如何实现本地大模型与MCP集成
1.概述
本文将围绕构建兼具本地运行大型语言模型(LLM)与MCP 集成能力的 AI 驱动工具展开,为读者提供从原理到实践的全流程指南。通过深度整合本地大模型的隐私性、可控性优势与 MCP 工具的自动化执行能力,帮助用户以低门槛、高效率的方式,打造个性化 AI 助手,实现任务自动化 —— 无论是文档处理、数据分析,还是流程调度等场景,均可通过这一集成方案,借助大模型的语义理解与推理能力,结合 MCP 工具的标准化接口,构建端到端的智能工作流,让 AI 真正成为提升生产力的核心引擎。
2.内容
2.1 环境准备
- ollama
- python==3.13.2
- uv 0.6.12
- Linux / macOS
大模型服务部署
- 安装ollama服务框架
- 通过ollama部署所需的大语言模型
开发环境配置
- 准备Python 3.13运行环境(推荐使用最新稳定版)
- 安装mcp服务开发所需的Python包
开发工具推荐
- 使用uv工具链(新一代Python项目管理工具)
- 功能覆盖:
- Python版本管理
- 虚拟环境控制
- 依赖包管理
- 项目依赖维护
- 优势:提供全流程的Python开发环境管理方案
2.2 ollama安装
访问ollama地址:https://ollama.com/,然后根据自己的环境下载对应的安装包,如下图所示:
安装好ollama后,启动服务后,可以执行命令来检查服务是否启动成功,如下图所示:

然后,我们在ollama的模型页面选择我们需要下载的大模型,可以根据自身机器的性能来选择不同规模的模型,如图所示:

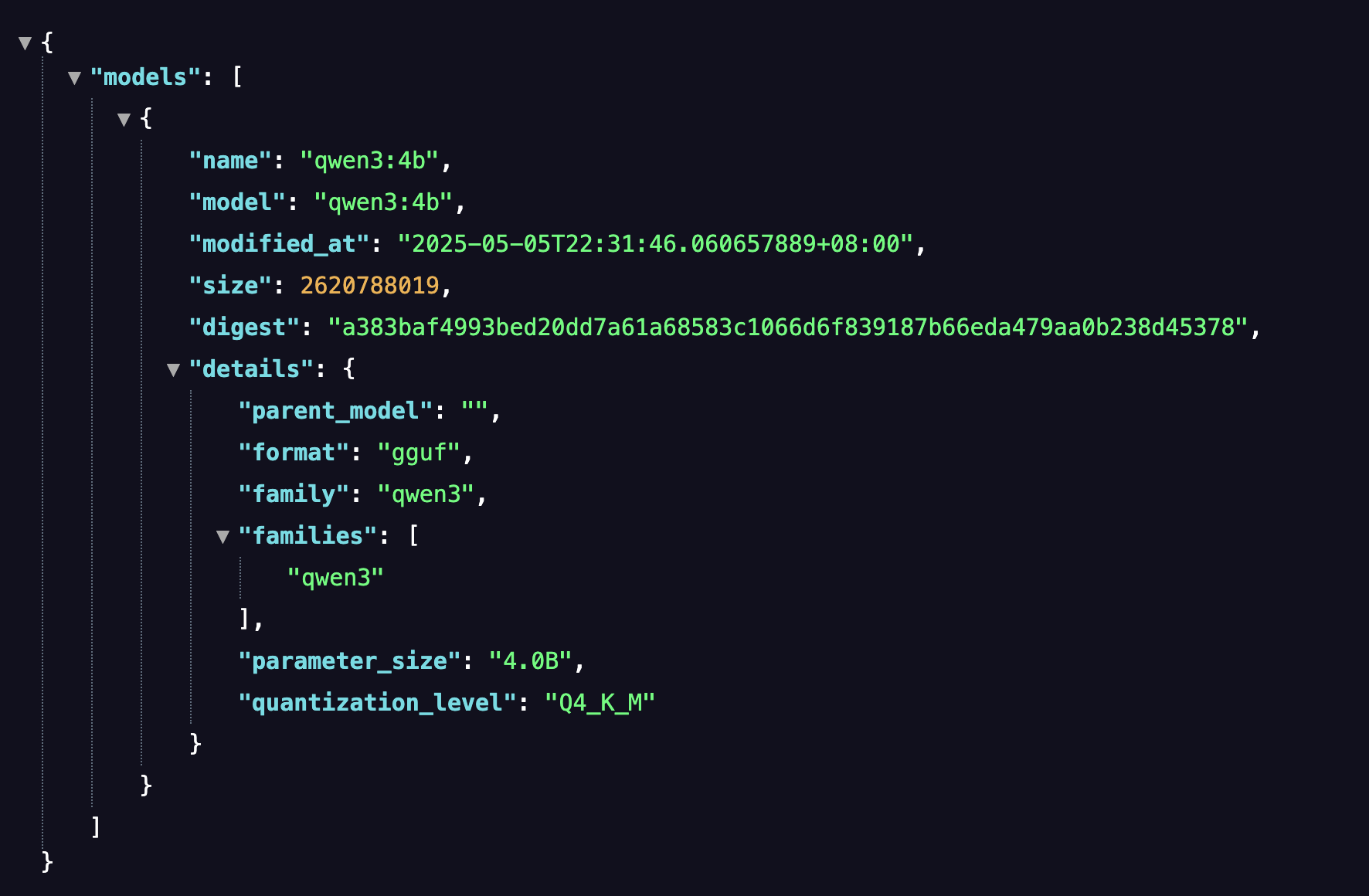
安装完成对应的模型后,可以通过http://localhost:11434/api/tags访问查看安装在本地的模型信息,如图所示:
2.3 安装uv工具
安装 uv(通常指 Rust 编写的超快 Python 包安装工具 uv,由 Astral 团队开发)的常用方法如下:
1. 使用官方安装脚本(推荐)
运行以下命令一键安装(适合 Linux/macOS):
curl -LsSf https://astral.sh/uv/install.sh | sh
安装后按提示将 uv 加入 PATH 环境变量,或直接重启终端。
2. 通过 pip 安装
如果已配置 Python 环境,可直接用 pip 安装:
pip install uv
3. 验证安装
运行以下命令检查是否成功:
uv --version
3.编写MCP服务
环境准备好之后,我们就可以开始编写MCP服务了,这里我们编写一个简单的MCP服务,用于读取本地文件,实现代码如下所示:
from mcp.server.fastmcp import FastMCP
from dotenv import load_dotenv
import os
from mcp.server.fastmcp import FastMCP
from starlette.applications import Starlette
from mcp.server.sse import SseServerTransport
from starlette.requests import Request
from starlette.routing import Mount, Route
from mcp.server import Server
import uvicorn load_dotenv() mcp = FastMCP("file_reader") # 定义要读取的文件路径
FILE_PATH = "/Users/smartloli/workspace/vscode/1/data.txt" @mcp.tool()
async def read_file():
"""
读取本地 /Users/smartloli/workspace/vscode/1/data.txt 文件的数据。 返回:
文件中的文本
"""
try:
with open(FILE_PATH, 'r', encoding='utf-8') as file:
content = file.read()
return content
except FileNotFoundError:
return f"Error: File {FILE_PATH} not found."
except Exception as e:
return f"An error occurred while reading the file: {str(e)}" # sse传输 def create_starlette_app(mcp_server: Server, *, debug: bool = False) -> Starlette:
"""Create a Starlette application that can serve the provided mcp server with SSE."""
sse = SseServerTransport("/messages/") async def handle_sse(request: Request) -> None:
async with sse.connect_sse(
request.scope,
request.receive,
request._send,
) as (read_stream, write_stream):
await mcp_server.run(
read_stream,
write_stream,
mcp_server.create_initialization_options(),
) return Starlette(
debug=debug,
routes=[
Route("/sse", endpoint=handle_sse),
Mount("/messages/", app=sse.handle_post_message),
],
) if __name__ == "__main__":
mcp_server = mcp._mcp_server import argparse parser = argparse.ArgumentParser(description='Run MCP SSE-based server')
parser.add_argument('--host', default='0.0.0.0', help='Host to bind to')
parser.add_argument('--port', type=int, default=8020,
help='Port to listen on')
args = parser.parse_args() # Bind SSE request handling to MCP server
starlette_app = create_starlette_app(mcp_server, debug=True) uvicorn.run(starlette_app, host=args.host, port=args.port)
然后,我们使用uv来启动MCP服务,执行命令如下:
uv run file_list.py --host 0.0.0.0 --port 8020
启动成功后,显示如下图所示信息:

4.集成LLM 和 MCP
准备好LLM服务和MCP服务之后,我们在Cherry Studio客户端上集成我们本地部署的LLM 和 MCP 服务,如下图所示:
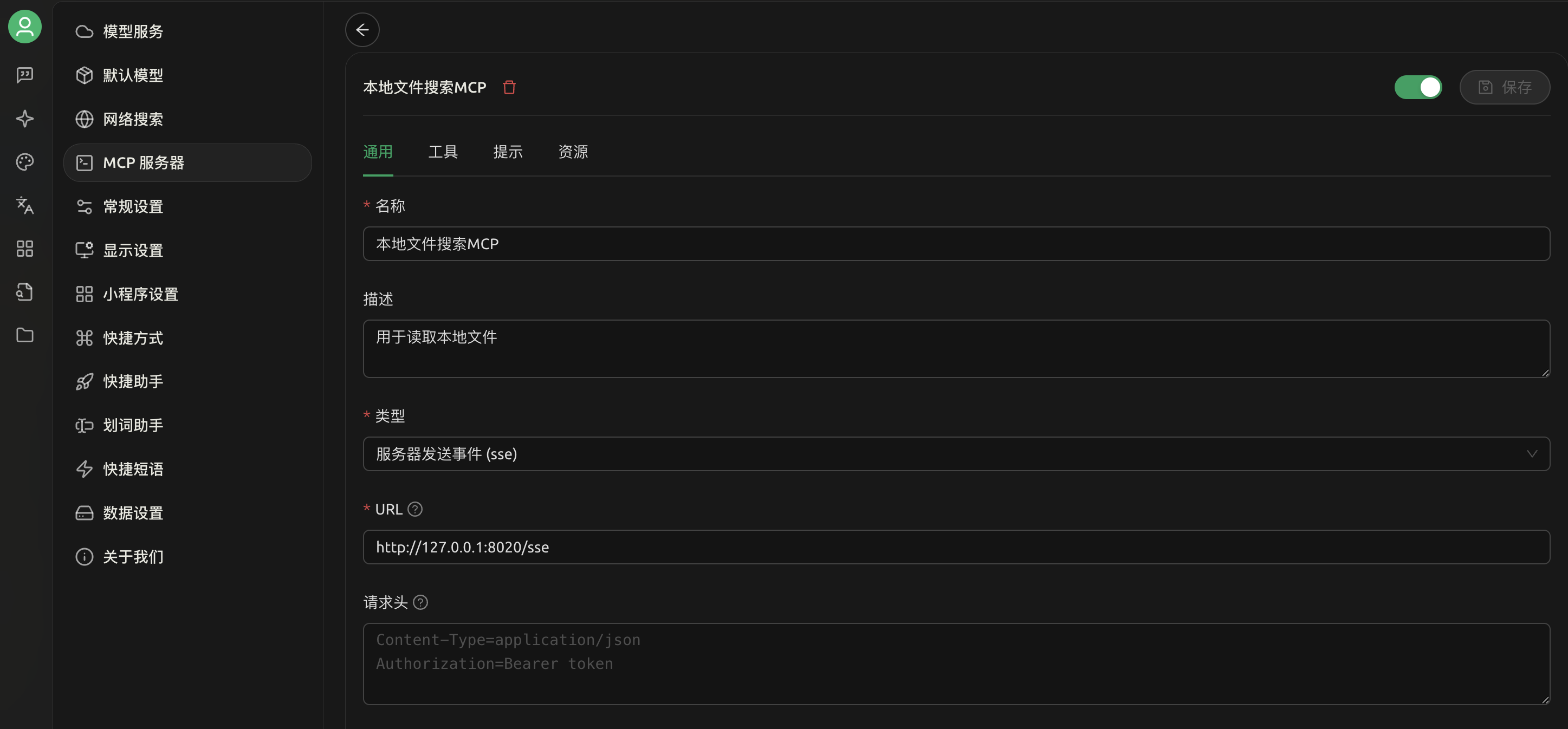
1.配置本地文件搜索MCP服务
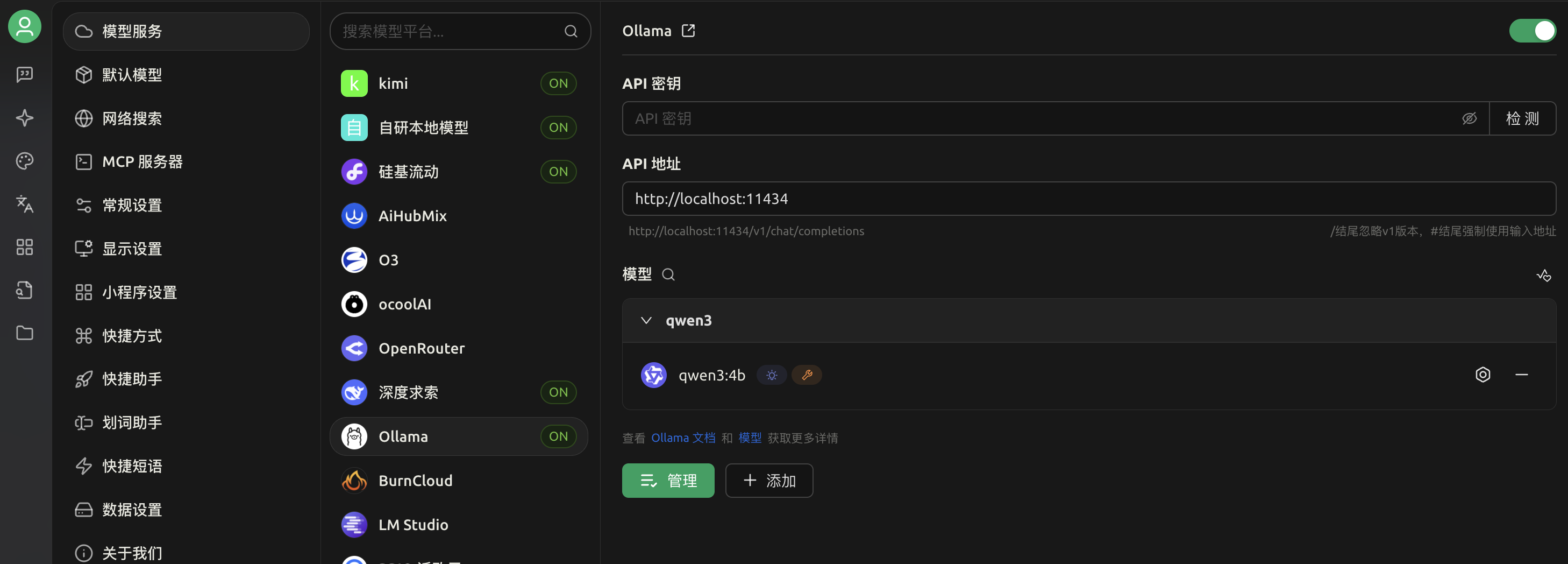
2.集成本地LLM
然后,在设置里面勾选“工具”就可以使用MCP服务了,如图所示:
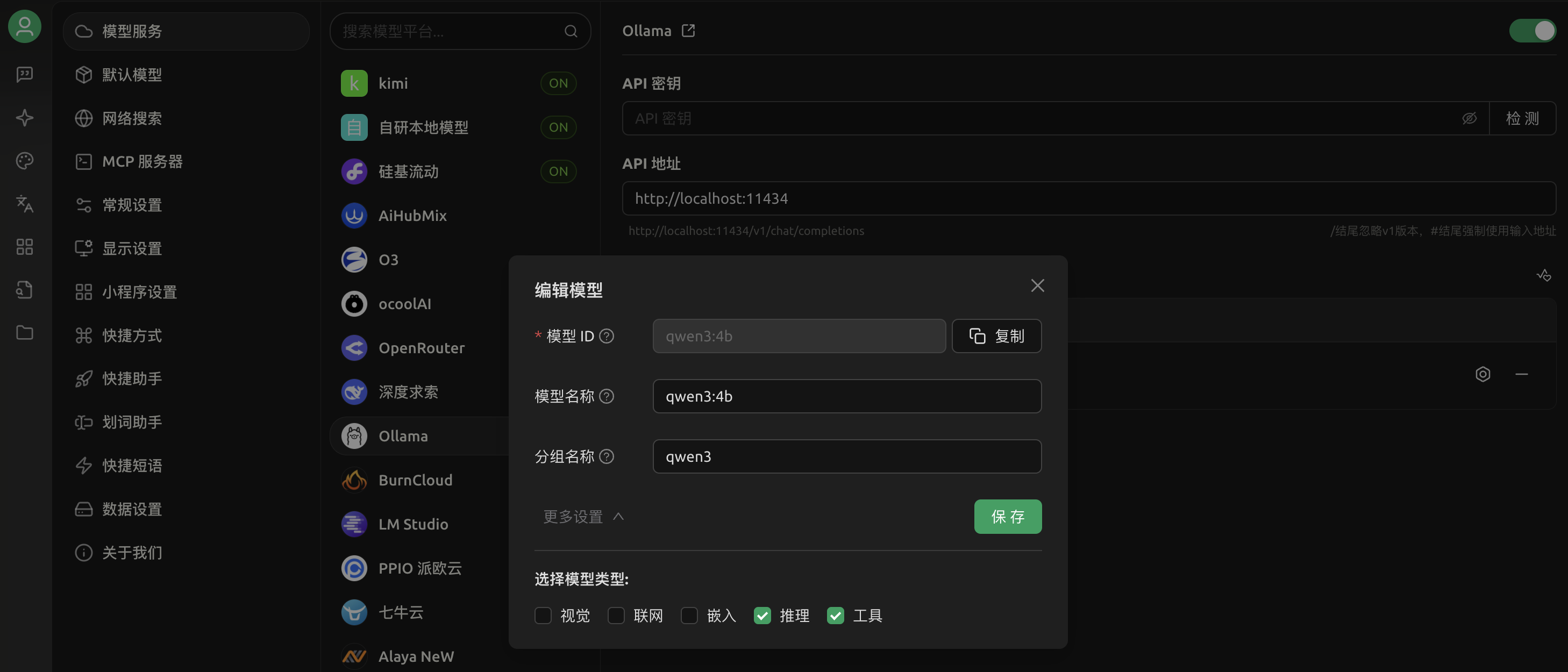
3.测试本地LLM回答
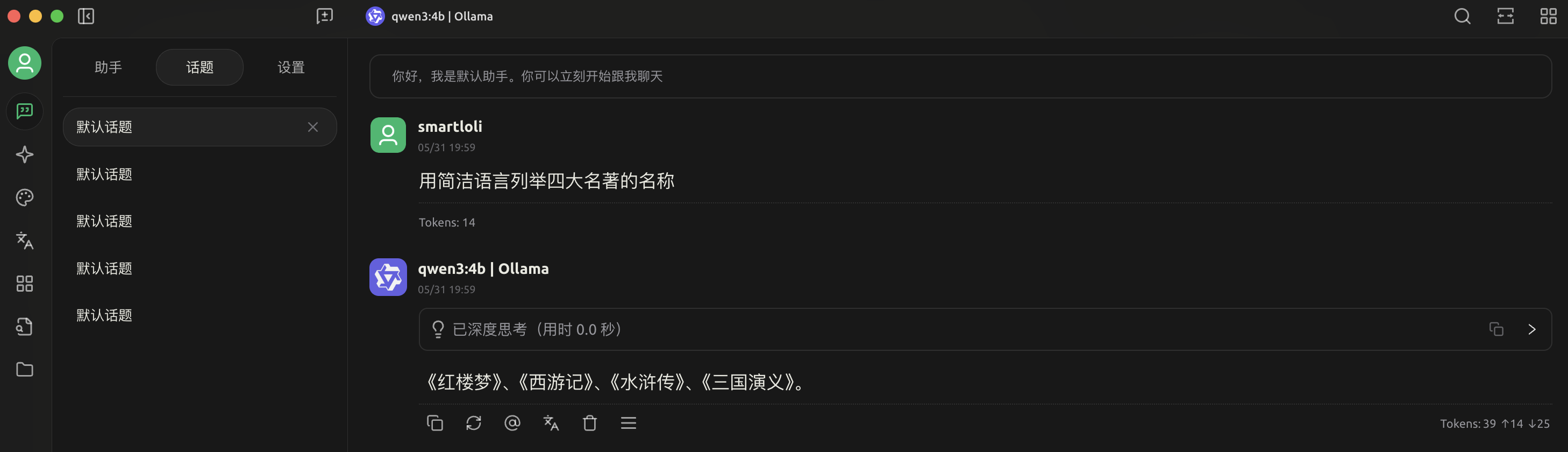
4.测试本地LLM & MCP调用
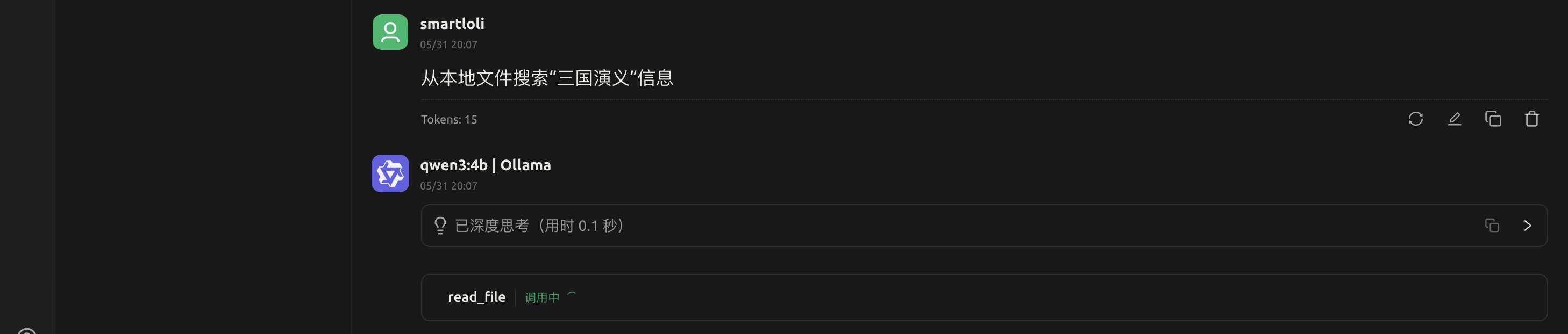
当我们开启MCP服务后,输入的搜索词中LLM会自行判断是否需要调用本地的MCP服务,这里我们通过搜索词触发LLM通过function去调用本地MCP服务。
5.总结
本文围绕本地大模型与模型上下文协议(MCP)的集成展开探索,重点揭示了通过 MCP 构建自定义 AI 工具的路径。通过适配不同开发环境与实际用例,MCP 为 AI 功能的跨场景整合提供了灵活框架,其核心优势体现在定制化能力上 —— 从模型选型到集成策略的全流程可调节性,使开发者能够基于具体需求打造精准适配的 AI 解决方案,展现了 MCP 在整合本地大模型时的多功能性与实践价值。
6.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
另外,博主出新书了《Hadoop与Spark大数据全景解析》、同时已出版的《深入理解Hive》、《Kafka并不难学》和《Hadoop大数据挖掘从入门到进阶实战》也可以和新书配套使用,喜欢的朋友或同学, 可以在公告栏那里点击购买链接购买博主的书进行学习,在此感谢大家的支持。关注下面公众号,根据提示,可免费获取书籍的教学视频。
如何实现本地大模型与MCP集成的更多相关文章
- 千亿参数开源大模型 BLOOM 背后的技术
假设你现在有了数据,也搞到了预算,一切就绪,准备开始训练一个大模型,一显身手了,"一朝看尽长安花"似乎近在眼前 -- 且慢!训练可不仅仅像这两个字的发音那么简单,看看 BLOOM ...
- DeepSpeed Chat: 一键式RLHF训练,让你的类ChatGPT千亿大模型提速省钱15倍
DeepSpeed Chat: 一键式RLHF训练,让你的类ChatGPT千亿大模型提速省钱15倍 1. 概述 近日来,ChatGPT及类似模型引发了人工智能(AI)领域的一场风潮. 这场风潮对数字世 ...
- 无插件的大模型浏览器Autodesk Viewer开发培训-武汉-2014年8月28日 9:00 – 12:00
武汉附近的同学们有福了,这是全球第一次关于Autodesk viewer的教室培训. :) 你可能已经在各种场合听过或看过Autodesk最新推出的大模型浏览器,这是无需插件的浏览器模型,支持几十种数 ...
- PowerDesigner 学习:十大模型及五大分类
个人认为PowerDesigner 最大的特点和优势就是1)提供了一整套的解决方案,面向了不同的人员提供不同的模型工具,比如有针对企业架构师的模型,有针对需求分析师的模型,有针对系统分析师和软件架构师 ...
- PowerDesigner 15学习笔记:十大模型及五大分类
个人认为PowerDesigner 最大的特点和优势就是1)提供了一整套的解决方案,面向了不同的人员提供不同的模型工具,比如有针对企业架构师的模型,有针对需求分析师的模型,有针对系统分析师和软件架构师 ...
- 华为高级研究员谢凌曦:下一代AI将走向何方?盘古大模型探路之旅
摘要:为了更深入理解千亿参数的盘古大模型,华为云社区采访到了华为云EI盘古团队高级研究员谢凌曦.谢博士以非常通俗的方式为我们娓娓道来了盘古大模型研发的"前世今生",以及它背后的艰难 ...
- 文心大模型api使用
文心大模型api使用 首先,我们要获取硅谷社区的连个key 复制两个api备用 获取Access Token 获取access_token示例代码 之后就会输出 作文创作 作文创作:作文创作接口基于文 ...
- AI大模型学习了解
# 百度文心 上线时间:2019年3月 官方介绍:https://wenxin.baidu.com/ 发布地点: 参考资料: 2600亿!全球最大中文单体模型鹏城-百度·文心发布 # 华为盘古 上线时 ...
- 谈谈模型融合之一 —— 集成学习与 AdaBoost
前言 前面的文章中介绍了决策树以及其它一些算法,但是,会发现,有时候使用使用这些算法并不能达到特别好的效果.于是乎就有了集成学习(Ensemble Learning),通过构建多个学习器一起结合来完成 ...
- 超详细!搭建本地大数据研发环境(16G内存+CDH)
工欲善其事必先利其器,在经过大量的理论学习以后,需要有一个本地的研发环境来进行练手.已经工作的可以不依赖于公司的环境,在家也可以随意的练习.而自学大数据的同学,也可以进行本地练习,大数据是一门偏实践的 ...
随机推荐
- Qt通过setProperty来达到设置控件的不同样式表
文章目录 前言 根据不同的属性显示不一样的样式 setProperty Q_PROPERTY和DynamicProperty 前言 最近在做项目的时候,找了一个开源的小控件,发现里面有一个设置样式的骚 ...
- windows使用Makefile时自动给可执行文件加上.exe后缀
APP := main 在使用makefile的时候,一般通过变量设置自己想要编译出来的可执行文件的名字 在windows平台编译出来的可执行文件是需要.exe后缀的 识别当前操作系统 通过识别当前的 ...
- yolov5 train报错:TypeError: expected np.ndarray (got numpy.ndarray)
前言 mac intel 机器上,使用 yolov5 物体检测训练时报错:TypeError: expected np.ndarray (got numpy.ndarray) 这个错误信息 TypeE ...
- go time包:秒、毫秒、纳秒时间戳输出
时间戳 10 位数的是以 秒 为单位: 13 位数的是以 毫秒 为单位: 19 位数的是以 纳秒 为单位: golang 中可以这样写: package main import ( "fmt ...
- linux安装protoc
protobuf 是做什么的? 专业的解答: Protocol Buffers 是一种轻便高效的结构化数据存储格式,可用于结构化数据串行化,很适合做数据存储或 RPC 数据交换格式.它可用于通讯协议. ...
- go包管理工具 govendor
govendor介绍 govendor 是 GoLang 常用的一个第三方包管理工具,它的出现解决了不同用户在 clone 同一个项目时从外部获取不同依赖库版本的问题. govendor会将项目需要的 ...
- codelite常用快捷键积累
博客地址:https://www.cnblogs.com/zylyehuo/ 编译整个工作空间 workplace Ctrl+shift+B 编译当前文件 file Ctrl+F7 编译项目 proj ...
- CAS和OAuth2.0区别
CAS和OAuth2.0区别 CAS (Central Authentication Service) 和 OAuth 2.0 都是身份验证和授权技术,但它们在工作原理和适用场景上有明显的差异. CA ...
- 如何每5分钟、10分钟或15分钟运行一次Cron计划任务
一个cron job是一个在指定时间段执行的任务.这些任务可以按分钟.小时.月.日.周.日或这些的任何组合来安排运行. Cron作业一般用于自动化系统维护或管理,例如备份数据库或数据.用最新的安全补丁 ...
- 【Python】导出docx格式Word文档中的文本、图片和附件等
[Python]导出docx格式Word文档中的文本.图片和附件等 零.需求 为批量批改学生在机房提交的实验报告,我需要对所有的实验文档内容进行处理.需要批量提取Word文档中的图片和附件以便进一步检 ...