Flink学习(六) 常用DataStreaming API
曾经提到过,Flink 很重要的一个特点是“流批一体”,然而事实上 Flink 并没有完全做到所谓的“流批一体”,即编写一套代码,可以同时支持流式计算场景和批量计算的场景。目前截止 1.10 版本依然采用了 DataSet 和 DataStream 两套 API 来适配不同的应用场景。
DateSet 和 DataStream 的区别和联系
在官网或者其他网站上,都可以找到目前 Flink 支持两套 API 和一些应用场景,但大都缺少了“为什么”这样的思考。
Apache Flink 在诞生之初的设计哲学是:用同一个引擎支持多种形式的计算,包括批处理、流处理和机器学习等。尤其是在流式计算方面,Flink 实现了计算引擎级别的流批一体。那么对于普通开发者而言,如果使用原生的 Flink ,直接的感受还是要编写两套代码。
整体架构如下图所示:

在 Flink 的源代码中,我们可以在 flink-java 这个模块中找到所有关于 DataSet 的核心类,DataStream 的核心实现类则在 flink-streaming-java 这个模块。

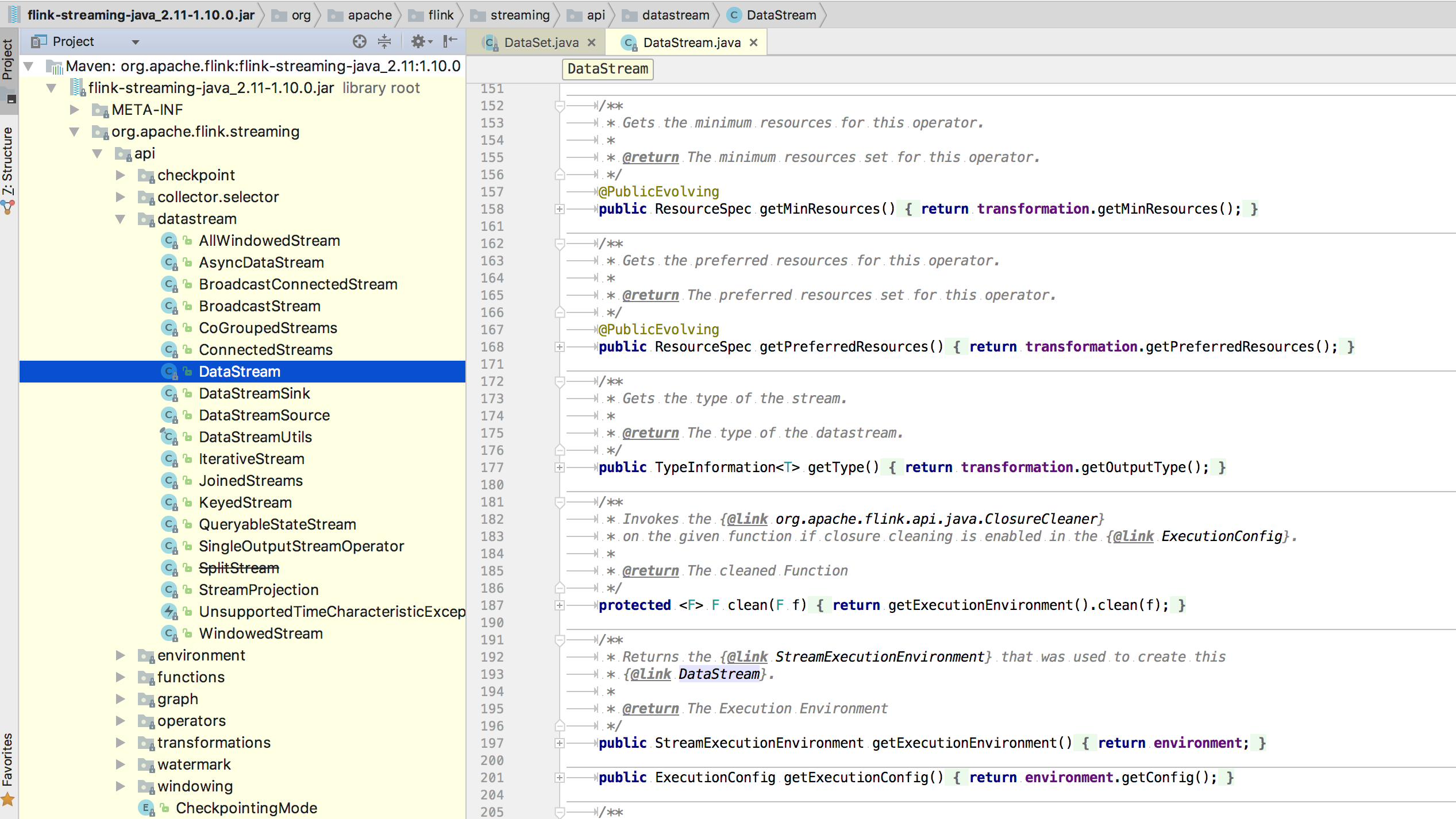
在上述两张图中,我们分别打开 DataSet 和 DataStream 这两个类,可以发现,二者支持的 API 都非常丰富且十分类似,比如常用的 map、filter、join 等常见的 transformation 函数。
我们在前面的课时中讲过 Flink 的编程模型,对于 DataSet 而言,Source 部分来源于文件、表或者 Java 集合;而 DataStream 的 Source 部分则一般是消息中间件比如 Kafka 等。
由于 Flink DataSet 和 DataStream API 的高度相似,并且 Flink 在实时计算领域中应用的更为广泛。所以下面我们详细讲解 DataStream API 的使用。
DataStream
我们先来回顾一下 Flink 的编程模型,在之前的课时中提到过,Flink 程序的基础构建模块是流(Streams)和转换(Transformations),每一个数据流起始于一个或多个 Source,并终止于一个或多个 Sink。数据流类似于有向无环图(DAG)。
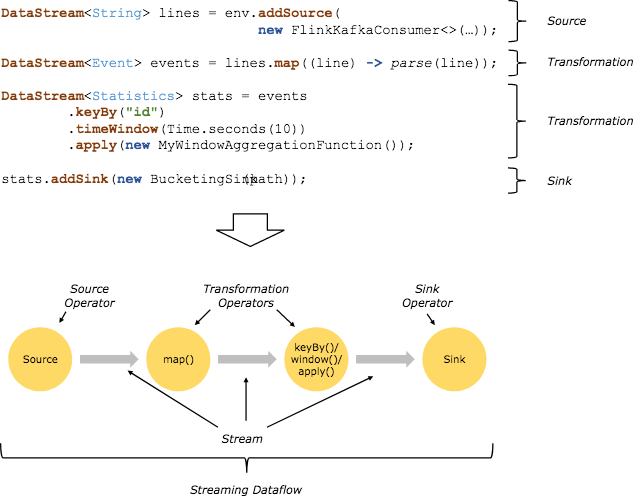
在之前中模仿了一个流式计算环境,我们选择监听一个本地的 Socket 端口,并且使用 Flink 中的滚动窗口,每 5 秒打印一次计算结果。
自定义实时数据源
在这里,我们利用 Flink 提供的自定义 Source 功能来实现一个自定义的实时数据源,具体实现如下:
public class MyStreamingSource implements SourceFunction<MyStreamingSource.Item> {
private boolean isRunning = true;
/**
* 重写run方法产生一个源源不断的数据发送源
* @param ctx
* @throws Exception
*/
@Override
public void run(SourceContext<Item> ctx) throws Exception {
while(isRunning){
Item item = generateItem();
ctx.collect(item);
//每秒产生一条数据
Thread.sleep(1000);
}
}
@Override
public void cancel() {
isRunning = false;
}
//随机产生一条商品数据
private Item generateItem(){
int i = new Random().nextInt(100);
Item item = new Item();
item.setName("name" + i);
item.setId(i);
return item;
}
class Item{
private String name;
private Integer id;
Item() {
}
public String getName() {
return name;
}
void setName(String name) {
this.name = name;
}
private Integer getId() {
return id;
}
void setId(Integer id) {
this.id = id;
}
@Override
public String toString() {
return "Item{" +
"name='" + name + '\'' +
", id=" + id +
'}';
}
}
}
class StreamingDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//获取数据源
DataStreamSource<MyStreamingSource.Item> text =
//注意:并行度设置为1,我们会在后面的课程中详细讲解并行度
env.addSource(new MyStreamingSource()).setParallelism(1);
DataStream<MyStreamingSource.Item> item = text.map(
(MapFunction<MyStreamingSource.Item, MyStreamingSource.Item>) value -> value);
//打印结果
item.print().setParallelism(1);
String jobName = "user defined streaming source";
env.execute(jobName);
}
}
在自定义的数据源中,实现了 Flink 中的 SourceFunction 接口,同时实现了其中的 run 方法,在 run 方法中每隔一秒钟随机发送一个自定义的 Item。
可以直接运行 main 方法来进行测试:
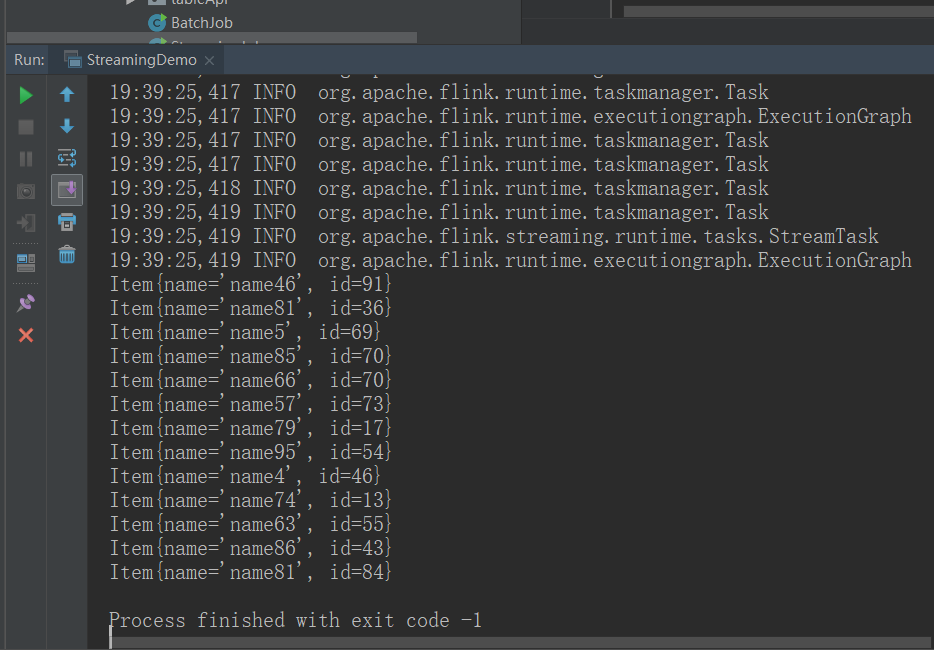
可以在控制台中看到,已经有源源不断地数据开始输出。下面我们就用自定义的实时数据源来演示 DataStream API 的使用。
Map
Map 接受一个元素作为输入,并且根据开发者自定义的逻辑处理后输出。

class StreamingDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//获取数据源
DataStreamSource<MyStreamingSource.Item> items = env.addSource(new MyStreamingSource()).setParallelism(1);
//Map
SingleOutputStreamOperator<Object> mapItems = items.map(new MapFunction<MyStreamingSource.Item, Object>() {
@Override
public Object map(MyStreamingSource.Item item) throws Exception {
return item.getName();
}
});
//打印结果
mapItems.print().setParallelism(1);
String jobName = "user defined streaming source";
env.execute(jobName);
}
}
我们只取出每个 Item 的 name 字段进行打印。

注意,Map 算子是最常用的算子之一,官网中的表述是对一个 DataStream 进行映射,每次进行转换都会调用 MapFunction 函数。从源 DataStream 到目标 DataStream 的转换过程中,返回的是 SingleOutputStreamOperator。当然了,我们也可以在重写的 map 函数中使用 lambda 表达式。
SingleOutputStreamOperator<Object> mapItems = items.map(
item -> item.getName()
);
甚至,还可以自定义自己的 Map 函数。通过重写 MapFunction 或 RichMapFunction 来自定义自己的 map 函数。
class StreamingDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//获取数据源
DataStreamSource<MyStreamingSource.Item> items = env.addSource(new MyStreamingSource()).setParallelism(1);
SingleOutputStreamOperator<String> mapItems = items.map(new MyMapFunction());
//打印结果
mapItems.print().setParallelism(1);
String jobName = "user defined streaming source";
env.execute(jobName);
}
static class MyMapFunction extends RichMapFunction<MyStreamingSource.Item,String> {
@Override
public String map(MyStreamingSource.Item item) throws Exception {
return item.getName();
}
}
}
此外,在 RichMapFunction 中还提供了 open、close 等函数方法,重写这些方法还能实现更为复杂的功能,比如获取累加器、计数器等。
FlatMap
FlatMap 接受一个元素,返回零到多个元素。FlatMap 和 Map 有些类似,但是当返回值是列表的时候,FlatMap 会将列表“平铺”,也就是以单个元素的形式进行输出。
SingleOutputStreamOperator<Object> flatMapItems = items.flatMap(new FlatMapFunction<MyStreamingSource.Item, Object>() {
@Override
public void flatMap(MyStreamingSource.Item item, Collector<Object> collector) throws Exception {
String name = item.getName();
collector.collect(name);
}
});
上面的程序会把名字逐个输出。我们也可以在 FlatMap 中实现更为复杂的逻辑,比如过滤掉一些我们不需要的数据等。
Filter
顾名思义,Fliter 的意思就是过滤掉不需要的数据,每个元素都会被 filter 函数处理,如果 filter 函数返回 true 则保留,否则丢弃。
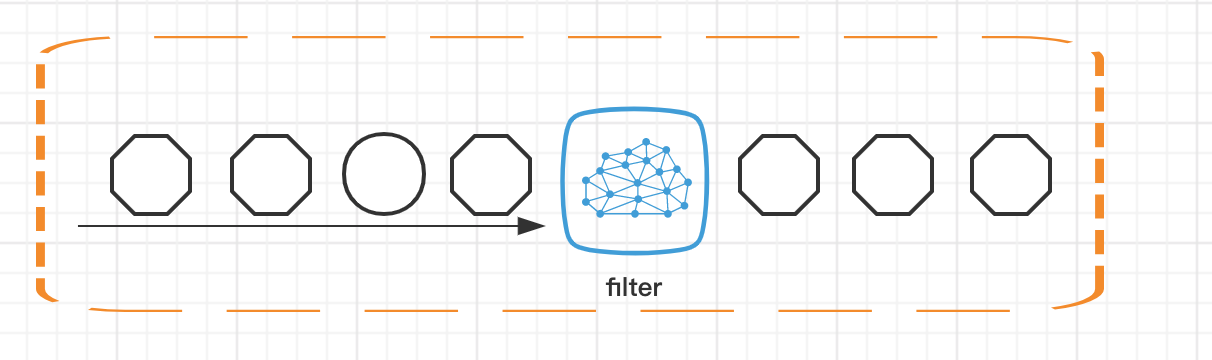
例如,我们只保留 id 为偶数的那些 item。
SingleOutputStreamOperator<MyStreamingSource.Item> filterItems = items.filter(new FilterFunction<MyStreamingSource.Item>() {
@Override
public boolean filter(MyStreamingSource.Item item) throws Exception {
return item.getId() % 2 == 0;
}
});
KeyBy
在介绍 KeyBy 函数之前,需要你理解一个概念:KeyedStream。 在实际业务中,我们经常会需要根据数据的某种属性或者单纯某个字段进行分组,然后对不同的组进行不同的处理。举个例子,当我们需要描述一个用户画像时,则需要根据用户的不同行为事件进行加权;再比如,我们在监控双十一的交易大盘时,则需要按照商品的品类进行分组,分别计算销售额。
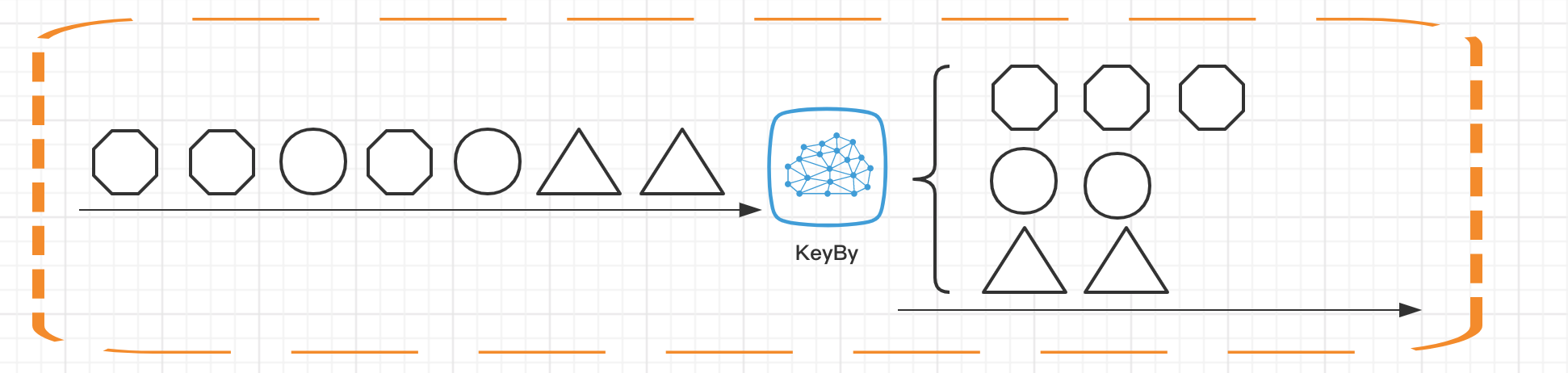
我们在使用 KeyBy 函数时会把 DataStream 转换成为 KeyedStream,事实上 KeyedStream 继承了 DataStream,KeyedStream 中的元素会根据用户传入的参数进行分组。
我们在第 02 课时中讲解的 WordCount 程序,曾经使用过 KeyBy:
// 将接收的数据进行拆分,分组,窗口计算并且进行聚合输出
DataStream<WordWithCount> windowCounts = text
.flatMap(new FlatMapFunction<String, WordWithCount>() {
@Override
public void flatMap(String value, Collector<WordWithCount> out) {
for (String word : value.split("\\s")) {
out.collect(new WordWithCount(word, 1L));
}
}
})
.keyBy("word")
.timeWindow(Time.seconds(5), Time.seconds
....
在生产环境中使用 KeyBy 函数时要十分注意!该函数会把数据按照用户指定的 key 进行分组,那么相同分组的数据会被分发到一个 subtask 上进行处理,在大数据量和 key 分布不均匀的时非常容易出现数据倾斜和反压,导致任务失败。
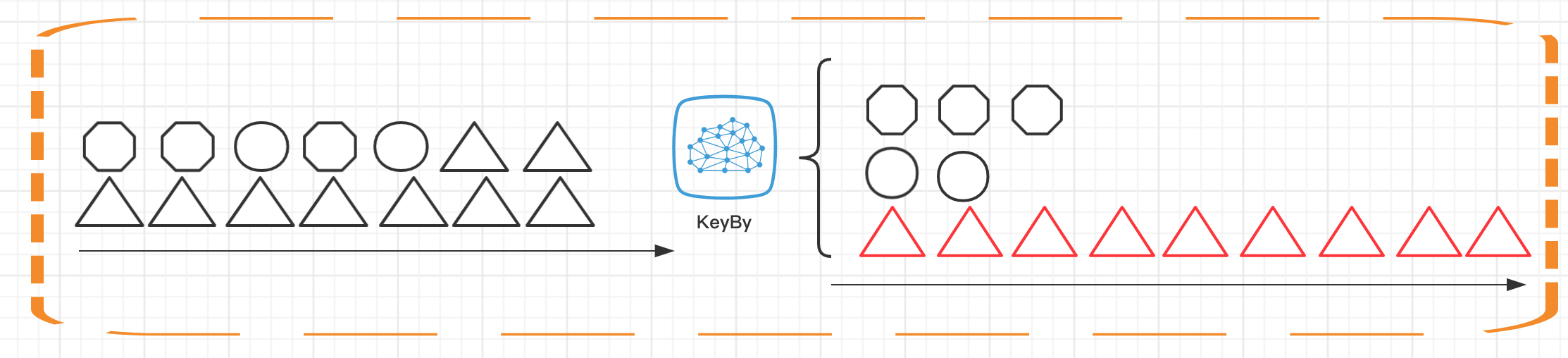
常见的解决方式是把所有数据加上随机前后缀,这些我们会在后面的课时中进行深入讲解。
Aggregations
Aggregations 为聚合函数的总称,常见的聚合函数包括但不限于 sum、max、min 等。Aggregations 也需要指定一个 key 进行聚合,官网给出了几个常见的例子:
keyedStream.sum(0);
keyedStream.sum("key");
keyedStream.min(0);
keyedStream.min("key");
keyedStream.max(0);
keyedStream.max("key");
keyedStream.minBy(0);
keyedStream.minBy("key");
keyedStream.maxBy(0);
keyedStream.maxBy("key");
在上面的这几个函数中,max、min、sum 会分别返回最大值、最小值和汇总值;而 minBy 和 maxBy 则会把最小或者最大的元素全部返回。
我们拿 max 和 maxBy 举例说明:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//获取数据源
List data = new ArrayList<Tuple3<Integer,Integer,Integer>>();
data.add(new Tuple3<>(0,1,0));
data.add(new Tuple3<>(0,1,1));
data.add(new Tuple3<>(0,2,2));
data.add(new Tuple3<>(0,1,3));
data.add(new Tuple3<>(1,2,5));
data.add(new Tuple3<>(1,2,9));
data.add(new Tuple3<>(1,2,11));
data.add(new Tuple3<>(1,2,13)); DataStreamSource<MyStreamingSource.Item> items = env.fromCollection(data);
items.keyBy(0).max(2).printToErr(); //打印结果
String jobName = "user defined streaming source";
env.execute(jobName);
我们直接运行程序,会发现奇怪的一幕:
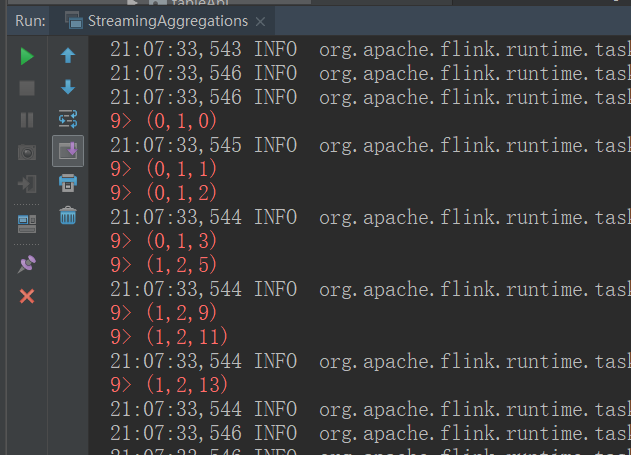
从上图中可以看到,我们希望按照 Tuple3 的第一个元素进行聚合,并且按照第三个元素取最大值。结果如我们所料,的确是按照第三个元素大小依次进行的打印,但是结果却出现了一个这样的元素 (0,1,2),这在我们的源数据中并不存在。
我们在 Flink 官网中的文档可以发现:
The difference between min and minBy is that min returns the minimum value, whereas minBy returns the element that has the minimum value in this field (same for max and maxBy).
文档中说:min 和 minBy 的区别在于,min 会返回我们制定字段的最大值,minBy 会返回对应的元素(max 和 maxBy 同理)。
网上很多资料也这么写:min 和 minBy 的区别在于 min 返回最小的值,而 minBy 返回最小值的key,严格来说这是不正确的。
min 和 minBy 都会返回整个元素,只是 min 会根据用户指定的字段取最小值,并且把这个值保存在对应的位置,而对于其他的字段,并不能保证其数值正确。max 和 maxBy 同理。
事实上,对于 Aggregations 函数,Flink 帮助我们封装了状态数据,这些状态数据不会被清理,所以在实际生产环境中应该尽量避免在一个无限流上使用 Aggregations。而且,对于同一个 keyedStream ,只能调用一次 Aggregation 函数。
Reduce
Reduce 函数的原理是,会在每一个分组的 keyedStream 上生效,它会按照用户自定义的聚合逻辑进行分组聚合。

List data = new ArrayList<Tuple3<Integer,Integer,Integer>>();
data.add(new Tuple3<>(0,1,0));
data.add(new Tuple3<>(0,1,1));
data.add(new Tuple3<>(0,2,2));
data.add(new Tuple3<>(0,1,3));
data.add(new Tuple3<>(1,2,5));
data.add(new Tuple3<>(1,2,9));
data.add(new Tuple3<>(1,2,11));
data.add(new Tuple3<>(1,2,13)); DataStreamSource<Tuple3<Integer,Integer,Integer>> items = env.fromCollection(data);
//items.keyBy(0).max(2).printToErr(); SingleOutputStreamOperator<Tuple3<Integer, Integer, Integer>> reduce = items.keyBy(0).reduce(new ReduceFunction<Tuple3<Integer, Integer, Integer>>() {
@Override
public Tuple3<Integer,Integer,Integer> reduce(Tuple3<Integer, Integer, Integer> t1, Tuple3<Integer, Integer, Integer> t2) throws Exception {
Tuple3<Integer,Integer,Integer> newTuple = new Tuple3<>(); newTuple.setFields(0,0,(Integer)t1.getField(2) + (Integer) t2.getField(2));
return newTuple;
}
}); reduce.printToErr().setParallelism(1);
Flink学习(六) 常用DataStreaming API的更多相关文章
- flink学习笔记:DataSream API
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- 《TomCat与Java Web开发技术详解》(第二版) 第四章节的学习总结--常用Servlet API
要开发Servlet,自然要掌握常用的servlet的相关API.通过此章节的学习,了解到如下常用API 1.Servlet接口--->GenericServlet抽象类(实现Servlet接口 ...
- python3.4学习笔记(六) 常用快捷键使用技巧,持续更新
python3.4学习笔记(六) 常用快捷键使用技巧,持续更新 安装IDLE后鼠标右键点击*.py 文件,可以看到Edit with IDLE 选择这个可以直接打开编辑器.IDLE默认不能显示行号,使 ...
- ROS常用库(四)API学习之常用common_msgs(下)
一.前言 承接ROS常用库(三)API学习之常用common_msgs(上). 二.sensor_msgs 1.sensor_msgs / BatteryState.msg #电源状态 uint8 P ...
- Flink实战(六) - Table API & SQL编程
1 意义 1.1 分层的 APIs & 抽象层次 Flink提供三层API. 每个API在简洁性和表达性之间提供不同的权衡,并针对不同的用例. 而且Flink提供不同级别的抽象来开发流/批处理 ...
- Hbase深入学习(六) Java操作HBase
Hbase深入学习(六) ―― Java操作HBase 本文讲述如何用hbase shell命令和hbase java api对hbase服务器进行操作. 先看以下读取一行记录hbase是如何进行工作 ...
- [Windows Phone]常用类库&API推荐
原文 [Windows Phone]常用类库&API推荐 简介: 把自己的应用程序搭建在稳定的API之上,这会使得我们在开发时能把精力都集中在程序的业务逻辑之上,避免重复造轮子,并且使得程序结 ...
- cesium 学习(六) 坐标转换
cesium 学习(六) 坐标转换 一.前言 在场景中,不管是二维还好还是三维也罢,只要涉及到空间概念都会提到坐标,坐标是让我们理解位置的一个非常有效的东西.有了坐标,我们能很快的确定位置相关关系,但 ...
- day 84 Vue学习六之axios、vuex、脚手架中组件传值
Vue学习六之axios.vuex.脚手架中组件传值 本节目录 一 axios的使用 二 vuex的使用 三 组件传值 四 xxx 五 xxx 六 xxx 七 xxx 八 xxx 一 axios的 ...
- 入门大数据---Flink学习总括
第一节 初识 Flink 在数据激增的时代,催生出了一批计算框架.最早期比较流行的有MapReduce,然后有Spark,直到现在越来越多的公司采用Flink处理.Flink相对前两个框架真正做到了高 ...
随机推荐
- Win10底部任务栏卡死的终极解决方法
原因:微软自带的资讯和兴趣因国内网络限制,造成失效. 解决方案:底部右键->资讯和兴趣->关闭. 以上仅限WIn10操作系统,win11操作系统以上忽略.
- vue3和elements创建应用
一. 创建环境 1. 创建D:\code\vue 文件夹 2. vscode打开文件夹 3. 打开终端,输入 npm install -g @vue/cli 4. 配置环境变量 终端输入:npm co ...
- 架构发展趋势以及 d2js 的未来
目前架构有几个热点方向:微服务, dubbo, Faas,还有 TiDB. 现在开发模式是前后端分离基本成为行规. 应该说以大部分企业业务量级.人员规模来说,要去和淘宝等大厂去对标是非常傻的.对大部分 ...
- shell内置字符串替换
shell变量赋值语法: 使用规则 解释单引号 所见即所得,即输出时会将单引号内的所有內容都原样输出,或者描述为单引号里面看到的是什么就会输出什么,这称为强引用双引号 (默认) 输出双引号内的所有内容 ...
- 3款.NET开源、功能强大的通讯调试工具,效率提升利器!
前言 今天大姚给大家分享3款.NET开源.功能强大的通讯调试工具,帮助大家提高通讯调试的效率和准确性. LLCOM LLCOM是一个.NET开源的.功能强大的串口调试工具.支持Lua自动化处理.串口调 ...
- 即时通讯技术文集(第36期):《跟着源码学IM》系列专题 [共12篇]
为了更好地分类阅读 52im.net 总计1000多篇精编文章,我将在每周三推送新的一期技术文集,本次是第36 期. [-1-] 跟着源码学IM(一):手把手教你用Netty实现心跳机制.断线重连机制 ...
- 阿里IM技术分享(四):闲鱼亿级IM消息系统的可靠投递优化实践
本文由阿里闲鱼技术团队景松分享,原题"到达率99.9%:闲鱼消息在高速上换引擎(集大成)",有修订和改动,感谢作者的分享. 1.引言 在2020年年初的时候接手了闲鱼的IM即时消息 ...
- IM开发干货分享:网易云信IM客户端的聊天消息全文检索技术实践
1.引言 在IM客户端的使用场景中,基于本地数据的全文检索功能扮演着重要的角色,最常用的比如:查找聊天记录.联系人,就像下图这样. ▲ 微信的聊天记录查找功能 类似于IM中的聊天记录查找.联系人搜索这 ...
- milvus操作
java 引入依赖 <dependency> <groupId>io.milvus</groupId> <artifactId>milvus-sdk-j ...
- SQL优化——深分页&排序
问题背景 在开发 Web 应用或处理数据库查询时,分页是一项常见需求.然而,当面对深度分页(即页码较大,偏移量较高的分页情况)时,性能问题往往接踵而至.比如对一些需要拉特定的页面查询.范围导出.范围计 ...