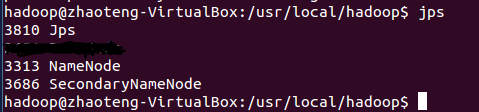
问题4 多次使用hadoop namenode -format 格式化导致数据节点无法正常启动 |
|
|
问题描述: 使用hadoop namenode -format 格式化时多次格式化造成了spaceID不一致 |
Jps命令没有datanode
|

三、解决方案:(列出遇到的问题和解决办法,列出没有解决的问题):
|
问题1/2 Java ApI或命令行执行追加写入时:无法写入 |
|
|
问题原因 |
我的环境中有3个datanode,备份数量设置的是3。在写操作时,它会在pipeline中写3个机器。默认replace-datanode-on-failure.policy是DEFAULT,如果系统中的datanode大于等于3,它会找另外一个datanode来拷贝。目前机器只有3台,因此只要一台datanode出问题,就一直无法写入成功。 |
|
问题解决: (针对JAVA API) |
在所要执行的代码中添加两句: conf.set("dfs.client.block.write.replace-datanode-on-failure.policy","NEVER"); 一次执行,可能无响应,再次请求即可。 详细内容可参考以下教程解释:https://blog.csdn.net/caiandyong/article/details/44730031?utm_source=copy |
|
问题解决: (针对命令行) |
修改hdfs-site.xml文件,添加或者修改如下两项: <property> <name>dfs.client.block.write.replace-datanode-on-failure.enable</name> <value>true</value> </property> <property> <name>dfs.client.block.write.replace-datanode-on-failure.policy</name> <value>NEVER</value> </property> |
|
注解 |
对于dfs.client.block.write.replace-datanode-on-failure.enable,客户端在写失败的时候,是否使用更换策略,默认是true没有问题 对于,dfs.client.block.write.replace-datanode-on-failure.policy,default在3个或以上备份的时候,是会尝试更换结点尝试写入datanode。而在两个备份的时候,不更换datanode,直接开始写。对于3个datanode的集群,只要一个节点没响应写入就会出问题,所以可以关掉。 详解参考:https://blog.csdn.net/themanofcoding/article/details/79512754?utm_source=copy |
|
问题3 Java ApI上传时.crc校验文件的校检失败 |
|
|
问题原因 |
Hadoop客户端将本地文件text.txt上传到hdfs上时,hadoop会通过fs.FSInputChecker判断需要上传的文件是否存在.crc校验文件。如果存在.crc校验文件,则会进行校验。如果校验失败,自然不会上传该文件。 可能因为之前对原文件有更改,所以会对校检文件的校验进行干扰。 |
|
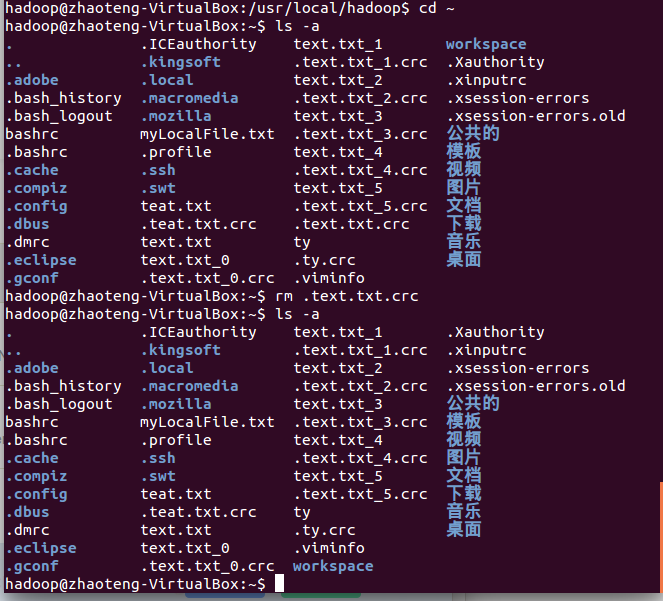
问题解决: |
cd到文件所在路径,ls -a查看,果然存在.text.crc文件
详细内容可参考以下教程解释:https://blog.csdn.net/bitcarmanlee/article/details/50969025?utm_source=copy |
|
注解 |
crc文件来源 DFS命令:hadoop fs -getmerge srcDir destFile 这类命令在执行的时候,会将srcDir目录下的所有文件合并成一个文件,保存在destFile中,同时会在本地磁盘生成一个. destFile.crc的校验文件。 DFS命令:hadoop fs -get -crc src dest 这类命令在执行的时候,会将src文件,保存在dest中,同时会在本地磁盘生成一个. dest.crc的校验文件。 如何避免 在使用hadoop fs -getmerge srcDir destFile命令时,本地磁盘一定会(没有参数可以关闭)生成相应的.crc文件。 所以如果需要修改getmerge获取的文件的内容,再次上传到DFS时,可以采取以下2种策略进行规避: 1. 删除.crc文件 2. 将getmerge获取的文件修改后重新命名,如使用mv操作,再次上传到DFS中。 更多关于Hadoop的文章,可以参考:http://www.cnblogs.com/gpcuster/tag/Hadoop/ |
|
问题4 多次使用hadoop namenode -format 格式化导致数据节点无法正常启动 |
|
|
问题原因 |
在第一次格式化dfs后,启动并使用了hadoop,后来又重新执行了格式化命令(hdfs namenode -format),这时namenode的clusterID会重新生成,而datanode的clusterID 保持不变。 |
|
问题解决: 使用hadoop namenode -format 格式化时多次格式化造成了spaceID不一致 |
1、停止集群(切换到/sbin目录下) 2、删除在hdfs中配置的data目录(即在core-site.xml中配置的hadoop.tmp.dir对应文件件)下面的所有数据; 3、重新格式化namenode(切换到hadoop目录下的bin目录下) 4、重新启动hadoop集群(切换到hadoop目录下的sbin目录下) 在使用hadoop dfsadmin -report查看使用情况,结果如下图所示: ok没有错误了。再次上传文件,成功。 转载:http://blog.csdn.net/weiyongle1996/article/details/74094989 详见:https://blog.csdn.net/love666666shen/article/details/74350358 |
HDFS 中文件操作的错误集锦的更多相关文章
- HDFS中文件的压缩与解压
HDFS中文件的压缩与解压 文件的压缩有两大好处:1.可以减少存储文件所需要的磁盘空间:2.可以加速数据在网络和磁盘上的传输.尤其是在处理大数据时,这两大好处是相当重要的. 下面是一个使用gzip工具 ...
- php中文件操作常用函数有哪些
php中文件操作常用函数有哪些 一.总结 一句话总结:读写文件函数 判断文件或者目录是否存在函数 创建目录函数 file_exists() mkdir() file_get_content() fil ...
- python中文件操作的六种模式及对文件某一行进行修改的方法
一.python中文件操作的六种模式分为:r,w,a,r+,w+,a+ r叫做只读模式,只可以读取,不可以写入 w叫做写入模式,只可以写入,不可以读取 a叫做追加写入模式,只可以在末尾追加内容,不可以 ...
- python中文件操作的其他方法
前面介绍过Python中文件操作的一般方法,包括打开,写入,关闭.本文中介绍下python中关于文件操作的其他比较常用的一些方法. 首先创建一个文件poems: p=open('poems','r', ...
- Hadoop第4周练习—HDFS读写文件操作
1 运行环境说明... 3 :编译并运行<权威指南>中的例3.2. 3 内容... 3 2.3.1 创建代码目录... 4 2.3.2 建立例子文件上传到hdfs中... 4 ...
- HDFS常用文件操作
put 上传文件 hadoop fs -put wordcount.txt /data/wordcount/ text 查看文件内容 hadoop fs -text /output/wo ...
- Python中文件操作2——shutil模块
1 文件操作 文件有很多的操作,之前的文件操作中介绍了内建函数对文件的打开.读取以及写入,这三种操作是对文件基本的使用.文件还有复制.删除.移动.改变文件的属主属组等操作.下面主要看os模块和shut ...
- Python 中文件操作
上代码: import os import os.path rootdir = "d:/code/su/data" # 指明被遍历的文件夹 for parent,dirnames, ...
- hdfs基本文件操作
编程实现下列要求: 1.创建一个自己姓名首字母的文件夹 2.在文件夹下创建一个hdfstext1.txt文件,项文件内输入“班级学号姓名HDFS课堂测试”的文字内容: 3.在文件夹下在创建一个好的fs ...
随机推荐
- 如何在adapter 中调用activity的方法
如何在adapter 中调用activity的方法 2015-08-07 17:06匿名 | 浏览 808 次 iWorkjavaAndroid public class HistoryData e ...
- MyBatisPlus代码生成 mvc项目
package com.test; import com.baomidou.mybatisplus.annotation.DbType; import com.baomidou.mybatisplus ...
- quartz spring 实现动态定时任务
在实际项目应用中经常会用到定时任务,可以通过quartz和spring的简单配置即可完成,但如果要改变任务的执行时间.频率,废弃任务等就需要改变配置甚至代码需要重启服务器,这里介绍一下如何通过quar ...
- save the transient instance before flushing错误解决办法
错误原因: new了一个新对象,在未保存之前将它保存进了一个新new的对象(也即不是持久态). 解决办法: 在保存或更新之前把这个对象查出来(这样就是一个持久态) <set name=" ...
- Day3-D-Protecting the Flowers POJ3262
Farmer John went to cut some wood and left N (2 ≤ N ≤ 100,000) cows eating the grass, as usual. When ...
- 【Unity】鼠标指向某物体,在其上显示物体的名字等等等等信息
之前一直用NGUI HUD Text插件做这个功能,感觉一个小功能就导一个插件进来简直丧心病狂.然后就自己写了一个~ Camera cam;//用于发射射线的相机 Camera UIcam;//UI层 ...
- 图像检索:CEDD(Color and Edge Directivity Descriptor)算法 颜色和边缘的方向性描述符
颜色和边缘的方向性描述符(Color and Edge Directivity Descriptor,CEDD) 本文节选自论文<Android手机上图像分类技术的研究>. CEDD具有抽 ...
- hue中访问hdfs报错
在hue中访问hdfs报错: Cannot access: /. Note: you are a Hue admin but not a HDFS superuser, "hdfs" ...
- springboot启动报错:Caused by: org.springframework.beans.factory.NoSuchBeanDefinitionException: No qualifying bean of type 'com.zxkj.lockserver.dao.CompanyDao' available: expected at least 1 bean which qua
Caused by: org.springframework.beans.factory.NoSuchBeanDefinitionException: No qualifying bean of ty ...
- 微信小程序提示:https://api.map.baidu.com 不在以下 request 合法域名列表中
如果你想利用百度地图API定位来获得当前位置,但却出现了如标题所示问题,那么请接着看: 1.首先我们需要在百度地图开放平台(https://lbs.baidu.com/apiconsole/key?a ...