R数据分析:PLS结构方程模型介绍,论文报告方法和实际操作
前面给大家写的关于结构方程模型的文章都是基于变量的方差协方差矩阵来探讨变量间关系的,叫做covariance-based SEM,今天给大家介绍一下另外一个类型的SEM,叫做偏最小二乘结构方差模型。一般来讲covariance-based SEM大家会用的更多,但是了解一下PLSSEM也挺好,所以本篇文章肯定依然值得您收藏。
它两的区别在哪?
Whereas CBSEM estimates model parameters so that the discrepancy between the estimated and sample covariance matrices is minimized, in PLS path models the explained variance of the endogenous latent variables is maximized by estimating partial model relationships in an iterative sequence of ordinary least squares (OLS) regressions.
CBSEM是让理论和数据吻合的原则来估计相应参数的,我们通过看模型的拟合优度可以知道我们设定的理论和收集来数据是不是吻合,从而判断理论是不是符合实际,是不是站得住脚,是一种非常典型的验证性思维;而PLSSEM则更强调解释更多因变量(内生变量)的变异,所以如果你做研究的主要目的不是要验证一个理论,就是说你对潜变量的测量和变量关系的理论结构已经有十足的把握,主要目的是探讨哪些外生变量是因变量的影响因素,这个时候PLSSEM相对来讲就更加适合。并且,PLS对数据分布没有要求,所以相对于CBSEM来讲它又被称为软结构方程模型。
PLSSEM本质上是通过循环迭代各个潜变量的权重的方法来估计模型参数的,它期望通过迭代达到解释因变量变异最大。所以一个完整的PLSSEM包括3个部分,1.测量模型,2.结构模型,还有一个叫加权策略weighting scheme,加权策略是PLSSEM独有的。
PLS path models consists of three components: the structural model, the measurement model and the weighting scheme.
与CBSEM不同,PLSSEM的测量模型又可以分为两种,一种是reflective measurements,叫做反映型测量模型,另外一种叫做构成型测量模型formative measurements
A model with all arrows pointing outwards is called a Mode A model – all LVs have reflective measurements. A model with all arrows pointing inwards is called a Mode B model – all LVs have formative measurements. A model containing both, formative and reflective LVs is referred to as MIMIC or a mode C model.
大家看一眼下面的图就可以明白两种测量模型的区别了:
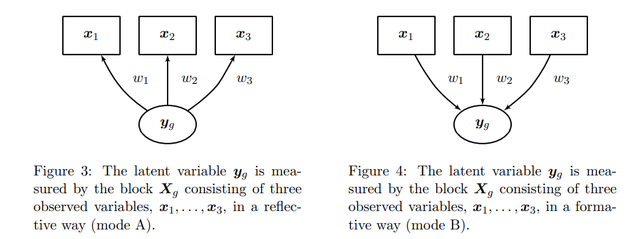
在反映型测量模型中,我们认为指标是潜变量导致的,潜变量通过指标反映出来;而在形成型测量模型中,我们认为是指标导致了潜变量,潜变量是由指标形成的:
Latent variables can be measured in two ways: • through their consequences or effects reflected on their indicators • through different indicators that are assumed to cause the latent variables
论文报告方法
今天我们看的论文是一篇已经公开发表的博士学位论文,作者是用SmartPLS软件做出来,在原文的结果部分作者报告了潜变量唯一度检验的两个特征根:

测量变量的信效度,具体指标有AVE,CR,α系数,communality:

还有各个显变量的载荷,还有bootstrap检验的结果,具体包括外部模型的检验和路径系数的检验,检验既报告统计量也报告p值:


上面很多指标的具体意思是什么大家可以自行去查阅文献,本文依然是重在实操,我现在要做的就是使用R语言和自己的数据对标上述报告内容,看看模型中需要报告的这些东西如何做出来。
实例操练
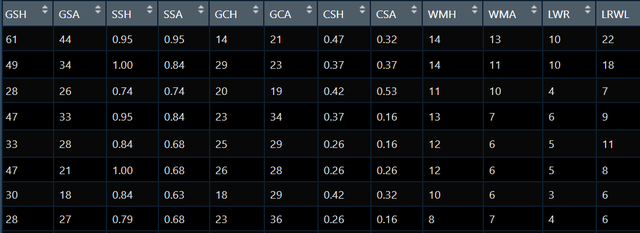
我现在有如下数据:
我自己想构建的理论模型如下图:
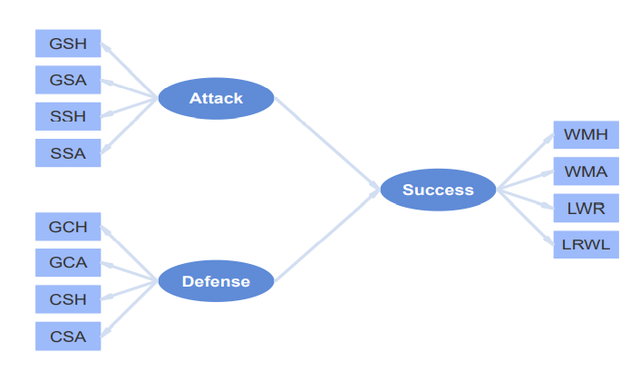
可以看到,上图中有3个潜变量,所有潜变量的测量变量都在我的数据集中,测量模型都是反映型测量。
怎么做呢?我们需要首先加载plspm包,然后设定测量模型和结构模型
一、结构模型的设定
我们已经知道我们的结构模型是Attack和Defense都会影响Success,这个结构我们需要用矩阵表示出来:
Attack = c(0, 0, 0)
Defense = c(0, 0, 0)
Success = c(1, 1, 0)
foot_path = rbind(Attack, Defense, Success)形成如下矩阵:
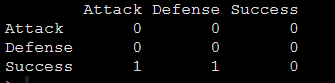
上图矩阵中为1的地方则是有关系的表示,上图的意思就是Attack和Defense都会影响Success。我们可以用innerplot()将我们的结构模型画出来
innerplot(foot_path)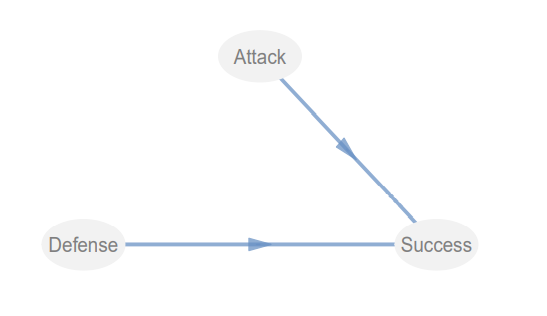
我们可以看到结构模型是没有问题的,到这儿我们的结构模型就算做好了。
二、测量模型的设定
我们需要指定数据集中的列的变量和潜变量的对应关系,比如1到4列测量指标对应一个潜变量,5到8对应第二个,9到12对应第三个,那么我们就可以写出代码:
foot_blocks = list(1:4, 5:8, 9:12)具体的顺序和结构模型中设定的潜变量顺序需要一致,也就是说1到4应该对应的Attack这个潜变量,5到8和9到12则对应Defense和Sucess这两个潜变量。
我们还需要设定测量模型的类型,因为我们3个潜变量都是反映型的测量模型,我们全部设定为A就行,如果是形成型测量模型的就应该设定为B,函数运行时默认取A,所以本例中我们也可以选择不设定直接默认就好。
结构模型和测量模型都设定好了我们就可以进行模型拟合了。
三、模型拟合
模型拟合需要用到的函数是plspm,大家可以去搜搜函数的说明:

可以看到,这个函数需要的主要参数为Data,就是我们的原始数据,还需要path_matrix,就是我们刚刚设定的结构模型的矩阵,还需要blocks,就是我们的潜变量对应的显变量,scheme这个是结构模型的加权策略,策略有3种,我们也可以直接默认。
拟合模型的时候我们按照函数说明写出如下代码:
foot_pls = plspm(data, foot_path, foot_blocks)
summary(foot_pls)运行代码后我们看输出,首先是需要报告的唯一度检验的两个特征根在图1种:
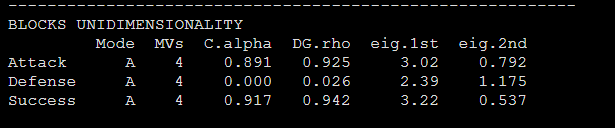
图1
然后是测量变量的信效度,包括AVE,communality在下图(图2)中:

图2
CR,α系数也在图1中。
还有显变量的载荷,以及路径系数的检验结果如下图:

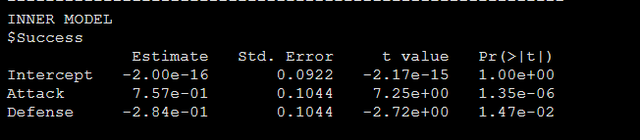
还有载荷系数的bootstrap检验结果:
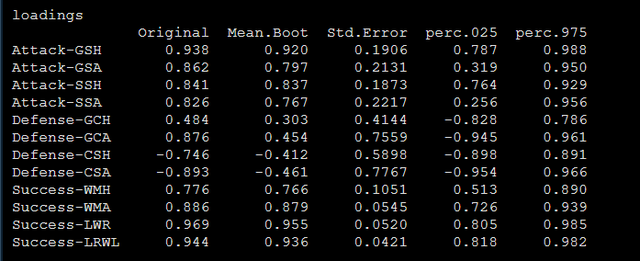
还有路径系数的bootstrap检验结果:

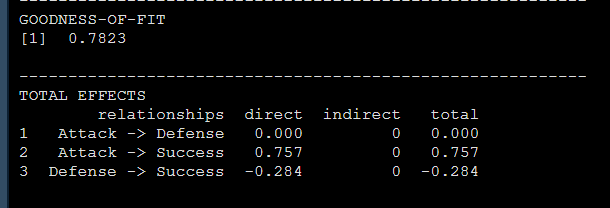
到这儿,一篇博士学位论文中的PLSsem分析部分就算完成了,其实R的结果中还有R方,总效应和效应分解等等如下,也可以选择性报告:
而且R还可以给我们的模型出图,直接把模型对象喂给plot函数就行:
plot(foot_pls)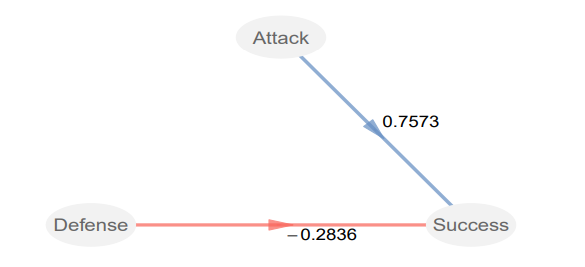
文章的最后再给大家分享一个模型图,与大家共勉:
小结
今天给大家写了PLS结构方程模型的做法和报告内容,希望对大家有所启发,感谢大家耐心看完,自己的文章都写的很细,重要代码都在原文中,希望大家都可以自己做一做,请转发本文到朋友圈后私信回复“数据链接”获取所有数据和本人收集的学习资料。如果对您有用请先记得收藏,再点赞分享。
也欢迎大家的意见和建议,大家想了解什么统计方法都可以在文章下留言,说不定我看见了就会给你写教程哦,有疑问欢迎私信。
R数据分析:PLS结构方程模型介绍,论文报告方法和实际操作的更多相关文章
- R数据分析:二分类因变量的混合效应,多水平logistics模型介绍
今天给大家写广义混合效应模型Generalised Linear Random Intercept Model的第一部分 ,混合效应logistics回归模型,这个和线性混合效应模型一样也有好几个叫法 ...
- R数据分析:潜类别轨迹模型LCTM的做法,实例解析
最近看了好多潜类别轨迹latent class trajectory models的文章,发现这个方法和我之前常用的横断面数据的潜类别和潜剖面分析完全不是一个东西,做纵向轨迹的正宗流派还是这个方法,当 ...
- R数据分析:纵向分类结局的分析-马尔可夫多态模型的理解与实操
今天要给大家分享的统计方法是马尔可夫多态模型,思路来源是下面这篇文章: Ward DD, Wallace LMK, Rockwood K Cumulative health deficits, APO ...
- R数据分析:生存分析与有竞争事件的生存分析的做法和解释
今天被粉丝发的文章给难住了,又偷偷去学习了一下竞争风险模型,想起之前写的关于竞争风险模型的做法,真的都是皮毛哟,大家见笑了.想着就顺便把所有的生存分析的知识和R语言的做法和论文报告方法都给大家梳理一遍 ...
- R数据分析:数据清洗的思路和核心函数介绍
好多同学把统计和数据清洗搞混,直接把原始数据发给我,做个统计吧,这个时候其实很大的工作量是在数据清洗和处理上,如果数据很杂乱,清洗起来是很费工夫的,反而清洗好的数据做统计分析常常就是一行代码的事情. ...
- R数据分析:如何给结构方程画路径图,tidySEM包详解
之前一直是用semPlot这个包给来进行结构方程模型的路径绘制,自从用了tidySEM这个包后就发现之前那个包不香了,今天就给大家分享一下tidySEM. 这个包的很大特点就是所有的画图原始都是存在数 ...
- R数据分析:临床预测模型中校准曲线和DCA曲线的意义与做法
之前给大家写过一个临床预测模型:R数据分析:跟随top期刊手把手教你做一个临床预测模型,里面其实都是比较基础的模型判别能力discrimination的一些指标,那么今天就再进一步,给大家分享一些和临 ...
- R数据分析:跟随top期刊手把手教你做一个临床预测模型
临床预测模型也是大家比较感兴趣的,今天就带着大家看一篇临床预测模型的文章,并且用一个例子给大家过一遍做法. 这篇文章来自护理领域顶级期刊的文章,文章名在下面 Ballesta-Castillejos ...
- R数据分析:如何简洁高效地展示统计结果
之前给大家写过一篇数据清洗的文章,解决的问题是你拿到原始数据后如何快速地对数据进行处理,处理到你基本上可以拿来分析的地步,其中介绍了如何选变量如何筛选个案,变量重新编码,如何去重,如何替换缺失值,如何 ...
- R数据分析:生存分析的列线图的理解与绘制详细教程
列线图作为一个非常简单明了的临床辅助决策工具,在临床中用的(发文章的)还是比较多的,尤其是肿瘤预后: Nomograms are widely used for cancer prognosis, p ...
随机推荐
- Wordle For Linux 2.0 | Windows 2.2.0
2.2.0 更新时间:2024/8/2 Click to Download | Linux 2.0 | Windows 2.2.0 2.2.0 版本已开源,详见压缩包 2.1.1 存在问题:答案显示未 ...
- Readme3.0 Final
Download Using 解压后放于不明显的地方 打开Devc++,点击 工具 > 编译选项 > 目录,在 C包含文件 与 C++包含文件 中复制完整路径并添加 选中刚添加的路径后,点 ...
- push_back和 emplace_back背后的逻辑
push_back 与 emplace_back 的区别 push_back: 功能:将一个对象(或其副本)添加到 vector 的末尾. 参数:接受一个对象(或其副本)的引用. 过程: 如果传入的是 ...
- 简单粗暴的实现 Blazor Server 登录鉴权
既然是简单粗暴,那么就不用关心诸如 IDentityServer4,OAuth 之类的组件,也不使用 AuthenticationStateProvider.IAuthService, razor 页 ...
- 统一携带 token
tokne 可以使用 vuex 和 本地存储处理 : 一些接口需要携带token为了避免代码的重复性,可以在请求拦截器统一加入token ,每次请求都会携带token参数,不需要token参数的接口也 ...
- Python之爬虫-全民k歌
import re import os import requests from aip import AipSpeech from pydub import AudioSegment APP_ID ...
- AvaloniaTCP-v1.0.0:学习使用Avalonia/C#进行TCP通讯的一个简单Demo
TCP通讯简介 TCP(传输控制协议,Transmission Control Protocol)是一种面向连接的.可靠的.基于字节流的传输层通信协议.它确保数据包按顺序传输,并在必要时进行重传,以保 ...
- 别再售卖 5块钱 的 Win10 激活码了,后果很严重
为了推广Windows 10系统(以下简称Win10),微软过去几年中一直给免费升级,Win7免费洗白的策略现在都还管用. 微软的大方也让很多人忘了Win10系统是要收费的,而且价格不便宜,国内的话, ...
- 《HelloGitHub》第 103 期
兴趣是最好的老师,HelloGitHub 让你对编程感兴趣! 简介 HelloGitHub 分享 GitHub 上有趣.入门级的开源项目. github.com/521xueweihan/HelloG ...
- CodeWF.EventBus:轻量级事件总线,让通信更流畅
1. CodeWF.EventBus EventBus(事件总线),用于解耦模块之间的通讯.本库(CodeWF.EventBus)适用于进程内消息传递(无其他外部依赖),与大家普遍使用的MediatR ...