ETLCloud结合kafka的数据集成
一、ETLCloud中实时数据集成的使用
在ETLCloud中数据集成有两种方式,一种是离线数据集成,另一种便是我们今天所要介绍的实时数据集成了,两者的区别从名字便可以得知,前者处理的数据是离线的没有时效性的,后者的数据是有时效性的,所以要根据自己需要的场景来使用这两个模块。
实时数据集成常见的场景有,CDC监听,Kafka监听,MQ监听(商业版),今天我们结合一些常用的场景来演示一下Kafka监听的使用。
二、场景演示
在实时数据集成中有一个重要的对象便是监听器,顾名思义是用来监听数据的变动的,一旦数据有变动那么监听器就能监听到并对数据进行原先设置好的方式去处理。
1、创建监听器
点击实时数据集成模块,进入模块首页,选择Kafka监听器,点击新增监听器
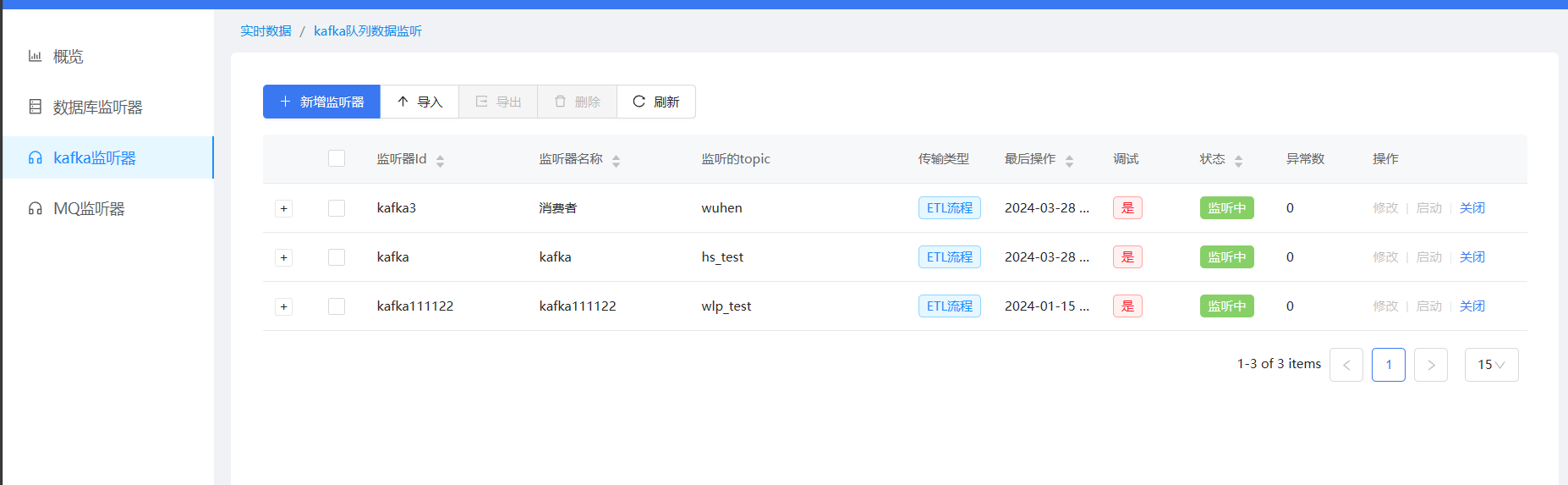
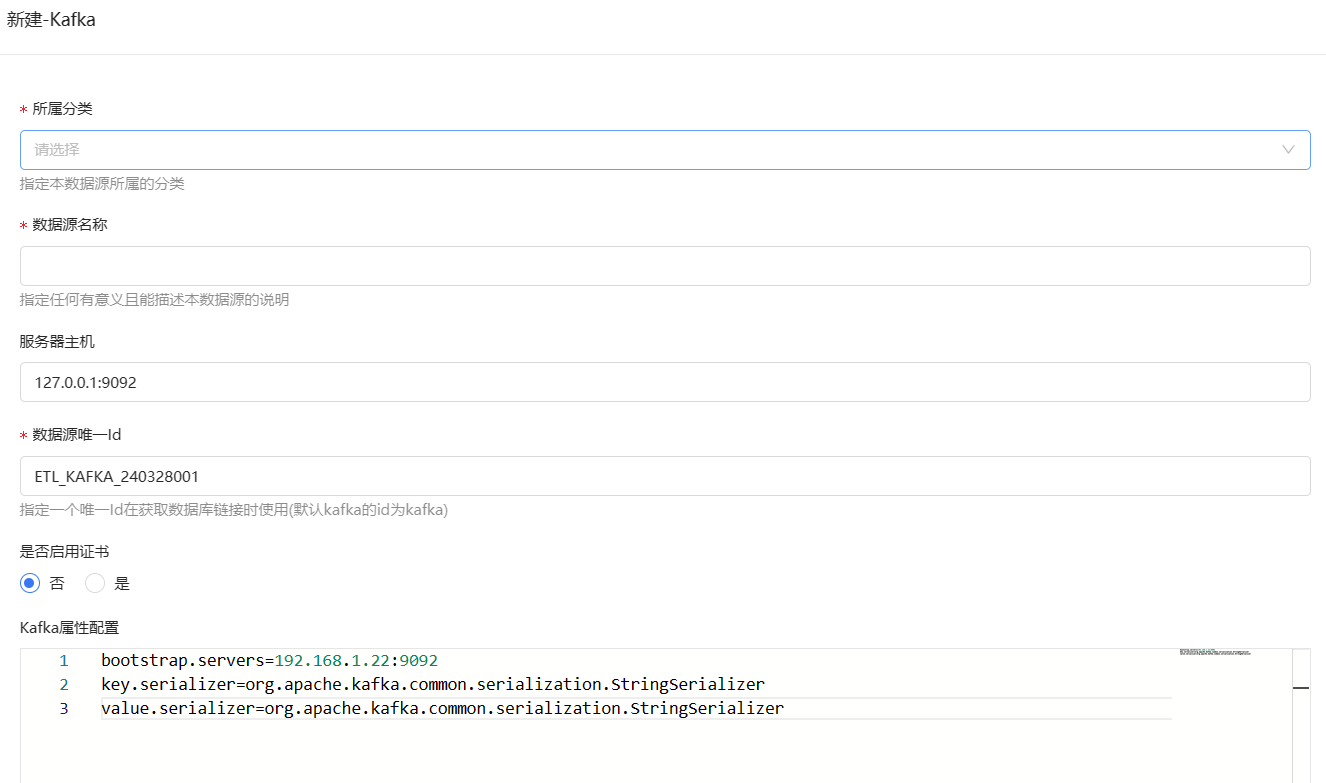
2、监听器的配置,Kafka的数据源我们需要在数据源管理中去新建
数据源选择Kafka然后新建数据源填写服务相关信息即可。
监听器配置图如下:
选择我们刚刚创建好的Kafka数据源,点击载入主题列表按钮,便可以获取所有的消费主题,填写消费分组,数据来源选择其他topic数据(监听的是Kafka中的主题)
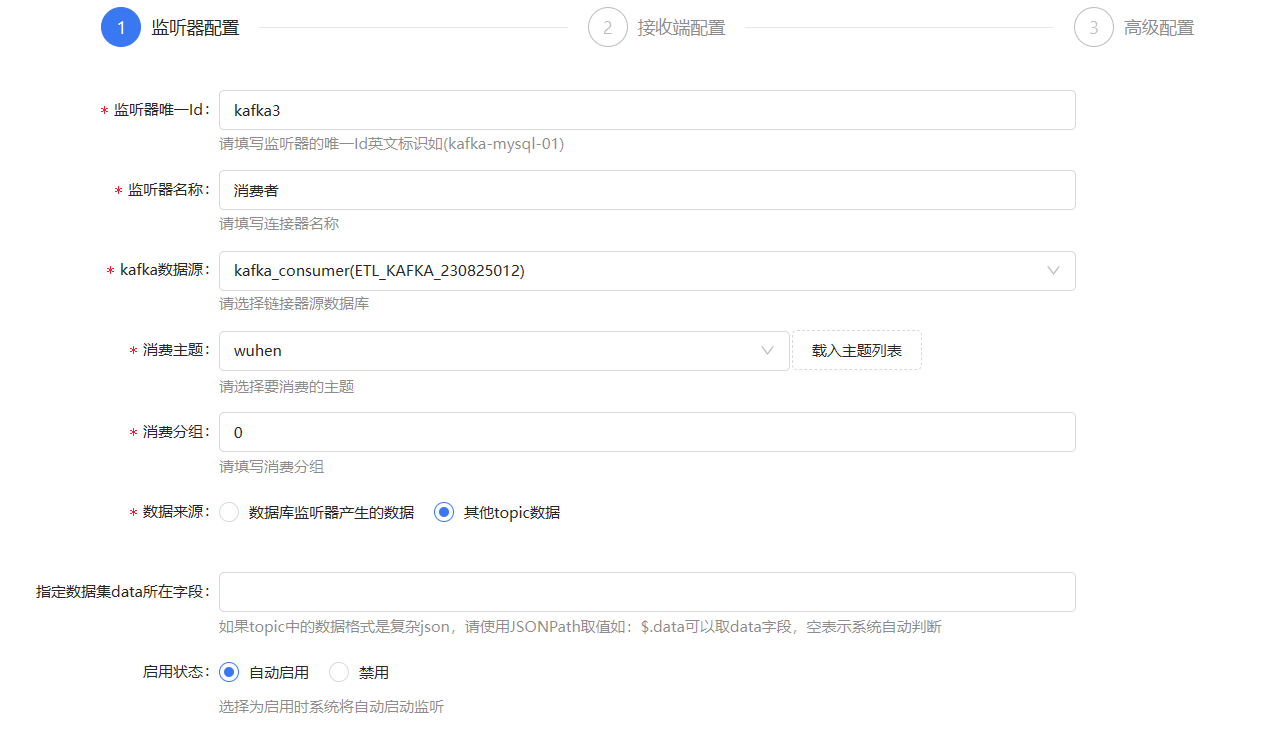
接收端的配置:
我们可以选择把数据传给指定流程或者直接输出到目标库中,我们选择传输给ETL流程
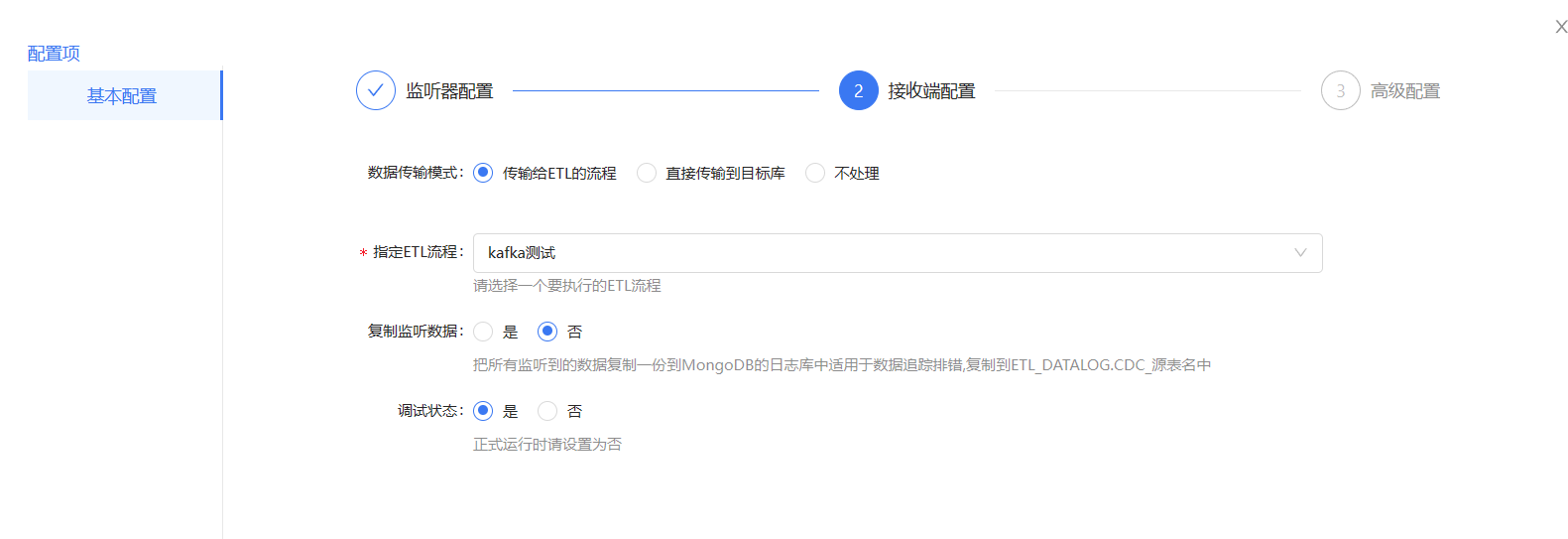
3、创建接收实时数据的离线流程或目标数据库
我们可以创建一个简单的流程,将数据进行输出,流程如下。

4、向Kafka发送消息,offersetExploer工具连接Kafka并找到所要监听的主题,进行消息发送。
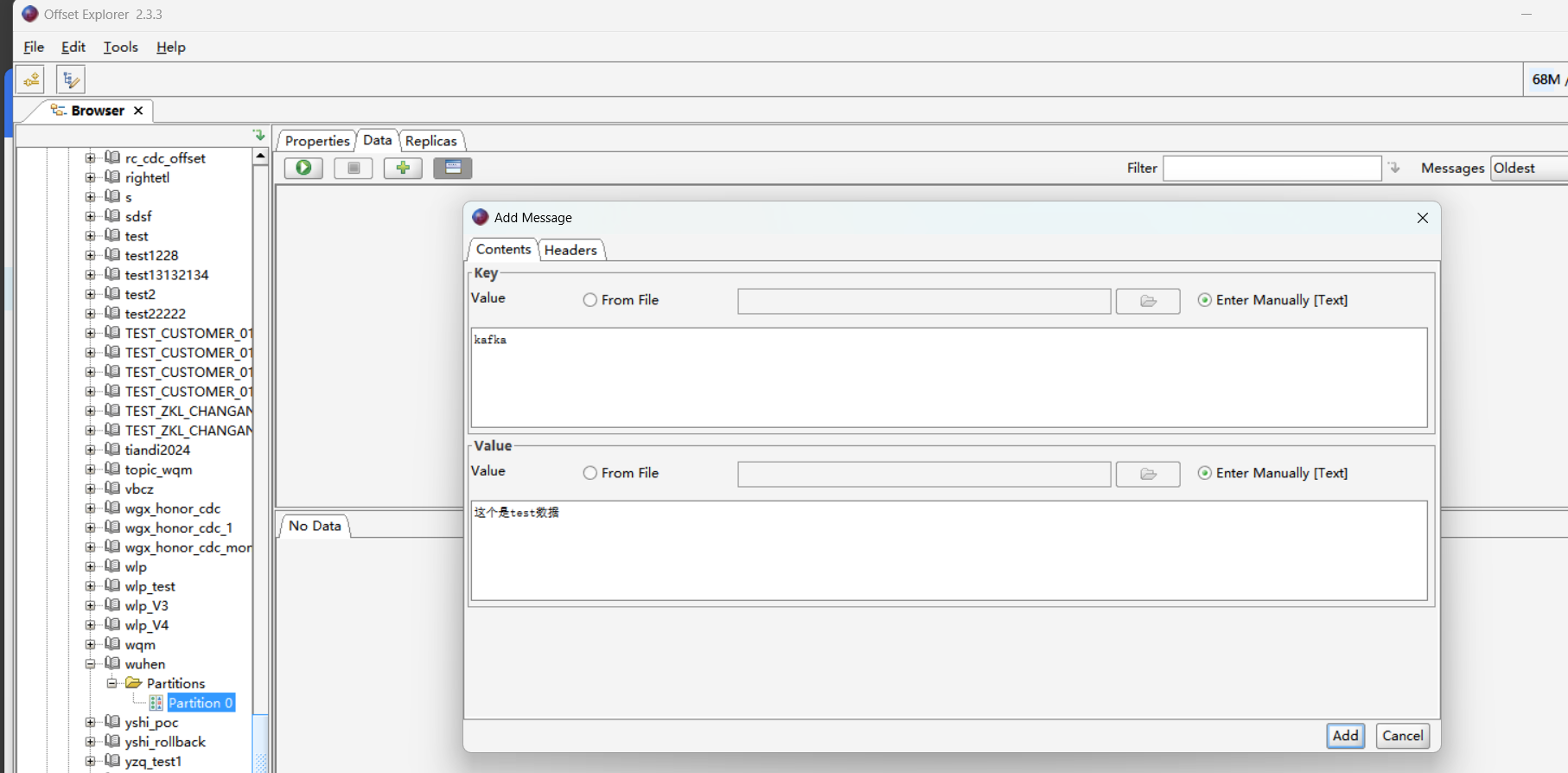
5、发送后回到我们之前创建好的流程查看流程日志,可以发现监听到的数据已经发送到流程中了。

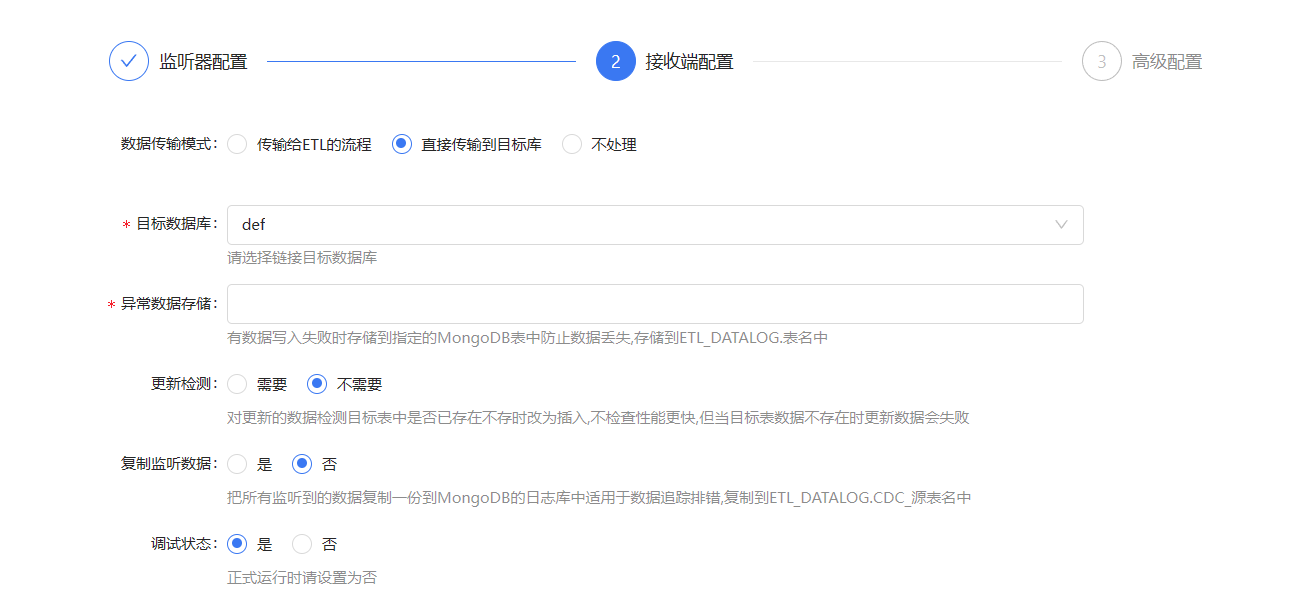
同理如果是将数据传输到目标数据库,只需要配置好目标数据源即可
三、总结
实时数据集成是ETLCloud中重要的功能模块之一,与离线数据集成相对应。实时数据集成能够处理具有时效性的数据,常见的场景包括CDC监听、Kafka监听以及MQ监听等。
在实时数据集成中,监听器是一个重要的对象,用于监听数据的变动,一旦数据有变动,监听器就会触发相应的处理操作。具体操作包括创建监听器、配置Kafka数据源、设置接收端配置等步骤。
对于Kafka监听器的配置,需要先在数据源管理中新建Kafka数据源并填写相关信息,然后配置监听器以选择消费主题、填写消费分组等。接收端的配置可以选择传输给ETL流程或直接输出到目标数据库。
创建接收实时数据的离线流程或目标数据库是实时数据集成的关键步骤之一,通过简单的流程可以将监听到的数据进行输出或传输至目标数据库。
最后,通过消息发送工具向Kafka发送消息,然后查看流程日志以确认监听到的数据是否已经发送到流程中。
ETLCloud结合kafka的数据集成的更多相关文章
- DataPipeline丨构建实时数据集成平台时,在技术选型上的考量点
文 | 陈肃 DataPipeline CTO 随着企业应用复杂性的上升和微服务架构的流行,数据正变得越来越以应用为中心. 服务之间仅在必要时以接口或者消息队列方式进行数据交互,从而避免了构建单一数 ...
- 基于Kafka Connect框架DataPipeline可以更好地解决哪些企业数据集成难题?
DataPipeline已经完成了很多优化和提升工作,可以很好地解决当前企业数据集成面临的很多核心难题. 1. 任务的独立性与全局性. 从Kafka设计之初,就遵从从源端到目的的解耦性.下游可以有很多 ...
- 基于Kafka Connect框架DataPipeline在实时数据集成上做了哪些提升?
在不断满足当前企业客户数据集成需求的同时,DataPipeline也基于Kafka Connect 框架做了很多非常重要的提升. 1. 系统架构层面. DataPipeline引入DataPipeli ...
- 以Kafka Connect作为实时数据集成平台的基础架构有什么优势?
Kafka Connect是一种用于在Kafka和其他系统之间可扩展的.可靠的流式传输数据的工具,可以更快捷和简单地将大量数据集合移入和移出Kafka的连接器.Kafka Connect为DataPi ...
- 打造实时数据集成平台——DataPipeline基于Kafka Connect的应用实践
导读:传统ETL方案让企业难以承受数据集成之重,基于Kafka Connect构建的新型实时数据集成平台被寄予厚望. 在4月21日的Kafka Beijing Meetup第四场活动上,DataPip ...
- Kafka ETL 之后,我们将如何定义新一代实时数据集成解决方案?
上一个十年,以 Hadoop 为代表的大数据技术发展如火如荼,各种数据平台.数据湖.数据中台等产品和解决方案层出不穷,这些方案最常用的场景包括统一汇聚企业数据,并对这些离线数据进行分析洞察,来达到辅助 ...
- DataPipeline CTO陈肃:从ETL到ELT,AI时代数据集成的问题与解决方案
引言:2018年7月25日,DataPipeline CTO陈肃在第一期公开课上作了题为<从ETL到ELT,AI时代数据集成的问题与解决方案>的分享,本文根据陈肃分享内容整理而成. 大家好 ...
- Kafka设计解析(十八)Kafka与Flink集成
转载自 huxihx,原文链接 Kafka与Flink集成 Apache Flink是新一代的分布式流式数据处理框架,它统一的处理引擎既可以处理批数据(batch data)也可以处理流式数据(str ...
- DataPipeline CTO 陈肃:我们花了3年时间,重新定义数据集成
目前,中国企业在大数据流通.交换.利用等方面仍处于起步阶段,但是企业应用数据集成市场却是庞大的.根据 Forrester 数据看来,2017 年全球数据应用集成市场纯软件规模是 320 亿美元,如果包 ...
- 详解Kafka: 大数据开发最火的核心技术
详解Kafka: 大数据开发最火的核心技术 架构师技术联盟 2019-06-10 09:23:51 本文共3268个字,预计阅读需要9分钟. 广告 大数据时代来临,如果你还不知道Kafka那你就真 ...
随机推荐
- 关于:js怎么获取元素的自定义属性的问题(原生JavaScript)
最近项目需要把后端传过来的数据隐藏的保存在页面中,方便后边做事件处理时使用.鉴于之前总是在后端处理后的页面中看到元素里除了常见的id.name属性外的data-xxx,就想到:元素的属性必然是可以自定 ...
- 通过apache tika从文档(pdf、doc、docx、txt)中 提取特征数据
本文介绍如何通过apache tika从文档(pdf.doc.docx.txt)中 提取特征数据,比如文档中有身份证.姓名等信息.[全部是经本人实际测试过的功能] 1.需引入相关pom依赖 <! ...
- 还有的时候,会遇到DataGrid里面嵌套DataGrid(重叠嵌套),然后里面的鼠标滚轮无法响应外面的滚动,为此记录下解决方案
与上一篇区别在于,详情里面的模板通常是通用的,被定义在样式文件中,被重复使用,因此无法为其添加后台代码,如果能添加后台代码,请翻阅第一篇:所以需要用到命令的方式来辅助事件的抛出,当然还可以利用第三方库 ...
- 11.7K Star!这个分布式爬虫管理平台让多语言协作如此简单!
嗨,大家好,我是小华同学,关注我们获得"最新.最全.最优质"开源项目和高效工作学习方法 分布式爬虫管理平台Crawlab,支持任何编程语言和框架的爬虫管理,提供可视化界面.任务调度 ...
- 【笔记】PyVis|神经网络数据集的可视化
文章目录 版本: 应用实例: PyVis的应用: 零.官方教程 一.初始化画布`Network` 二.添加结点 添加单个结点`add_node`: 添加一系列结点`add_nodes`: 三.添加边 ...
- 获取接口方式(Bean注入方式总结)
一.在工具类中使用SpringContextHolder获取Bean对象,用来调用各个接口 /** * 获取阿里巴巴属性列表映射 * * @author 王子威 * @param alibabaPro ...
- JS/Jquery检查网络路径文件是否存在
var url='网络文件路径'; var isExists; $.ajax(url, { type: 'HEAD', dataType: 'text', async: false, success: ...
- FFmpeg开发笔记(六十二)Windows给FFmpeg集成H.266编码器vvenc
<FFmpeg开发实战:从零基础到短视频上线>该书的第八章介绍了如何在Windows环境给FFmpeg集成H.264和H.265的编码器,如今H.266的编码器vvenc也日渐成熟,从7 ...
- 使用 TRL 训练Reward Model奖励模型
训练过程 在此示例中,将微调"distilroberta-base"模型. 该formatting_func函数将指令与所选和拒绝的响应相结合,创建两个新字符串.这些字符串被标记化 ...
- Squid代理配置使用
1.Squid简单说明 Squid Cache(简称为Squid)是HTTP代理服务器软件.Squid用途广泛,可以作为缓存服务器,可以过滤流量帮助网络安全,也可以作为代理服务器链中的一环,向上级代理 ...