基于 abp vNext 和 .NET Core 开发博客项目 - Blazor 实战系列(三)
系列文章
- 基于 abp vNext 和 .NET Core 开发博客项目 - 使用 abp cli 搭建项目
- 基于 abp vNext 和 .NET Core 开发博客项目 - 给项目瘦身,让它跑起来
- 基于 abp vNext 和 .NET Core 开发博客项目 - 完善与美化,Swagger登场
- 基于 abp vNext 和 .NET Core 开发博客项目 - 数据访问和代码优先
- 基于 abp vNext 和 .NET Core 开发博客项目 - 自定义仓储之增删改查
- 基于 abp vNext 和 .NET Core 开发博客项目 - 统一规范API,包装返回模型
- 基于 abp vNext 和 .NET Core 开发博客项目 - 再说Swagger,分组、描述、小绿锁
- 基于 abp vNext 和 .NET Core 开发博客项目 - 接入GitHub,用JWT保护你的API
- 基于 abp vNext 和 .NET Core 开发博客项目 - 异常处理和日志记录
- 基于 abp vNext 和 .NET Core 开发博客项目 - 使用Redis缓存数据
- 基于 abp vNext 和 .NET Core 开发博客项目 - 集成Hangfire实现定时任务处理
- 基于 abp vNext 和 .NET Core 开发博客项目 - 用AutoMapper搞定对象映射
- 基于 abp vNext 和 .NET Core 开发博客项目 - 定时任务最佳实战(一)
- 基于 abp vNext 和 .NET Core 开发博客项目 - 定时任务最佳实战(二)
- 基于 abp vNext 和 .NET Core 开发博客项目 - 定时任务最佳实战(三)
- 基于 abp vNext 和 .NET Core 开发博客项目 - 博客接口实战篇(一)
- 基于 abp vNext 和 .NET Core 开发博客项目 - 博客接口实战篇(二)
- 基于 abp vNext 和 .NET Core 开发博客项目 - 博客接口实战篇(三)
- 基于 abp vNext 和 .NET Core 开发博客项目 - 博客接口实战篇(四)
- 基于 abp vNext 和 .NET Core 开发博客项目 - 博客接口实战篇(五)
- 基于 abp vNext 和 .NET Core 开发博客项目 - Blazor 实战系列(一)
- 基于 abp vNext 和 .NET Core 开发博客项目 - Blazor 实战系列(二)
上一篇完成了博客的主题切换,菜单和二维码的显示与隐藏功能,本篇继续完成分页查询文章列表的数据展示。
添加页面
现在点击页面上的链接,都会提示错误消息,因为没有找到对应的路由地址。先在Pages下创建五个文件夹:Posts、Categories、Tags、Apps、FriendLinks。
然后在对应的文件夹下添加Razor组件。
- Posts文件夹:文章列表页面
Posts.razor、根据分类查询文章列表页面Posts.Category.razor、根据标签查询文章列表页面Posts.Tag.razor、文章详情页Post.razor - Categories文件夹:分类列表页面
Categories.razor - Tags文件夹:标签列表页面
Tags.razor - Apps文件夹:
Apps.razor准备将友情链接入口放在里面 - FriendLinks文件夹:友情链接列表页面
FriendLinks.razor
先分别创建上面这些Razor组件,差不多除了后台CURD的页面就这些了,现在来逐个突破。
不管三七二十一,先把所有页面的路由给确定了,指定页面路由使用 @page 指令,官方文档说不支持可选参数,但是可以支持多个路由规则。
默认先什么都不显示,可以将之前的加载中圈圈写成一个组件,供每个页面使用。
在Shared文件夹添加组件Loading.razor。
<!--Loading.razor-->
<div class="loader"></div>
//Posts.razor
@page "/posts/"
@page "/posts/page/{page:int}"
@page "/posts/{page:int}"
<Loading />
@code {
/// <summary>
/// 当前页码
/// </summary>
[Parameter]
public int? page { get; set; }
}
这里我加了三条,可以匹配没有page参数,带page参数的,/posts/page/{page:int}这个大家可以不用加,我是用来兼容目前线上的博客路由的。总的来说可以匹配到:/posts、/posts/1、/posts/page/1这样的路由。
//Posts.Category.razor
@page "/category/{name}"
<Loading />
@code {
/// <summary>
/// 分类名称参数
/// </summary>
[Parameter]
public string name { get; set; }
}
根据分类名称查询文章列表页面,name当作分类名称参数,可以匹配到类似于:/category/aaa、/category/bbb这样的路由。
//Posts.Tag.razor
@page "/tag/{name}"
<Loading />
@code {
/// <summary>
/// 标签名称参数
/// </summary>
[Parameter]
public string name { get; set; }
}
这个根据标签名称查询文章列表页面和上面差不多一样,可以匹配到:/tag/aaa、/tag/bbb这样的路由。
//Post.razor
@page "/post/{year:int}/{month:int}/{day:int}/{name}"
<Loading />
@code {
[Parameter]
public int year { get; set; }
[Parameter]
public int month { get; set; }
[Parameter]
public int day { get; set; }
[Parameter]
public string name { get; set; }
}
文章详情页面的路由有点点复杂,以/post/开头,加上年月日和当前文章的语义化名称组成。分别添加了四个参数年月日和名称,用来接收URL的规则,使用int来设置路由的约束,最终可以匹配到路由:/post/2020/06/09/aaa、/post/2020/06/9/bbb这样的。
//Categories.razor
@page "/categories"
<Loading />
//Tags.razor
@page "/tags"
<Loading />
//FriendLinks.razor
@page "/friendlinks"
<Loading />
分类、标签、友情链接都是固定的路由,像上面这样就不多说了,然后还剩一个Apps.razor。
//Apps.razor
@page "/apps"
<div class="container">
<div class="post-wrap">
<h2 class="post-title">- Apps -</h2>
<ul>
<li>
<a target="_blank" href="https://support.qq.com/products/75616"><h3>吐个槽_留言板</h3></a>
</li>
<li>
<NavLink href="/friendlinks"><h3>友情链接</h3></NavLink>
</li>
</ul>
</div>
</div>
在里面添加了一个友情链接的入口,和一个 腾讯兔小巢 的链接,欢迎大家吐槽留言噢。
现在可以运行一下看看,点击所有的链接都不会提示错误,只要路由匹配正确就会出现加载中的圈圈了。
文章列表
在做文章列表的数据绑定的时候遇到了大坑,有前端开发经验的都知道,JavaScript弱类型语言中接收json数据随便玩,但是在Blazor中我试了下动态接受传递过来的JSON数据,一直报错压根运行不起来。所以在请求api接收数据的时候需要指定接收对象,那就好办了我就直接引用API中的.Application.Contracts就行了啊,但是紧接着坑又来了,目标框架对不上,引用之后也运行不起来,这里应该是之前没有设计好。
于是,我就想了一个折中的办法吧,将API中的返回对象可以用到的DTO先手动拷贝一份到Blazor项目中,后续可以考虑将公共的返回模型做成Nuget包,方便使用。
那么,最终就是在Blazor中添加一个Response文件夹,用来放接收对象,里面的内容看图:
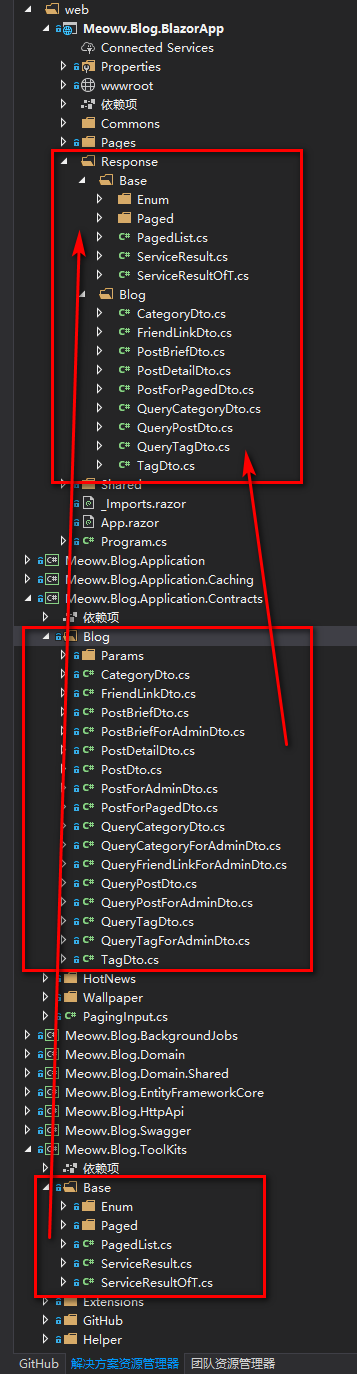
有点傻,先这样解决,后面在做进一步的优化吧。
将我们复制进来的东东,在_Imports.razor中添加引用。
//_Imports.razor
@using System.Net.Http
@using System.Net.Http.Json
@using Microsoft.AspNetCore.Components.Forms
@using Microsoft.AspNetCore.Components.Routing
@using Microsoft.AspNetCore.Components.Web
@using Microsoft.AspNetCore.Components.WebAssembly.Http
@using Meowv.Blog.BlazorApp.Shared
@using Response.Base
@using Response.Blog
@inject HttpClient Http
@inject Commons.Common Common
@inject HttpClient Http:注入HttpClient,用它来请求API数据。
现在有了接收对象,接下来就好办了,来实现分页查询文章列表吧。
先添加三个私有变量,限制条数,就是一次加载文章的数量,总页码用来计算分页,还有就是API的返回数据的接收类型参数。
/// <summary>
/// 限制条数
/// </summary>
private int Limit = 15;
/// <summary>
/// 总页码
/// </summary>
private int TotalPage;
/// <summary>
/// 文章列表数据
/// </summary>
private ServiceResult<PagedList<QueryPostDto>> posts;
然后当页面初始化的时候,去加载数据,渲染页面,因为page参数可能存在为空的情况,所以要考虑进去,当为空的时候给他一个默认值1。
/// <summary>
/// 初始化
/// </summary>
protected override async Task OnInitializedAsync()
{
// 设置默认值
page = page.HasValue ? page : 1;
await RenderPage(page);
}
/// <summary>
/// 点击页码重新渲染数据
/// </summary>
/// <param name="page"></param>
/// <returns></returns>
private async Task RenderPage(int? page)
{
// 获取数据
posts = await Http.GetFromJsonAsync<ServiceResult<PagedList<QueryPostDto>>>($"/blog/posts?page={page}&limit={Limit}");
// 计算总页码
TotalPage = (int)Math.Ceiling((posts.Result.Total / (double)Limit));
}
在初始化方法中设置默认值,调用RenderPage(...)获取到API返回来的数据,并根据返回数据计算出页码,这样就可以绑定数据了。
@if (posts == null)
{
<Loading />
}
else
{
<div class="post-wrap archive">
@if (posts.Success && posts.Result.Item.Any())
{
@foreach (var item in posts.Result.Item)
{
<h3>@item.Year</h3>
@foreach (var post in item.Posts)
{
<article class="archive-item">
<NavLink href="@("/post" + post.Url)">@post.Title</NavLink>
<span class="archive-item-date">@post.CreationTime</span>
</article>
}
}
<nav class="pagination">
@for (int i = 1; i <= TotalPage; i++)
{
var _page = i;
if (page == _page)
{
<span class="page-number current">@_page</span>
}
else
{
<a class="page-number" @onclick="@(() => RenderPage(_page))" href="/posts/@_page">@_page</a>
}
}
</nav>
}
else
{
<ErrorTip />
}
</div>
}
在加载数据的时候肯定是需要一个等待时间的,因为不可抗拒的原因数据还没加载出来的时候,可以让它先转一会圈圈,当posts不为空的时候,再去绑定数据。
在绑定数据,for循环页码的时候我又遇到了一个坑,这里不能直接去使用变量i,必须新建一个变量去接受它,不然我传递给RenderPage(...)的参数就会是错的,始终会取到最后一次循环的i值。
当判断数据出错或者没有数据的时候,在把错误提示<ErrorTip />扔出来显示。
做到这里,可以去运行看看了,肯定会报错,因为还有一个重要的东西没有改,就是我们接口的BaseAddress,在Program.cs中,默认是当前Blazor项目的运行地址。
我们需要先将API项目运行起来,拿到地址配置在Program.cs中,因为现在还是本地开发,有多种办法可以解决,可以将.HttpApi.Hosting设为启动项目直接运行起来,也可以使用命令直接dotnet run。
我这里为了方便,直接发布在IIS中,后续只要电脑打开就可以访问了,你甚至选择其它任何你能想到的方式。
关于如何发布这里先不做展开,有机会的话写一篇将.net core开发的项目发布到 Windows、Linux、Docker 的教程吧。
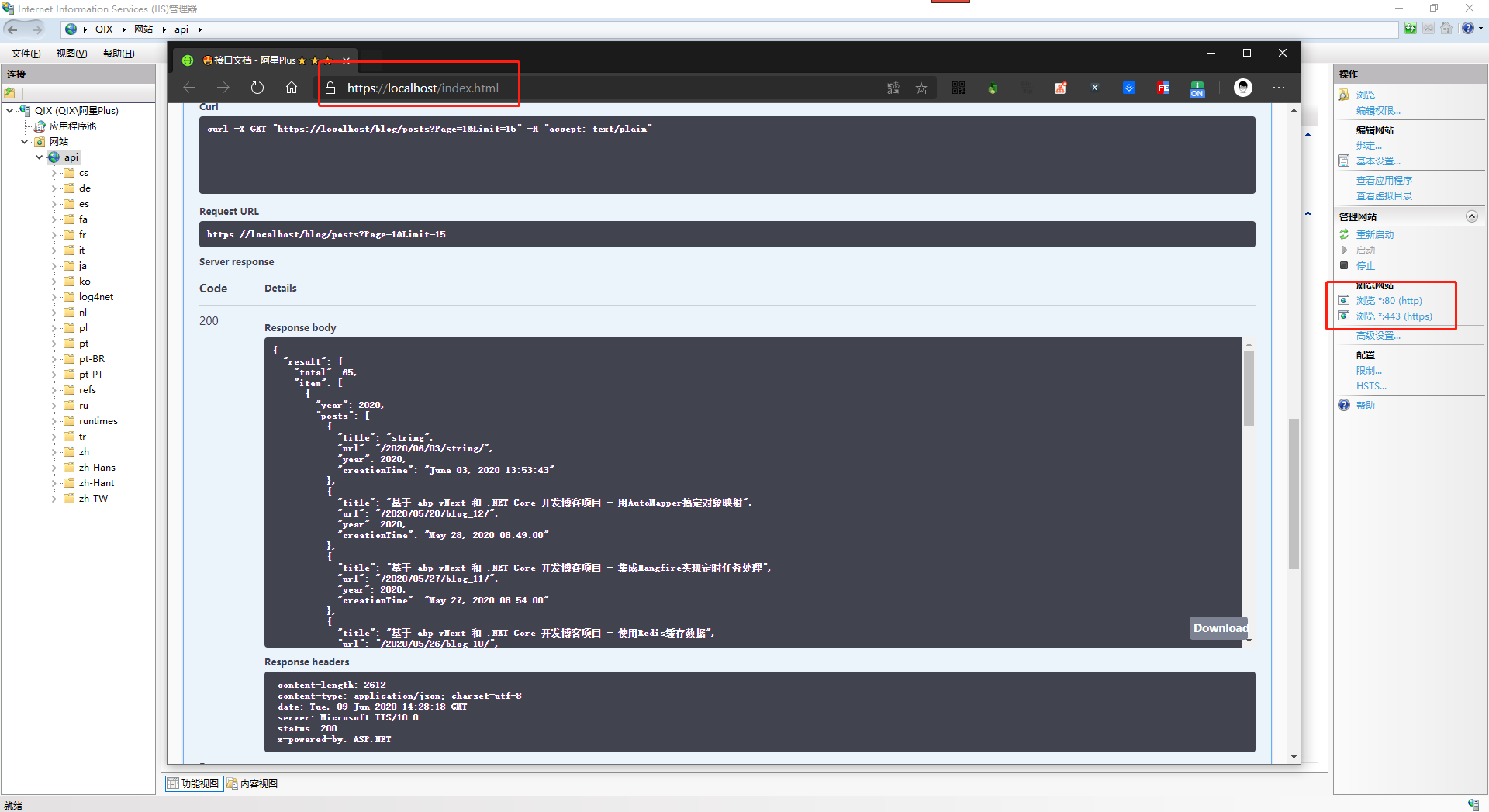
所以我的Program.cs中配置如下:
//Program.cs
using Meowv.Blog.BlazorApp.Commons;
using Microsoft.AspNetCore.Components.WebAssembly.Hosting;
using Microsoft.Extensions.DependencyInjection;
using System;
using System.Net.Http;
using System.Threading.Tasks;
namespace Meowv.Blog.BlazorApp
{
public class Program
{
public static async Task Main(string[] args)
{
var builder = WebAssemblyHostBuilder.CreateDefault(args);
builder.RootComponents.Add<App>("app");
var baseAddress = "https://localhost";
if (builder.HostEnvironment.IsProduction())
baseAddress = "https://api.meowv.com";
builder.Services.AddTransient(sp => new HttpClient
{
BaseAddress = new Uri(baseAddress)
});
builder.Services.AddSingleton(typeof(Common));
await builder.Build().RunAsync();
}
}
}
baseAddress默认为本地开发地址,使用builder.HostEnvironment.IsProduction()判断是否为线上正式生产环境,改变baseAddress地址。
现在可以看到已经可以正常获取数据,并且翻页也是OK的,然后又出现了一个新的BUG。
解决BUG
细心的可以发现,当我点击头部组件的Postsa 标签菜单时候,页面没有发生变化,只是路由改变了。
思来想去,我决定使用NavigationManager这个URI和导航状态帮助程序来解决,当点击头部的Postsa 标签菜单直接刷新页面得了。
在Common.cs中使用构造函数注入NavigationManager,然后添加一个跳转指定URL的方法。
/// <summary>
/// 跳转指定URL
/// </summary>
/// <param name="uri"></param>
/// <param name="forceLoad">true,绕过路由刷新页面</param>
/// <returns></returns>
public async Task RenderPage(string url, bool forceLoad = true)
{
_navigationManager.NavigateTo(url, forceLoad);
await Task.CompletedTask;
}
当forceLoad = true的时候,将会绕过路由直接强制刷新页面,如果forceLoad = false,则不会刷新页面。
紧接着在Header.razor中修改代码,添加点击事件。
@*<NavLink class="menu-item" href="posts">Posts</NavLink>*@
<NavLink class="menu-item" href="posts" @onclick="@(async () => await Common.RenderPage("posts"))">Posts</NavLink>
总算是搞定,完成了分页查询文章列表的数据绑定,今天就到这里吧,未完待续...
开源地址:https://github.com/Meowv/Blog/tree/blog_tutorial
基于 abp vNext 和 .NET Core 开发博客项目 - Blazor 实战系列(三)的更多相关文章
- 基于 abp vNext 和 .NET Core 开发博客项目 - Blazor 实战系列(二)
系列文章 基于 abp vNext 和 .NET Core 开发博客项目 - 使用 abp cli 搭建项目 基于 abp vNext 和 .NET Core 开发博客项目 - 给项目瘦身,让它跑起来 ...
- 基于 abp vNext 和 .NET Core 开发博客项目 - Blazor 实战系列(四)
系列文章 基于 abp vNext 和 .NET Core 开发博客项目 - 使用 abp cli 搭建项目 基于 abp vNext 和 .NET Core 开发博客项目 - 给项目瘦身,让它跑起来 ...
- 基于 abp vNext 和 .NET Core 开发博客项目 - Blazor 实战系列(五)
系列文章 基于 abp vNext 和 .NET Core 开发博客项目 - 使用 abp cli 搭建项目 基于 abp vNext 和 .NET Core 开发博客项目 - 给项目瘦身,让它跑起来 ...
- 基于 abp vNext 和 .NET Core 开发博客项目 - Blazor 实战系列(六)
系列文章 基于 abp vNext 和 .NET Core 开发博客项目 - 使用 abp cli 搭建项目 基于 abp vNext 和 .NET Core 开发博客项目 - 给项目瘦身,让它跑起来 ...
- 基于 abp vNext 和 .NET Core 开发博客项目 - Blazor 实战系列(七)
系列文章 基于 abp vNext 和 .NET Core 开发博客项目 - 使用 abp cli 搭建项目 基于 abp vNext 和 .NET Core 开发博客项目 - 给项目瘦身,让它跑起来 ...
- 基于 abp vNext 和 .NET Core 开发博客项目 - Blazor 实战系列(八)
系列文章 基于 abp vNext 和 .NET Core 开发博客项目 - 使用 abp cli 搭建项目 基于 abp vNext 和 .NET Core 开发博客项目 - 给项目瘦身,让它跑起来 ...
- 基于 abp vNext 和 .NET Core 开发博客项目 - Blazor 实战系列(九)
系列文章 基于 abp vNext 和 .NET Core 开发博客项目 - 使用 abp cli 搭建项目 基于 abp vNext 和 .NET Core 开发博客项目 - 给项目瘦身,让它跑起来 ...
- 基于 abp vNext 和 .NET Core 开发博客项目 - Blazor 实战系列(一)
系列文章 基于 abp vNext 和 .NET Core 开发博客项目 - 使用 abp cli 搭建项目 基于 abp vNext 和 .NET Core 开发博客项目 - 给项目瘦身,让它跑起来 ...
- 基于 abp vNext 和 .NET Core 开发博客项目 - 终结篇之发布项目
系列文章 基于 abp vNext 和 .NET Core 开发博客项目 - 使用 abp cli 搭建项目 基于 abp vNext 和 .NET Core 开发博客项目 - 给项目瘦身,让它跑起来 ...
随机推荐
- scrapy框架简介与安装启动
Scrapy 是一个专业的.高效的爬虫框架,它使用专业的 Twisted 包(基于事件驱动的网络引擎包)高效地处理网络通信,使用 lxml(专业的 XML 处理包).cssselect 高效地提取 H ...
- DPDK开发环境搭建(学会了步骤适合各版本)
一.版本的选择 首先要说明的是,对于生产来说DPDK版本不是越高越好,如何选择合适的版本? 1.要选择长期支持的版本LTS(Long Term Support) 2.根据当前开发的系统环境选择 可以在 ...
- LightOJ1030 Discovering Gold
题目链接:https://vjudge.net/problem/LightOJ-1030 知识点: 概率与期望 解题思路: 设某一个点 \(i\) 能到达的点的个数为 \(x\),其上有金 \(g\) ...
- 环境篇:Zeppelin
环境篇:Zeppelin Zeppelin 是什么 Apache Zeppelin 是一个让交互式数据分析变得可行的基于网页的开源框架.Zeppelin提供了数据分析.数据可视化等功能. Zeppel ...
- HTML特殊符号整理
往网页中输入特殊字符,需在html代码中加入以&开头的字母组合或以&#开头的数字.下面就是以字母或数字表示的特殊符号大全. ...
- ES[7.6.x]学习笔记(十)聚合查询
聚合查询,它是在搜索的结果上,提供的一些聚合数据信息的方法.比如:求和.最大值.平均数等.聚合查询的类型有很多种,每一种类型都有它自己的目的和输出.在ES中,也有很多种聚合查询,下面我们看看聚合查询的 ...
- APP定位元素之UiSelector
1.UiSelector 类介绍 功能:通过各种属性与节点关系定位组件 操作步骤:找到对象->操作对象 2.四中匹配关系的介绍 (1)完全匹配 (2)包含匹配 (3)正则匹配 (4)起始匹 例子 ...
- 8.Hash集合类型操作使用
数据类型Hash (1)介绍 hash数据类型存储的数据与mysql数据库中存储的一条记录极为相似 Redis本身就类似于Hash的存储结构,分为key-value键值对,实际上它的Hash数据就好像 ...
- Beta冲刺 ——5.27
这个作业属于哪个课程 软件工程 这个作业要求在哪里 Beta冲刺 这个作业的目标 Beta冲刺 作业正文 正文 github链接 项目地址 其他参考文献 无 一.会议内容 1.组员一起学习Git分支管 ...
- 【Linux】将javaweb项目部署到CentOS的tomcat上
1.将项目打包成war包 build之后war文件就生成了. 2.拷贝war文件到CentOS的tomcat的项目文件夹中 用WinSCP将文件粘帖进这个文件夹中 /wocloud/tomcat_cl ...