使用uint64_t批量比较短字符串
记录一下从开源代码里学来的短字符串比较优化。
这个优化只适用于长度在八字节以下的字符串,且只适用于优化相等比较。
原理
想要判断字符串相等,常见的有利用strcmp、利用字符串的hash或者利用正则表达式等。
就速度而言strcmp > hash > 正则,而灵活性上正则 > hash ≈ strcmp。
字符串的相等性比较可以说是程序运行中的热点,因此用于比较字符串的各种函数也是性能优化中的重点,这使得strcmp在通用场景下有着相当不错的性能表现。
不过在细分场景上strcmp就有点心有余而力不足了。我们要讨论的场景就是这种细分场景:两个字符串长度相同且都小于等于八字节。
在这个场景下,绝大多数字符串比较函数都是选择逐字节循环比较的,这个策略其实没有问题,少量数据以固定模式进行循环处理,对于现代cpu来说是个很容易吃到缓存优化的操作,因此速度不会落下风。
但这个方案仍然需要多次比较数据,这是一个瓶颈,我们要讲的优化就是针对减少比较次数这一点进行的。
考虑两个八字节长度的字符串hello123和hello124,如果用逐字节比较的办法,最坏情况下我们需要比较8次。想要减少比较次数我们就得每次比较两个字节以上的数据,甚至是一次就处理全部的八个字节。
碰巧的是现代的x86和ARM芯片上还真有这种一次比较八字节数据的指令,只不过这些指令比较的是64位整数值而不是字符串。我们的优化措施就是利用这些指令来比较字符串内容。
所以现在的问题变成了怎么把字符串转换成整数值。很多读者应该会立即想到hash,但这里用hash是不合适的,hash本身需要处理每一个字符,而且需要添加很多额外的运算,在以前的博客里我测试过在处理短字符串时它的性能是不及strcmp的。而现在我们要实现比strcmp更快的方法,hash自然是不适用的。
剩下只有一种途径了,64位整数正好需要八字节内存,我们的字符串也正好是八字节,所以我们可以考虑把字符串的二进制数据整个复制给整数。这个做法其实在c/c++系统编程里很常见,但对于习惯了go/js的人来说可能有些陌生了:
uint64_t string2uint64(const char *str)
{
uint64_t res = 0;
memcpy((void*)&res, (const void*)str, sizeof(uint64_t));
return res;
}
为了代码尽量简短,我用了c-style的类型转换。这个函数其实不安全,想象一下str没有8字节长的情景,这个函数会越界访问。这段代码也不够类型安全。
string2uint64要求字符串必须有至少8字节长度,所以对于不足8字节的字符串,调用的时候得补足:
string2uint64("hello123") // 正好8字节
string2uint64("hell\0\0\0\0") // 补了4个0
而且长度的计量单位是字节,因此碰到汉字这种不管什么编码基本都是多字节存储的内容,这个函数也很容易出错。
如果觉得补0很麻烦,实际上我们也有简化手段:使用memccpy。这个函数可以在找到指定字符的时候停止复制,因此我们只要让它找到字符串结尾的0就可以阻止越界访问了:
uint64_t string2uint64Unalign(const char *str)
{
uint64_t res = 0;
memccpy((void*)&res, (const void*)str, 0, sizeof(uint64_t));
return res;
}
注意两个版本我都采用了复制而不是直接把字符串的指针转换成uint64_t*,因为后者是真正的踩在了语言标准的红线上,而且也没办法像string2uint64Unalign那样处理长度对齐。
在把字符串转换成整数之后,我们就可以用比较整数的方式比较字符串了:
strcmp("hello", "world") == 0 || strcmp("hello", "Hello") == 0 || strcmp("hello", "hello") == 0;
// 等价于
const auto value = string2uint64("hello\0\0\0");
value == string2uint64("world\0\0\0") || value == string2uint64("Hello\0\0\0") || value == string2uint64("hello\0\0\0");
注意为了补足长度而填充进去的0。
可以自己写个测试代码看看两个函数生成的整数值,具体的值会和字节序有关,但只要每个字符串都按相同的字节序进行处理,就不会有问题:
int main()
{
std::cout << string2uint64("hello123") << '\n';
std::cout << string2uint64Unalign("hello123") << '\n';
std::cout << string2uint64("hell\0\0\0\0") << '\n';
std::cout << string2uint64Unalign("hell") << '\n';
}
// 输出
3689065399400031592
3689065399400031592
1819043176
1819043176
性能测试
理解了原理,现在该看看性能了。
有经验的读者应该会有两个担心的点,第一个在于一次memcpy的内存复制开销是否会成为性能杀手,第二个在于memccpy做了额外的检测会不会导致执行速度减慢。
我也有这些担心,所以我设计了一个性能测试。测试使用随机生成的8字节长度的字符串,然后让两种优化方法和strcmp每次都就行八次匹配,只有最后一次会得到相等的结果。这样我们可以让字符串相等的判断逻辑尽量处理足够多的字符内容,以便模拟日常开发中的场景。
用随机生成字符串是有讲究的,因为用字符串常量编译器会在编译时就进行计算导致结果没有意义。这不能怪编译器,因为字符串比较操作实在太常用所以必须抓住一切机会就行优化。随机生成比较用的数据暂时能阻止编译器的优化。
生成随机字符串的代码我直接让AI写了,AI很适合生成这种只用一两次的阅后即焚的小型函数:
std::string generateRandomString(std::size_t length = 8) {
const std::string charset = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
"abcdefghijklmnopqrstuvwxyz"
"0123456789";
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_int_distribution<> distrib(0, charset.size() - 1);
std::string result;
result.reserve(length);
for (std::size_t i = 0; i < length; ++i) {
result += charset[distrib(gen)];
}
return result;
}
写的确实很一般,但勉强能用。测试部分当然是我手写的,这块代码很简单:
void bench_strcmp(benchmark::State &state)
{
const char *target = "hello123";
std::vector<std::string> data;
for (int i = 0; i < 7; ++i) {
data.push_back(generateRandomString());
}
data.push_back("hello123");
for (auto _ : state) {
for (const auto &str: data) {
benchmark::DoNotOptimize(strcmp(target, str.c_str()) == 0);
}
}
}
BENCHMARK(bench_strcmp);
void bench_fast(benchmark::State &state)
{
const char *target = "hello123";
const uint64_t v = string2uint64(target);
std::vector<std::string> data;
for (int i = 0; i < 7; ++i) {
data.push_back(generateRandomString());
}
data.push_back("hello123");
for (auto _ : state) {
for (const auto &str: data) {
benchmark::DoNotOptimize(v == string2uint64(str.c_str()));
}
}
}
BENCHMARK(bench_fast);
void bench_not_need_align(benchmark::State &state)
{
const char *target = "hello123";
std::vector<std::string> data;
for (int i = 0; i < 7; ++i) {
data.push_back(generateRandomString());
}
data.push_back("hello123");
const uint64_t v = string2uint64Unalign(target);
for (auto _ : state) {
for (const auto &str: data) {
benchmark::DoNotOptimize(v == string2uint64Unalign(str.c_str()));
}
}
}
BENCHMARK(bench_not_need_align);
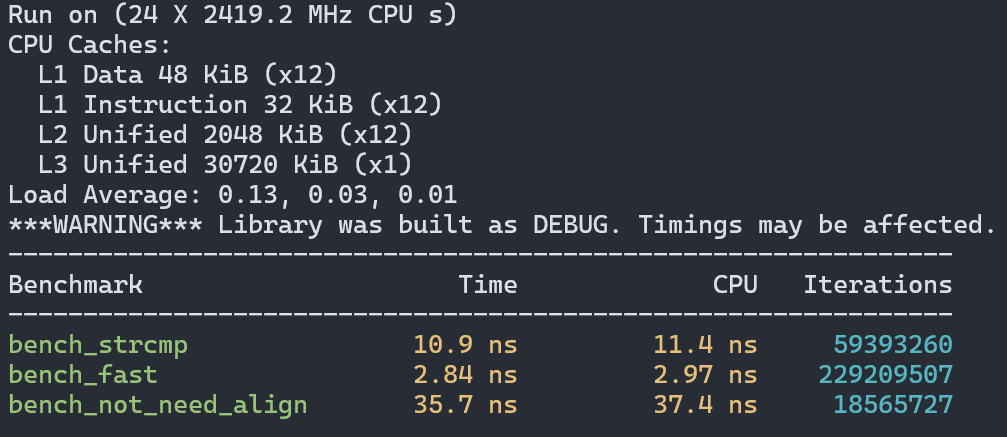
首先是在Intel CPU的Linux上使用GCC的测试结果:
接着是在Intel cpu的Windows上使用msvc编译器的结果:

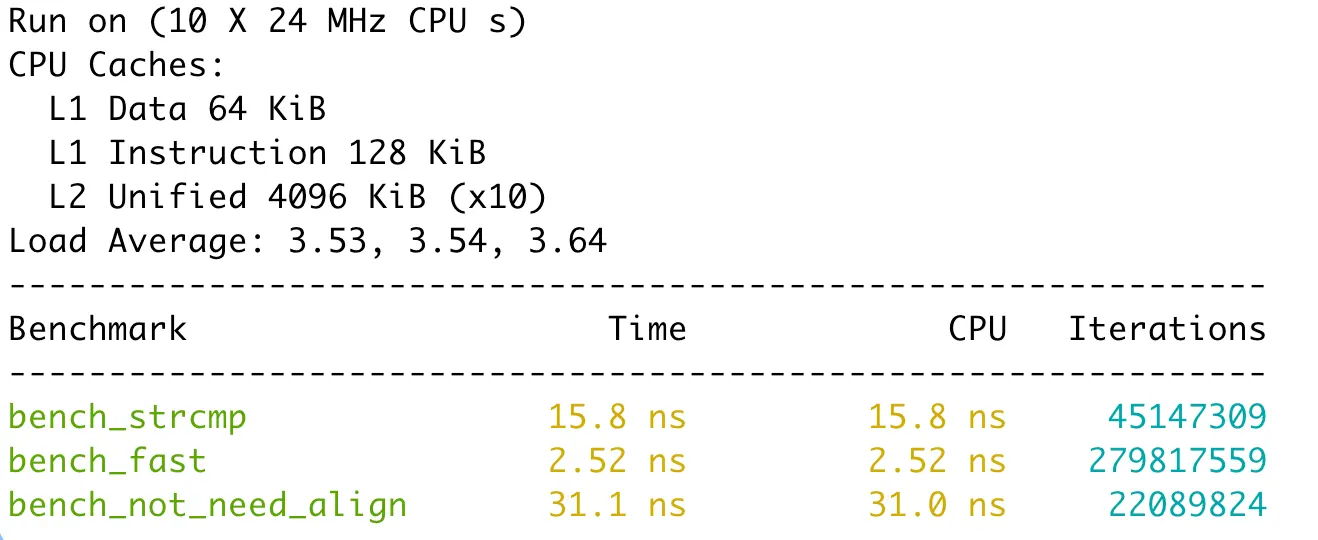
最后是Apple M4上使用clang的结果:
所有编译器都采用了最高级别的优化(gcc/clang使用-O3,msvc使用/O2)。
可以看到一次内存复制并不会成为性能瓶颈,反而让性能获得了至少3倍的提升。但memccpy确实成了性能杀手,每个结果里都比用strcmp慢至少一倍。
结论就是如果比较的字符串长度都是8字节,那么使用string2uint64是最好的,只要有一个条件不满足,那么就改用strcmp。你问我为啥没测试需要补零的场景,其实我测过,不管怎么补都会比memccpy慢得多,所以没有放出来的价值。
其他语言中的效果
其他语言指的是go语言,python/js/lua没提过直接操作底层对象内存数据的接口,而rust又对类型安全和内存安全有严格的限制(使用unsafe能绕过一部分但最好别这么做),那就只有go能试试了。
实现方法采用的是*byte强转*uint64然后解引用获取数值。虽然c++里不许这么干,但golang里是可以的,但往大里说这是对unsafe的滥用:
func str2uint64(s string) uint64 {
p := unsafe.StringData(s)
up := (*uint64)(unsafe.Pointer(p))
return *up
}
golang中没有memccpy,前面我们也测过自动探测字符串边界的办法很慢,因此这里就省略了。
这个函数也和c++版本的一样,字符串必须是八字节长,否则会panic。
性能测试采用和c++一样的策略,测试版本是golang 1.24.5:
func BenchmarkStrcmp(b *testing.B) {
data := make([]string, 0, 8)
for range 7 {
data = append(data, GenerateRandomString(8))
}
data = append(data, "hello123")
for b.Loop() {
for i, s := range data {
a := strings.Compare("hello123", s) == 0
if i < 7 && a {
panic("error")
}
}
}
}
func BenchmarkEqual(b *testing.B) {
data := make([]string, 0, 8)
for range 7 {
data = append(data, GenerateRandomString(8))
}
data = append(data, "hello123")
for b.Loop() {
for i, s := range data {
a := s == "hello123"
if i < 7 && a {
panic("error")
}
}
}
}
func BenchmarkFast(b *testing.B) {
data := make([]string, 0, 8)
for range 7 {
data = append(data, GenerateRandomString(8))
}
data = append(data, "hello123")
v := str2uint64("hello123")
for b.Loop() {
for i, s := range data {
a := v == str2uint64(s)
if i < 7 && a {
panic("error")
}
}
}
}
遗憾的是效果并不理想:
cpu: Intel(R) Core(TM) i7-14650HX
BenchmarkStrcmp-24 52009516 22.81 ns/op 0 B/op 0 allocs/op
BenchmarkEqual-24 286688548 4.218 ns/op 0 B/op 0 allocs/op
BenchmarkFast-24 150709956 7.951 ns/op 0 B/op 0 allocs/op
我们的方法比直接使用==慢了接近一倍。原因其实很简单,go的编译器已经做过字符串转数字再比较的操作了。因此==节省了很多边界检查和转换操作,速度更快。go编译器也没有采用我们这种强转类型的做法,而是使用了移位操作和位运算来组合每一个字节到最终的整数值,这也是为什么它的速度比我们的cpp版本慢一些的原因。go使用位运算拼接整数的目的在于可以让比较的操作数可以有不同的长度,不足的部分默认都是0,这还免除了我们使用memccpy导致的性能下降,是比较smart的。除了更快,编译器优化的版本比我们自己实现的更安全,不用担心panic。
go直接优化的字符串长度还可以超过8字节,因为它会检测平台是否支持一次可以加载超过8字节数据的指令。在c++里想这么做得费很大一番功夫,因此我没有实现这种功能。
虽说我们在go中手动实现优化的效果不理想,但这也从侧面证明我们的思路是对的——别的语言也采纳了这种优化。
总结
其实不止是优化固定长度的字符串比较,将二进制数据转换成整数进行批量处理其实是一种丐版的“SIMD”,所以这个技巧你可以在很多开源项目里发现,比如go对字符串相等判断的优化,又比如google开发的swisstable中在目标环境上不支持SIMD时会使用整数类型合并多个元素的tag进行批量处理,例子还可以举出很多。
最后我还是得提醒一下,这个方案有一定的安全风险,以及优化前要用性能测试找瓶颈,优化后要用性能测试做验证,切记。
使用uint64_t批量比较短字符串的更多相关文章
- 使用List把一个长字符串分解成若干个短字符串
把一个长字符串分解成若干个固定长度的短字符串,由于事先不知道长字符串的长度,以及短字符串的数量,只能使用List. public static void get_list_sbody(String s ...
- TSQL:判断某较短字符串在较长字符串中出现的次数。
给定一个较短字符串shortStr='ab',和一个较长字符串longStr='adkdabkwelabwkereabrsdweo2342ablk234lksdfsdf1abe': 判断shortSt ...
- 个人永久性免费-Excel催化剂功能第85波-灵活便捷的批量发送短信功能(使用腾讯云接口)
微信时代的今天,短信一样不可缺席,大系统都有集成短信接口.若只是临时用一下,若能够直接在Excel上加工好内容就可以直接发送,这些假设在此篇批量群发短信功能中都为大家带来完美答案. 业务场景 不多说, ...
- C++Day09 深拷贝、写时复制(cow)、短字符串优化
一.std::string 的底层实现 1.深拷贝 1 class String{ 2 public: 3 String(const String &rhs):m_pstr(new char[ ...
- JAVA实现多线程处理批量发送短信、APP推送
/** * 推送消息 APP.短信 * @param message * @throws Exception */ public void sendMsg(Message message) throw ...
- php批量发送短信或邮件的方案
最近遇到在开发中遇到一个场景,后台管理员批量审核用户时候,需要给用户发送审核通过信息,有人可能会想到用foreach循环发送,一般的短信接口都有调用频率,循环发送,肯定会导致部分信息发送失败,有人说用 ...
- linux批量替换文本字符串
(一)通过vi编辑器来替换.vi/vim 中可以使用 :s 命令来替换字符串.:s/well/good/ 替换当前行第一个 well 为 good:s/well/good/g 替换当前行所有 well ...
- Linux批量查询替换字符串
Linux 批量查询替换文本文件中的字符串: 1.批量查找某个目下文件的包含的内容,例如: # grep -rn "要找查找的文本" ./ 2.批量查找并替换文件内容. # ...
- 用那啥 那啥来着Django来发送Email,结合腾讯云,批量发短信给用户!
你们好,我是来ZB的! 这篇博客是用来发送邮件的,用的是Django框架,很好用.遗憾的是我当时用的阿里云,把腾讯QQ的端口给……给屏蔽了,啊啊啊啊,多么痛的领悟呀.后来用的163网易的邮箱.可以了! ...
- MSSQL批量替换网址字符串语句
1.如何批量替换ntext字段里面的数据 问题描述: 我想把数据库中News表中的字段content中的一些字符批量替换. 我的content字段是ntext类型的. 我想替换的字段是content字 ...
随机推荐
- 3.4K star!全能PDF处理神器开源!文档转换/OCR识别一键搞定
嗨,大家好,我是小华同学,关注我们获得"最新.最全.最优质"开源项目和高效工作学习方法 PDF-Guru 是一款开箱即用的全能型PDF处理工具,支持跨平台文档转换.智能OCR识别. ...
- rider更新2021.2
Rider 的新功能Rider 2021.2 带有增强的 C# 语言支持,包括对代码分析.可为空引用类型和源生成器的大量更新.对于 Web 开发人员,此版本支持 ASP.NET Core Endpoi ...
- 基于Kubernetes可扩展的Selenium 并行自动化测试部署及搭建(3)——基于k8s的selenium grid集群搭建
本篇主要讲解如何使用k8s搭建selenium grid集群 Selenium Grid集群部署 1. 首先我们将通过 Kubernetes 服务进行通信以到达hub和nodes.Kubernete ...
- Flutter跨平台发送系统通知和状态栏通知技术浅析
@charset "UTF-8"; .markdown-body { line-height: 1.75; font-weight: 400; font-size: 15px; o ...
- TVM Pass优化 -- 移除无用函数(Remove Unused Function)
定义 移除无用函数,Remove Unused Function,顾名思义,就是删除Module中定义但未用到的函数 当然,它也是一个模块级的优化, 举例子: def get_mod(): mod = ...
- AI+自动化测试系统方案:网络设备与网络应用智能测试
一.系统目标 通过AI与自动化测试工具的结合,实现网络设备和应用的 全生命周期测试,覆盖 流量分析.配置验证.故障排查.预警告警 四大核心场景,提升网络运维效率与可靠性. 二.技术架构设计 1. 整体 ...
- K-th Symbol in Grammar——LeetCode进阶路
原题链接https://leetcode.com/problems/k-th-symbol-in-grammar/ 题目描述 On the first row, we write a 0. Now i ...
- 基于ROS2/MoveIt!的工业机械臂控制系统开发全攻略
1. 系统架构设计 1.1 系统组成模块 [Vision System] --> [Perception Node] | | [Gazebo Sim] <--> [ROS2 Cont ...
- .NET外挂系列:6. harmony中一些实用的反射工具包
一:背景 1. 讲故事 本来想研究一下 IL编织和反向补丁的相关harmony知识,看了下其实这些东西对 .NET高级调试 没什么帮助,所以本篇就来说一些比较实用的反射工具包吧. 二:反射工具包 1. ...
- Linux 统计活跃线程和线程数
摘要:使用Linux命令ps -eT动态查看进程中,以指定字符串打头的活跃线程和线程数. 动态查看进程的线程数及活跃线程数 实现方案 在Linux系统中,可以使用以下命令来动态查看进程中名字包含& ...