hashtable底层
一、单线程环境下
底层:hash表结构 (数组 + 链表)
使用无参构造创建对象时 会默认长度11的数组 加载因子0.75
Hashtable<Object, Object> hashtable = new Hashtable<>();

添加第一个元素
hashtable.put("键","值");
根据键的哈希值计算出应存入的索引 例: 5;然后判断 5索引上是否为 null 如果为null 直接存入元素
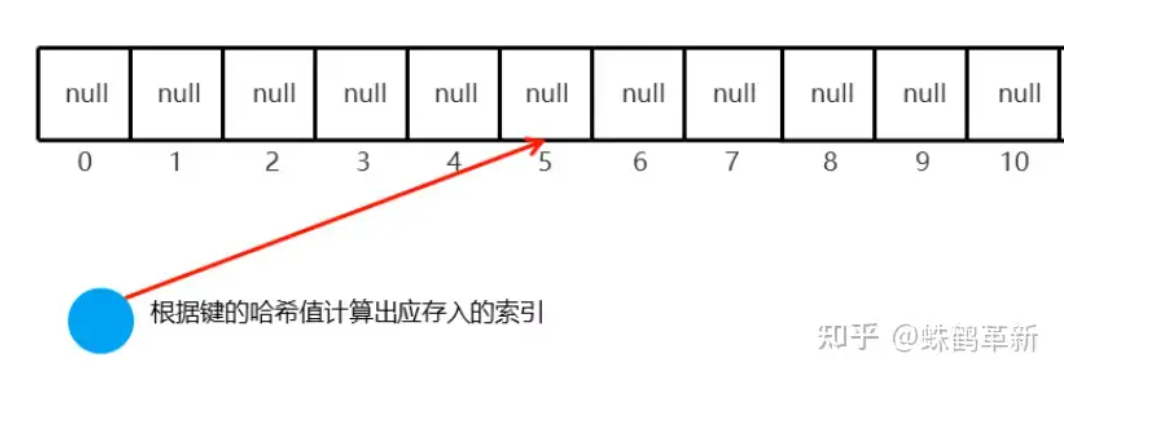
添加第二个元素
根据键的哈希值计算出应存入的索引 例: 8;然后判断 8索引上是否为 null 如果为null 直接存入元素
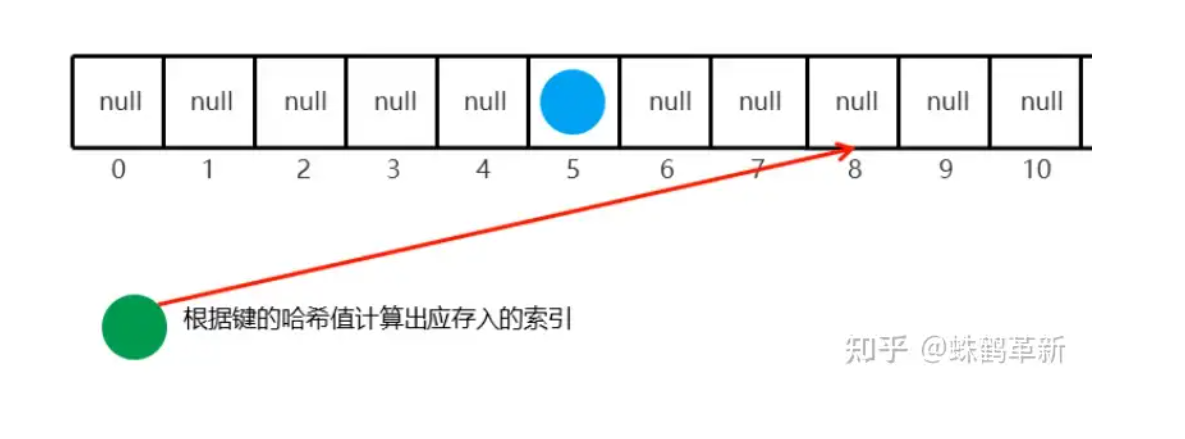
添加第三个元素
根据键的哈希值计算出应存入的索引 例: 5
然后判断 5索引上是否为 null
此时 5 索引上 已经有了一个元素 不为null ,则会调用equals方法比较键的属性值
如果一样,则覆盖,如果不一样,则存入数组,头插的形式,老元素挂在新元素下面 形成链表结构

二、多线程环境下
采用悲观锁的方式

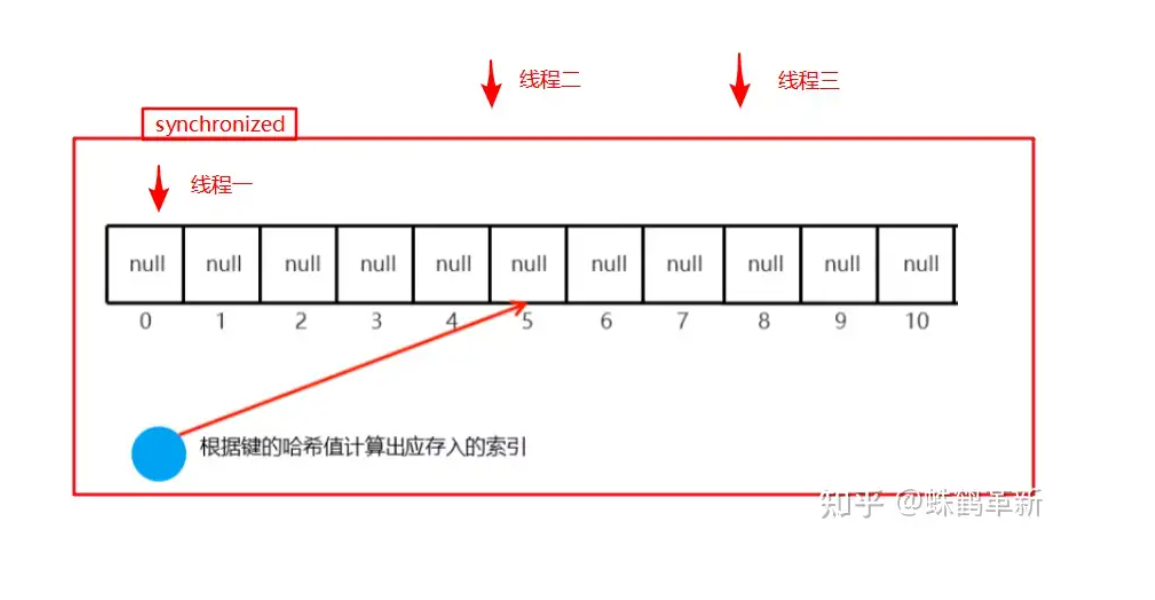
添加元素
多个线程添加元素时 ,线程一进入后 synchronized锁住整个数组 其他线程 等待锁释放 其他操作不变
三、JDK1.8 hashtable的put方法的底层源码
在 JDK 1.8 中,Hashtable 的 put 方法是线程安全的哈希表操作核心方法之一,其源码设计体现了同步机制、哈希冲突解决和动态扩容等关键逻辑。以下是详细的源码解析和实现原理:
1、put 方法源码
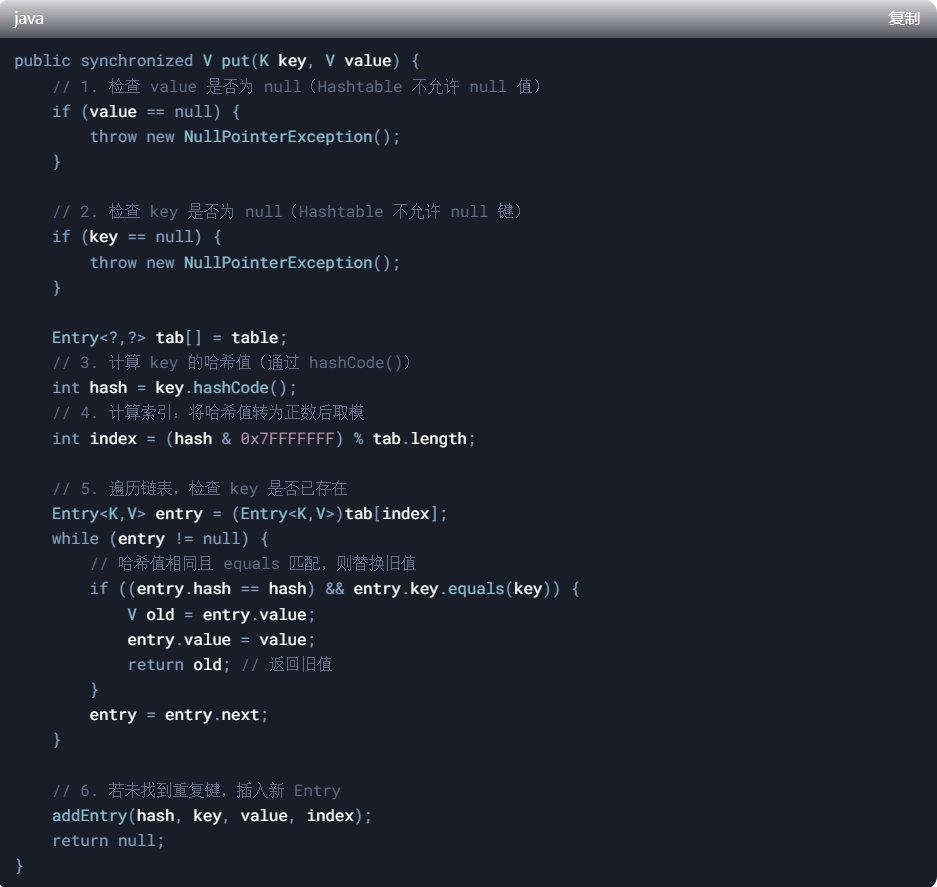
关键步骤解析
a、线程安全保证
put 方法被 synchronized 修饰,同一时间仅允许一个线程操作,确保线程安全
缺点:在高并发场景下,同步粒度较粗,可能导致性能瓶颈(相比之下,ConcurrentHashMap 使用分段锁优化)
b、空值检查
强制约束:Hashtable 不允许 key 或 value 为 null,直接抛出 NullPointerException
对比:HashMap 允许 null 键和值,但需特殊处理(如 hashCode 为 0)
c、哈希值计算
通过 key.hashCode() 获取哈希值
哈希修正:hash & 0x7FFFFFFF 将哈希值转为正数(索引必须非负)
d、索引定位
通过 (hash % tab.length) 计算索引(tab.length 是哈希表数组长度)
问题:取模运算可能效率较低(HashMap 使用位运算优化)
e、链表遍历
在计算出的索引位置遍历链表,检查是否存在相同键:
若存在,直接替换旧值并返回旧值
若不存在,调用 addEntry 插入新节点
2、插入新节点(addEntry)
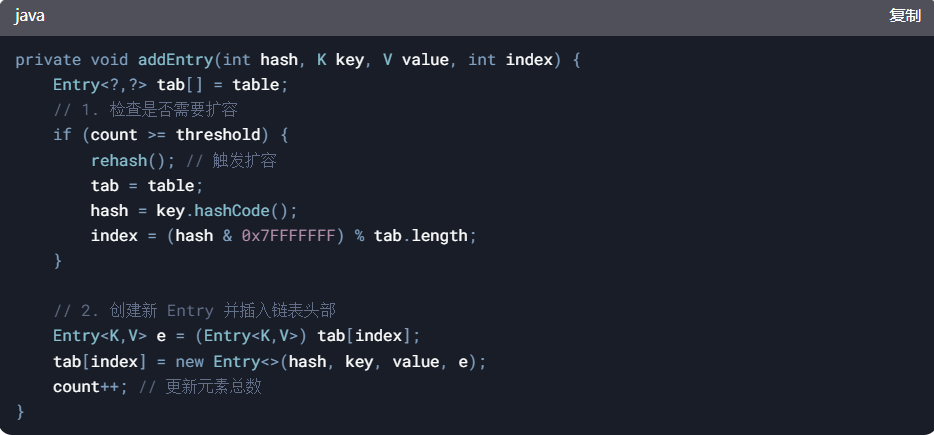
扩容条件:当元素数量 count 超过阈值 threshold(默认 capacity * loadFactor)
头插法:新节点插入链表头部(JDK 1.8 的 HashMap 改为尾插法避免循环链表问题)
3、扩容机制(rehash)
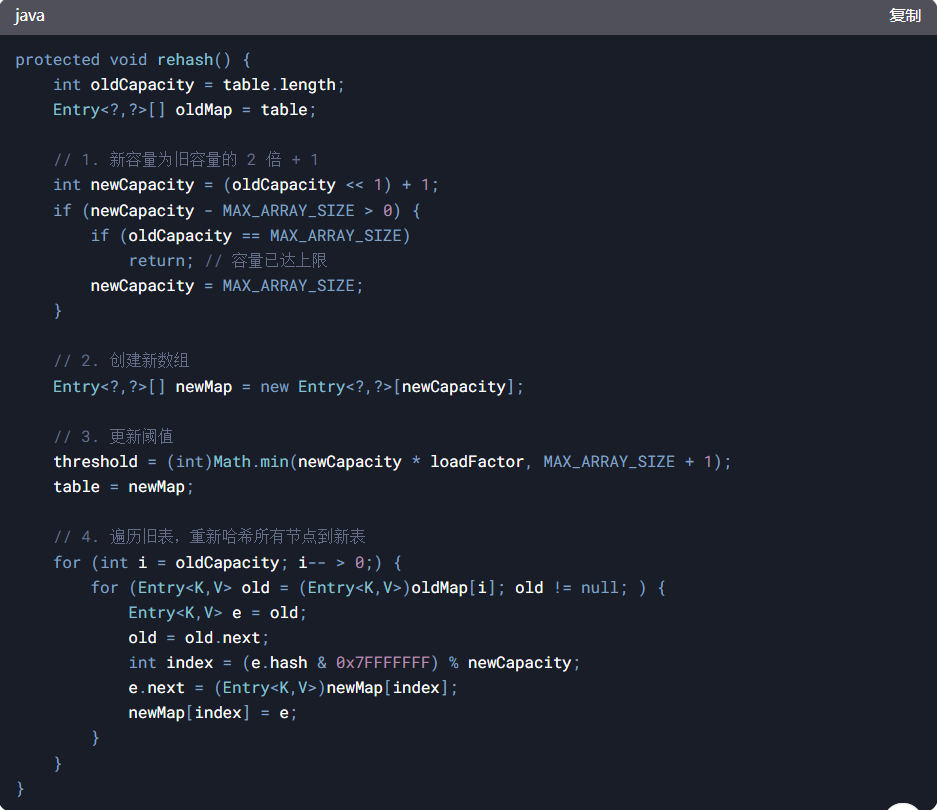
新容量:newCapacity = 2 * oldCapacity + 1(非严格的 2 倍扩容)
重新哈希:所有节点需重新计算索引,并迁移到新数组
四、put方法的整个处理流程分析
put方法的整个处理流程是:计算key的hash值,根据hash值获得key在table数组中的索引位置,然后迭代该key处的Entry链表,若该链表中存在一个这个的key对象,那么就直接替换其value值即可,
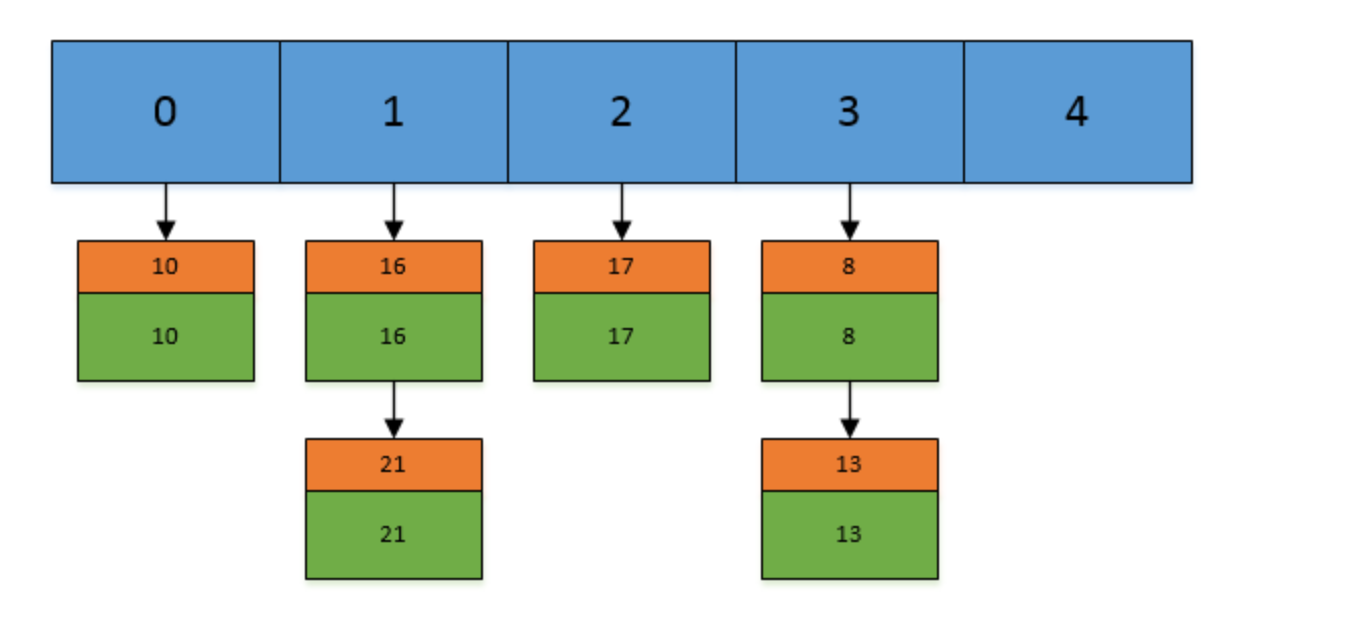
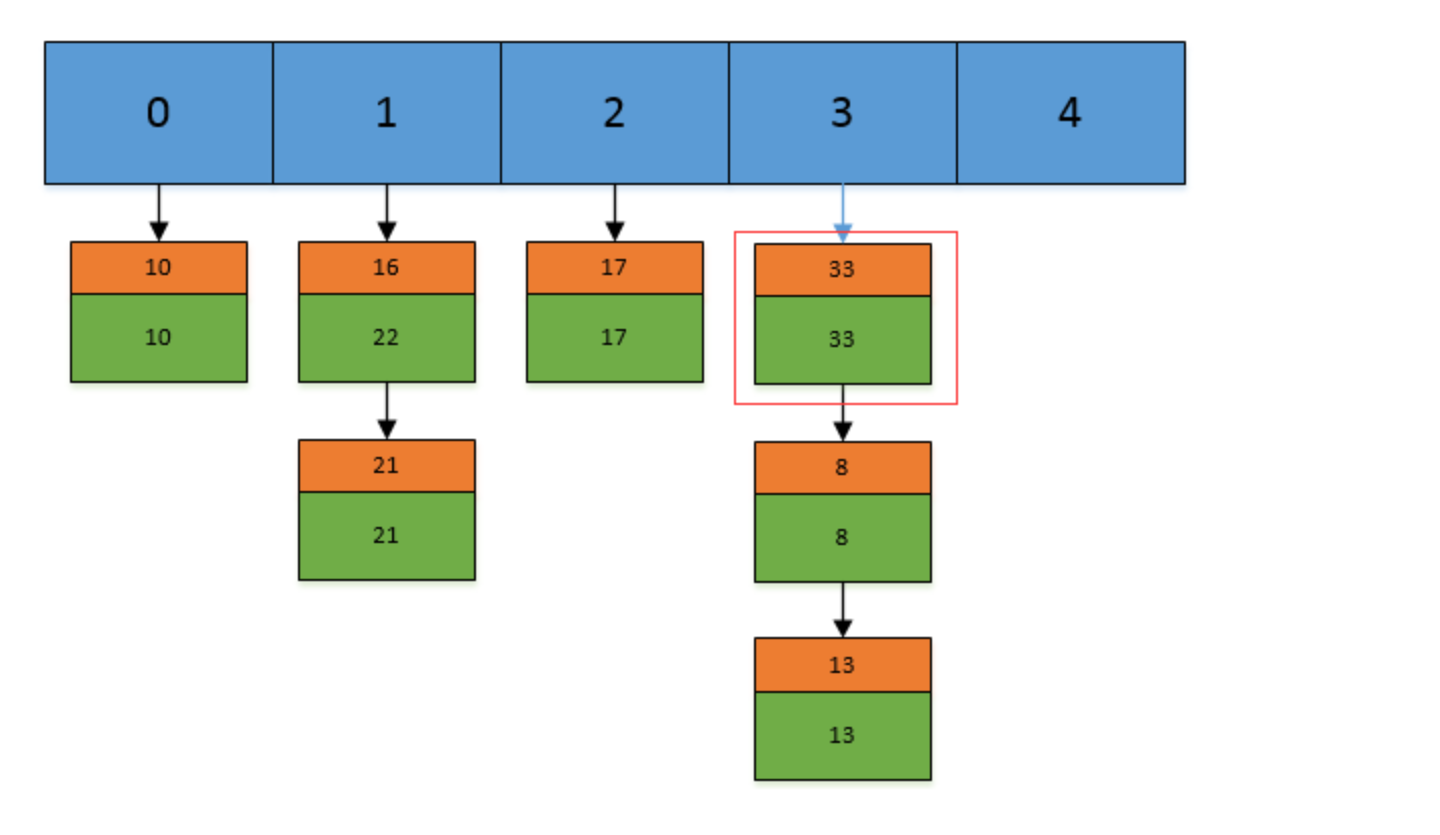
否则在将改key-value节点插入该index索引位置处。如下:假设我们现在Hashtable的容量为5,已经存在了(5,5),(13,13),(16,16),(17,17),(21,21)这 5 个键值对,目前他们在Hashtable中的位置如下:
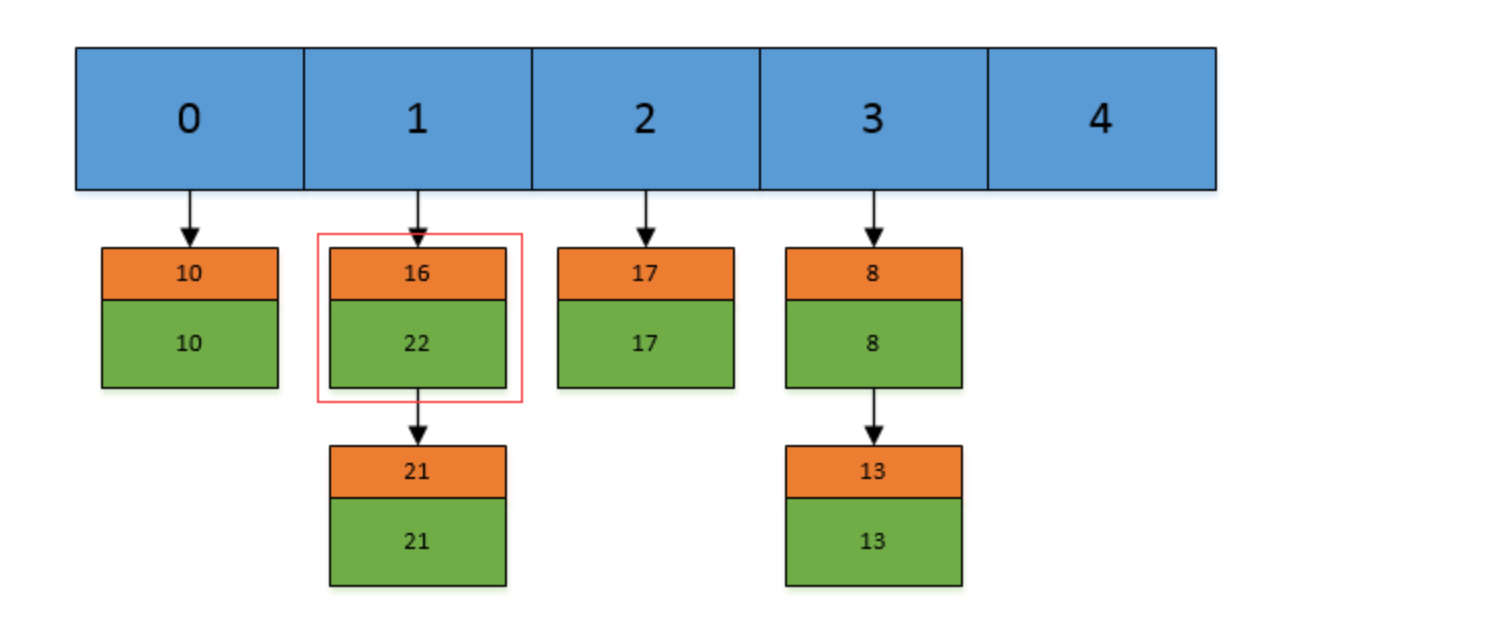
现在,我们插入一个新的键值对,put(16,22),假设key=16的索引为1.但现在索引1的位置有两个Entry了,所以程序会对链表进行迭代。迭代的过程中,发现其中有一个Entry的key和我们要插入的键值对的key相同,
所以现在会做的工作就是将newValue=22替换oldValue=16,然后返回oldValue=16.
然后我们现在再插入一个,put(33,33),key=33的索引为3,并且在链表中也不存在key=33的Entry,所以将该节点头插入链表的第一个位置。
五、总结
设计目标:Hashtable 是早期线程安全哈希表实现,通过方法级同步保证安全
缺点:
锁粒度粗,并发性能差
不支持 null 键值
哈希冲突处理简单(仅链表,无红黑树优化)
适用场景:低并发环境或需要兼容旧代码时(现代开发更推荐 ConcurrentHashMap)
hashtable底层的更多相关文章
- java面试题之HashMap和HashTable底层实现的区别
HashMap和HashTable的区别: 相同点:都是以key和value的形式存储: 不同点: HashMap是不安全的:HashTable线程安全的(使用了synchronized关键字来保证线 ...
- java-vector hashtable过时?
vector hashtable过时? 在用JAVA集合时,IDE提示 vector 以及hashtable被arraylist ,hashmap替代,而前者又是线程同步的,不知道为什么?是效率差了的 ...
- Java中常见数据结构:list与map -底层如何实现
1:集合 2 Collection(单列集合) 3 List(有序,可重复) 4 ArrayList 5 底层数据结构是数组,查询快,增删慢 6 线程不安全,效率高 7 Vector 8 底层数据结构 ...
- HashMap、Hashtable、ConcurrentHashMap的原理与区别
同步首发:http://www.yuanrengu.com/index.php/2017-01-17.html 如果你去面试,面试官不问你这个问题,你来找我^_^ 下面直接来干货,先说这三个Map的区 ...
- 集合各个实现类的底层实现原理 ----- 原文地址:https://blog.csdn.net/qq_25868207/article/details/55259978
ArrayList实现原理要点概括 参考文献: http://zhangshixi.iteye.com/blog/674856l https://www.cnblogs.com/leesf456/p/ ...
- HashMap、Hashtable、ConcurrentHashMap的原理与区别(简述)
HashTable 底层数组+链表实现,无论key还是value都不能为null,线程安全,实现线程安全的方式是在修改数据时锁住整个HashTable,效率低,ConcurrentHashMap做了相 ...
- hashMap,hashTable,concurrentHashMap区别
HashTable 底层数组+链表实现,无论key还是value都不能为null,线程安全,实现线程安全的方式是在修改数据时锁住整个HashTable,效率低,ConcurrentHashMap做了相 ...
- 面试必备:HashMap、Hashtable、ConcurrentHashMap的原理与区别
同步首发:http://www.yuanrengu.com/index.php/2017-01-17.html 如果你去面试,面试官不问你这个问题,你来找我^_^ 下面直接来干货,先说这三个Map的区 ...
- CurrentHashMap、HashMap、HashTable的区别
HashTable 底层数组+链表实现,无论key还是value都不能为null,线程安全,实现线程安全的方式是在修改数据时锁住整个HashTable,效率低,ConcurrentHashMap做了相 ...
- HashMap,HashTable,concurrentHashMap,LinkedHashMap 区别
HashMap 不是线程安全的 HashTable,concurrentHashMap 是线程安全 HashTable 底层是所有方法都加有锁(synchronized) 所以操作起来效率会低 con ...
随机推荐
- 使用 pdf.js 通过文件流方式加载pdf文件
关于Pdf.js的基础知识,请参考我的博客 使用 pdf.js 在网页中加载 pdf 文件 使用 pdf.js 跨域问题的处理方法 上面两篇博客中介绍的内容都是基于直接加载远程服务器中静态PDF文件 ...
- Kotlin:【初始化】主构造函数、在主构造函数里定义属性、次构造函数、默认参数、初始化块、初始化顺序
- Pipe pg walkthrough Intermediate
NAMP ┌──(root?kali)-[~] └─# nmap -p- -A 192.168.128.45 Starting Nmap 7.95 ( https://nmap.org ) at 20 ...
- spring boot配置pagehelper插件
一.maven配置 <mybatis-spring.version>2.1.1</mybatis-spring.version> <pagehelper-spring.v ...
- 告别 DeepSeek 系统繁忙,七个 DeepSeek 曲线救国平替入口,官网崩溃也能用!
前言 DeepSeek作为一款备受瞩目的国产大模型,以其强大的功能和卓越的性能赢得了众多用户的青睐.然而,随着用户量的激增,DeepSeek官网近期频繁遭遇服务器繁忙甚至崩溃的问题,给广大用户带来了不 ...
- RFID实践——NET IoT程序读取高频RFID卡或者标签
这篇文章是一份RFID实践的保姆级教程,将详细介绍如何用 Raspberry Pi 连接 PN5180 模块,并开发 .NET IoT 程序读写ISO14443 和 ISO15693协议的卡/标签. ...
- 图解MySQL【日志】——Binlog
Binlog(Binary Log,归档日志) 为什么需要 Binlog? Binlog 是 MySQL 中的二进制日志,用于记录数据库的所有写操作(INSERT.UPDATE.DELETE 等) 1 ...
- Vue3响应式编程三剑客:计算属性、方法与侦听器深度实战指南
在Vue3开发中,计算属性.方法和侦听器是处理数据逻辑的核心工具.它们各自有不同的作用和适用场景,合理使用这些工具可以显著提升代码的可读性和性能.本篇将深入探讨这三者的定义.使用场景以及实际案例,并通 ...
- Netty - [01] 概述
题记部分 一.介绍 Netty 是由JBOSS提供的一个Java开源框架,现为Github上的独立项目. Netty是一个异步的.基于事件驱动的网络应用框架,用以快速开发高性能.高可靠性的网络I/O程 ...
- ETL工程师
Python Flume DataX HDFS 数仓建模分层:ODS.DIM.DWD.DWS.APS Kettle.Informatica SQL(Oracle.MySQL)