DeepSeek LLM
作者前言:
DeepSeek系列现在非常火,笔者决定主要梳理DeepSeekzui最重要的四代版本:
DeepSeek-LLM; DeepSeekMath; DeepSeek-V2; DeepSeek-V3; DeepSeek-R1 敬请期待。
Deepseek系列博客目录
| Model | 核心 | Date |
|---|---|---|
| DeepSeekLLM | 探究LLM Scalling Law | 2024.01 |
| DeepSeekMath | 提出GRPO | 2024.04 |
| DeepSeek-V2 | DeepSeekMoE, Multi-Head Latent Attention (MLA) | 2024.06 |
| DeepSeek-V3 | 新版DeepSeekMoE, MTP, 混合精度训练 | 2024.12 |
| DeepSeek-R1 | GRPO应用 | 2025.01 |
一、背景动机
开源社区的关注点:LLaMA 之后,开源社区主要关注训练固定规模的高质量 LLM(如 7B、13B、34B 和 70B),而对 LLM 的缩放定律研究探索较少。
缩放定律的重要性:当前开源 LLM 仍处于 AGI 发展的初期阶段,因此研究扩展定律对于未来发展至关重要。
缩放结论的分歧:早期研究(Hoffmann 等人,2022 年;Kaplan 等人,2020 年)对计算预算增长时的模型和数据扩展提出了不同的结论,并未充分解决超参数的影响。
研究目标:本研究广泛探索 LLM 的缩放行为,主要应用于 7B 和 67B 规模的模型,以奠定开源 LLM 未来扩展的基础。
关键研究内容:
- 研究 batch size 和 learning rate 随模型规模的缩放规律,发现其趋势。
- 研究数据和模型规模的缩放关系,揭示最佳的模型/数据扩展分配策略,并预测大规模模型的性能。
- 发现不同数据集的缩放定律存在显著差异,表明数据选择对缩放行为影响较大,在跨数据集推广缩放定律时需谨慎。
二、做了什么
- 收集 2 万亿个代币进行预训练,主要使用中文和英文。
- 在模型层面,我们通常遵循 LLaMA 的架构,但用多步学习率调度器取代了余弦学习率调度器,在保持性能的同时促进持续训练。
- 从不同来源收集了超过 100 万个实例用于监督微调 (SFT) (Ouyang et al., 2022)。
- 分享在数据消融技术中不同 SFT 策略和发现的经验
- 利用直接偏好优化 (DPO) (Rafailov et al., 2023) 来提高模型的对话性能。
三、预训练
主要目标: 全面增强数据集的丰富性和多样性
3.1 数据预处理
方法分为三个基本阶段:重复数据删除、过滤和重新混合。
其中,重复数据删除和重新混合阶段通过对唯一实例进行采样来确保数据的多样化表示。过滤阶段提高了信息的密度,从而实现了更高效和有效的模型训练。
重复数据删除
扩大了重复数据删除的范围。因为与在单个转储中删除重复数据相比,对整个 Common Crawl 语料库进行重复数据删除可以提高重复实例的删除率。表 1 表明,与 91 个转储相比,在 91 个转储中消除重复数据删除的文档数量是单个转储方法的四倍。
Note: "转储"(dump) 指的是某个时间点抓取到的完整网页数据的存储文件。例如,Common Crawl 定期抓取互联网上的大量网页,并将这些数据存储在不同时间的快照(转储,dump)中。
单个转储(Single Dump)指的是某次抓取的完整网页数据快照。例如:
2023 年 1 月的 Common Crawl 数据 → 这是一个单独的转储
2023 年 7 月的 Common Crawl 数据 → 这是另一个独立的转储
传统去重方法 主要在单个转储内部执行,即在同一次抓取的数据范围内查找并删除重复的内容。

过滤
在过滤阶段,我们专注于为文档质量评估制定稳健的标准。这涉及结合语言和语义评估的详细分析,从个人和全局角度提供数据质量视图。
重新混合
在重新混合阶段,我们调整了解决数据不平衡的方法,专注于增加代表性不足的域的存在。这项调整旨在实现更加平衡和包容的数据集,确保充分代表不同的观点和信息。
3.2 分词器 (Tokenizer) 设计与实现
实现了基于 Huggingface tokenizers 库 的 BBPE(Byte-level Byte Pair Encoding) 算法(详见;我的另一篇博客:https://www.cnblogs.com/zz-w/p/18696566),预分词策略与 GPT-2 相似,主要特点如下:
1. 预分词(Pre-tokenization)
目的:防止来自不同字符类别的 token 进行合并,提高分词合理性。
- 防止新行、标点符号和 CJK(中文-日语-韩语)字符合并
例如:"你好,world!"
- 无预分词 可能会生成错误的 token,如
["你好", ",world", "!"](错误合并) - 使用预分词,确保
["你好", ",", "world", "!"](正确拆分)4
- 无预分词 可能会生成错误的 token,如
Note: GPT-2中的预分词
浏览huggingface 的 transformers v4.30.2 里 GPT2Tokenizer 源码(https://huggingface.co/transformers/v3.0.2/_modules/transformers/tokenization_gpt2.html#GPT2Tokenizer),可发现GPT2tokenizer.init 中设置了以下正则表达式变量self.pat,它是用来做预分词处理的(pre-tokenizer)
self.pat 定义如下
import regex as re
# Should have added re.IGNORECASE so BPE merges can happen for capitalized versions of contractions
self.pat = re.compile(r"""'s|'t|'re|'ve|'m|'ll|'d| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+""")
注意这个是 re 是 regex 库而不是 re 库,regex 支持 ?\p 这类更复杂的正则表达式。
`'s|'t|'re|'ve|'m|'ll|'d`:这部分匹配常见的英文缩写和所有格形式,如 `'s`, `'t`, `'re`, `'ve`, `'m`, `'ll`, `'d`(例如,matches `it's`, `don't`, `they're`, `I've`, `I'm`, `we'll`, `I'd`)。
`?\p{L}+`:这部分使用 Unicode 属性匹配一个或多个任意语言的字母。`\p{L}` 匹配任何语言的字母字符。可选的前导空格由 `?` 表示。
`?\p{N}+`:类似地,这部分匹配一个或多个数字。`\p{N}` 匹配任何数字字符。数字前面的空格是可选的。
`?[^\s\p{L}\p{N}]+`:这部分匹配任何不是空格、字母或数字的字符序列。这可能包括标点符号、特殊字符等。字符序列前的空格是可选的。
`\s+(?!§)`:这个部分稍微复杂一些。`\s+` 匹配一个或多个空白字符,`(?!§)` 是一个负向前瞻断言,确保后面不跟着非空白字符。这样的组合意味着它匹配字符串末尾的空白字符。
`\s+`:匹配一个或多个空白字符。
总的来说,这个正则表达式设计用于匹配包括缩写、单词、数字、特殊符号和某些空白字符在内的多种模式。它似乎用于某种形式的文本处理或分词任务,可能是在自然语言处理的上下文中。使用 `re.findall(self.pat, text)` 将返回给定文本中所有匹配这些模式的子串的列表。
- 数字拆分为单个字符
2024 → ["2", "0", "2", "4"]- 这样有助于模型更好地处理数字,而不是将整个数字作为一个 token。
2. 词汇表设计
- 训练数据:分词器在 约 24GB 的多语言语料库 上进行训练,以适应不同语言的文本处理需求。
- 词汇表规模:
- 常规 token 数量:100,000
- 额外增加 15 个特殊标记(例如
[PAD],[UNK],[CLS],[SEP]等),使最终词汇表达到 100,015。 - 训练时词汇表大小配置为 102,400,确保训练期间的计算效率并为将来可能需要的任何其他特殊标记预留空间。
3.3 模型结构
DeepSeek LLM基本上遵循LLaMA的设计,DeepSeek LLM 采用了 Pre-Norm 结构,即在主要变换之前对输入进行归一化。这有助于稳定训练并提高收敛性。使用了SwiGLU作为Feed-Forward Network(FFN 的激活函数,FFN 的中间层维度设置为 $ \frac{8}{3}d_{model} $。这种缩放有助于平衡计算成本和模型容量。它还集成了RoPE。为了优化推理成本,67B模型使用分组查询注意力(GQA)而不是传统的多头注意力(MHA)。
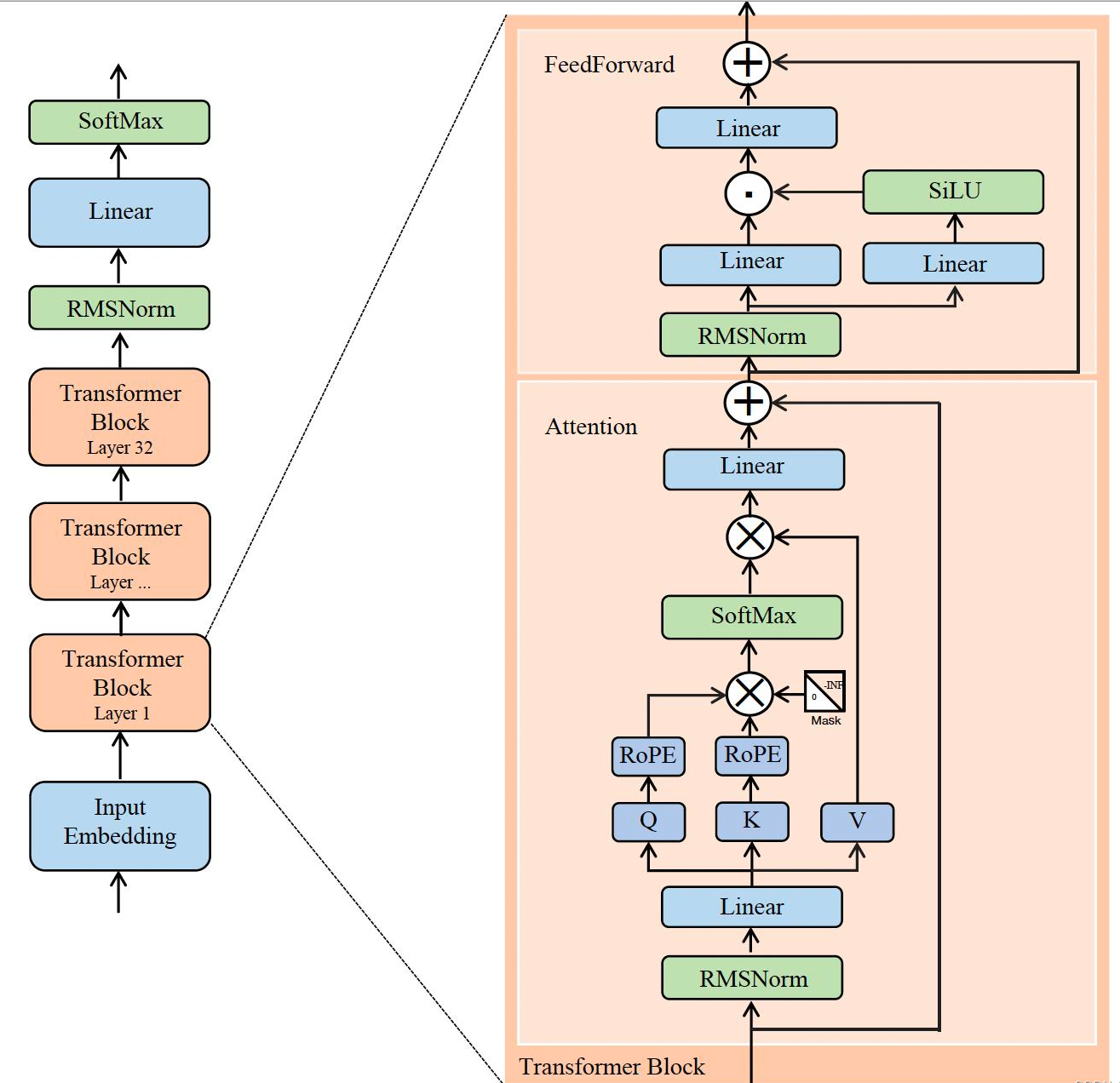
在宏观设计方面,DeepSeek LLM略有不同。DeepSeek LLM 7B是一个30层的网络,DeepSeek LLM 67B有95层。这些层调整在保持与其他开源模型参数一致的同时,也有助于优化训练和推理的模型管道划分。
与大多数使用分组查询注意力(GQA)的模型不同,deepseek扩大了67B模型的参数网络深度,而不是常见的拓宽FFN层中间宽度的做法,旨在获得更好的性能。详细的网络规格可以在表2中找到。

3.4 超参数
DeepSeek LLM的更多相关文章
- Hugging Face 每周速递: Chatbot Hackathon;FLAN-T5 XL 微调;构建更安全的 LLM
每一周,我们的同事都会向社区的成员们发布一些关于 Hugging Face 相关的更新,包括我们的产品和平台更新.社区活动.学习资源和内容更新.开源库和模型更新等,我们将其称之为「Hugging Ne ...
- 微软开源了一个 助力开发LLM 加持的应用的 工具包 semantic-kernel
在首席执行官萨蒂亚·纳德拉(Satya Nadella)的支持下,微软似乎正在迅速转变为一家以人工智能为中心的公司.最近微软的众多产品线都采用GPT-4加持,从Microsoft 365等商业产品到& ...
- Semantic Kernel 入门系列:🛸LLM降临的时代
不论你是否关心,不可否认,AGI的时代即将到来了. 在这个突如其来的时代中,OpenAI的ChatGPT无疑处于浪潮之巅.而在ChatGPT背后,我们不能忽视的是LLM(Large Language ...
- Schillace法则:使用LLM创建软件的最佳实践
LLM(大语言模型)的发展正在改变软件开发的方式. 以前,开发人员需要编写大量的代码来实现其意图,但现在,随着语言模型的发展,开发人员可以使用自然语言来表达他们的意图,而无需编写大量的代码.这使得软件 ...
- Semantic Kernel 入门系列:🪄LLM的魔法
ChatGPT 只是LLM 的小试牛刀,让人类能够看到的是机器智能对于语言系统的理解和掌握. 如果只是用来闲聊,而且只不过是将OpenAI的接口封装一下,那么市面上所有的ChatGPT的换皮应用都差不 ...
- 【河南省多校脸萌第六场 E】LLM找对象
[链接]点击打开链接 [题意] 在这里写题意 [题解] 把n个时间离散化一下. 对于不是相邻的点,在两者之间再加一个空格就好. 这样最多会有1000个位置. 则定义dp[i][k][j] 表示前i个数 ...
- LLM(大语言模型)解码时是怎么生成文本的?
Part1配置及参数 transformers==4.28.1 源码地址:transformers/configuration_utils.py at v4.28.1 · huggingface/tr ...
- SCNU ACM 2016新生赛决赛 解题报告
新生初赛题目.解题思路.参考代码一览 A. 拒绝虐狗 Problem Description CZJ 去排队打饭的时候看到前面有几对情侣秀恩爱,作为单身狗的 CZJ 表示很难受. 现在给出一个字符串代 ...
- Redis 学习笔记(C#)
Redis安装及简单操作 Windows下安装步骤: 1. 第一步当然是先下载咯~ 地址:https://github.com/dmajkic/redis/downloads (根据自己实际情况选择 ...
- webapi 中的本地登录
WebApi 身份验证方式 asp.net WebApi 中有三种身份验证方式 个人用户账户.用户可以在网站注册,也可以使用 google, facebook 等外部服务登录. 工作和学校账户.使用活 ...
随机推荐
- https证书中的subject alternative name字段作用及如何生成含该字段的证书
背景 最近,某个运维同事找到我,说测试环境的某个域名(他也在负责维护),假设域名为test.baidu.com,以前呢,证书都是用的生产的证书,最近不让用了.问为啥呢,说不安全,现在在整改了,因为证书 ...
- PHP的curl获取header信息
PHP的curl功能十分强大,简单点说,就是一个PHP实现浏览器的基础. 最常用的可能就是抓取远程数据或者向远程POST数据.但是在这个过程中,调试时,可能会有查看header的必要. echo ge ...
- FastAPI测试策略:参数解析单元测试
扫描二维码关注或者微信搜一搜:编程智域 前端至全栈交流与成长 探索数千个预构建的 AI 应用,开启你的下一个伟大创意 第一章:核心测试方法论 1.1 三层测试体系架构 # 第一层:模型级测试 def ...
- CentOS 版本选择:DVD、Everything、LiveCD、Minimal、NetInstall
CentOS 7.X,主要是下载的时候有很多版本供选择,如何选择? DVD版:这个是常用版本,就是普通安装版了,推荐大家安装.里面包含大量的常用软件,大部分情况下安装时无需再在线下载,体积为4G.Ev ...
- el-tree 动态图标
举个栗子 https://jsfiddle.net/taadis/x9crjsum/ https://jsrun.net/MYXKp - 上面看不了的,可以看这个...
- 如何在 Vim 里直接完成 Git 操作?
Vim 是 Linux 下一款很常用的文本编辑器,虽然它对初学者而言并不友好,但通过一些插件的配合,它可以被打造成一款很强大的 IDE .良许曾经介绍过三款很常用的插件,可点击以下链接查看: Vim ...
- volatile修饰全局变量,可以保证线程并发安全吗?
今天被人问到volatile能不能保证并发安全? 呵,这能难倒我? 直接上代码: public class ThreadTest { // 使用volatile修饰变量 private static ...
- springboot集成docker实现自动化构建镜像说明
springboot集成docker实现自动化构建镜像说明 文档说明 该文档仅包括通过配置springboot.docker.jenkins.git.appollo等实现持续构建,持续发布的功能,不包 ...
- SpringBoot整合Redis日志反复提示Redis重连问题
1. 报错信息如图: 2. 原因: spring boot 2.0之后spring-boot-starter-data-redis默认不再使用jedis连接redis,而是lettuce 这是lett ...
- php获取前一天,前一个月,前半年,前一年的时间戳
#获取前一小时strtotime("-1 hour") #获取前一天strtotime("-1 day") #获取前一周strtotime("-1 w ...